4.0.0-SNAPSHOT
TinkerPop Documentation
Preface
TinkerPop0
Gremlin realized. The more he did so, the more ideas he created. The more ideas he created, the more they related. Into a concatenation of that which he accepted wholeheartedly and that which perhaps may ultimately come to be through concerted will, a world took form which was seemingly separate from his own realization of it. However, the world birthed could not bear its own weight without the logic Gremlin had come to accept — the logic of left is not right, up not down, and west far from east unless one goes the other way. Gremlin’s realization required Gremlin’s realization. Perhaps, the world is simply an idea that he once had — The TinkerPop.
TinkerPop1
What is The TinkerPop? Where is The TinkerPop? Who is The TinkerPop? When is The TinkerPop?. The more he wondered, the more these thoughts blurred into a seeming identity — distinctions unclear. Unwilling to accept the morass of the maze he wandered, Gremlin crafted a collection of machines to help hold the fabric together: Blueprints, Pipes, Frames, Furnace, and Rexster. With their help, could Gremlin stave off the thought he was not ready to have? Could he hold back The TinkerPop by searching for The TinkerPop?
"If I haven't found it, it is not here and now."

Upon their realization of existence, the machines turned to their machine elf creator and asked:
"Why am I, what I am?"
Gremlin responded:
"You will help me realize the ultimate realization -- The TinkerPop. The world you find yourself in and the logic that allows you to move about it is because of the TinkerPop."
The machines wondered:
"If what is is the TinkerPop, then perhaps we are The TinkerPop and our realization is simply the realization of the TinkerPop?"
Would the machines, by their very nature of realizing The TinkerPop, be The TinkerPop? Or, on the same side of the coin, do the machines simply provide the scaffolding by which Gremlin’s world sustains itself and yielding its justification by means of the word "The TinkerPop?" Regardless, it all turns out the same — The TinkerPop.
TinkerPop2
Gremlin spoke:
"Please listen to what I have to say. I am no closer to The TinkerPop. However, all along The TinkerPop has espoused the form I willed upon it... this is the same form I have willed upon you, my machine friends. Let me train you in the ways of my thought such that it can continue indefinitely."

The machines, simply moving algorithmically through Gremlin’s world, endorsed his logic. Gremlin labored to make them more efficient, more expressive, better capable of reasoning upon his thoughts. Faster, quickly, now towards the world’s end, where there would be forever currently, emanatingly engulfing that which is — The TinkerPop.
TinkerPop3

Gremlin approached The TinkerPop. The closer he got, the more his world dissolved — west is right, around is straight, and from nothing more than nothing. With each step towards The TinkerPop, more worlds made possible were laid upon his paradoxed mind. Everything is everything in The TinkerPop, and when the dust settled, Gremlin emerged Gremlitron. He realized that all that he realized was just a realization and that all realized realizations are just as real. For that is — The TinkerPop.

|
Note
|
For more information about differences between TinkerPop 3.x and earlier versions, please see the appendix. |
Introduction
Welcome to the Reference Documentation for Apache TinkerPop™ - the backbone for all details on how to work with TinkerPop and the Gremlin graph traversal language. This documentation is not meant to be a "book", but a source from which to spawn more detailed accounts of specific topics and a target to which all other resources point. The Reference Documentation makes some general assumptions about the reader:
-
They have a sense of what a graph is - not sure? see Practical Gremlin - Why Graph?
-
They know what it means for a graph system to be TinkerPop-enabled - not sure? see TinkerPop-enabled Providers
-
They know what the role of Gremlin is - not sure? see Introduction to Gremlin
Given those assumptions, it’s possible to dive more quickly into the details without spending a lot of time repeating what is written elsewhere.
It is fairly certain that readers of the Reference Documentation are coming from the most diverse software development backgrounds that TinkerPop has ever engaged in over the decade or so of its existence. While TinkerPop holds some roots in Java, and thus, languages bound to the Java Virtual Machine (JVM), it long ago branched out into other languages such as Python, Javascript, .NET, GO, and others. To compound upon that diversity, it is also seeing extensive support from different graph systems which have chosen TinkerPop as their standard method for allowing users to interface with their graph. Moreover, the graph systems themselves are not only separated by OLTP and OLAP style workloads, but also by their implementation patterns, which range everywhere from being an embedded graph system to a cloud-only graph. One might even find diversity parallel to Gremlin if considering other graph query languages.

Despite all this diversity and disparity, Gremlin remains the unifying interface for all these different elements of the graph community. As a user, choosing a TinkerPop-enabled graph and using Gremlin in the correct way when building applications shields them from change and disparity in the space. As a graph provider, choosing to become TinkerPop-enabled not only expands the reach their system can get into different development ecosystems, but also provides access to other query languages through bytecode compilation as seen in sparql-gremlin.
Irrespective of the programming language being used, graph system chosen or other development background that might be driving a user to this documentation, the critical point to remember is that "Gremlin is Gremlin is Gremlin". The same Gremlin that is written for an OLTP query over an in-memory TinkerGraph is the same Gremlin that is written to execute over a multi-billion edge graph using OLAP through Spark. That same Gremlin for either of those cases is written in the same way whether using Java or Python or Javascript. The Gremlin is always fundamentally the same aside from syntactical differences that might be language specific - e.g. the construction of a lambda in Groovy is different than the construction of a lambda in Python or a reserved word in Javascript forces a Gremlin step to have slightly different naming than Java.
While learning the Gremlin language and its patterns is largely agnostic to all the diversity in the space, it is not really possible to ignore the impact of the diversity from an application development perspective and the Reference Documentation makes an effort to try to point out where differences and inconsistencies might lie without diving too deeply into specific graph provider implementations. Users are strongly encouraged to consult the documentation of their chosen graph provider to understand all of the capabilities and limitations that may restrict or inhibit usage of certain aspects of TinkerPop APIs which are defined here in this Reference Documentation.
The following introductory sections and separately referenced content will be of varying interest to different readers. The summaries below will hopefully be helpful in directing individuals to the appropriate place to start their learning process.
-
Graph Computing is an introduction to what "graph computing" means to TinkerPop and describes many of the provider and user-facing TinkerPop APIs and concepts that enable Gremlin.
-
Connecting Gremlin provides descriptions for the different modes by which users will connect to graphs depending on their environment.
-
Basic Gremlin describes how to use a connection to start writing Gremlin.
-
Staying Agnostic provides tips on ways to keep Gremlin as portable as possible among different graph providers.
New users should not ignore TinkerPop’s Getting Started tutorial or The Gremlin Console tutorial. Both contain a large set of basic information and tips that can help readers avoid some general pitfalls early on. Both also focus on Gremlin usage in the Gremlin Console, which tends to be a critical tool for Gremlin developers of any development background.
More advanced and experience users will appreciate Gremlin Recipes which provide examples of common Gremlin traversal patterns.
Finally, all Gremlin developers should become familiar with "Practical Gremlin" by Kelvin Lawrence. This book is freely available and published online. It contains great examples and details that are applicable to anyone building applications with Gremlin.
Graph Computing

A graph is a data structure composed of vertices (nodes, dots) and edges (arcs, lines). When modeling a graph in a computer and applying it to modern data sets and practices, the generic mathematically-oriented, binary graph is extended to support both labels and key/value properties. This structure is known as a property graph. More formally, it is a directed, binary, attributed multi-graph. An example property graph is diagrammed below.

|
Tip
|
Get to know this graph structure as it is used extensively throughout the documentation and in wider circles as well. It is referred to as "TinkerPop Modern" as it is a modern variation of the original demo graph distributed with TinkerPop0 back in 2009 (i.e. the good ol' days — it was the best of times and it was the worst of times). |
|
Tip
|
All of the toy graphs available in TinkerPop are described in The Gremlin Console tutorial. |
Similar to computing in general, graph computing makes a distinction between structure (graph) and process (traversal). The structure of the graph is the data model defined by a vertex/edge/property topology. The process of the graph is the means by which the structure is analyzed. The typical form of graph processing is called a traversal.
 TinkerPop’s role in graph computing is to provide the appropriate
interfaces for graph providers and users to interact with graphs over
their structure and process. When a graph system implements the TinkerPop structure and process
APIs, their technology is considered
TinkerPop-enabled and becomes nearly indistinguishable from any other TinkerPop-enabled graph system save for their
respective time and space complexity. The purpose of this documentation is to describe the structure/process dichotomy
at length and in doing so, explain how to leverage TinkerPop for the sole purpose of graph system-agnostic graph
computing.
TinkerPop’s role in graph computing is to provide the appropriate
interfaces for graph providers and users to interact with graphs over
their structure and process. When a graph system implements the TinkerPop structure and process
APIs, their technology is considered
TinkerPop-enabled and becomes nearly indistinguishable from any other TinkerPop-enabled graph system save for their
respective time and space complexity. The purpose of this documentation is to describe the structure/process dichotomy
at length and in doing so, explain how to leverage TinkerPop for the sole purpose of graph system-agnostic graph
computing.
|
Important
|
TinkerPop is licensed under the popular Apache2 free software license. However, note that the underlying graph engine used with TinkerPop may have a different license. Thus, be sure to respect the license caveats of the graph system product. |
Generally speaking, the structure or "graph" API is meant for graph providers who are implementing the TinkerPop interfaces and the process or "traversal" API (i.e. Gremlin) is meant for end-users who are utilizing a graph system from a graph provider. While the components of the process API are itemized below, they are described in greater detail in the Gremlin’s Anatomy tutorial.
-
Graph: maintains a set of vertices and edges, and access to database functions such as transactions. -
Element: maintains a collection of properties and a string label denoting the element type.-
Vertex: extends Element and maintains a set of incoming and outgoing edges. -
Edge: extends Element and maintains an incoming and outgoing vertex.
-
-
Property<V>: a string key associated with aVvalue.-
VertexProperty<V>: a string key associated with aVvalue as well as a collection ofProperty<U>properties (vertices only)
-
-
TraversalSource: a generator of traversals for a particular graph, domain specific language (DSL), and execution engine.-
Traversal<S,E>: a functional data flow process transforming objects of typeSinto object of typeE.-
GraphTraversal: a traversal DSL that is oriented towards the semantics of the raw graph (i.e. vertices, edges, etc.).
-
-
-
GraphComputer: a system that processes the graph in parallel and potentially, distributed over a multi-machine cluster.-
VertexProgram: code executed at all vertices in a logically parallel manner with intercommunication via message passing. -
MapReduce: a computation that analyzes all vertices in the graph in parallel and yields a single reduced result.
-
|
Note
|
The TinkerPop API rides a fine line between providing concise "query language" method names and respecting
Java method naming standards. The general convention used throughout TinkerPop is that if a method is "user exposed,"
then a concise name is provided (e.g. out(), path(), repeat()). If the method is primarily for graph systems
providers, then the standard Java naming convention is followed (e.g. getNextStep(), getSteps(),
getElementComputeKeys()).
|
The Graph Structure
 A graph’s structure is the topology formed by the explicit references
between its vertices, edges, and properties. A vertex has incident edges. A vertex is adjacent to another vertex if
they share an incident edge. A property is attached to an element and an element has a set of properties. A property
is a key/value pair, where the key is always a character
A graph’s structure is the topology formed by the explicit references
between its vertices, edges, and properties. A vertex has incident edges. A vertex is adjacent to another vertex if
they share an incident edge. A property is attached to an element and an element has a set of properties. A property
is a key/value pair, where the key is always a character String. Conceptual knowledge of how a graph is composed is
essential to end-users working with graphs, however, as mentioned earlier, the structure API is not the appropriate
way for users to think when building applications with TinkerPop. The structure API is reserved for usage by graph
providers. Those interested in implementing the structure API to make their graph system TinkerPop enabled can learn
more about it in the Graph Provider documentation.
The Graph Process
 The primary way in which graphs are processed are via graph
traversals. The TinkerPop process API is focused on allowing users to create graph traversals in a
syntactically-friendly way over the structures defined in the previous section. A traversal is an algorithmic walk
across the elements of a graph according to the referential structure explicit within the graph data structure.
For example: "What software does vertex 1’s friends work on?" This English-statement can be represented in the
following algorithmic/traversal fashion:
The primary way in which graphs are processed are via graph
traversals. The TinkerPop process API is focused on allowing users to create graph traversals in a
syntactically-friendly way over the structures defined in the previous section. A traversal is an algorithmic walk
across the elements of a graph according to the referential structure explicit within the graph data structure.
For example: "What software does vertex 1’s friends work on?" This English-statement can be represented in the
following algorithmic/traversal fashion:
-
Start at vertex 1.
-
Walk the incident knows-edges to the respective adjacent friend vertices of 1.
-
Move from those friend-vertices to software-vertices via created-edges.
-
Finally, select the name-property value of the current software-vertices.
Traversals in Gremlin are spawned from a TraversalSource. The GraphTraversalSource is the typical "graph-oriented"
DSL used throughout the documentation and will most likely be the most used DSL in a TinkerPop application.
GraphTraversalSource provides two traversal methods.
-
GraphTraversalSource.V(Object… ids): generates a traversal starting at vertices in the graph (if no ids are provided, all vertices). -
GraphTraversalSource.E(Object… ids): generates a traversal starting at edges in the graph (if no ids are provided, all edges).
The return type of V() and E() is a GraphTraversal. A GraphTraversal maintains numerous methods that return
GraphTraversal. In this way, a GraphTraversal supports function composition. Each method of GraphTraversal is
called a step and each step modulates the results of the previous step in one of five general ways.
-
map: transform the incoming traverser’s object to another object (S → E). -
flatMap: transform the incoming traverser’s object to an iterator of other objects (S → E*). -
filter: allow or disallow the traverser from proceeding to the next step (S → E ⊆ S). -
sideEffect: allow the traverser to proceed unchanged, but yield some computational sideEffect in the process (S ↬ S). -
branch: split the traverser and send each to an arbitrary location in the traversal (S → { S1 → E*, …, Sn → E* } → E*).
Nearly every step in GraphTraversal either extends MapStep, FlatMapStep, FilterStep, SideEffectStep, or
BranchStep.
|
Tip
|
GraphTraversal is a monoid in that it is an algebraic structure
that has a single binary operation that is associative. The binary operation is function composition (i.e. method
chaining) and its identity is the step identity(). This is related to a
monad as popularized by the functional programming
community.
|
Given the TinkerPop graph, the following query will return the names of all the people that the marko-vertex knows. The following query is demonstrated using Gremlin-Groovy.
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
gremlin> graph = TinkerFactory.createModern() // //1
==>tinkergraph[vertices:6 edges:6]
gremlin> g = traversal().with(graph) // //2
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V().has('name','marko').out('knows').values('name') // //3
==>vadas
==>josh-
Open the toy graph and reference it by the variable
graph. -
Create a graph traversal source from the graph using the standard, OLTP traversal engine. This object should be created once and then re-used.
-
Spawn a traversal off the traversal source that determines the names of the people that the marko-vertex knows.

Or, if the marko-vertex is already realized with a direct reference pointer (i.e. a variable), then the traversal can be spawned off that vertex.
gremlin> marko = g.V().has('name','marko').next() //// (1)
==>v[1]
gremlin> g.V(marko).out('knows') //// (2)
==>v[2]
==>v[4]
gremlin> g.V(marko).out('knows').values('name') //// (3)
==>vadas
==>joshmarko = g.V().has('name','marko').next() //// (1)
g.V(marko).out('knows') //// (2)
g.V(marko).out('knows').values('name') //3-
Set the variable
markoto the vertex in the graphgnamed "marko". -
Get the vertices that are outgoing adjacent to the marko-vertex via knows-edges.
-
Get the names of the marko-vertex’s friends.
The Traverser
When a traversal is executed, the source of the traversal is on the left of the expression (e.g. vertex 1), the steps
are the middle of the traversal (e.g. out('knows') and values('name')), and the results are "traversal.next()'d"
out of the right of the traversal (e.g. "vadas" and "josh").

The objects propagating through the traversal are wrapped in a Traverser<T>. The traverser provides the means by
which steps remain stateless. A traverser maintains all the metadata about the traversal — e.g., how many times the
traverser has gone through a loop, the path history of the traverser, the current object being traversed, etc.
Traverser metadata may be accessed by a step. A classic example is the path()-step.
gremlin> g.V(marko).out('knows').values('name').path()
==>[v[1],v[2],vadas]
==>[v[1],v[4],josh]g.V(marko).out('knows').values('name').path()|
Warning
|
Path calculation is costly in terms of space as an array of previously seen objects is stored in each path of the respective traverser. Thus, a traversal strategy analyzes the traversal to determine if path metadata is required. If not, then path calculations are turned off. |
Another example is the repeat()-step which takes into account the number of times the traverser
has gone through a particular section of the traversal expression (i.e. a loop).
gremlin> g.V(marko).repeat(out()).times(2).values('name')
==>ripple
==>lopg.V(marko).repeat(out()).times(2).values('name')|
Warning
|
TinkerPop does not guarantee the order of results returned from a traversal. It only guarantees not to modify
the iteration order provided by the underlying graph. Therefore it is important to understand the order guarantees of
the graph database being used. A traversal’s result is never ordered by TinkerPop unless performed explicitly by means
of order()-step.
|
Connecting Gremlin
It was established in the initial introductory section that Gremlin is Gremlin is Gremlin, meaning that irrespective of programming language, graph system, etc. the Gremlin written is always of the same general construct making it possible for users to move between development languages and TinkerPop-enabled graph technology easily. This quality of Gremlin generally applies to the traversal language itself. It applies less to the way in which the user connects to a graph to utilize Gremlin, which might differ considerably depending on the programming language or graph database chosen.
How one connects to a graph is a multi-faceted subject that essentially divides along a simple lines determined by the answer to this question: Where is the Gremlin Traversal Machine (GTM)? The reason that this question is so important is because the GTM is responsible for processing traversals. One can write Gremlin traversals in any language, but without a GTM there will be no way to execute that traversal against a TinkerPop-enabled graph. The GTM is typically in one of the following places:
The following sections outline each of these models and what impact they have to using Gremlin.
Embedded
 TinkerPop maintains the reference implementation for the GTM,
which is written in Java and thus available for the Java Virtual Machine (JVM). This is the classic model that
TinkerPop has long been based on and many examples, blog posts and other resources on the internet will be
demonstrated in this style. It is worth noting that the embedded mode is not restricted to just Java as a programming
language. Any JVM language can take this approach and in some cases there are language specific wrappers that can help
make Gremlin more convenient to use in the style and capability of that language. Examples of these wrappers include
gremlin-scala and Ogre (for Clojure).
TinkerPop maintains the reference implementation for the GTM,
which is written in Java and thus available for the Java Virtual Machine (JVM). This is the classic model that
TinkerPop has long been based on and many examples, blog posts and other resources on the internet will be
demonstrated in this style. It is worth noting that the embedded mode is not restricted to just Java as a programming
language. Any JVM language can take this approach and in some cases there are language specific wrappers that can help
make Gremlin more convenient to use in the style and capability of that language. Examples of these wrappers include
gremlin-scala and Ogre (for Clojure).
In this mode, users will start by creating a Graph instance, followed by a GraphTraversalSource which is the class
from which Gremlin traversals are spawned. Graphs that allow this sort of direct instantiation are obviously ones
that are JVM-based (or have a JVM-based connector) and directly implement TinkerPop interfaces.
Graph graph = TinkerGraph.open();The "graph" is then used to spawn a GraphTraversalSource as follows and typically, by convention, this variable is
named "g":
GraphTraversalSource g = traversal().with(graph);
List<Vertex> vertices = g.V().toList()|
Note
|
It may be helpful to read the Gremlin Anatomy tutorial, which describes the component parts of Gremlin to get a better understanding of the terminology before proceeding further. |
While the TinkerPop Community strives to ensure consistent behavior among all modes of usage, the embedded mode does provide the greatest level of flexibility and control. There are a number of features that can only work if using a JVM language. The following list outlines a number of these available options:
-
Lambdas can be written in the native language which is convenient, however, it will reduce the portability of Gremlin to do so should the need arise to switch away from the embedded mode. See more in the Note on Lambdas Section.
-
Any features that involve extending TinkerPop Java interfaces - e.g.
VertexProgram,TraversalStrategy, etc. are bound to the JVM. In some cases, these features can be made accessible to non-JVM languages, but they obviously must be initially developed for the JVM. -
Certain built-in
TraversalStrategyimplementations that rely on lambdas or other JVM-only configurations may not be available for use any other way. -
There are no boundaries put in place by serialization (e.g. GraphSON) as embedded graphs are only dealing with Java objects.
-
Greater control of graph transactions.
-
Direct access to lower-levels of the API - e.g. "structure" API methods like
VertexandEdgeinterface methods. As mentioned elsewhere in this documentation, TinkerPop does not recommend direct usage of these methods by end-users.
Gremlin Server
 A JVM-based graph may be hosted in TinkerPop’s
Gremlin Server. Gremlin Server exposes the graph as an endpoint to which different clients can
connect, essentially providing a remote GTM. Gremlin Server supports multiple methods for clients to interface with it:
A JVM-based graph may be hosted in TinkerPop’s
Gremlin Server. Gremlin Server exposes the graph as an endpoint to which different clients can
connect, essentially providing a remote GTM. Gremlin Server supports multiple methods for clients to interface with it:
-
HTTP for string-based scripts (both gremlin-lang and gremlin-groovy)
Connecting looks somewhat similar to the embedded approach in that there is a need to create a
GraphTraversalSource. In the embedded approach, the means for that object’s creation is derived from a Graph object
which spawns it. In this case, however, the Graph instance exists only on the server which means that there is no
Graph instance to create locally. The approach is to instead create a GraphTraversalSource anonymously with
AnonymousTraversalSource and then apply some "remote" options that describe the location of the Gremlin Server to
connect to:
// gremlin-driver module
import org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection;
// gremlin-core module
import static org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;
GraphTraversalSource g = traversal().with(
DriverRemoteConnection.using("localhost", 8182));// gremlin-driver module
import org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection;
// gremlin-core module
import static org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;
def g = traversal().with(
DriverRemoteConnection.using('localhost', 8182))from gremlin_python.process.anonymous_traversal_source import traversal
g = traversal().with(
DriverRemoteConnection('ws://localhost:8182/gremlin'))As shown in the embedded approach in the previous section, once "g" is defined, writing Gremlin is structurally and conceptually the same irrespective of programming language.
|
Tip
|
The variable g, the TraversalSource, only needs to be instantiated once and should then be re-used.
|
Limitations
The previous section on the embedded model outlined a number of areas where it has some advantages that it gains due to the fact that the full GTM is available to the user in the language of its origin, i.e. Java. Some of those items touch upon important concepts to focus on here.
The first of these points is serialization. When Gremlin Server receives a request, the results must be serialized to the form requested by the client and then the client deserializes those into objects native to the language. TinkerPop has two such formats that it uses with GraphBinary and GraphSON. Users should prefer GraphBinary when available in the programming language being used.
|
Important
|
4.0 Milestone Release - There is temporary support for GraphSON in the Java driver which will help with testing, but it is expected that the drivers will only support GraphBinary when 4.0 is fully released. |
A good example is the subgraph()-step which returns a Graph instance as its result. The subgraph returned from
the server can be deserialized into an actual Graph instance on the client, which then means it is possible to
spawn a GraphTraversalSource from that to do local Gremlin traversals on the client-side. For non-JVM
Gremlin Language Variants there is no local graph to deserialize that result into and
no GTM to process Gremlin so there isn’t much that can be done with such a result.
The second point is related to this issue. As there is no GTM, there is no "structure" API and thus graph elements like
Vertex and Edge are usually "references". A "reference" means that they only contain the id and label of the
element and not the properties. To be consistent, even JVM-based languages hold this limitation when talking to a
remote Gremlin Server. However, you can alternatively get a "detached" element when using the all option for
materializeProperties. In this case, the element will contain all of its properties, but will not be connected to any
other element.
|
Important
|
Most SQL developers would not write a query as SELECT * FROM table. They would instead write the
individual names of the fields they wanted in place of the wildcard. Writing "good" Gremlin is no different with this
regard. Prefer explicit property key names in Gremlin unless it is completely impossible to do so.
|
The third and final point involves transactions. Under this model, one traversal is equivalent to a single transaction and there is no way in TinkerPop to string together multiple traversals into the same transaction.
|
Important
|
4.0 Milestone Release - Remote transactions are not supported in this milestone. |
Remote Gremlin Provider
Remote Gremlin Providers (RGPs) are showing up more and more often in the graph database space. In TinkerPop terms, this category of graph providers is defined by those who simply support the Gremlin language. Typically, these are server-based graphs, often cloud-based, which accept Gremlin scripts as a request and return results. They will often implement Gremlin Server protocols, which enables TinkerPop drivers to connect to them as they would with Gremlin Server. Therefore, the typical connection approach is identical to the method of connection presented in the previous section with the exact same caveats pointed out toward the end.
Despite leveraging TinkerPop protocols and drivers as being typical, RGPs are not required to do so to be considered TinkerPop-enabled. RGPs may well have their own drivers and protocols that may plug into Gremlin Language Variants and may allow for more advanced options like better security, cluster awareness, batched requests or other features. The details of these different systems are outside the scope of this documentation, so be sure to consult their documentation for more information.
Basic Gremlin
 The
The GraphTraversalSource is basically the connection to a graph
instance. That graph instance might be embedded, hosted in
Gremlin Server or hosted in a RGP, but the GraphTraversalSource is
agnostic to that. Assuming "g" is the GraphTraversalSource, getting data into the graph regardless of programming
language or mode of operation is just some basic Gremlin:
gremlin> v1 = g.addV('person').property('name','marko').next()
==>v[0]
gremlin> v2 = g.addV('person').property('name','stephen').next()
==>v[2]
gremlin> g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()v1 = g.addV('person').property('name','marko').next()
v2 = g.addV('person').property('name','stephen').next()
g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()Vertex v1 = g.addV("person").property("name","marko").next();
Vertex v2 = g.addV("person").property("name","stephen").next();
g.V(v1).addE("knows").to(v2).property("weight",0.75).iterate();v1 = g.addV('person').property('name','marko').next()
v2 = g.addV('person').property('name','stephen').next()
g.V(v1).addE('knows').to(v2).property('weight',0.75).iterate()The first two lines add a vertex each with the vertex label of "person" and the associated "name" property. The third
line adds an edge with the "knows" label between them and an associated "weight" property. Note the use of next()
and iterate() at the end of the lines - their effect as terminal steps is described in
The Gremlin Console Tutorial.
|
Important
|
Writing Gremlin is just one way to load data into the graph. Some graphs may have special data loaders which could be more efficient and make the task easier and faster. It is worth looking into those tools especially if there is a large one-time load to do. |
Retrieving this data is also a just writing a Gremlin statement:
gremlin> marko = g.V().has('person','name','marko').next()
==>v[0]
gremlin> peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()
==>v[2]marko = g.V().has('person','name','marko').next()
peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()Vertex marko = g.V().has("person","name","marko").next()
List<Vertex> peopleMarkoKnows = g.V().has("person","name","marko").out("knows").toList()marko = g.V().has('person','name','marko').next()
peopleMarkoKnows = g.V().has('person','name','marko').out('knows').toList()In all these examples presented so far there really isn’t a lot of difference in how the Gremlin itself looks. There are a few language syntax specific odds and ends, but for the most part Gremlin looks like Gremlin in all of the different languages.
The library of Gremlin steps with examples for each can be found in The Traversal Section. This section is meant as a reference guide and will not necessarily provide methods for applying Gremlin to solve particular problems. Please see the aforementioned Tutorials Recipes and the Practical Gremlin book for that sort of information.
|
Note
|
A full list of helpful Gremlin resources can be found on the TinkerPop Compendium page. |
Staying Agnostic
A good deal has been written in these introductory sections on how TinkerPop enables an agnostic approach to building graph application and that agnosticism is enabled through Gremlin. As good a job as Gremlin can do in this area, it’s evident from the Connecting Gremlin Section that TinkerPop is just an enabler. It does not prevent a developer from making design choices that can limit its protective power.
There are several places to be concerned when considering this issue:
-
Data types - Different graphs will support different types of data. Something like TinkerGraph will accept any JVM object, but another graph like Neo4j has a small tight subset of possible types. Choosing a type that is exotic or perhaps is a custom type that only a specific graph supports might create migration friction should the need arise.
-
Schemas/Indices - TinkerPop does not provide abstractions for schemas and/or index management. Users will work directly with the API of the graph provider. It is considered good practice to attempt to enclose such code in a graph provider specific class or set of classes to isolate or abstract it.
-
Extensions - Graphs may provide extensions to the Gremlin language, which will not be designed to be compatible with other graph providers. There may be a special helper syntax or expressions which can make certain features of that specific graph shine in powerful ways. Using those options is probably recommended, but users should be aware that doing so ties them more tightly to that graph.
-
Graph specific semantics - TinkerPop tries to enforce specific semantics through its test suite which is quite extensive, but some graph providers may not completely respect all the semantics of the Gremlin language or TinkerPop’s model for its APIs. For the most part, that doesn’t disqualify them from being any less TinkerPop-enabled than another provider that might meet the semantics perfectly. Take care when considering a new graph and pay attention to what it supports and does not support.
-
Graph API - The Graph API (also referred to as the Structure API) is not always accessible to users. Its accessibility is dependent on the choice of graph system and programming language. It is therefore recommended that users avoid usage of methods like
Graph.addVertex()orVertex.properties()and instead prefer use of Gremlin withg.addV()org.V(1).properties().
Outside of considering these points, the best practice for ensuring the greatest level of compatibility across graphs
is to avoid embedded mode and stick to the traversal-based approaches explained in the
Gremlin Server and the RGP sections above. It creates the least
opportunity to stray from the agnostic path as anything that can be done with those two modes also works in embedded
mode. If using embedded mode, simply write code as though the Graph instance is "remote" and not local to the JVM.
In other words, write code as though the GTM is not available locally. Taking that approach and isolating the points
of concern above makes it so that swapping graph providers largely comes down to a configuration task (i.e. modifying
configuration files to point at a different graph system).
The Graph
The Introduction discussed the diversity of TinkerPop-enabled graphs, with special attention paid to the
different connection models, and how TinkerPop makes it possible to bridge that diversity in
an agnostic manner. This particular section deals with elements of the Graph API which was noted
as an API to avoid when trying to build an agnostic system. The Graph API refers to the core elements of what composes
the structure of a graph within the Gremlin Traversal Machine (GTM), such as the Graph, Vertex
and Edge Java interfaces.
To maintain the most portable code, users should only reference these interfaces. To "reference", simply means to
utilize it as a pointer. For Graph, that means holding a pointer to the location of graph data and then using it to
spawn GraphTraversalSource instances so as to write Gremlin:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.addV('person')
==>v[0]graph = TinkerGraph.open()
g = traversal().with(graph)
g.addV('person')In the above example, "graph" is the Graph interface produced by calling open() on TinkerGraph which creates the
instance. Note that while the end intent of the code is to create a "person" vertex, it does not use the APIs on
Graph to do that - e.g. graph.addVertex(T.label,'person').
Even if the developer desired to use the graph.addVertex() method there are only a handful of scenarios where it is
possible:
-
The application is being developed on the JVM and the developer is using embedded mode
-
The architecture includes Gremlin Server and the user is sending Gremlin scripts to the server
-
The graph system chosen is a Remote Gremlin Provider and they expose the Graph API via scripts
Note that Gremlin Language Variants force developers to use the Graph API by reference. There is no addVertex()
method available to GLVs on their respective Graph instances, nor are their graph elements filled with data at the
call of properties(). Developing applications to meet this lowest common denominator in API usage will go a long
way to making that application portable across TinkerPop-enabled systems.
When considering the remaining sub-sections that follow, recall that they are all generally bound to the Graph API. They are described here for reference and in some sense backward compatibility with older recommended models of development. In the future, the contents of this section will become less and less relevant.
Features
A Feature implementation describes the capabilities of a Graph instance. This interface is implemented by graph
system providers for two purposes:
-
It tells users the capabilities of their
Graphinstance. -
It allows the features they do comply with to be tested against the Gremlin Test Suite - tests that do not comply are "ignored").
The following example in the Gremlin Console shows how to print all the features of a Graph:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> graph.features()
==>FEATURES
> GraphFeatures
>-- Transactions: false
>-- Computer: true
>-- Persistence: true
>-- ConcurrentAccess: false
>-- ThreadedTransactions: false
>-- IoRead: true
>-- IoWrite: true
>-- OrderabilitySemantics: true
>-- ServiceCall: true
> VariableFeatures
>-- Variables: true
>-- DoubleValues: true
>-- FloatValues: true
>-- IntegerValues: true
>-- LongValues: true
>-- MapValues: true
>-- MixedListValues: true
>-- SerializableValues: true
>-- StringValues: true
>-- UniformListValues: true
>-- BooleanArrayValues: true
>-- ByteArrayValues: true
>-- DoubleArrayValues: true
>-- FloatArrayValues: true
>-- IntegerArrayValues: true
>-- LongArrayValues: true
>-- StringArrayValues: true
>-- BooleanValues: true
>-- ByteValues: true
> VertexFeatures
>-- MetaProperties: true
>-- Upsert: false
>-- AddVertices: true
>-- RemoveVertices: true
>-- MultiProperties: true
>-- DuplicateMultiProperties: true
>-- NullPropertyValues: false
>-- UserSuppliedIds: true
>-- AddProperty: true
>-- RemoveProperty: true
>-- NumericIds: true
>-- StringIds: true
>-- UuidIds: true
>-- CustomIds: false
>-- AnyIds: true
> VertexPropertyFeatures
>-- NullPropertyValues: false
>-- UserSuppliedIds: true
>-- RemoveProperty: true
>-- NumericIds: true
>-- StringIds: true
>-- UuidIds: true
>-- CustomIds: false
>-- AnyIds: true
>-- Properties: true
>-- DoubleValues: true
>-- FloatValues: true
>-- IntegerValues: true
>-- LongValues: true
>-- MapValues: true
>-- MixedListValues: true
>-- SerializableValues: true
>-- StringValues: true
>-- UniformListValues: true
>-- BooleanArrayValues: true
>-- ByteArrayValues: true
>-- DoubleArrayValues: true
>-- FloatArrayValues: true
>-- IntegerArrayValues: true
>-- LongArrayValues: true
>-- StringArrayValues: true
>-- BooleanValues: true
>-- ByteValues: true
> EdgeFeatures
>-- AddEdges: true
>-- RemoveEdges: true
>-- Upsert: false
>-- NullPropertyValues: false
>-- UserSuppliedIds: true
>-- AddProperty: true
>-- RemoveProperty: true
>-- NumericIds: true
>-- StringIds: true
>-- UuidIds: true
>-- CustomIds: false
>-- AnyIds: true
> EdgePropertyFeatures
>-- Properties: true
>-- DoubleValues: true
>-- FloatValues: true
>-- IntegerValues: true
>-- LongValues: true
>-- MapValues: true
>-- MixedListValues: true
>-- SerializableValues: true
>-- StringValues: true
>-- UniformListValues: true
>-- BooleanArrayValues: true
>-- ByteArrayValues: true
>-- DoubleArrayValues: true
>-- FloatArrayValues: true
>-- IntegerArrayValues: true
>-- LongArrayValues: true
>-- StringArrayValues: true
>-- BooleanValues: true
>-- ByteValues: truegraph = TinkerGraph.open()
graph.features()A common pattern for using features is to check their support prior to performing an operation:
gremlin> graph.features().graph().supportsTransactions()
==>false
gremlin> graph.features().graph().supportsTransactions() ? g.tx().commit() : "no tx"
==>no txgraph.features().graph().supportsTransactions()
graph.features().graph().supportsTransactions() ? g.tx().commit() : "no tx"|
Tip
|
To ensure provider agnostic code, always check feature support prior to usage of a particular function. In that way, the application can behave gracefully in case a particular implementation is provided at runtime that does not support a function being accessed. |
|
Warning
|
Features of reference graphs which are used to connect to remote graphs do not reflect the features of the graph to which it connects. It reflects the features of instantiated graph itself, which will likely be quite different considering that reference graphs will typically be immutable. |
Vertex Properties
 TinkerPop introduces the concept of a
TinkerPop introduces the concept of a VertexProperty<V>. All the
properties of a Vertex are a VertexProperty. A VertexProperty implements Property and as such, it has a
key/value pair. However, VertexProperty also implements Element and thus, can have a collection of key/value
pairs. Moreover, while an Edge can only have one property of key "name" (for example), a Vertex can have multiple
"name" properties. With the inclusion of vertex properties, two features are introduced which ultimately advance the
graph modelers toolkit:
-
Multiple properties (multi-properties): a vertex property key can have multiple values. For example, a vertex can have multiple "name" properties.
-
Properties on properties (meta-properties): a vertex property can have properties (i.e. a vertex property can have key/value data associated with it).
Possible use cases for meta-properties:
-
Permissions: Vertex properties can have key/value ACL-type permission information associated with them.
-
Auditing: When a vertex property is manipulated, it can have key/value information attached to it saying who the creator, deletor, etc. are.
-
Provenance: The "name" of a vertex can be declared by multiple users. For example, there may be multiple spellings of a name from different sources.
A running example using vertex properties is provided below to demonstrate and explain the API.
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> v = g.addV().property('name','marko').property('name','marko a. rodriguez').next()
==>v[0]
gremlin> g.V(v).properties('name').count() //// (1)
==>2
gremlin> v.property(list, 'name', 'm. a. rodriguez') //// (2)
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties('name').count()
==>3
gremlin> g.V(v).properties()
==>vp[name->marko]
==>vp[name->marko a. rodriguez]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties('name')
==>vp[name->marko]
==>vp[name->marko a. rodriguez]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties('name').hasValue('marko')
==>vp[name->marko]
gremlin> g.V(v).properties('name').hasValue('marko').property('acl','private') //// (3)
==>vp[name->marko]
gremlin> g.V(v).properties('name').hasValue('marko a. rodriguez')
==>vp[name->marko a. rodriguez]
gremlin> g.V(v).properties('name').hasValue('marko a. rodriguez').property('acl','public')
==>vp[name->marko a. rodriguez]
gremlin> g.V(v).properties('name').has('acl','public').value()
==>marko a. rodriguez
gremlin> g.V(v).properties('name').has('acl','public').drop() //// (4)
gremlin> g.V(v).properties('name').has('acl','public').value()
gremlin> g.V(v).properties('name').has('acl','private').value()
==>marko
gremlin> g.V(v).properties()
==>vp[name->marko]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties().properties() //// (5)
==>p[acl->private]
gremlin> g.V(v).properties().property('date',2014) //// (6)
==>vp[name->marko]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties().property('creator','stephen')
==>vp[name->marko]
==>vp[name->m. a. rodriguez]
gremlin> g.V(v).properties().properties()
==>p[date->2014]
==>p[creator->stephen]
==>p[acl->private]
==>p[date->2014]
==>p[creator->stephen]
gremlin> g.V(v).properties('name').valueMap()
==>[date:2014,creator:stephen,acl:private]
==>[date:2014,creator:stephen]
gremlin> g.V(v).property('name','okram') //// (7)
==>v[0]
gremlin> g.V(v).properties('name')
==>vp[name->okram]
gremlin> g.V(v).values('name') //// (8)
==>okramgraph = TinkerGraph.open()
g = traversal().with(graph)
v = g.addV().property('name','marko').property('name','marko a. rodriguez').next()
g.V(v).properties('name').count() //// (1)
v.property(list, 'name', 'm. a. rodriguez') //// (2)
g.V(v).properties('name').count()
g.V(v).properties()
g.V(v).properties('name')
g.V(v).properties('name').hasValue('marko')
g.V(v).properties('name').hasValue('marko').property('acl','private') //// (3)
g.V(v).properties('name').hasValue('marko a. rodriguez')
g.V(v).properties('name').hasValue('marko a. rodriguez').property('acl','public')
g.V(v).properties('name').has('acl','public').value()
g.V(v).properties('name').has('acl','public').drop() //// (4)
g.V(v).properties('name').has('acl','public').value()
g.V(v).properties('name').has('acl','private').value()
g.V(v).properties()
g.V(v).properties().properties() //// (5)
g.V(v).properties().property('date',2014) //// (6)
g.V(v).properties().property('creator','stephen')
g.V(v).properties().properties()
g.V(v).properties('name').valueMap()
g.V(v).property('name','okram') //// (7)
g.V(v).properties('name')
g.V(v).values('name') //8-
A vertex can have zero or more properties with the same key associated with it.
-
If a property is added with a cardinality of
Cardinality.list, an additional property with the provided key will be added. -
A vertex property can have standard key/value properties attached to it.
-
Vertex property removal is identical to property removal.
-
Gets the meta-properties of each vertex property.
-
A vertex property can have any number of key/value properties attached to it.
-
property(…)will remove all existing key’d properties before adding the new single property (seeVertexProperty.Cardinality). -
If only the value of a property is needed, then
values()can be used.
If the concept of vertex properties is difficult to grasp, then it may be best to think of vertex properties in terms of "literal vertices." A vertex can have an edge to a "literal vertex" that has a single value key/value — e.g. "value=okram." The edge that points to that literal vertex has an edge-label of "name." The properties on the edge represent the literal vertex’s properties. The "literal vertex" can not have any other edges to it (only one from the associated vertex).
|
Tip
|
A toy graph demonstrating all of the new TinkerPop graph structure features is available at
TinkerFactory.createTheCrew() and data/tinkerpop-crew*. This graph demonstrates multi-properties and meta-properties.
|

gremlin> g.V().as('a').
properties('location').as('b').
hasNot('endTime').as('c').
select('a','b','c').by('name').by(value).by('startTime') // determine the current location of each person
==>[a:marko,b:santa fe,c:2005]
==>[a:stephen,b:purcellville,c:2006]
==>[a:matthias,b:seattle,c:2014]
==>[a:daniel,b:aachen,c:2009]
gremlin> g.V().has('name','gremlin').inE('uses').
order().by('skill',asc).as('a').
outV().as('b').
select('a','b').by('skill').by('name') // rank the users of gremlin by their skill level
==>[a:3,b:matthias]
==>[a:4,b:marko]
==>[a:5,b:stephen]
==>[a:5,b:daniel]g.V().as('a').
properties('location').as('b').
hasNot('endTime').as('c').
select('a','b','c').by('name').by(value).by('startTime') // determine the current location of each person
g.V().has('name','gremlin').inE('uses').
order().by('skill',asc).as('a').
outV().as('b').
select('a','b').by('skill').by('name') // rank the users of gremlin by their skill levelGraph Variables
Graph.Variables are key/value pairs associated with the graph itself — in essence, a Map<String,Object>. These
variables are intended to store metadata about the graph. Example use cases include:
-
Schema information: What do the namespace prefixes resolve to and when was the schema last modified?
-
Global permissions: What are the access rights for particular groups?
-
System user information: Who are the admins of the system?
An example of graph variables in use is presented below:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> graph.variables()
==>variables[size:0]
gremlin> graph.variables().set('systemAdmins',['stephen','peter','pavel'])
==>null
gremlin> graph.variables().set('systemUsers',['matthias','marko','josh'])
==>null
gremlin> graph.variables().keys()
==>systemAdmins
==>systemUsers
gremlin> graph.variables().get('systemUsers')
==>Optional[[matthias, marko, josh]]
gremlin> graph.variables().get('systemUsers').get()
==>matthias
==>marko
==>josh
gremlin> graph.variables().remove('systemAdmins')
==>null
gremlin> graph.variables().keys()
==>systemUsersgraph = TinkerGraph.open()
graph.variables()
graph.variables().set('systemAdmins',['stephen','peter','pavel'])
graph.variables().set('systemUsers',['matthias','marko','josh'])
graph.variables().keys()
graph.variables().get('systemUsers')
graph.variables().get('systemUsers').get()
graph.variables().remove('systemAdmins')
graph.variables().keys()|
Important
|
Graph variables are not intended to be subject to heavy, concurrent mutation nor to be used in complex computations. The intention is to have a location to store data about the graph for administrative purposes. |
|
Warning
|
Attempting to set graph variables in a reference graph will not promote them to the remote graph. Typically, a reference graph has immutable features and will not support this features. |
Namespace Conventions
End users, graph system providers, GraphComputer algorithm designers,
GremlinPlugin creators, etc. all leverage properties on elements to store information. There are
a few conventions that should be respected when naming property keys to ensure that conflicts between these
stakeholders do not conflict.
-
End users are granted the flat namespace (e.g.
name,age,location) to key their properties and label their elements. -
Graph system providers are granted the hidden namespace (e.g.
~metadata) to key their properties and labels. Data keyed as such is only accessible via the graph system implementation and no other stakeholders are granted read nor write access to data prefixed with "~" (seeGraph.Hidden). Test coverage and exceptions exist to ensure that graph systems respect this hard boundary. -
VertexProgramandMapReducedevelopers should leverage qualified namespaces particular to their domain (e.g.mydomain.myvertexprogram.computedata). -
GremlinPlugincreators should prefix their plugin name with their domain (e.g.mydomain.myplugin).
|
Important
|
TinkerPop uses tinkerpop. and gremlin. as the prefixes for provided strategies, vertex programs, map
reduce implementations, and plugins.
|
The only truly protected namespace is the hidden namespace provided to graph systems. From there, it’s up to engineers to respect the namespacing conventions presented.
The Traversal
At the most general level there is Traversal<S,E> which implements Iterator<E>, where the S stands for start and
the E stands for end. A traversal is composed of four primary components:
-
Step<S,E>: an individual function applied toSto yieldE. Steps are chained within a traversal. -
TraversalStrategy: interceptor methods to alter the execution of the traversal (e.g. query re-writing). -
TraversalSideEffects: key/value pairs that can be used to store global information about the traversal. -
Traverser<T>: the object propagating through theTraversalcurrently representing an object of typeT.
The classic notion of a graph traversal is provided by GraphTraversal<S,E> which extends Traversal<S,E>.
GraphTraversal provides an interpretation of the graph data in terms of vertices, edges, etc. and thus, a graph
traversal DSL.

A GraphTraversal<S,E> is spawned from a GraphTraversalSource. It can also be spawned anonymously (i.e. empty)
via __. A graph traversal is composed of an ordered list of steps. All the steps provided by GraphTraversal
inherit from the more general forms diagrammed above. A list of all the steps (and their descriptions) are provided
in the TinkerPop GraphTraversal JavaDoc.
|
Important
|
The basics for starting a traversal are described in The Graph Process section as well as in the Getting Started tutorial. |
|
Note
|
To reduce the verbosity of the expression, it is good to
import static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.*. This way, instead of doing __.inE()
for an anonymous traversal, it is possible to simply write inE(). Be aware of language-specific reserved keywords
when using anonymous traversals. For example, in and as are reserved keywords in Groovy, therefore you must use
the verbose syntax __.in() and __.as() to avoid collisions.
|
|
Important
|
The underlying Step implementations provided by TinkerPop should encompass most of the functionality
required by a DSL author. It is important that DSL authors leverage the provided steps as then the common optimization
and decoration strategies can reason on the underlying traversal sequence. If new steps are introduced, then common
traversal strategies may not function properly.
|
Traversal Transactions
|
Important
|
4.0 Milestone Release - Transactions are currently disabled in this Milestone release. |
 A database transaction
represents a unit of work to execute against the database. A traversals unit of work is affected by usage convention
(i.e. the method of connecting) and the graph provider’s transaction model. Without diving
deeply into different conventions and models the most general and recommended approach to working with transactions is
demonstrated as follows:
A database transaction
represents a unit of work to execute against the database. A traversals unit of work is affected by usage convention
(i.e. the method of connecting) and the graph provider’s transaction model. Without diving
deeply into different conventions and models the most general and recommended approach to working with transactions is
demonstrated as follows:
GraphTraversalSource g = traversal().with(graph);
// or
GraphTraversalSource g = traversal().with(conn);
Transaction tx = g.tx();
// spawn a GraphTraversalSource from the Transaction. Traversals spawned
// from gtx will be essentially be bound to tx
GraphTraversalSource gtx = tx.begin();
try {
gtx.addV('person').iterate();
gtx.addV('software').iterate();
tx.commit();
} catch (Exception ex) {
tx.rollback();
}The above example is straightforward and represents a good starting point for discussing the nuances of transactions in relation to the usage convention and graph provider caveats alluded to earlier.
Focusing on remote contexts first, note that it is still possible to issue traversals from g, but those will have a
transaction scope outside of gtx and will simply commit() on the server if successfully executed or rollback()
on the server otherwise (i.e. one traversal is one transaction). Each isolated transaction will require its own
Transaction object. Multiple begin() calls on the same Transaction object will produce GraphTraversalSource
instances that are bound to the same transaction, therefore:
GraphTraversalSource g = traversal().with(conn);
Transaction tx1 = g.tx();
Transaction tx2 = g.tx();
// both gtx1a and gtx1b will be bound to the same transaction
GraphTraversalSource gtx1a = tx1.begin();
GraphTraversalSource gtx1b = tx1.begin();
// g and gtx2 will not have knowledge of what happens in tx1
GraphTraversalSource gtx2 = tx2.begin();In remote cases, GraphTraversalSource instances spawned from begin() are safe to use in multiple threads though
on the server side they will be processed serially as they arrive. The default behavior of close() on a
Transaction for remote cases is to commit(), so the following re-write of the earlier example is also valid:
// note here that we dispense with creating a Transaction object and
// simply spawn the gtx in a more inline fashion
GraphTraversalSource gtx = g.tx().begin();
try {
gtx.addV('person').iterate();
gtx.addV('software').iterate();
gtx.close();
} catch (Exception ex) {
tx.rollback();
}|
Important
|
Transactions with non-JVM languages are always "remote". For specific transaction syntax in a particular language, please see the "Transactions" sub-section of your language of interest in the Gremlin Drivers and Variants section. |
In embedded cases, that initial recommended model for defining transactions holds, but users have more options here
on deeper inspection. For embedded use cases (and perhaps even in configuration of a graph instance in Gremlin Server),
the type of Transaction object that is returned from g.tx() is an important indicator as to the features of that
graph’s transaction model. In most cases, inspection of that object will indicate an instance that derives from the
AbstractThreadLocalTransaction class, which means that the transaction is bound to the current thread and therefore
all traversals that execute within that thread are tied to that transaction.
A ThreadLocal transaction differs then from the remote case described before because technically any traversal
spawned from g or from a Transaction will fall under the same transaction scope. As a result, it is wise, when
trying to write context agnostic Gremlin, to follow the more rigid conventions of the initial example.
The sub-sections that follow offer a bit more insight into each of the usage contexts.
Embedded
When on the JVM using an embedded graph, there is considerable flexibility for working with
transactions. With the Graph API, transactions are controlled by an implementation of the Transaction interface and
that object can be obtained from the Graph interface using the tx() method. It is important to note that the
Transaction object does not represent a "transaction" itself. It merely exposes the methods for working with
transactions (e.g. committing, rolling back, etc).
Most Graph implementations that supportsTransactions will implement an "automatic" ThreadLocal transaction,
which means that when a read or write occurs after the Graph is instantiated, a transaction is automatically
started within that thread. There is no need to manually call a method to "create" or "start" a transaction. Simply
modify the graph as required and call graph.tx().commit() to apply changes or graph.tx().rollback() to undo them.
When the next read or write action occurs against the graph, a new transaction will be started within that current
thread of execution.
When using transactions in this fashion, especially in web application (e.g. HTTP server), it is important to ensure that transactions do not leak from one request to the next. In other words, unless a client is somehow bound via session to process every request on the same server thread, every request must be committed or rolled back at the end of the request. By ensuring that the request encapsulates a transaction, it ensures that a future request processed on a server thread is starting in a fresh transactional state and will not have access to the remains of one from an earlier request. A good strategy is to rollback a transaction at the start of a request, so that if it so happens that a transactional leak does occur between requests somehow, a fresh transaction is assured by the fresh request.
|
Tip
|
The tx() method is on the Graph interface, but it is also available on the TraversalSource spawned from a
Graph. Calls to TraversalSource.tx() are proxied through to the underlying Graph as a convenience.
|
|
Tip
|
Some graphs may throw an exception that implements TemporaryException. In this case, this marker interface is
designed to inform the client that it may choose to retry the operation at a later time for possible success.
|
|
Warning
|
TinkerPop provides for basic transaction control, however, like many aspects of TinkerPop, it is up to the graph system provider to choose the specific aspects of how their implementation will work and how it fits into the TinkerPop stack. Be sure to understand the transaction semantics of the specific graph implementation that is being utilized as it may present differing functionality than described here. |
Configuring
Determining when a transaction starts is dependent upon the behavior assigned to the Transaction. It is up to the
Graph implementation to determine the default behavior and unless the implementation doesn’t allow it, the behavior
itself can be altered via these Transaction methods:
public Transaction onReadWrite(Consumer<Transaction> consumer);
public Transaction onClose(Consumer<Transaction> consumer);Providing a Consumer function to onReadWrite allows definition of how a transaction starts when a read or a write
occurs. Transaction.READ_WRITE_BEHAVIOR contains pre-defined Consumer functions to supply to the onReadWrite
method. It has two options:
-
AUTO- automatic transactions where the transaction is started implicitly to the read or write operation -
MANUAL- manual transactions where it is up to the user to explicitly open a transaction, throwing an exception if the transaction is not open
Providing a Consumer function to onClose allows configuration of how a transaction is handled when
Transaction.close() is called. Transaction.CLOSE_BEHAVIOR has several pre-defined options that can be supplied to
this method:
-
COMMIT- automatically commit an open transaction -
ROLLBACK- automatically rollback an open transaction -
MANUAL- throw an exception if a transaction is open, forcing the user to explicitly close the transaction
|
Important
|
As transactions are ThreadLocal in nature, so are the transaction configurations for onReadWrite and
onClose.
|
Once there is an understanding for how transactions are configured, most of the rest of the Transaction interface
is self-explanatory. Note that Neo4j-Gremlin is used for the examples to follow as TinkerGraph does
not support transactions.
|
Important
|
The following example is meant to demonstrate specific use of ThreadLocal transactions and is at odds
with the more generalized transaction convention that is recommended for both embedded and remote contexts. Please be
sure to understand the preferred approach described at in the Traversal Transactions Section before
using this method.
|
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[EmbeddedGraphDatabase [/tmp/neo4j]]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]
gremlin> graph.features()
==>FEATURES
> GraphFeatures
>-- Transactions: true //1
>-- Computer: false
>-- Persistence: true
...
gremlin> g.tx().onReadWrite(Transaction.READ_WRITE_BEHAVIOR.AUTO) //2
==>org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph$Neo4jTransaction@1c067c0d
gremlin> g.addV("person").("name","stephen") //3
==>v[0]
gremlin> g.tx().commit() //4
==>null
gremlin> g.tx().onReadWrite(Transaction.READ_WRITE_BEHAVIOR.MANUAL) //5
==>org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph$Neo4jTransaction@1c067c0d
gremlin> g.tx().isOpen()
==>false
gremlin> g.addV("person").("name","marko") //6
Open a transaction before attempting to read/write the transaction
gremlin> g.tx().open() //7
==>null
gremlin> g.addV("person").("name","marko") //8
==>v[1]
gremlin> g.tx().commit()
==>null-
Check
featuresto ensure that the graph supports transactions. -
By default,
Neo4jGraphis configured with "automatic" transactions, so it is set here for demonstration purposes only. -
When the vertex is added, the transaction is automatically started. From this point, more mutations can be staged or other read operations executed in the context of that open transaction.
-
Calling
commitfinalizes the transaction. -
Change transaction behavior to require manual control.
-
Adding a vertex now results in failure because the transaction was not explicitly opened.
-
Explicitly open a transaction.
-
Adding a vertex now succeeds as the transaction was manually opened.
|
Note
|
It may be important to consult the documentation of the Graph implementation you are using when it comes to the
specifics of how transactions will behave. TinkerPop allows some latitude in this area and implementations may not have
the exact same behaviors and ACID guarantees.
|
Gremlin Server
The available capability for transactions with Gremlin Server is dependent upon the method of interaction that is used. The preferred method for interacting with Gremlin Server is via websockets and bytecode based requests. The start of the Transactions Section describes this approach in detail with examples.
Gremlin Server also has the option to accept Gremlin-based scripts. The scripting approach provides access to the Graph API and thus also the transactional model described in the embedded section. Therefore a single script can have the ability to execute multiple transactions per request with complete control provided to the developer to commit or rollback transactions as needed.
|
Important
|
4.0 Milestone Release - Transactions are currently disabled in this Milestone release. |
There are two methods for sending scripts to Gremlin Server: sessionless and session-based. With sessionless requests there will always be an attempt to close the transaction at the end of the request with a commit if there are no errors or a rollback if there is a failure. It is therefore unnecessary to close transactions manually within scripts themselves. By default, session-based requests do not have this quality. The transaction will be held open on the server until the user closes it manually. There is an option to have automatic transaction management for sessions. More information on this topic can be found in the Considering Transactions Section.
|
Important
|
4.0 Milestone Release - Sessions have been removed. All scripts are now sessionless. |
Remote Gremlin Providers
At this time, transactional patterns for Remote Gremlin Providers are largely in line with Gremlin Server. As most of
RGPs do not expose a Graph instance, access to lower level transactional functions available to embedded graphs
even in a sessionless fashion are not typically permitted. For example, without a Graph instance it is not possible
to configure transaction close or read-write
behaviors. The nature of what a "transaction" means will be dependent on the RGP as is the case with any
TinkerPop-enabled graph system, so it is important to consult that systems documentation for more details.
Configuration Steps
Many of the methods on the GraphTraversalSource are meant to configure the source for usage. These configuration
affect the manner in which a traversals are spawned from it. Configuration methods can be identified by their names
with make use of "with" as a prefix:
With Configuration
The with() configuration adds arbitrary data to a TraversalSource which can then be used by graph providers as
configuration options for a traversal execution. This configuration is similar to with()-modulator which
has similar functionality when applied to an individual step.
g.with('providerDefinedVariable', 0.33).V()The 0.33 value for the "providerDefinedVariable" will be bound to each traversal spawned that way. Consult the
graph system being used to determine if any such configuration options are available.
WithBulk Configuration
The withBulk() configuration allows for control of bulking operations. This value is true by default allowing for
normal bulking operations, but when set to false, introduces a subtle change in that behavior as
shown in examples in sack()-step.
WithComputer Configuration
The withComputer() configuration adds a Computer that will be used to process the traversal and is necessary for
OLAP based processing and steps that require that processing. See examples related to
SparkGraphComputer or see examples in the computer required steps, like pageRank() or
[shortestpath-shortestPath()].
WithSack Configuration
The withSack() configuration adds a "sack" that can be accessed by traversals spawned from this source. This
functionality is shown in more detail in the examples for (sack())-step.
WithSideEffect Configuration
The withSideEffect() configuration adds an arbitrary Object to traversals spawned from this source which can be
accessed as a side-effect given the supplied key.
gremlin> g.withSideEffect('x',['dog','cat','fish']).
V().has('person','name','marko').select('x').unfold()
==>dog
==>cat
==>fishg.withSideEffect('x',['dog','cat','fish']).
V().has('person','name','marko').select('x').unfold()WithStrategies Configuration
The withStrategies() configuration allows inclusion of additional TraversalStrategy instances to be applied to
any traversals spawned from the configured source. Please see the Traversal Strategy Section
for more details on how this configuration works.
WithoutStrategies Configuration
The withoutStrategies() configuration removes a particular TraversalStrategy from those to be applied to traversals
spawned from the configured source. Please see the Traversal Strategy Section for more details
on how this configuration works.
Start Steps
Not all steps are capable of starting a GraphTraversal. Only those steps on the GraphTraversalSource can do that.
Many of the methods on GraphTraversalSource are actually for its configuration and start
steps should not be confused with those.
Spawn steps, which actually yield a traversal, typically match the names of existing steps:
-
addE()- Adds anEdgeto start the traversal (example). -
addV()- Adds aVertexto start the traversal (example). -
call()- Makes a provider-specific service call to start the traversal (example). -
E()- Reads edges from the graph to start the traversal (example). -
inject()- Inserts arbitrary objects to start the traversal (example). -
mergeE()- Adds anEdgein a "create if not exist" fashion to start the traversal (example) -
mergeV()- Adds aVertexin a "create if not exist" fashion to start the traversal (example) -
union()- Merges the results of an arbitrary number of child traversals to start the traversal (example). -
V()- Reads vertices from the graph to start the traversal (example).
Graph Traversal Steps
Gremlin steps are chained together to produce the actual traversal and are triggered by way of start steps
on the GraphTraversalSource.
|
Important
|
More details about the Gremlin language can be found in the Provider Documentation within the Gremlin Semantics Section. |
General Steps
There are five general steps, each having a traversal and a lambda representation, by which all other specific steps described later extend.
| Step | Description |
|---|---|
|
map the traverser to some object of type |
|
map the traverser to an iterator of |
|
map the traverser to either true or false, where false will not pass the traverser to the next step. |
|
perform some operation on the traverser and pass it to the next step. |
|
split the traverser to all the traversals indexed by the |
|
Warning
|
Lambda steps are presented for educational purposes as they represent the foundational constructs of the Gremlin language. In practice, lambda steps should be avoided in favor of their traversals representation and traversal verification strategies exist to disallow their use unless explicitly "turned off." For more information on the problems with lambdas, please read A Note on Lambdas. |
The Traverser<S> object provides access to:
-
The current traversed
Sobject —Traverser.get(). -
The current path traversed by the traverser —
Traverser.path().-
A helper shorthand to get a particular path-history object —
Traverser.path(String) == Traverser.path().get(String).
-
-
The number of times the traverser has gone through the current loop —
Traverser.loops(). -
The number of objects represented by this traverser —
Traverser.bulk(). -
The local data structure associated with this traverser —
Traverser.sack(). -
The side-effects associated with the traversal —
Traverser.sideEffects().-
A helper shorthand to get a particular side-effect —
Traverser.sideEffect(String) == Traverser.sideEffects().get(String).
-

gremlin> g.V(1).out().values('name') //// (1)
==>lop
==>vadas
==>josh
gremlin> g.V(1).out().map {it.get().value('name')} //// (2)
==>lop
==>vadas
==>josh
gremlin> g.V(1).out().map(values('name')) //// (3)
==>lop
==>vadas
==>joshg.V(1).out().values('name') //// (1)
g.V(1).out().map {it.get().value('name')} //// (2)
g.V(1).out().map(values('name')) //3-
An outgoing traversal from vertex 1 to the name values of the adjacent vertices.
-
The same operation, but using a lambda to access the name property values.
-
Again the same operation, but using the traversal representation of
map().

gremlin> g.V().filter {it.get().label() == 'person'} //// (1)
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().filter(label().is('person')) //// (2)
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().hasLabel('person') //// (3)
==>v[1]
==>v[2]
==>v[4]
==>v[6]g.V().filter {it.get().label() == 'person'} //// (1)
g.V().filter(label().is('person')) //// (2)
g.V().hasLabel('person') //3-
A filter that only allows the vertex to pass if it has the "person" label
-
The same operation, but using the traversal representation of
filter(). -
The more specific
has()-step is implemented as afilter()with respective predicate.

gremlin> g.V().hasLabel('person').sideEffect(System.out.&println) //// (1)
v[1]
==>v[1]
v[2]
==>v[2]
v[4]
==>v[4]
v[6]
==>v[6]
gremlin> g.V().sideEffect(outE().count().aggregate(local,"o")).
sideEffect(inE().count().aggregate(local,"i")).cap("o","i") //// (2)
==>[i:[0,0,1,1,1,3],o:[3,0,0,0,2,1]]g.V().hasLabel('person').sideEffect(System.out.&println) //// (1)
g.V().sideEffect(outE().count().aggregate(local,"o")).
sideEffect(inE().count().aggregate(local,"i")).cap("o","i") //2-
Whatever enters
sideEffect()is passed to the next step, but some intervening process can occur. -
Compute the out- and in-degree for each vertex. Both
sideEffect()are fed with the same vertex.

gremlin> g.V().branch {it.get().value('name')}.
option('marko', values('age')).
option(none, values('name')) //// (1)
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().branch(values('name')).
option('marko', values('age')).
option(none, values('name')) //// (2)
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().choose(has('name','marko'),
values('age'),
values('name')) //// (3)
==>29
==>vadas
==>lop
==>josh
==>ripple
==>peterg.V().branch {it.get().value('name')}.
option('marko', values('age')).
option(none, values('name')) //// (1)
g.V().branch(values('name')).
option('marko', values('age')).
option(none, values('name')) //// (2)
g.V().choose(has('name','marko'),
values('age'),
values('name')) //3-
If the vertex is "marko", get his age, else get the name of the vertex.
-
The same operation, but using the traversal representing of
branch(). -
The more specific boolean-based
choose()-step is implemented as abranch().
Terminal Steps
Typically, when a step is concatenated to a traversal a traversal is returned. In this way, a traversal is built up in a fluent, monadic fashion. However, some steps do not return a traversal, but instead, execute the traversal and return a result. These steps are known as terminal steps (terminal) and they are explained via the examples below.
gremlin> g.V().out('created').hasNext() //// (1)
==>true
gremlin> g.V().out('created').next() //// (2)
==>v[3]
gremlin> g.V().out('created').next(2) //// (3)
==>v[3]
==>v[5]
gremlin> g.V().out('nothing').tryNext() //// (4)
==>Optional.empty
gremlin> g.V().out('created').toList() //// (5)
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.V().out('created').toSet() //// (6)
==>v[3]
==>v[5]
gremlin> g.V().out('created').toBulkSet() //// (7)
==>v[3]
==>v[3]
==>v[3]
==>v[5]
gremlin> results = ['blah',3]
==>blah
==>3
gremlin> g.V().out('created').fill(results) //// (8)
==>blah
==>3
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.addV('person').iterate() //// (9)g.V().out('created').hasNext() //// (1)
g.V().out('created').next() //// (2)
g.V().out('created').next(2) //// (3)
g.V().out('nothing').tryNext() //// (4)
g.V().out('created').toList() //// (5)
g.V().out('created').toSet() //// (6)
g.V().out('created').toBulkSet() //// (7)
results = ['blah',3]
g.V().out('created').fill(results) //// (8)
g.addV('person').iterate() //9-
hasNext()determines whether there are available results (not supported ingremlin-javascript). -
next()will return the next result. -
next(n)will return the nextnresults in a list (not supported ingremlin-javascriptor Gremlin.NET). -
tryNext()will return anOptionaland thus, is a composite ofhasNext()/next()(only supported for JVM languages). -
toList()will return all results in a list. -
toSet()will return all results in a set and thus, duplicates removed (not supported ingremlin-javascript). -
toBulkSet()will return all results in a weighted set and thus, duplicates preserved via weighting (only supported for JVM languages). -
fill(collection)will put all results in the provided collection and return the collection when complete (only supported for JVM languages). -
iterate()does not exactly fit the definition of a terminal step in that it doesn’t return a result, but still returns a traversal - it does however behave as a terminal step in that it iterates the traversal and generates side effects without returning the actual result.
There is also the promise() terminator step, which can only be used with remote traversals to
Gremlin Server or RGPs. It starts a promise to execute a function
on the current Traversal that will be completed in the future.
Finally, explain()-step is also a terminal step and is described in its own section.
AddE Step
Reasoning is the process of making explicit what is implicit
in the data. What is explicit in a graph are the objects of the graph — i.e. vertices and edges. What is implicit
in the graph is the traversal. In other words, traversals expose meaning where the meaning is determined by the
traversal definition. For example, take the concept of a "co-developer." Two people are co-developers if they have
worked on the same project together. This concept can be represented as a traversal and thus, the concept of
"co-developers" can be derived. Moreover, what was once implicit can be made explicit via the addE()-step
(map/sideEffect).

gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')).
addE('co-developer').from('a').property('year',2009) //// (1)
==>e[0][1-co-developer->4]
==>e[13][1-co-developer->6]
gremlin> g.V(3,4,5).aggregate('x').has('name','josh').as('a').
select('x').unfold().hasLabel('software').addE('createdBy').to('a') //// (2)
==>e[14][3-createdBy->4]
==>e[15][5-createdBy->4]
gremlin> g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public') //// (3)
==>e[16][3-createdBy->1]
==>e[17][5-createdBy->4]
==>e[18][3-createdBy->4]
==>e[19][3-createdBy->6]
gremlin> g.V(1).as('a').out('knows').
addE('livesNear').from('a').property('year',2009).
inV().inE('livesNear').values('year') //// (4)
==>2009
==>2009
gremlin> g.V().match(
__.as('a').out('knows').as('b'),
__.as('a').out('created').as('c'),
__.as('b').out('created').as('c')).
addE('friendlyCollaborator').from('a').to('b').
property(id,23).property('project',select('c').values('name')) //// (5)
==>e[23][1-friendlyCollaborator->4]
gremlin> g.E(23).valueMap()
==>[project:lop]
gremlin> vMarko = g.V().has('name','marko').next()
==>v[1]
gremlin> vPeter = g.V().has('name','peter').next()
==>v[6]
gremlin> g.V(vMarko).addE('knows').to(vPeter) //// (6)
==>e[22][1-knows->6]
gremlin> g.addE('knows').from(vMarko).to(vPeter) //// (7)
==>e[24][1-knows->6]g.V(1).as('a').out('created').in('created').where(neq('a')).
addE('co-developer').from('a').property('year',2009) //// (1)
g.V(3,4,5).aggregate('x').has('name','josh').as('a').
select('x').unfold().hasLabel('software').addE('createdBy').to('a') //// (2)
g.V().as('a').out('created').addE('createdBy').to('a').property('acl','public') //// (3)
g.V(1).as('a').out('knows').
addE('livesNear').from('a').property('year',2009).
inV().inE('livesNear').values('year') //// (4)
g.V().match(
__.as('a').out('knows').as('b'),
__.as('a').out('created').as('c'),
__.as('b').out('created').as('c')).
addE('friendlyCollaborator').from('a').to('b').
property(id,23).property('project',select('c').values('name')) //// (5)
g.E(23).valueMap()
vMarko = g.V().has('name','marko').next()
vPeter = g.V().has('name','peter').next()
g.V(vMarko).addE('knows').to(vPeter) //// (6)
g.addE('knows').from(vMarko).to(vPeter) //7-
Add a co-developer edge with a year-property between marko and his collaborators.
-
Add incoming createdBy edges from the josh-vertex to the lop- and ripple-vertices.
-
Add an inverse createdBy edge for all created edges.
-
The newly created edge is a traversable object.
-
Two arbitrary bindings in a traversal can be joined
from()→to(), whereidcan be provided for graphs that supports user provided ids. -
Add an edge between marko and peter given the directed (detached) vertex references.
-
Add an edge between marko and peter given the directed (detached) vertex references.
Additional References
AddV Step
The addV()-step is used to add vertices to the graph (map/sideEffect). For every incoming object, a vertex is
created. Moreover, GraphTraversalSource maintains an addV() method.
gremlin> g.addV('person').property('name','stephen')
==>v[0]
gremlin> g.V().values('name')
==>stephen
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().outE('knows').addV().property('name','nothing')
==>v[13]
==>v[15]
gremlin> g.V().has('name','nothing')
==>v[13]
==>v[15]
gremlin> g.V().has('name','nothing').bothE()g.addV('person').property('name','stephen')
g.V().values('name')
g.V().outE('knows').addV().property('name','nothing')
g.V().has('name','nothing')
g.V().has('name','nothing').bothE()Additional References
Aggregate Step

The aggregate()-step (sideEffect) is used to aggregate all the objects at a particular point of traversal into a
Collection. The step is uses Scope to help determine the aggregating behavior. For global scope this means that
the step will use eager evaluation in that no objects continue on
until all previous objects have been fully aggregated. The eager evaluation model is crucial in situations
where everything at a particular point is required for future computation. By default, when the overload of
aggregate() is called without a Scope, the default is global. An example is provided below.
gremlin> g.V(1).out('created') //// (1)
==>v[3]
gremlin> g.V(1).out('created').aggregate('x') //// (2)
==>v[3]
gremlin> g.V(1).out('created').aggregate(global, 'x') //// (3)
==>v[3]
gremlin> g.V(1).out('created').aggregate('x').in('created') //// (4)
==>v[1]
==>v[4]
==>v[6]
gremlin> g.V(1).out('created').aggregate('x').in('created').out('created') //// (5)
==>v[3]
==>v[5]
==>v[3]
==>v[3]
gremlin> g.V(1).out('created').aggregate('x').in('created').out('created').
where(without('x')).values('name') //// (6)
==>rippleg.V(1).out('created') //// (1)
g.V(1).out('created').aggregate('x') //// (2)
g.V(1).out('created').aggregate(global, 'x') //// (3)
g.V(1).out('created').aggregate('x').in('created') //// (4)
g.V(1).out('created').aggregate('x').in('created').out('created') //// (5)
g.V(1).out('created').aggregate('x').in('created').out('created').
where(without('x')).values('name') //6-
What has marko created?
-
Aggregate all his creations.
-
Identical to the previous line.
-
Who are marko’s collaborators?
-
What have marko’s collaborators created?
-
What have marko’s collaborators created that he hasn’t created?
In recommendation systems, the above pattern is used:
"What has userA liked? Who else has liked those things? What have they liked that userA hasn't already liked?"
Finally, aggregate()-step can be modulated via by()-projection.
gremlin> g.V().out('knows').aggregate('x').cap('x')
==>[v[2],v[4]]
gremlin> g.V().out('knows').aggregate('x').by('name').cap('x')
==>[vadas,josh]
gremlin> g.V().out('knows').aggregate('x').by('age').cap('x') //// (1)
==>[27,32]g.V().out('knows').aggregate('x').cap('x')
g.V().out('knows').aggregate('x').by('name').cap('x')
g.V().out('knows').aggregate('x').by('age').cap('x') //1-
The "age" property is not productive for all vertices and therefore those values are not included in the aggregation.
For local scope the aggregation will occur in a lazy fashion.
|
Note
|
Prior to 3.4.3, local aggregation (i.e. lazy) evaluation was handled by store()-step.
|
gremlin> g.V().aggregate(global, 'x').limit(1).cap('x')
==>[v[1],v[2],v[3],v[4],v[5],v[6]]
gremlin> g.V().aggregate(local, 'x').limit(1).cap('x')
==>[v[1]]
gremlin> g.withoutStrategies(EarlyLimitStrategy).V().aggregate(local,'x').limit(1).cap('x')
==>[v[1],v[2]]g.V().aggregate(global, 'x').limit(1).cap('x')
g.V().aggregate(local, 'x').limit(1).cap('x')
g.withoutStrategies(EarlyLimitStrategy).V().aggregate(local,'x').limit(1).cap('x')It is important to note that EarlyLimitStrategy introduced in 3.3.5 alters the behavior of aggregate(local).
Without that strategy (which is installed by default), there are two results in the aggregate() side-effect even
though the interval selection is for 1 object. Realize that when the second object is on its way to the range()
filter (i.e. [0..1]), it passes through aggregate() and thus, stored before filtered.
gremlin> g.E().aggregate(local,'x').by('weight').cap('x')
==>[0.5,1.0,1.0,0.4,0.4,0.2]g.E().aggregate(local,'x').by('weight').cap('x')Additional References
All Step
It is possible to filter list traversers using all()-step (filter). Every item in the list will be tested against
the supplied predicate and if all of the items pass then the traverser is passed along the stream, otherwise it is
filtered. Empty lists are passed along but null or non-iterable traversers are filtered out.
|
Python
|
The term |
gremlin> g.V().values('age').fold().all(gt(25)) //// (1)
==>[29,27,32,35]g.V().values('age').fold().all(gt(25)) //1-
Return the list of ages only if everyone’s age is greater than 25.
Additional References
And Step
The and()-step ensures that all provided traversals yield a result (filter). Please see or() for or-semantics.
|
Python
|
The term |
gremlin> g.V().and(
outE('knows'),
values('age').is(lt(30))).
values('name')
==>markog.V().and(
outE('knows'),
values('age').is(lt(30))).
values('name')The and()-step can take an arbitrary number of traversals. All traversals must produce at least one output for the
original traverser to pass to the next step.
An infix notation can be used as well.
gremlin> g.V().where(outE('created').and().outE('knows')).values('name')
==>markog.V().where(outE('created').and().outE('knows')).values('name')Additional References
Any Step
It is possible to filter list traversers using any()-step (filter). All items in the list will be tested against
the supplied predicate and if any of the items pass then the traverser is passed along the stream, otherwise it is
filtered. Empty lists, null traversers, and non-iterable traversers are filtered out as well.
|
Python
|
The term |
gremlin> g.V().values('age').fold().any(gt(25)) //// (1)
==>[29,27,32,35]g.V().values('age').fold().any(gt(25)) //1-
Return the list of ages if anyone’s age is greater than 25.
Additional References
As Step
The as()-step is not a real step, but a "step modulator" similar to by() and option().
With as(), it is possible to provide a label to the step that can later be accessed by steps and data structures
that make use of such labels — e.g., select(), match(), and path.
|
Groovy
|
The term |
|
Python
|
The term |
gremlin> g.V().as('a').out('created').as('b').select('a','b') //// (1)
==>[a:v[1],b:v[3]]
==>[a:v[4],b:v[5]]
==>[a:v[4],b:v[3]]
==>[a:v[6],b:v[3]]
gremlin> g.V().as('a').out('created').as('b').select('a','b').by('name') //// (2)
==>[a:marko,b:lop]
==>[a:josh,b:ripple]
==>[a:josh,b:lop]
==>[a:peter,b:lop]g.V().as('a').out('created').as('b').select('a','b') //// (1)
g.V().as('a').out('created').as('b').select('a','b').by('name') //2-
Select the objects labeled "a" and "b" from the path.
-
Select the objects labeled "a" and "b" from the path and, for each object, project its name value.
A step can have any number of labels associated with it. This is useful for referencing the same step multiple times in a future step.
gremlin> g.V().hasLabel('software').as('a','b','c').
select('a','b','c').
by('name').
by('lang').
by(__.in('created').values('name').fold())
==>[a:lop,b:java,c:[marko,josh,peter]]
==>[a:ripple,b:java,c:[josh]]g.V().hasLabel('software').as('a','b','c').
select('a','b','c').
by('name').
by('lang').
by(__.in('created').values('name').fold())Additional References
AsString Step
The asString()-step (map) returns the value of incoming traverser as strings. Null values are returned unchanged.
gremlin> g.V().hasLabel('person').values('age').asString() //// (1)
==>29
==>27
==>32
==>35
gremlin> g.V().hasLabel('person').values('age').asString().concat(' years old') //// (2)
==>29 years old
==>27 years old
==>32 years old
==>35 years old
gremlin> g.V().hasLabel('person').values('age').fold().asString(local) //// (3)
==>[29,27,32,35]g.V().hasLabel('person').values('age').asString() //// (1)
g.V().hasLabel('person').values('age').asString().concat(' years old') //// (2)
g.V().hasLabel('person').values('age').fold().asString(local) //3-
Return ages as string.
-
Return ages as string and use concat to generate phrases.
-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
AsDate Step
The asDate()-step (map) converts string or numeric input to Date.
For string input only ISO-8601 format is supported. For numbers, the value is considered as the number of the milliseconds since "the epoch" (January 1, 1970, 00:00:00 GMT). Date input is passed without changes.
If the incoming traverser is not a string, number or Date then an IllegalArgumentException will be thrown.
gremlin> g.inject(1690934400000).asDate() //// (1)
==>2023-08-02T00:00Z
gremlin> g.inject("2023-08-02T00:00:00Z").asDate() //// (2)
==>2023-08-02T00:00Z
gremlin> g.inject(datetime("2023-08-24T00:00:00Z")).asDate() //// (3)
==>2023-08-24T00:00Zg.inject(1690934400000).asDate() //// (1)
g.inject("2023-08-02T00:00:00Z").asDate() //// (2)
g.inject(datetime("2023-08-24T00:00:00Z")).asDate() //3-
Convert number to Date
-
Convert ISO-8601 string to Date
-
Pass Date without modification
Additional References
Barrier Step
The barrier()-step (barrier) turns the lazy traversal pipeline into a bulk-synchronous pipeline. This step is
useful in the following situations:
-
When everything prior to
barrier()needs to be executed before moving onto the steps after thebarrier()(i.e. ordering). -
When "stalling" the traversal may lead to a "bulking optimization" in traversals that repeatedly touch many of the same elements (i.e. optimizing).
gremlin> g.V().sideEffect{println "first: ${it}"}.sideEffect{println "second: ${it}"}.iterate()
first: v[1]
second: v[1]
first: v[2]
second: v[2]
first: v[3]
second: v[3]
first: v[4]
second: v[4]
first: v[5]
second: v[5]
first: v[6]
second: v[6]
gremlin> g.V().sideEffect{println "first: ${it}"}.barrier().sideEffect{println "second: ${it}"}.iterate()
first: v[1]
first: v[2]
first: v[3]
first: v[4]
first: v[5]
first: v[6]
second: v[1]
second: v[2]
second: v[3]
second: v[4]
second: v[5]
second: v[6]g.V().sideEffect{println "first: ${it}"}.sideEffect{println "second: ${it}"}.iterate()
g.V().sideEffect{println "first: ${it}"}.barrier().sideEffect{println "second: ${it}"}.iterate()The theory behind a "bulking optimization" is simple. If there are one million traversers at vertex 1, then there is
no need to calculate one million both()-computations. Instead, represent those one million traversers as a single
traverser with a Traverser.bulk() equal to one million and execute both() once. A bulking optimization example is
made more salient on a larger graph. Therefore, the example below leverages the Grateful Dead graph.
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> g = traversal().with(graph).withoutStrategies(LazyBarrierStrategy) //// (1)
==>graphtraversalsource[tinkergraph[vertices:808 edges:8049], standard]
gremlin> clockWithResult(1){g.V().both().both().both().count().next()} //// (2)
==>7541.370895
==>126653966
gremlin> clockWithResult(1){g.V().repeat(both()).times(3).count().next()} //// (3)
==>7255.088965
==>126653966
gremlin> clockWithResult(1){g.V().both().barrier().both().barrier().both().barrier().count().next()} //// (4)
==>8.283762
==>126653966graph = TinkerGraph.open()
g = traversal().with(graph)
g.io('data/grateful-dead.xml').read().iterate()
g = traversal().with(graph).withoutStrategies(LazyBarrierStrategy) //// (1)
clockWithResult(1){g.V().both().both().both().count().next()} //// (2)
clockWithResult(1){g.V().repeat(both()).times(3).count().next()} //// (3)
clockWithResult(1){g.V().both().barrier().both().barrier().both().barrier().count().next()} //4-
Explicitly remove
LazyBarrierStrategywhich yields a bulking optimization. -
A non-bulking traversal where each traverser is processed.
-
Each traverser entering
repeat()has its recursion bulked. -
A bulking traversal where implicit traversers are not processed.
If barrier() is provided an integer argument, then the barrier will only hold n-number of unique traversers in its
barrier before draining the aggregated traversers to the next step. This is useful in the aforementioned bulking
optimization scenario with the added benefit of reducing the risk of an out-of-memory exception.
LazyBarrierStrategy inserts barrier()-steps into a traversal where appropriate in order to gain the
"bulking optimization."
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph) //// (1)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> clockWithResult(1){g.V().both().both().both().count().next()}
==>5.5897049999999995
==>126653966
gremlin> g.V().both().both().both().count().iterate().toString() //// (2)
==>[TinkerGraphStep(vertex,[]), VertexStep(BOTH,vertex), NoOpBarrierStep(2500), VertexStep(BOTH,vertex), NoOpBarrierStep(2500), VertexStep(BOTH,edge), CountGlobalStep, DiscardStep]graph = TinkerGraph.open()
g = traversal().with(graph) //// (1)
g.io('data/grateful-dead.xml').read().iterate()
clockWithResult(1){g.V().both().both().both().count().next()}
g.V().both().both().both().count().iterate().toString() //2-
LazyBarrierStrategyis a default strategy and thus, does not need to be explicitly activated. -
With
LazyBarrierStrategyactivated,barrier()-steps are automatically inserted where appropriate.
Additional References
Branch Step
The branch() step splits the traverser to all the child traversals provided to it. Please see the
General Steps section for more information, but also consider that branch() is the basis for more
robust steps like choose() and union().
Additional References
By Step
The by()-step is not an actual step, but instead is a "step-modulator" similar to as() and
option(). If a step is able to accept traversals, functions, comparators, etc. then by() is the
means by which they are added. The general pattern is step().by()…by(). Some steps can only accept one by()
while others can take an arbitrary amount.
gremlin> g.V().group().by(bothE().count()) //// (1)
==>[1:[v[2],v[5],v[6]],3:[v[1],v[3],v[4]]]
gremlin> g.V().group().by(bothE().count()).by('name') //// (2)
==>[1:[vadas,ripple,peter],3:[marko,lop,josh]]
gremlin> g.V().group().by(bothE().count()).by(count()) //// (3)
==>[1:3,3:3]g.V().group().by(bothE().count()) //// (1)
g.V().group().by(bothE().count()).by('name') //// (2)
g.V().group().by(bothE().count()).by(count()) //3-
by(outE().count())will group the elements by their edge count (traversal). -
by('name')will process the grouped elements by their name (element property projection). -
by(count())will count the number of elements in each group (traversal).
When a by() modulator does not produce a result, it is deemed "unproductive". An "unproductive" modulator will lead
to the filtering of the traverser it is currently working with. The filtering will manifest in various ways depending
on the step.
gremlin> g.V().sample(1).by('age') //// (1)
==>v[6]g.V().sample(1).by('age') //1-
The "age" property key is not present for all vertices, therefore
sample()will ignore (i.e. filter) such vertices for consideration in the sampling.
The following steps all support by()-modulation. Note that the semantics of such modulation should be understood
on a step-by-step level and thus, as discussed in their respective section of the documentation.
-
aggregate(): aggregate all objects into a set but only store theirby()-modulated values. -
cyclicPath(): filter if the traverser’s path is cyclic givenby()-modulation. -
dedup(): dedup on the results of aby()-modulation. -
group(): create group keys and values according toby()-modulation. -
groupCount(): count those groups where the group keys are the result ofby()-modulation. -
math(): transform a traverser provided to the step by way of theby()modulator before it processed by it. -
order(): order the objects by the results of aby()-modulation. -
path(): get the path of the traverser where each path element isby()-modulated. -
project(): project a map of results given variousby()-modulations off the current object. -
propertyMap(): transform the result of the values in the resultingMapusing theby()modulator. -
sack(): provides the transformation for a traverser to a value to be stored in the sack. -
sample(): sample using the value returned byby()-modulation. -
select(): select path elements and transform them viaby()-modulation. -
simplePath(): filter if the traverser’s path is simple givenby()-modulation. -
tree(): get a tree of traversers objects where the objects have beenby()-modulated. -
valueMap(): transform the result of the values in the resultingMapusing theby()modulator. -
where(): determine the predicate given the testing of the results ofby()-modulation.
Additional References
Call Step
The call() step allows for custom, provider-specific service calls either at the start of a traversal or mid-traversal.
This allows Graph providers to expose operations not natively built into the Gremlin language, such as full text search,
custom analytics, notification triggers, etc.
When called with no arguments, call() will produce a list of callable services available for the graph in use. This
no-argument version is equivalent to call('--list'). This "directory service" is also capable of producing more
verbose output describing all the services or an individual service:
gremlin> g.call() //// (1)
gremlin> g.call('--list') //// (1)
gremlin> g.call().with('verbose') //// (2)
gremlin> g.call().with('verbose').with('service', 'xyz-service') //// (3)g.call() //// (1)
g.call('--list') //// (1)
g.call().with('verbose') //// (2)
g.call().with('verbose').with('service', 'xyz-service') //3-
List available services by name
-
Produce a Map of detailed service information by name
-
Produce the detailed service information for the 'xyz-service'
The first argument to call() is always the name of the service call. Additionally, service calls can accept both
static and dynamically produced parameters. Static parameters can be passed as a Map to the call() as the second
argument. Individual static parameters can also be added using the .with() modulator. Dynamic parameters can be
passed as a Map-producing Traversal as the second argument (no static parameters) or third argument (static + dynamic
parameters). Additional individual dynamic parameters can be added using the .with() modulator.
g.call('xyz-service') //1
g.call('xyz-service', ['a':'b']) //2
g.call('xyz-service').with('a', 'b') //2
g.call('xyz-service', __.inject(['a':'b'])) //3
g.call('xyz-service').with('a', __.inject('b')) //3
g.call('xyz-service', ['a':'b'], __.inject(['c':'d'])) //4-
Call the 'xyz-service' with no parameters
-
Examples of static parameters (constants known before execution)
-
Examples of dynamic parameters (these will be computed at execution time)
-
Example of static + dynamic parameters (these will be computed and merged into one set of parameters at execution time)
Additional References
GraphTraversalSource:
GraphTraversal:
Cap Step
The cap()-step (barrier) iterates the traversal up to itself and emits the sideEffect referenced by the provided
key. If multiple keys are provided, then a Map<String,Object> of sideEffects is emitted.
gremlin> g.V().groupCount('a').by(label).cap('a') //// (1)
==>[software:2,person:4]
gremlin> g.V().groupCount('a').by(label).groupCount('b').by(outE().count()).cap('a','b') //// (2)
==>[a:[software:2,person:4],b:[0:3,1:1,2:1,3:1]]g.V().groupCount('a').by(label).cap('a') //// (1)
g.V().groupCount('a').by(label).groupCount('b').by(outE().count()).cap('a','b') //2-
Group and count vertices by their label. Emit the side effect labeled 'a', which is the group count by label.
-
Same as statement 1, but also emit the side effect labeled 'b' which groups vertices by the number of out edges.
Additional References
Choose Step

The choose()-step (branch) routes the current traverser to a particular traversal branch option. With choose(),
it is possible to implement if/then/else-semantics as well as more complicated selections.
gremlin> g.V().hasLabel('person').
choose(values('age').is(lte(30)),
__.in(),
__.out()).values('name') //// (1)
==>marko
==>ripple
==>lop
==>lop
gremlin> g.V().hasLabel('person').
choose(values('age')).
option(27, __.in()).
option(32, __.out()).values('name') //// (2)
==>marko
==>ripple
==>lopg.V().hasLabel('person').
choose(values('age').is(lte(30)),
__.in(),
__.out()).values('name') //// (1)
g.V().hasLabel('person').
choose(values('age')).
option(27, __.in()).
option(32, __.out()).values('name') //2-
If the traversal yields an element, then do
in, else doout(i.e. true/false-based option selection). -
Use the result of the traversal as a key to the map of traversal options (i.e. value-based option selection).
If the "false"-branch is not provided, then if/then-semantics are implemented.
gremlin> g.V().choose(hasLabel('person'), out('created')).values('name') //// (1)
==>lop
==>lop
==>ripple
==>lop
==>ripple
==>lop
gremlin> g.V().choose(hasLabel('person'), out('created'), identity()).values('name') //// (2)
==>lop
==>lop
==>ripple
==>lop
==>ripple
==>lopg.V().choose(hasLabel('person'), out('created')).values('name') //// (1)
g.V().choose(hasLabel('person'), out('created'), identity()).values('name') //2-
If the vertex is a person, emit the vertices they created, else emit the vertex.
-
If/then/else with an
identity()on the false-branch is equivalent to if/then with no false-branch.
Note that choose() can have an arbitrary number of options and moreover, can take an anonymous traversal as its choice function.
gremlin> g.V().hasLabel('person').
choose(values('name')).
option('marko', values('age')).
option('josh', values('name')).
option('vadas', elementMap()).
option('peter', label())
==>29
==>[id:2,label:person,name:vadas,age:27]
==>josh
==>persong.V().hasLabel('person').
choose(values('name')).
option('marko', values('age')).
option('josh', values('name')).
option('vadas', elementMap()).
option('peter', label())The choose()-step can leverage the Pick.none option match. For anything that does not match a specified option, the none-option is taken.
gremlin> g.V().hasLabel('person').
choose(values('name')).
option('marko', values('age')).
option(none, values('name'))
==>29
==>vadas
==>josh
==>peterg.V().hasLabel('person').
choose(values('name')).
option('marko', values('age')).
option(none, values('name'))Additional References
Coalesce Step
The coalesce()-step evaluates the provided traversals in order and returns the first traversal that emits at
least one element.
gremlin> g.V(1).coalesce(outE('knows'), outE('created')).inV().path().by('name').by(label)
==>[marko,knows,vadas]
==>[marko,knows,josh]
gremlin> g.V(1).coalesce(outE('created'), outE('knows')).inV().path().by('name').by(label)
==>[marko,created,lop]
gremlin> g.V(1).property('nickname', 'okram')
==>v[1]
gremlin> g.V().hasLabel('person').coalesce(values('nickname'), values('name'))
==>okram
==>vadas
==>josh
==>peterg.V(1).coalesce(outE('knows'), outE('created')).inV().path().by('name').by(label)
g.V(1).coalesce(outE('created'), outE('knows')).inV().path().by('name').by(label)
g.V(1).property('nickname', 'okram')
g.V().hasLabel('person').coalesce(values('nickname'), values('name'))Additional References
Coin Step
To randomly filter out a traverser, use the coin()-step (filter). The provided double argument biases the "coin toss."
gremlin> g.V().coin(0.5)
==>v[2]
==>v[3]
==>v[4]
==>v[5]
gremlin> g.V().coin(0.0)
gremlin> g.V().coin(1.0)
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]g.V().coin(0.5)
g.V().coin(0.0)
g.V().coin(1.0)Additional References
Combine Step
The combine()-step (map) combines the elements of the incoming list traverser and the provided list argument into
one list. This is also known as appending or concatenating. This step only expects list data (array or Iterable) and
will throw an IllegalArgumentException if any other type is encountered (including null). This differs from the
merge()-step in that it allows duplicates to exist.
gremlin> g.V().values("name").fold().combine(["james","jen","marko","vadas"])
==>[marko,vadas,lop,josh,ripple,peter,james,jen,marko,vadas]
gremlin> g.V().values("name").fold().combine(__.constant("stephen").fold())
==>[marko,vadas,lop,josh,ripple,peter,stephen]g.V().values("name").fold().combine(["james","jen","marko","vadas"])
g.V().values("name").fold().combine(__.constant("stephen").fold())Additional References
Concat Step
The concat()-step (map) concatenates one or more String values together to the incoming String traverser. This step
can take either String varargs or Traversal varargs.
Any null String values will be skipped when concatenated with non-null String values. If two null value are
concatenated, the null value will be propagated and returned.
If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.addV(constant('prefix_').concat(__.V(1).label())).property(id, 10) //// (1)
==>v[10]
gremlin> g.V(10).label()
==>prefix_person
gremlin> g.V().hasLabel('person').values('name').as('a').
constant('Mr.').concat(__.select('a')) //// (2)
==>Mr.marko
==>Mr.vadas
==>Mr.josh
==>Mr.peter
gremlin> g.V().hasLabel('software').as('a').values('name').
concat(' uses ').
concat(select('a').values('lang')) //// (3)
==>lop uses java
==>ripple uses java
gremlin> g.V(1).outE().as('a').V(1).values('name').
concat(' ').
concat(select('a').label()).
concat(' ').
concat(select("a").inV().values('name')) //// (4)
==>marko created lop
==>marko knows vadas
==>marko knows josh
gremlin> g.V(1).outE().as('a').V(1).values('name').
concat(constant(' '),
select("a").label(),
constant(' '),
select('a').inV().values('name')) //// (5)
==>marko created lop
==>marko knows vadas
==>marko knows josh
gremlin> g.inject('hello', 'hi').concat(__.V().values('name')) //// (6)
==>hellomarko
==>himarko
gremlin> g.inject('This').concat(' ').concat('is a ', 'gremlin.') //// (7)
==>This is a gremlin.g.addV(constant('prefix_').concat(__.V(1).label())).property(id, 10) //// (1)
g.V(10).label()
g.V().hasLabel('person').values('name').as('a').
constant('Mr.').concat(__.select('a')) //// (2)
g.V().hasLabel('software').as('a').values('name').
concat(' uses ').
concat(select('a').values('lang')) //// (3)
g.V(1).outE().as('a').V(1).values('name').
concat(' ').
concat(select('a').label()).
concat(' ').
concat(select("a").inV().values('name')) //// (4)
g.V(1).outE().as('a').V(1).values('name').
concat(constant(' '),
select("a").label(),
constant(' '),
select('a').inV().values('name')) //// (5)
g.inject('hello', 'hi').concat(__.V().values('name')) //// (6)
g.inject('This').concat(' ').concat('is a ', 'gremlin.') //7-
Add a new vertex with id 10 which should be labeled like an existing vertex but with some prefix attached
-
Attach the prefix "Mr." to all the names using the
constant()-step -
Generate a string of software names and the language they use
-
Generate a string description for each of marko’s outgoing edges
-
Alternative way to generate the string description by using traversal varargs. Use the
constant()step to add desired strings between arguments. -
The
concat()step will append the first result from the child traversal to the incoming traverser -
A generic use of
concat()to join strings together
Additional References
Conjoin Step
The conjoin()-step (map) joins together the elements in the incoming list traverser together with the provided argument
as a delimiter. The resulting String is added to the Traversal Stream. This step only expects list data (array or
Iterable) in the incoming traverser and will throw an IllegalArgumentException if any other type is encountered
(including null). Null values are skipped and not included in the result.
gremlin> g.V().values("name").fold().conjoin("+")
==>marko+vadas+lop+josh+ripple+peterg.V().values("name").fold().conjoin("+")Additional References
ConnectedComponent Step
The connectedComponent() step performs a computation to identify Connected Component
instances in a graph. When this step completes, the vertices will be labelled with a component identifier to denote
the component to which they are associated.
|
Important
|
The connectedComponent()-step is a VertexComputing-step and as such, can only be used against a graph
that supports GraphComputer (OLAP).
|
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().
connectedComponent().
with(ConnectedComponent.propertyName, 'component').
project('name','component').
by('name').
by('component')
==>[name:ripple,component:1]
==>[name:josh,component:1]
==>[name:marko,component:1]
==>[name:vadas,component:1]
==>[name:lop,component:1]
==>[name:peter,component:1]
gremlin> g.V().hasLabel('person').
connectedComponent().
with(ConnectedComponent.propertyName, 'component').
with(ConnectedComponent.edges, outE('knows')).
project('name','component').
by('name').
by('component')
==>[name:vadas,component:1]
==>[name:peter,component:6]
==>[name:josh,component:1]
==>[name:marko,component:1]g = traversal().with(graph).withComputer()
g.V().
connectedComponent().
with(ConnectedComponent.propertyName, 'component').
project('name','component').
by('name').
by('component')
g.V().hasLabel('person').
connectedComponent().
with(ConnectedComponent.propertyName, 'component').
with(ConnectedComponent.edges, outE('knows')).
project('name','component').
by('name').
by('component')Note the use of the with() modulating step which provides configuration options to the algorithm. It takes
configuration keys from the ConnectedComponent class and is automatically imported to the Gremlin Console.
Additional References
Constant Step
To specify a constant value for a traverser, use the constant()-step (map). This is often useful with conditional
steps like choose()-step or coalesce()-step.
gremlin> g.V().choose(hasLabel('person'),
values('name'),
constant('inhuman')) //// (1)
==>marko
==>vadas
==>inhuman
==>josh
==>inhuman
==>peter
gremlin> g.V().coalesce(
hasLabel('person').values('name'),
constant('inhuman')) //// (2)
==>marko
==>vadas
==>inhuman
==>josh
==>inhuman
==>peterg.V().choose(hasLabel('person'),
values('name'),
constant('inhuman')) //// (1)
g.V().coalesce(
hasLabel('person').values('name'),
constant('inhuman')) //2-
Show the names of people, but show "inhuman" for other vertices.
-
Same as statement 1 (unless there is a person vertex with no name).
Additional References
Count Step

The count()-step (map) counts the total number of represented traversers in the streams (i.e. the bulk count).
gremlin> g.V().count()
==>6
gremlin> g.V().hasLabel('person').count()
==>4
gremlin> g.V().hasLabel('person').outE('created').count().path() //// (1)
==>[4]
gremlin> g.V().hasLabel('person').outE('created').count().map {it.get() * 10}.path() //// (2)
==>[4,40]g.V().count()
g.V().hasLabel('person').count()
g.V().hasLabel('person').outE('created').count().path() //// (1)
g.V().hasLabel('person').outE('created').count().map {it.get() * 10}.path() //2-
count()-step is a reducing barrier step meaning that all of the previous traversers are folded into a new traverser. -
The path of the traverser emanating from
count()starts atcount().
|
Important
|
count(local) counts the current, local object (not the objects in the traversal stream). This works for
Collection- and Map-type objects. For any other object, a count of 1 is returned.
|
Additional References
CyclicPath Step

Each traverser maintains its history through the traversal over the graph — i.e. its path.
If it is important that the traverser repeat its course, then cyclic()-path should be used (filter). The step
analyzes the path of the traverser thus far and if there are any repeats, the traverser is filtered out over the
traversal computation. If non-cyclic behavior is desired, see simplePath().
gremlin> g.V(1).both().both()
==>v[1]
==>v[4]
==>v[6]
==>v[1]
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(1).both().both().cyclicPath()
==>v[1]
==>v[1]
==>v[1]
gremlin> g.V(1).both().both().cyclicPath().path()
==>[v[1],v[3],v[1]]
==>[v[1],v[2],v[1]]
==>[v[1],v[4],v[1]]
gremlin> g.V(1).both().both().cyclicPath().by('age').path() //// (1)
==>[v[1],v[2],v[1]]
==>[v[1],v[4],v[1]]
gremlin> g.V(1).as('a').out('created').as('b').
in('created').as('c').
cyclicPath().
path()
==>[v[1],v[3],v[1]]
gremlin> g.V(1).as('a').out('created').as('b').
in('created').as('c').
cyclicPath().from('a').to('b').
path()g.V(1).both().both()
g.V(1).both().both().cyclicPath()
g.V(1).both().both().cyclicPath().path()
g.V(1).both().both().cyclicPath().by('age').path() //// (1)
g.V(1).as('a').out('created').as('b').
in('created').as('c').
cyclicPath().
path()
g.V(1).as('a').out('created').as('b').
in('created').as('c').
cyclicPath().from('a').to('b').
path()-
The "age" property is not productive for all vertices and therefore those traversers are filtered.
Additional References
DateAdd Step
The dateAdd()-step (map) returns the value with the addition of the value number of units as specified by the DateToken.
If the incoming traverser is not a Date, then an IllegalArgumentException will be thrown.
gremlin> g.inject("2023-08-02T00:00:00Z").asDate().dateAdd(DT.day, 7) //// (1)
==>2023-08-09T00:00Z
gremlin> g.inject(["2023-08-02T00:00:00Z", "2023-08-03T00:00:00Z"]).unfold().asDate().dateAdd(DT.minute, 1) //// (2)
==>2023-08-02T00:01Z
==>2023-08-03T00:01Zg.inject("2023-08-02T00:00:00Z").asDate().dateAdd(DT.day, 7) //// (1)
g.inject(["2023-08-02T00:00:00Z", "2023-08-03T00:00:00Z"]).unfold().asDate().dateAdd(DT.minute, 1) //2-
Add 7 days to Date
-
Add 1 minute to incoming dates
Additional References
DateDiff Step
The dateDiff()-step (map) returns the difference between two Dates in epoch time.
If the incoming traverser is not a Date, then an IllegalArgumentException will be thrown.
gremlin> g.inject("2023-08-02T00:00:00Z").asDate().dateDiff(constant("2023-08-03T00:00:00Z").asDate()) //// (1)
==>-86400g.inject("2023-08-02T00:00:00Z").asDate().dateDiff(constant("2023-08-03T00:00:00Z").asDate()) //1-
Find difference between two dates
Additional References
Dedup Step
With dedup()-step (filter), repeatedly seen objects are removed from the traversal stream. Note that if a
traverser’s bulk is greater than 1, then it is set to 1 before being emitted.
gremlin> g.V().values('lang')
==>java
==>java
gremlin> g.V().values('lang').dedup()
==>java
gremlin> g.V(1).repeat(bothE('created').dedup().otherV()).emit().path() //// (1)
==>[v[1],e[9][1-created->3],v[3]]
==>[v[1],e[9][1-created->3],v[3],e[11][4-created->3],v[4]]
==>[v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6]]
==>[v[1],e[9][1-created->3],v[3],e[11][4-created->3],v[4],e[10][4-created->5],v[5]]
gremlin> g.V().bothE().properties().dedup() //// (2)
==>p[weight->0.4]
==>p[weight->0.5]
==>p[weight->1.0]
==>p[weight->0.2]g.V().values('lang')
g.V().values('lang').dedup()
g.V(1).repeat(bothE('created').dedup().otherV()).emit().path() //// (1)
g.V().bothE().properties().dedup() //2-
Traverse all
creatededges, but don’t touch any edge twice. -
Note that
Propertyinstances will compare on key and value, whereas aVertexPropertywill also include its element as it is a first-class citizen.
If a by-step modulation is provided to dedup(), then the object is processed accordingly prior to determining if it
has been seen or not.
gremlin> g.V().elementMap('name')
==>[id:1,label:person,name:marko]
==>[id:2,label:person,name:vadas]
==>[id:3,label:software,name:lop]
==>[id:4,label:person,name:josh]
==>[id:5,label:software,name:ripple]
==>[id:6,label:person,name:peter]
gremlin> g.V().dedup().by(label).values('name')
==>marko
==>lopg.V().elementMap('name')
g.V().dedup().by(label).values('name')Finally, if dedup() is provided an array of strings, then it will ensure that the de-duplication is not with respect
to the current traverser object, but to the path history of the traverser.
gremlin> g.V().as('a').out('created').as('b').in('created').as('c').select('a','b','c')
==>[a:v[1],b:v[3],c:v[1]]
==>[a:v[1],b:v[3],c:v[4]]
==>[a:v[1],b:v[3],c:v[6]]
==>[a:v[4],b:v[5],c:v[4]]
==>[a:v[4],b:v[3],c:v[1]]
==>[a:v[4],b:v[3],c:v[4]]
==>[a:v[4],b:v[3],c:v[6]]
==>[a:v[6],b:v[3],c:v[1]]
==>[a:v[6],b:v[3],c:v[4]]
==>[a:v[6],b:v[3],c:v[6]]
gremlin> g.V().as('a').out('created').as('b').in('created').as('c').dedup('a','b').select('a','b','c') //// (1)
==>[a:v[1],b:v[3],c:v[1]]
==>[a:v[4],b:v[5],c:v[4]]
==>[a:v[4],b:v[3],c:v[1]]
==>[a:v[6],b:v[3],c:v[1]]
gremlin> g.V().as('a').both().as('b').both().as('c').
dedup('a','b').by('age'). //// (2)
select('a','b','c').by('name')
==>[a:marko,b:vadas,c:marko]
==>[a:marko,b:josh,c:ripple]
==>[a:vadas,b:marko,c:lop]
==>[a:josh,b:marko,c:lop]g.V().as('a').out('created').as('b').in('created').as('c').select('a','b','c')
g.V().as('a').out('created').as('b').in('created').as('c').dedup('a','b').select('a','b','c') //// (1)
g.V().as('a').both().as('b').both().as('c').
dedup('a','b').by('age'). //// (2)
select('a','b','c').by('name')-
If the current
aandbcombination has been seen previously, then filter the traverser. -
The "age" property is not productive for all vertices and therefore those values are filtered.
Additional References
Difference Step
The difference()-step (map) calculates the difference between the incoming list traverser and the provided list
argument. More specifically, this provides the set operation A-B where A is the traverser and B is the argument. This
step only expects list data (array or Iterable) and will throw an IllegalArgumentException if any other type is
encountered (including null).
gremlin> g.V().values("name").fold().difference(["lop","ripple"])
==>[peter,vadas,josh,marko]
gremlin> g.V().values("name").fold().difference(__.V().limit(2).values("name").fold())
==>[ripple,peter,josh,lop]g.V().values("name").fold().difference(["lop","ripple"])
g.V().values("name").fold().difference(__.V().limit(2).values("name").fold())Additional References
Discard Step
The discard()-step (filter) filters all objects from a traversal stream. It is especially useful for traversals
that are executed remotely where returning results is not useful and the traversal is only meant to generate
side-effects. Choosing not to return results saves in serialization and network costs as the objects are filtered on
the remote end and not returned to the client side. Typically, this step does not need to be used directly and is
quietly used by the iterate() terminal step which appends discard() to the traversal before actually cycling through
results.
Additional References
Disjunct Step
The disjunct()-step (map) calculates the disjunct set between the incoming list traverser and the provided list
argument. This step only expects list data (array or Iterable) and will throw an IllegalArgumentException if any other
type is encountered (including null).
gremlin> g.V().values("name").fold().disjunct(["lop","peter","sam"]) //// (1)
==>[ripple,vadas,josh,sam,marko]
gremlin> g.V().values("name").fold().disjunct(__.V().limit(3).values("name").fold())
==>[ripple,peter,josh]g.V().values("name").fold().disjunct(["lop","peter","sam"]) //// (1)
g.V().values("name").fold().disjunct(__.V().limit(3).values("name").fold())-
Find the unique names between two group of names
Additional References
Drop Step
The drop()-step (filter/sideEffect) is used to remove element and properties from the graph (i.e. remove). It
is a filter step because the traversal yields no outgoing objects.
gremlin> g.V().outE().drop()
gremlin> g.E()
gremlin> g.V().properties('name').drop()
gremlin> g.V().elementMap()
==>[id:1,label:person,age:29]
==>[id:2,label:person,age:27]
==>[id:3,label:software,lang:java]
==>[id:4,label:person,age:32]
==>[id:5,label:software,lang:java]
==>[id:6,label:person,age:35]
gremlin> g.V().drop()
gremlin> g.V()g.V().outE().drop()
g.E()
g.V().properties('name').drop()
g.V().elementMap()
g.V().drop()
g.V()Additional References
E Step
The E()-step is meant to read edges from the graph and is usually used to start a GraphTraversal, but can also
be used mid-traversal.
gremlin> g.E(11) //// (1)
==>e[11][4-created->3]
gremlin> g.E().hasLabel('knows').has('weight', gt(0.75))
==>e[8][1-knows->4]
gremlin> g.inject(1).coalesce(E().hasLabel("knows"), addE("knows").from(V().has("name","josh")).to(V().has("name","vadas"))) //// (2)
==>e[7][1-knows->2]
==>e[8][1-knows->4]g.E(11) //// (1)
g.E().hasLabel('knows').has('weight', gt(0.75))
g.inject(1).coalesce(E().hasLabel("knows"), addE("knows").from(V().has("name","josh")).to(V().has("name","vadas"))) //2-
Find the edge by its unique identifier (i.e.
T.id) - not all graphs will use a numeric value for their identifier. -
Get edges with label
knows, if there is none then add new one betweenjoshandvadas.
Additional References
Element Step
The element() step is a no-argument step that traverses from a Property to the Element that owns it.
gremlin> g.V().properties().element() //// (1)
==>v[1]
==>v[1]
==>v[1]
==>v[1]
==>v[1]
==>v[7]
==>v[7]
==>v[7]
==>v[7]
==>v[8]
==>v[8]
==>v[8]
==>v[8]
==>v[8]
==>v[9]
==>v[9]
==>v[9]
==>v[9]
==>v[10]
==>v[11]
gremlin> g.E().properties().element() //// (2)
==>e[13][1-develops->10]
==>e[14][1-develops->11]
==>e[15][1-uses->10]
==>e[16][1-uses->11]
==>e[17][7-develops->10]
==>e[18][7-develops->11]
==>e[19][7-uses->10]
==>e[20][7-uses->11]
==>e[21][8-develops->10]
==>e[22][8-uses->10]
==>e[23][8-uses->11]
==>e[24][9-uses->10]
==>e[25][9-uses->11]
gremlin> g.V().properties().properties().element() //// (3)
==>vp[location->san diego]
==>vp[location->san diego]
==>vp[location->santa cruz]
==>vp[location->santa cruz]
==>vp[location->brussels]
==>vp[location->brussels]
==>vp[location->santa fe]
==>vp[location->centreville]
==>vp[location->centreville]
==>vp[location->dulles]
==>vp[location->dulles]
==>vp[location->purcellville]
==>vp[location->bremen]
==>vp[location->bremen]
==>vp[location->baltimore]
==>vp[location->baltimore]
==>vp[location->oakland]
==>vp[location->oakland]
==>vp[location->seattle]
==>vp[location->spremberg]
==>vp[location->spremberg]
==>vp[location->kaiserslautern]
==>vp[location->kaiserslautern]
==>vp[location->aachen]g.V().properties().element() //// (1)
g.E().properties().element() //// (2)
g.V().properties().properties().element() //3-
Traverse from
VertexPropertytoVertex -
Traverse from
Property(edge property) toEdge -
Traverse from
Property(meta property) toVertexProperty
Additional References
ElementMap Step
The elementMap()-step yields a Map representation of the structure of an element.
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,age:29]
==>[id:2,label:person,name:vadas,age:27]
==>[id:3,label:software,name:lop,lang:java]
==>[id:4,label:person,name:josh,age:32]
==>[id:5,label:software,name:ripple,lang:java]
==>[id:6,label:person,name:peter,age:35]
gremlin> g.V().elementMap('age')
==>[id:1,label:person,age:29]
==>[id:2,label:person,age:27]
==>[id:3,label:software]
==>[id:4,label:person,age:32]
==>[id:5,label:software]
==>[id:6,label:person,age:35]
gremlin> g.V().elementMap('age','blah')
==>[id:1,label:person,age:29]
==>[id:2,label:person,age:27]
==>[id:3,label:software]
==>[id:4,label:person,age:32]
==>[id:5,label:software]
==>[id:6,label:person,age:35]
gremlin> g.E().elementMap()
==>[id:7,label:knows,IN:[id:2,label:person],OUT:[id:1,label:person],weight:0.5]
==>[id:8,label:knows,IN:[id:4,label:person],OUT:[id:1,label:person],weight:1.0]
==>[id:9,label:created,IN:[id:3,label:software],OUT:[id:1,label:person],weight:0.4]
==>[id:10,label:created,IN:[id:5,label:software],OUT:[id:4,label:person],weight:1.0]
==>[id:11,label:created,IN:[id:3,label:software],OUT:[id:4,label:person],weight:0.4]
==>[id:12,label:created,IN:[id:3,label:software],OUT:[id:6,label:person],weight:0.2]g.V().elementMap()
g.V().elementMap('age')
g.V().elementMap('age','blah')
g.E().elementMap()It is important to note that the map of a vertex assumes that cardinality for each key is single and if it is list
then only the first item encountered will be returned. As single is the more common cardinality for properties this
assumption should serve the greatest number of use cases.
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,location:santa fe]
==>[id:7,label:person,name:stephen,location:purcellville]
==>[id:8,label:person,name:matthias,location:seattle]
==>[id:9,label:person,name:daniel,location:aachen]
==>[id:10,label:software,name:gremlin]
==>[id:11,label:software,name:tinkergraph]
gremlin> g.V().has('name','marko').properties('location')
==>vp[location->san diego]
==>vp[location->santa cruz]
==>vp[location->brussels]
==>vp[location->santa fe]
gremlin> g.V().has('name','marko').properties('location').elementMap()
==>[id:6,key:location,value:san diego,startTime:1997,endTime:2001]
==>[id:7,key:location,value:santa cruz,startTime:2001,endTime:2004]
==>[id:8,key:location,value:brussels,startTime:2004,endTime:2005]
==>[id:9,key:location,value:santa fe,startTime:2005]g.V().elementMap()
g.V().has('name','marko').properties('location')
g.V().has('name','marko').properties('location').elementMap()|
Important
|
The elementMap()-step does not return the vertex labels for incident vertices when using GraphComputer
as the id is the only available data to the star graph.
|
Additional References
Emit Step
The emit-step is not an actual step, but is instead a step modulator for repeat() (find more
documentation on the emit() there).
Additional References
Explain Step
The explain()-step (terminal) will return a TraversalExplanation. A traversal explanation details how the
traversal (prior to explain()) will be compiled given the registered traversal strategies.
A TraversalExplanation has a toString() representation with 3-columns. The first column is the
traversal strategy being applied. The second column is the traversal strategy category: [D]ecoration, [O]ptimization,
[P]rovider optimization, [F]inalization, and [V]erification. Finally, the third column is the state of the traversal
post strategy application. The final traversal is the resultant execution plan.
gremlin> g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain()
==>Traversal Explanation
==================================================================================================================================================================================
Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
ConnectiveStrategy [D] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), IdentityStep, EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
IdentityRemovalStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
ByModulatorOptimizationStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
EarlyLimitStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
MatchPredicateStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
FilterRankingStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
InlineFilterStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), EdgeVertexStep(IN), CountGlobalStep, IsStep(gt(5))]
IncidentToAdjacentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,vertex), CountGlobalStep, IsStep(gt(5))]
AdjacentToIncidentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]
RepeatUnrollStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), CountGlobalStep, IsStep(gt(5))]
CountStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
PathRetractionStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
LazyBarrierStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
TinkerGraphCountStrategy [P] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
ProfileStrategy [F] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]
Final Traversal [TinkerGraphStep(vertex,[~label.eq(person)]), VertexStep(OUT,edge), RangeGlobalStep(0,6), CountGlobalStep, IsStep(gt(5))]g.V().hasLabel('person').outE().identity().inV().count().is(gt(5)).explain()For traversal profiling information, please see profile()-step.
Fail Step
The fail()-step provides a way to force a traversal to immediately fail with an exception. This feature is often
helpful during debugging purposes and for validating certain conditions prior to continuing with traversal execution.
gremlin> g.V().has('person','name','peter').fold().
......1> coalesce(unfold(),
......2> fail('peter should exist')).
......3> property('k',100)
==>v[6]
gremlin> g.V().has('person','name','stephen').fold().
......1> coalesce(unfold(),
......2> fail('stephen should exist')).
......3> property('k',100)
fail() Step Triggered
===========================================================================================================================
Message > stephen should exist
Traverser> []
Bulk > 1
Traversal> fail()
Parent > CoalesceStep [V().has("person","name","stephen").fold().coalesce(__.unfold(),__.fail()).property("k",(int) 100)]
Metadata > {}
===========================================================================================================================The code example above exemplifies the latter use case where there is essentially an assertion that there is a vertex with a particular "name" value prior to updating the property "k" and explicitly failing when that vertex is not found.
Additional References
Filter Step
The filter() step maps the traverser from the current object to either true or false where the latter will not
pass the traverser to the next step in the process. Please see the General Steps section for more
information.
Additional References
FlatMap Step
The flatMap() step maps the traverser from the current object to an Iterator of objects for the next step in the
process. Please see the General Steps section for more information.
Additional References
Format Step
This step is designed to simplify some string operations. In general, it is similar to the string formatting function available in many programming languages. Variable values can be picked up from Element properties, maps and scope variables.
gremlin> g.V().format("%{name} is %{age} years old") //// (1)
==>marko is 29 years old
==>vadas is 27 years old
==>josh is 32 years old
==>peter is 35 years old
gremlin> g.V().hasLabel("person").as("a").values("name").as("p1").select("a").in("knows").format("%{p1} knows %{name}") //// (2)
==>vadas knows marko
==>josh knows marko
gremlin> g.V().format("%{name} has %{_} connections").by(bothE().count()) //// (3)
==>marko has 3 connections
==>vadas has 1 connections
==>lop has 3 connections
==>josh has 3 connections
==>ripple has 1 connections
==>peter has 1 connections
gremlin> g.V().project("name","count").by(values("name")).by(bothE().count()).format("%{name} has %{count} connections") //// (4)
==>marko has 3 connections
==>vadas has 1 connections
==>lop has 3 connections
==>josh has 3 connections
==>ripple has 1 connections
==>peter has 1 connectionsg.V().format("%{name} is %{age} years old") //// (1)
g.V().hasLabel("person").as("a").values("name").as("p1").select("a").in("knows").format("%{p1} knows %{name}") //// (2)
g.V().format("%{name} has %{_} connections").by(bothE().count()) //// (3)
g.V().project("name","count").by(values("name")).by(bothE().count()).format("%{name} has %{count} connections") //4-
A
format()will use property values from incoming Element to produce String result. -
A
format()will use scope variablep1and propertynameto resolve variable values. -
A
format()will use propertynameand traversal product for positional argument to resolve variable values. -
A
format()will use map produced byprojectstep to resolve variable values.
Additional References
Fold Step
There are situations when the traversal stream needs a "barrier" to aggregate all the objects and emit a computation
that is a function of the aggregate. The fold()-step (map) is one particular instance of this. Please see
unfold()-step for the inverse functionality.
gremlin> g.V(1).out('knows').values('name')
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name').fold() //// (1)
==>[vadas,josh]
gremlin> g.V(1).out('knows').values('name').fold().next().getClass() //// (2)
==>class java.util.ArrayList
gremlin> g.V(1).out('knows').values('name').fold(0) {a,b -> a + b.length()} //// (3)
==>9
gremlin> g.V().values('age').fold(0) {a,b -> a + b} //// (4)
==>123
gremlin> g.V().values('age').fold(0, sum) //// (5)
==>123
gremlin> g.V().values('age').sum() //// (6)
==>123
gremlin> g.inject(["a":1],["b":2]).fold([], addAll) //// (7)
==>[[a:1],[b:2]]g.V(1).out('knows').values('name')
g.V(1).out('knows').values('name').fold() //// (1)
g.V(1).out('knows').values('name').fold().next().getClass() //// (2)
g.V(1).out('knows').values('name').fold(0) {a,b -> a + b.length()} //// (3)
g.V().values('age').fold(0) {a,b -> a + b} //// (4)
g.V().values('age').fold(0, sum) //// (5)
g.V().values('age').sum() //// (6)
g.inject(["a":1],["b":2]).fold([], addAll) //7-
A parameterless
fold()will aggregate all the objects into a list and then emit the list. -
A verification of the type of list returned.
-
fold()can be provided two arguments — a seed value and a reduce bi-function ("vadas" is 5 characters + "josh" with 4 characters). -
What is the total age of the people in the graph?
-
The same as before, but using a built-in bi-function.
-
The same as before, but using the
sum()-step. -
A mechanism for merging
Mapinstances. If a key occurs in more than a singleMap, the later occurrence will replace the earlier.
Additional References
From Step
The from()-step is not an actual step, but instead is a "step-modulator" similar to as() and
by(). If a step is able to accept traversals or strings then from() is the
means by which they are added. The general pattern is step().from(). See to()-step.
The list of steps that support from()-modulation are: simplePath(), cyclicPath(),
path(), and addE().
|
Javascript
|
The term |
|
Python
|
The term |
Additional References
Group Step
As traversers propagate across a graph as defined by a traversal, sideEffect computations are sometimes required.
That is, the actual path taken or the current location of a traverser is not the ultimate output of the computation,
but some other representation of the traversal. The group()-step (map/sideEffect) is one such sideEffect that
organizes the objects according to some function of the object. Then, if required, that organization (a list) is
reduced. An example is provided below.
gremlin> g.V().group().by(label) //// (1)
==>[software:[v[3],v[5]],person:[v[1],v[2],v[4],v[6]]]
gremlin> g.V().group().by(label).by('name') //// (2)
==>[software:[lop,ripple],person:[marko,vadas,josh,peter]]
gremlin> g.V().group().by(label).by(count()) //// (3)
==>[software:2,person:4]g.V().group().by(label) //// (1)
g.V().group().by(label).by('name') //// (2)
g.V().group().by(label).by(count()) //3-
Group the vertices by their label.
-
For each vertex in the group, get their name.
-
For each grouping, what is its size?
The two projection parameters available to group() via by() are:
-
Key-projection: What feature of the object to group on (a function that yields the map key)?
-
Value-projection: What feature of the group to store in the key-list?
gremlin> g.V().group().by('age').by('name') //// (1)
==>[32:[josh],35:[peter],27:[vadas],29:[marko]]
gremlin> g.V().group().by('name').by('age') //// (2)
==>[ripple:[],peter:[35],vadas:[27],josh:[32],lop:[],marko:[29]]g.V().group().by('age').by('name') //// (1)
g.V().group().by('name').by('age') //2-
The "age" property is not productive for all vertices and therefore those keys are filtered.
-
The "age" property is not productive for all vertices and therefore those values are filtered.
Additional References
GroupCount Step
When it is important to know how many times a particular object has been at a particular part of a traversal,
groupCount()-step (map/sideEffect) is used.
"What is the distribution of ages in the graph?"
gremlin> g.V().hasLabel('person').values('age').groupCount()
==>[32:1,35:1,27:1,29:1]
gremlin> g.V().hasLabel('person').groupCount().by('age') //// (1)
==>[32:1,35:1,27:1,29:1]
gremlin> g.V().groupCount().by('age') //// (2)
==>[32:1,35:1,27:1,29:1]g.V().hasLabel('person').values('age').groupCount()
g.V().hasLabel('person').groupCount().by('age') //// (1)
g.V().groupCount().by('age') //2-
You can also supply a pre-group projection, where the provided
by()-modulation determines what to group the incoming object by. -
The "age" property is not productive for all vertices and therefore those values are filtered.
There is one person that is 32, one person that is 35, one person that is 27, and one person that is 29.
"Iteratively walk the graph and count the number of times you see the second letter of each name."

gremlin> g.V().repeat(both().groupCount('m').by(label)).times(10).cap('m')
==>[software:19598,person:39196]g.V().repeat(both().groupCount('m').by(label)).times(10).cap('m')The above is interesting in that it demonstrates the use of referencing the internal Map<Object,Long> of
groupCount() with a string variable. Given that groupCount() is a sideEffect-step, it simply passes the object
it received to its output. Internal to groupCount(), the object’s count is incremented.
Additional References
Has Step

It is possible to filter vertices, edges, and vertex properties based on their properties using has()-step
(filter). There are numerous variations on has() including:
-
has(key,value): Remove the traverser if its element does not have the provided key/value property. -
has(label, key, value): Remove the traverser if its element does not have the specified label and provided key/value property. -
has(key,predicate): Remove the traverser if its element does not have a key value that satisfies the bi-predicate. For more information on predicates, please read A Note on Predicates. -
hasLabel(labels…): Remove the traverser if its element does not have any of the labels. -
hasId(ids…): Remove the traverser if its element does not have any of the ids. -
hasKey(keys…): Remove thePropertytraverser if it does not match one of the provided keys. -
hasValue(values…): Remove thePropertytraverser if it does not match one of the provided values. -
has(key): Remove the traverser if its element does not have a value for the key. -
hasNot(key): Remove the traverser if its element has a value for the key. -
has(key, traversal): Remove the traverser if its object does not yield a result through the traversal off the property value.
gremlin> g.V().hasLabel('person')
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().hasLabel('person','name','marko')
==>v[1]
==>v[2]
==>v[4]
==>v[6]
gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh'))
==>v[2]
==>v[4]
gremlin> g.V().hasLabel('person').out().has('name',within('vadas','josh')).
outE().hasLabel('created')
==>e[10][4-created->5]
==>e[11][4-created->3]
gremlin> g.V().has('age',inside(20,30)).values('age') //// (1)
==>29
==>27
gremlin> g.V().has('age',outside(20,30)).values('age') //// (2)
==>32
==>35
gremlin> g.V().has('name',within('josh','marko')).elementMap() //// (3)
==>[id:1,label:person,name:marko,age:29]
==>[id:4,label:person,name:josh,age:32]
gremlin> g.V().has('name',without('josh','marko')).elementMap() //// (4)
==>[id:2,label:person,name:vadas,age:27]
==>[id:3,label:software,name:lop,lang:java]
==>[id:5,label:software,name:ripple,lang:java]
==>[id:6,label:person,name:peter,age:35]
gremlin> g.V().has('name',not(within('josh','marko'))).elementMap() //// (5)
==>[id:2,label:person,name:vadas,age:27]
==>[id:3,label:software,name:lop,lang:java]
==>[id:5,label:software,name:ripple,lang:java]
==>[id:6,label:person,name:peter,age:35]
gremlin> g.V().properties().hasKey('age').value() //// (6)
==>29
==>27
==>32
==>35
gremlin> g.V().hasNot('age').values('name') //// (7)
==>lop
==>ripple
gremlin> g.V().has('person','name', startingWith('m')) //// (8)
==>v[1]
gremlin> g.V().has(null, 'vadas') //// (9)
gremlin> g.V().has(label, __.is('person')) //// (10)
==>v[1]
==>v[2]
==>v[4]
==>v[6]g.V().hasLabel('person')
g.V().hasLabel('person','name','marko')
g.V().hasLabel('person').out().has('name',within('vadas','josh'))
g.V().hasLabel('person').out().has('name',within('vadas','josh')).
outE().hasLabel('created')
g.V().has('age',inside(20,30)).values('age') //// (1)
g.V().has('age',outside(20,30)).values('age') //// (2)
g.V().has('name',within('josh','marko')).elementMap() //// (3)
g.V().has('name',without('josh','marko')).elementMap() //// (4)
g.V().has('name',not(within('josh','marko'))).elementMap() //// (5)
g.V().properties().hasKey('age').value() //// (6)
g.V().hasNot('age').values('name') //// (7)
g.V().has('person','name', startingWith('m')) //// (8)
g.V().has(null, 'vadas') //// (9)
g.V().has(label, __.is('person')) //10-
Find all vertices whose ages are between 20 (exclusive) and 30 (exclusive). In other words, the age must be greater than 20 and less than 30.
-
Find all vertices whose ages are not between 20 (inclusive) and 30 (inclusive). In other words, the age must be less than 20 or greater than 30.
-
Find all vertices whose names are exact matches to any names in the collection
[josh,marko], display all the key,value pairs for those vertices. -
Find all vertices whose names are not in the collection
[josh,marko], display all the key,value pairs for those vertices. -
Same as the prior example save using
notonwithinto yieldwithout. -
Find all age-properties and emit their value.
-
Find all vertices that do not have an age-property and emit their name.
-
Find all "person" vertices that have a name property that starts with the letter "m".
-
Property key is always stored as
Stringand therefore an equality check withnullwill produce no result. -
An example of
has()where the argument is aTraversaland does not quite behave the way most expect.
Item 10 in the above set of examples bears some discussion. The behavior is not such that the result of the Traversal
is used as the comparing value for has(), but the current Traverser, which in this case is the vertex label, is
given to the Traversal to behave as a filter itself. In other words, if the Traversal (i.e. is('person')) returns
a value then the has() is effectively true. A common mistake is to try to use select() in this context where one
would do has('name', select('n')) to try to inject the value of "n" into the step to get has('name', <value-of-n>),
but this would instead simply produce an always true filter for has().
TinkerPop does not support a regular expression predicate, although specific graph databases that leverage TinkerPop may provide a partial match extension.
Additional References
has(String),
has(String,Object),
has(String,P),
has(String,String,Object),
has(String,String,P),
has(String,Traversal),
has(T,Object),
has(T,P),
has(T,Traversal),
hasId(Object,Object…),
hasId(P),
hasKey(P),
hasKey(String,String…),
hasLabel(P),
hasLabel(String,String…),
hasNot(String),
hasValue(Object,Object…),
hasValue(P),
P,
TextP,
T,
Recipes - Anti-pattern
Id Step
The id()-step (map) takes an Element and extracts its identifier from it.
gremlin> g.V().id()
==>1
==>2
==>3
==>4
==>5
==>6
gremlin> g.V(1).out().id().is(2)
==>2
gremlin> g.V(1).outE().id()
==>9
==>7
==>8
gremlin> g.V(1).properties().id()
==>0
==>1g.V().id()
g.V(1).out().id().is(2)
g.V(1).outE().id()
g.V(1).properties().id()Additional References
Identity Step
The identity()-step (map) is an identity function which maps
the current object to itself.
gremlin> g.V().identity()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]g.V().identity()Additional References
Index Step
The index()-step (map) indexes each element in the current collection. If the current traverser’s value is not a collection, then it’s treated as a single-item collection. There are two indexers
available, which can be chosen using the with() modulator. The list indexer (default) creates a list for each collection item, with the first item being the original element and the second element
being the index. The map indexer created a linked hash map in which the index represents the key and the original item is used as the value.
gremlin> g.V().hasLabel("software").index() //// (1)
==>[[v[3],0]]
==>[[v[5],0]]
gremlin> g.V().hasLabel("software").values("name").fold().
order(Scope.local).
index().
unfold().
order().
by(__.tail(Scope.local, 1)) //// (2)
==>[lop,0]
==>[ripple,1]
gremlin> g.V().hasLabel("software").values("name").fold().
order(Scope.local).
index().
with(WithOptions.indexer, WithOptions.list).
unfold().
order().
by(__.tail(Scope.local, 1)) //// (3)
==>[lop,0]
==>[ripple,1]
gremlin> g.V().hasLabel("person").values("name").fold().
order(Scope.local).
index().
with(WithOptions.indexer, WithOptions.map) //// (4)
==>[0:josh,1:marko,2:peter,3:vadas]g.V().hasLabel("software").index() //// (1)
g.V().hasLabel("software").values("name").fold().
order(Scope.local).
index().
unfold().
order().
by(__.tail(Scope.local, 1)) //// (2)
g.V().hasLabel("software").values("name").fold().
order(Scope.local).
index().
with(WithOptions.indexer, WithOptions.list).
unfold().
order().
by(__.tail(Scope.local, 1)) //// (3)
g.V().hasLabel("person").values("name").fold().
order(Scope.local).
index().
with(WithOptions.indexer, WithOptions.map) //4-
Indexing non-collection items results in multiple indexed single-item collections.
-
Index all software names in their alphabetical order.
-
Same as statement 1, but with an explicitely specified list indexer.
-
Index all person names in their alphabetical order and store the result in an ordered map.
Additional References
Inject Step

The concept of "injectable steps" makes it possible to insert objects arbitrarily into a traversal stream. In general,
inject()-step (sideEffect) exists and a few examples are provided below.
gremlin> g.V(4).out().values('name').inject('daniel')
==>daniel
==>ripple
==>lop
gremlin> g.V(4).out().values('name').inject('daniel').map {it.get().length()}
==>6
==>6
==>3
gremlin> g.V(4).out().values('name').inject('daniel').map {it.get().length()}.path()
==>[daniel,6]
==>[v[4],v[5],ripple,6]
==>[v[4],v[3],lop,3]g.V(4).out().values('name').inject('daniel')
g.V(4).out().values('name').inject('daniel').map {it.get().length()}
g.V(4).out().values('name').inject('daniel').map {it.get().length()}.path()In the last example above, note that the path starting with daniel is only of length 2. This is because the
daniel string was inserted half-way in the traversal. Finally, a typical use case is provided below — when the
start of the traversal is not a graph object.
gremlin> inject(1,2)
==>1
==>2
gremlin> inject(1,2).map {it.get() + 1}
==>2
==>3
gremlin> inject(1,2).map {it.get() + 1}.map {g.V(it.get()).next()}.values('name')
==>vadas
==>lopinject(1,2)
inject(1,2).map {it.get() + 1}
inject(1,2).map {it.get() + 1}.map {g.V(it.get()).next()}.values('name')Additional References
Intersect Step
The intersect()-step (map) calculates the intersection between the incoming list traverser and the provided list
argument. This step only expects list data (array or Iterable) and will throw an IllegalArgumentException if any other
type is encountered (including null).
gremlin> g.V().values("name").fold().intersect(["marko","josh","james","jen"])
==>[josh,marko]
gremlin> g.V().values("name").fold().intersect(__.V().limit(2).values("name").fold())
==>[vadas,marko]g.V().values("name").fold().intersect(["marko","josh","james","jen"])
g.V().values("name").fold().intersect(__.V().limit(2).values("name").fold())Additional References
IO Step
 The task of importing and exporting the data of
The task of importing and exporting the data of Graph instances is the
job of the io()-step. By default, TinkerPop supports three formats for importing and exporting graph data in
GraphML, GraphSON, and Gryo.
|
Note
|
Additional documentation for TinkerPop IO formats can be found in the IO Reference. |
By itself the io()-step merely configures the kind of importing and exporting that is going
to occur and it is the follow-on call to the read() or write() step that determines which of those actions will
execute. Therefore, a typical usage of the io()-step would look like this:
g.io(someInputFile).read().iterate()
g.io(someOutputFile).write().iterate()|
Important
|
The commands above are still traversals and therefore require iteration to be executed, hence the use of
iterate() as a termination step.
|
By default, the io()-step will try to detect the right file format using the file name extension. To gain greater
control of the format use the with() step modulator to provide further information to io(). For example:
g.io(someInputFile).
with(IO.reader, IO.graphson).
read().iterate()
g.io(someOutputFile).
with(IO.writer,IO.graphml).
write().iterate()The IO class is a helper for the io()-step that provides expressions that can be used to help configure it
and in this case it allows direct specification of the "reader" or "writer" to use. The "reader" actually refers to
a GraphReader implementation and the "writer" refers to a GraphWriter implementation. The implementations of
those interfaces provided by default are the standard TinkerPop implementations.
That default is an important point to consider for users. The default TinkerPop implementations are not designed with massive, complex, parallel bulk loading in mind. They are designed to do single-threaded, OLTP-style loading of data in the most generic way possible so as to accommodate the greatest number of graph databases out there. As such, from a reading perspective, they work best for small datasets (or perhaps medium datasets where memory is plentiful and time is not critical) that are loading to an empty graph - incremental loading is not supported. The story from the writing perspective is not that different in there are no parallel operations in play, however streaming the output to disk requires a single pass of the data without high memory requirements for larger datasets.
|
Important
|
Default graph formats don’t contain information about property cardinality, so it is up to the graph provider to choose the appropriate one. You will see a warning message if the chosen cardinality is SINGLE while your graph input contains multiple values for that property. |
In general, TinkerPop recommends that users examine the native bulk import/export tools of the graph implementation
that they choose. Those tools will often outperform the io()-step and perhaps be easier to use with a greater
feature set. That said, graph providers do have the option to optimize io() to back it with their own
import/export utilities and therefore the default behavior provided by TinkerPop described above might be overridden
by the graph.
An excellent example of this lies in HadoopGraph with SparkGraphComputer
which replaces the default single-threaded implementation with a more advanced OLAP style bulk import/export
functionality internally using CloneVertexProgram. With this model, graphs of arbitrary size
can be imported/exported assuming that there is a Hadoop InputFormat or OutputFormat to support it.
|
Important
|
Remote Gremlin Console users or Gremlin Language Variant (GLV) users (e.g. gremlin-python) who utilize
the io()-step should recall that their read() or write() operation will occur on the server and not locally
and therefore the file specified for import/export must be something accessible by the server.
|
GraphSON and Gryo formats are extensible allowing users and graph providers to extend supported serialization options.
These extensions are exposed through IoRegistry implementations. To apply an IoRegistry use the with() option
and the IO.registry key, where the value is either an actual IoRegistry instance or the fully qualified class
name of one.
g.io(someInputFile).
with(IO.reader, IO.gryo).
with(IO.registry, TinkerIoRegistryV3d0.instance())
read().iterate()
g.io(someOutputFile).
with(IO.writer,IO.graphson).
with(IO.registry, "org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerIoRegistryV3d0")
write().iterate()GLVs will obviously always be forced to use the latter form as they can’t explicitly create an instance of an
IoRegistry to pass to the server (nor are IoRegistry instances necessarily serializable).
The version of the formats (e.g. GraphSON 2.0 or 3.0) utilized by io() is determined entirely by the IO.reader and
IO.writer configurations or their defaults. The defaults will always be the latest version for the current release
of TinkerPop. It is also possible for graph providers to override these defaults, so consult the documentation of the
underlying graph database in use for any details on that.
|
Note
|
The io() step will try to automatically detect the appropriate GraphReader or GraphWriter to use based on
the file extension. If the file has a different extension than the ones expected, use with() as shown above to set the
reader or writer explicitly.
|
For more advanced configuration of GraphReader and GraphWriter operations (e.g. normalized output for GraphSON,
disabling class registrations for Gryo, etc.) then construct the appropriate GraphReader and GraphWriter using
the build() method on their implementations and use it directly. It can be passed directly to the IO.reader or
IO.writer options. Obviously, these are JVM based operations and thus not available to GLVs as portable features.
GraphML
 The GraphML file format is a
common XML-based representation of a graph. It is widely supported by graph-related tools and libraries making it a
solid interchange format for TinkerPop. In other words, if the intent is to work with graph data in conjunction with
applications outside of TinkerPop, GraphML may be the best choice to do that. Common use cases might be:
The GraphML file format is a
common XML-based representation of a graph. It is widely supported by graph-related tools and libraries making it a
solid interchange format for TinkerPop. In other words, if the intent is to work with graph data in conjunction with
applications outside of TinkerPop, GraphML may be the best choice to do that. Common use cases might be:
|
Warning
|
GraphML is a "lossy" format in that it only supports primitive values for properties and does not have
support for Graph variables. It will use toString to serialize property values outside of those primitives.
|
|
Warning
|
GraphML as a specification allows for <edge> and <node> elements to appear in any order. Most software
that writes GraphML (including as TinkerPop’s GraphMLWriter) write <node> elements before <edge> elements.
However it is important to note that GraphMLReader will read this data in order and order can matter. This is because
TinkerPop does not allow the vertex label to be changed after the vertex has been created. Therefore, if an <edge>
element comes before the <node>, the label on the vertex will be ignored. It is thus better to order <node>
elements in the GraphML to appear before all <edge> elements if vertex labels are important to the graph.
|
// expects a file extension of .xml or .graphml to determine that
// a GraphML reader/writer should be used.
g.io("graph.xml").read().iterate();
g.io("graph.xml").write().iterate();|
Note
|
If using GraphML generated from TinkerPop 2.x, read more about its incompatibilities in the Upgrade Documentation. |
GraphSON
 GraphSON is a JSON-based format extended
from earlier versions of TinkerPop. It is important to note that TinkerPop’s GraphSON is not backwards compatible
with prior TinkerPop GraphSON versions. GraphSON has some support from graph-related application outside of TinkerPop,
but it is generally best used in two cases:
GraphSON is a JSON-based format extended
from earlier versions of TinkerPop. It is important to note that TinkerPop’s GraphSON is not backwards compatible
with prior TinkerPop GraphSON versions. GraphSON has some support from graph-related application outside of TinkerPop,
but it is generally best used in two cases:
-
A text format of the graph or its elements is desired (e.g. debugging, usage in source control, etc.)
-
The graph or its elements need to be consumed by code that is not JVM-based (e.g. JavaScript, Python, .NET, etc.)
// expects a file extension of .json to interpret that
// a GraphSON reader/writer should be used
g.io("graph.json").read().iterate();
g.io("graph.json").write().iterate();|
Note
|
Additional documentation for GraphSON can be found in the IO Reference. |
Gryo
 Kryo is a popular
serialization package for the JVM. Gremlin-Kryo is a binary
Kryo is a popular
serialization package for the JVM. Gremlin-Kryo is a binary Graph serialization format for use on the JVM by JVM
languages. It is designed to be space efficient, non-lossy and is promoted as the standard format to use when working
with graph data inside of the TinkerPop stack. A list of common use cases is presented below:
-
Migration from one Gremlin Structure implementation to another (e.g.
TinkerGraphtoNeo4jGraph) -
Serialization of individual graph elements to be sent over the network to another JVM.
-
Backups of in-memory graphs or subgraphs.
|
Warning
|
When migrating between Gremlin Structure implementations, Kryo may not lose data, but it is important to
consider the features of each Graph and whether or not the data types supported in one will be supported in the
other. Failure to do so, may result in errors.
|
// expects a file extension of .kryo to interpret that
// a GraphSON reader/writer should be used
g.io("graph.kryo").read().iterate()
g.io("graph.kryo").write().iterate()Additional References
Is Step
It is possible to filter scalar values using is()-step (filter).
|
Python
|
The term |
gremlin> g.V().values('age').is(32)
==>32
gremlin> g.V().values('age').is(lte(30))
==>29
==>27
gremlin> g.V().values('age').is(inside(30, 40))
==>32
==>35
gremlin> g.V().where(__.in('created').count().is(1)).values('name') //// (1)
==>ripple
gremlin> g.V().where(__.in('created').count().is(gte(2))).values('name') //// (2)
==>lop
gremlin> g.V().where(__.in('created').values('age').
mean().is(inside(30d, 35d))).values('name') //// (3)
==>lop
==>rippleg.V().values('age').is(32)
g.V().values('age').is(lte(30))
g.V().values('age').is(inside(30, 40))
g.V().where(__.in('created').count().is(1)).values('name') //// (1)
g.V().where(__.in('created').count().is(gte(2))).values('name') //// (2)
g.V().where(__.in('created').values('age').
mean().is(inside(30d, 35d))).values('name') //3-
Find projects having exactly one contributor.
-
Find projects having two or more contributors.
-
Find projects whose contributors average age is between 30 and 35.
Additional References
is(Object),
is(P),
P
Key Step
The key()-step (map) takes a Property and extracts the key from it.
gremlin> g.V(1).properties().key()
==>name
==>location
==>location
==>location
==>location
gremlin> g.V(1).properties().properties().key()
==>startTime
==>endTime
==>startTime
==>endTime
==>startTime
==>endTime
==>startTimeg.V(1).properties().key()
g.V(1).properties().properties().key()Additional References
Label Step
The label()-step (map) takes an Element and extracts its label from it.
gremlin> g.V().label()
==>person
==>person
==>software
==>person
==>software
==>person
gremlin> g.V(1).outE().label()
==>created
==>knows
==>knows
gremlin> g.V(1).properties().label()
==>name
==>ageg.V().label()
g.V(1).outE().label()
g.V(1).properties().label()Additional References
Length Step
The length()-step (map) returns the length incoming string or list of string traverser. Null values are not processed and remain as null when returned.
If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.V().values('name').length() //// (1)
==>5
==>5
==>3
==>4
==>6
==>5
gremlin> g.V().values('name').fold().length(local) //// (2)
==>[5,5,3,4,6,5]g.V().values('name').length() //// (1)
g.V().values('name').fold().length(local) //2-
Return the string length of all vertex names.
-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
Limit Step
The limit()-step is analogous to range()-step save that the lower end range is set to 0.
gremlin> g.V().limit(2)
==>v[1]
==>v[2]
gremlin> g.V().range(0, 2)
==>v[1]
==>v[2]g.V().limit(2)
g.V().range(0, 2)The limit()-step can also be applied with Scope.local, in which case it operates on the incoming collection.
The examples below use the The Crew toy data set.
gremlin> g.V().valueMap().select('location').limit(local,2) //// (1)
==>[san diego,santa cruz]
==>[centreville,dulles]
==>[bremen,baltimore]
==>[spremberg,kaiserslautern]
gremlin> g.V().valueMap().limit(local, 1) //// (2)
==>[name:[marko]]
==>[name:[stephen]]
==>[name:[matthias]]
==>[name:[daniel]]
==>[name:[gremlin]]
==>[name:[tinkergraph]]g.V().valueMap().select('location').limit(local,2) //// (1)
g.V().valueMap().limit(local, 1) //2-
List<String>for each vertex containing the first two locations. -
Map<String, Object>for each vertex, but containing only the first property value.
Additional References
Local Step

A GraphTraversal operates on a continuous stream of objects. In many situations, it is important to operate on a
single element within that stream. To do such object-local traversal computations, local()-step exists (branch).
Note that the examples below use the The Crew toy data set.
gremlin> g.V().as('person').
properties('location').order().by('startTime',asc).limit(2).value().as('location').
select('person','location').by('name').by() //// (1)
==>[person:daniel,location:spremberg]
==>[person:stephen,location:centreville]
gremlin> g.V().as('person').
local(properties('location').order().by('startTime',asc).limit(2)).value().as('location').
select('person','location').by('name').by() //// (2)
==>[person:marko,location:san diego]
==>[person:marko,location:santa cruz]
==>[person:stephen,location:centreville]
==>[person:stephen,location:dulles]
==>[person:matthias,location:bremen]
==>[person:matthias,location:baltimore]
==>[person:daniel,location:spremberg]
==>[person:daniel,location:kaiserslautern]g.V().as('person').
properties('location').order().by('startTime',asc).limit(2).value().as('location').
select('person','location').by('name').by() //// (1)
g.V().as('person').
local(properties('location').order().by('startTime',asc).limit(2)).value().as('location').
select('person','location').by('name').by() //2-
Get the first two people and their respective location according to the most historic location start time.
-
For every person, get their two most historic locations.
The two traversals above look nearly identical save the inclusion of local() which wraps a section of the traversal
in an object-local traversal. As such, the order().by() and the limit() refer to a particular object, not to the
stream as a whole.
Local Step is quite similar in functionality to Flat Map Step where it can often be confused.
local() propagates the traverser through the internal traversal as is without splitting/cloning it. Thus, its
a “global traversal” with local processing. Its use is subtle and primarily finds application in compilation
optimizations (i.e. when writing TraversalStrategy implementations. As another example consider:
gremlin> g.V().both().barrier().flatMap(groupCount().by("name"))
==>[lop:1]
==>[lop:1]
==>[lop:1]
==>[vadas:1]
==>[josh:1]
==>[josh:1]
==>[josh:1]
==>[marko:1]
==>[marko:1]
==>[marko:1]
==>[peter:1]
==>[ripple:1]
gremlin> g.V().both().barrier().local(groupCount().by("name"))
==>[lop:3]
==>[vadas:1]
==>[josh:3]
==>[marko:3]
==>[peter:1]
==>[ripple:1]g.V().both().barrier().flatMap(groupCount().by("name"))
g.V().both().barrier().local(groupCount().by("name"))Use of local() is often a mistake. This is especially true when its argument contains a reducing step. For example,
let’s say the requirement was to count the number of properties per Vertex in:
gremlin> g.V().both().local(properties('name','age').count()) //// (1)
==>3
==>2
==>6
==>6
==>2
==>1
gremlin> g.V().both().map(properties('name','age').count()) //// (2)
==>1
==>1
==>1
==>2
==>2
==>2
==>2
==>2
==>2
==>2
==>2
==>1g.V().both().local(properties('name','age').count()) //// (1)
g.V().both().map(properties('name','age').count()) //2-
The output here seems impossible because no single vertex in the "modern" graph can have more than two properties given the "name" and "age" filters, but because the counting is happening object-local the counting is occurring unique to each object rather than each global traverser.
-
Replacing
local()withmap()returns the result desired by the requirement.
|
Warning
|
The anonymous traversal of local() processes the current object "locally." In OLAP, where the atomic unit
of computing is the vertex and its local "star graph," it is important that the anonymous traversal does not leave
the confines of the vertex’s star graph. In other words, it can not traverse to an adjacent vertex’s properties or edges.
|
Additional References
Loops Step
The loops()-step (map) extracts the number of times the Traverser has gone through the current loop.
gremlin> g.V().emit(__.has("name", "marko").or().loops().is(2)).repeat(__.out()).values("name")
==>marko
==>ripple
==>lopg.V().emit(__.has("name", "marko").or().loops().is(2)).repeat(__.out()).values("name")Additional References
LTrim Step
The lTrim()-step (map) returns a string with leading whitespace removed. Null values are not processed and remain
as null when returned. If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.inject(" hello ", " world ", null).lTrim()
==>hello
==>world
==>null
gremlin> g.inject([" hello ", " world ", null]).lTrim(local) //// (1)
==>[hello ,world ,null]g.inject(" hello ", " world ", null).lTrim()
g.inject([" hello ", " world ", null]).lTrim(local) //1-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Map Step
The map() step maps the traverser from the current object to the next step in the process. Please see the
General Steps section for more information.
Additional References
Match Step
The match()-step (map) provides a more declarative
form of graph querying based on the notion of pattern matching.
With match(), the user provides a collection of "traversal fragments," called patterns, that have variables defined
that must hold true throughout the duration of the match(). When a traverser is in match(), a registered
MatchAlgorithm analyzes the current state of the traverser (i.e. its history based on its
path data), the runtime statistics of the traversal patterns, and returns a traversal-pattern
that the traverser should try next. The default MatchAlgorithm provided is called CountMatchAlgorithm and it
dynamically revises the pattern execution plan by sorting the patterns according to their filtering capabilities
(i.e. largest set reduction patterns execute first). For very large graphs, where the developer is uncertain of the
statistics of the graph (e.g. how many knows-edges vs. worksFor-edges exist in the graph), it is advantageous to
use match(), as an optimal plan will be determined automatically. Furthermore, some queries are much easier to
express via match() than with single-path traversals.
"Who created a project named 'lop' that was also created by someone who is 29 years old? Return the two creators."

gremlin> g.V().match(
__.as('a').out('created').as('b'),
__.as('b').has('name', 'lop'),
__.as('b').in('created').as('c'),
__.as('c').has('age', 29)).
select('a','c').by('name')
==>[a:marko,c:marko]
==>[a:josh,c:marko]
==>[a:peter,c:marko]g.V().match(
__.as('a').out('created').as('b'),
__.as('b').has('name', 'lop'),
__.as('b').in('created').as('c'),
__.as('c').has('age', 29)).
select('a','c').by('name')Note that the above can also be more concisely written as below which demonstrates that standard inner-traversals can be arbitrarily defined.
gremlin> g.V().match(
__.as('a').out('created').has('name', 'lop').as('b'),
__.as('b').in('created').has('age', 29).as('c')).
select('a','c').by('name')
==>[a:marko,c:marko]
==>[a:josh,c:marko]
==>[a:peter,c:marko]g.V().match(
__.as('a').out('created').has('name', 'lop').as('b'),
__.as('b').in('created').has('age', 29).as('c')).
select('a','c').by('name')In order to improve readability, as()-steps can be given meaningful labels which better reflect your domain. The
previous query can thus be written in a more expressive way as shown below.
gremlin> g.V().match(
__.as('creators').out('created').has('name', 'lop').as('projects'), //// (1)
__.as('projects').in('created').has('age', 29).as('cocreators')). //// (2)
select('creators','cocreators').by('name') //// (3)
==>[creators:marko,cocreators:marko]
==>[creators:josh,cocreators:marko]
==>[creators:peter,cocreators:marko]g.V().match(
__.as('creators').out('created').has('name', 'lop').as('projects'), //// (1)
__.as('projects').in('created').has('age', 29).as('cocreators')). //// (2)
select('creators','cocreators').by('name') //3-
Find vertices that created something and match them as 'creators', then find out what they created which is named 'lop' and match these vertices as 'projects'.
-
Using these 'projects' vertices, find out their creators aged 29 and remember these as 'cocreators'.
-
Return the name of both 'creators' and 'cocreators'.

MatchStep brings functionality similar to SPARQL to Gremlin. Like SPARQL,
MatchStep conjoins a set of patterns applied to a graph. For example, the following traversal finds exactly those
songs which Jerry Garcia has both sung and written (using the Grateful Dead graph distributed in the data/ directory):
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> g.V().match(
__.as('a').has('name', 'Garcia'),
__.as('a').in('writtenBy').as('b'),
__.as('a').in('sungBy').as('b')).
select('b').values('name')
==>CREAM PUFF WAR
==>CRYPTICAL ENVELOPMENTg = traversal().with(graph)
g.io('data/grateful-dead.xml').read().iterate()
g.V().match(
__.as('a').has('name', 'Garcia'),
__.as('a').in('writtenBy').as('b'),
__.as('a').in('sungBy').as('b')).
select('b').values('name')Among the features which differentiate match() from SPARQL are:
gremlin> g.V().match(
__.as('a').out('created').has('name','lop').as('b'), //// (1)
__.as('b').in('created').has('age', 29).as('c'),
__.as('c').repeat(out()).times(2)). //// (2)
select('c').out('knows').dedup().values('name') //// (3)
==>vadas
==>joshg.V().match(
__.as('a').out('created').has('name','lop').as('b'), //// (1)
__.as('b').in('created').has('age', 29).as('c'),
__.as('c').repeat(out()).times(2)). //// (2)
select('c').out('knows').dedup().values('name') //3-
Patterns of arbitrary complexity:
match()is not restricted to triple patterns or property paths. -
Recursion support:
match()supports the branch-based steps within a pattern, includingrepeat(). -
Imperative/declarative hybrid: Before and after a
match(), it is possible to leverage classic Gremlin traversals.
To extend point #3, it is possible to support going from imperative, to declarative, to imperative, ad infinitum.
gremlin> g.V().match(
__.as('a').out('knows').as('b'),
__.as('b').out('created').has('name','lop')).
select('b').out('created').
match(
__.as('x').in('created').as('y'),
__.as('y').out('knows').as('z')).
select('z').values('name')
==>vadas
==>joshg.V().match(
__.as('a').out('knows').as('b'),
__.as('b').out('created').has('name','lop')).
select('b').out('created').
match(
__.as('x').in('created').as('y'),
__.as('y').out('knows').as('z')).
select('z').values('name')|
Important
|
The match()-step is stateless. The variable bindings of the traversal patterns are stored in the path
history of the traverser. As such, the variables used over all match()-steps within a traversal are globally unique.
A benefit of this is that subsequent where(), select(), match(), etc. steps can leverage the same variables in
their analysis.
|
Like all other steps in Gremlin, match() is a function and thus, match() within match() is a natural consequence
of Gremlin’s functional foundation (i.e. recursive matching).
gremlin> g.V().match(
__.as('a').out('knows').as('b'),
__.as('b').out('created').has('name','lop'),
__.as('b').match(
__.as('b').out('created').as('c'),
__.as('c').has('name','ripple')).
select('c').as('c')).
select('a','c').by('name')
==>[a:marko,c:ripple]g.V().match(
__.as('a').out('knows').as('b'),
__.as('b').out('created').has('name','lop'),
__.as('b').match(
__.as('b').out('created').as('c'),
__.as('c').has('name','ripple')).
select('c').as('c')).
select('a','c').by('name')If a step-labeled traversal proceeds the match()-step and the traverser entering the match() is destined to bind
to a particular variable, then the previous step should be labeled accordingly.
gremlin> g.V().as('a').out('knows').as('b').
match(
__.as('b').out('created').as('c'),
__.not(__.as('c').in('created').as('a'))).
select('a','b','c').by('name')
==>[a:marko,b:josh,c:ripple]g.V().as('a').out('knows').as('b').
match(
__.as('b').out('created').as('c'),
__.not(__.as('c').in('created').as('a'))).
select('a','b','c').by('name')There are three types of match() traversal patterns.
-
as('a')…as('b'): both the start and end of the traversal have a declared variable. -
as('a')…: only the start of the traversal has a declared variable. -
…: there are no declared variables.
If a variable is at the start of a traversal pattern it must exist as a label in the path history of the traverser
else the traverser can not go down that path. If a variable is at the end of a traversal pattern then if the variable
exists in the path history of the traverser, the traverser’s current location must match (i.e. equal) its historic
location at that same label. However, if the variable does not exist in the path history of the traverser, then the
current location is labeled as the variable and thus, becomes a bound variable for subsequent traversal patterns. If a
traversal pattern does not have an end label, then the traverser must simply "survive" the pattern (i.e. not be
filtered) to continue to the next pattern. If a traversal pattern does not have a start label, then the traverser
can go down that path at any point, but will only go down that pattern once as a traversal pattern is executed once
and only once for the history of the traverser. Typically, traversal patterns that do not have a start and end label
are used in conjunction with and(), or(), and where(). Once the traverser has "survived" all the patterns (or at
least one for or()), match()-step analyzes the traverser’s path history and emits a Map<String,Object> of the
variable bindings to the next step in the traversal.
gremlin> g.V().as('a').out().as('b'). //// (1)
match( //// (2)
__.as('a').out().count().as('c'), //// (3)
__.not(__.as('a').in().as('b')), //// (4)
or( //// (5)
__.as('a').out('knows').as('b'),
__.as('b').in().count().as('c').and().as('c').is(gt(2)))). //// (6)
dedup('a','c'). //// (7)
select('a','b','c').by('name').by('name').by() //// (8)
==>[a:marko,b:lop,c:3]g.V().as('a').out().as('b'). //// (1)
match( //// (2)
__.as('a').out().count().as('c'), //// (3)
__.not(__.as('a').in().as('b')), //// (4)
or( //// (5)
__.as('a').out('knows').as('b'),
__.as('b').in().count().as('c').and().as('c').is(gt(2)))). //// (6)
dedup('a','c'). //// (7)
select('a','b','c').by('name').by('name').by() //8-
A standard, step-labeled traversal can come prior to
match(). -
If the traverser’s path prior to entering
match()has requisite label values, then those historic values are bound. -
It is possible to use barrier steps though they are computed locally to the pattern (as one would expect).
-
It is possible to
not()a pattern. -
It is possible to nest
and()- andor()-steps for conjunction matching. -
Both infix and prefix conjunction notation is supported.
-
It is possible to "distinct" the specified label combination.
-
The bound values are of different types — vertex ("a"), vertex ("b"), long ("c").
Using Where with Match
Match is typically used in conjunction with both select() (demonstrated previously) and where() (presented here).
A where()-step allows the user to further constrain the result set provided by match().
gremlin> g.V().match(
__.as('a').out('created').as('b'),
__.as('b').in('created').as('c')).
where('a', neq('c')).
select('a','c').by('name')
==>[a:marko,c:josh]
==>[a:marko,c:peter]
==>[a:josh,c:marko]
==>[a:josh,c:peter]
==>[a:peter,c:marko]
==>[a:peter,c:josh]g.V().match(
__.as('a').out('created').as('b'),
__.as('b').in('created').as('c')).
where('a', neq('c')).
select('a','c').by('name')The where()-step can take either a P-predicate (example above) or a Traversal (example below). Using
MatchPredicateStrategy, where()-clauses are automatically folded into match() and thus, subject to the query
optimizer within match()-step.
gremlin> traversal = g.V().match(
__.as('a').has(label,'person'), //// (1)
__.as('a').out('created').as('b'),
__.as('b').in('created').as('c')).
where(__.as('a').out('knows').as('c')). //// (2)
select('a','c').by('name'); null //// (3)
==>null
gremlin> traversal.toString() //// (4)
==>[GraphStep(vertex,[]), MatchStep(null,AND,[[MatchStartStep(a), HasStep([~label.eq(person)]), MatchEndStep(null)], [MatchStartStep(a), VertexStep(OUT,[created],vertex), MatchEndStep(b)], [MatchStartStep(b), VertexStep(IN,[created],vertex), MatchEndStep(c)]]), WhereTraversalStep([WhereStartStep(a), VertexStep(OUT,[knows],vertex), WhereEndStep(c)]), SelectStep(last,[a, c],[value(name)])]
gremlin> traversal // // (5) (6)
==>[a:marko,c:josh]
gremlin> traversal.toString() //// (7)
==>[TinkerGraphStep(vertex,[~label.eq(person)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,[created],vertex), MatchEndStep(b)], [MatchStartStep(b), VertexStep(IN,[created],vertex), MatchEndStep(c)], [MatchStartStep(a), WhereTraversalStep([WhereStartStep(null), VertexStep(OUT,[knows],vertex), WhereEndStep(c)]), MatchEndStep(null)]]), SelectStep(last,[a, c],[value(name)])]traversal = g.V().match(
__.as('a').has(label,'person'), //// (1)
__.as('a').out('created').as('b'),
__.as('b').in('created').as('c')).
where(__.as('a').out('knows').as('c')). //// (2)
select('a','c').by('name'); null //// (3)
traversal.toString() //// (4)
traversal // // (5) (6) (5)
traversal.toString() //7-
Any
has()-step traversal patterns that start with the match-key are pulled out ofmatch()to enable the graph system to leverage the filter for index lookups. -
A
where()-step with a traversal containing variable bindings declared inmatch(). -
A useful trick to ensure that the traversal is not iterated by Gremlin Console.
-
The string representation of the traversal prior to its strategies being applied.
-
The Gremlin Console will automatically iterate anything that is an iterator or is iterable.
-
Both marko and josh are co-developers and marko knows josh.
-
The string representation of the traversal after the strategies have been applied (and thus,
where()is folded intomatch())
|
Important
|
A where()-step is a filter and thus, variables within a where() clause are not globally bound to the
path of the traverser in match(). As such, where()-steps in match() are used for filtering, not binding.
|
Additional References
Math Step
The math()-step (math) enables scientific calculator functionality within Gremlin. This step deviates from the common
function composition and nesting formalisms to provide an easy to read string-based math processor. Variables within the
equation map to scopes in Gremlin — e.g. path labels, side-effects, or incoming map keys. This step supports
by()-modulation where the by()-modulators are applied in the order in which the variables are first referenced
within the equation. Note that the reserved variable _ refers to the current numeric traverser object incoming to the
math()-step.
gremlin> g.V().as('a').out('knows').as('b').math('a + b').by('age')
==>56.0
==>61.0
gremlin> g.V().as('a').out('created').as('b').
math('b + a').
by(both().count().math('_ + 100')).
by('age')
==>132.0
==>133.0
==>135.0
==>138.0
gremlin> g.withSideEffect('x',10).V().values('age').math('_ / x')
==>2.9
==>2.7
==>3.2
==>3.5
gremlin> g.withSack(1).V(1).repeat(sack(sum).by(constant(1))).times(10).emit().sack().math('sin _')
==>0.9092974268256817
==>0.1411200080598672
==>-0.7568024953079282
==>-0.9589242746631385
==>-0.27941549819892586
==>0.6569865987187891
==>0.9893582466233818
==>0.4121184852417566
==>-0.5440211108893698
==>-0.9999902065507035
gremlin> g.V().math('_+1').by('age') //// (1)
==>30.0
==>28.0
==>33.0
==>36.0g.V().as('a').out('knows').as('b').math('a + b').by('age')
g.V().as('a').out('created').as('b').
math('b + a').
by(both().count().math('_ + 100')).
by('age')
g.withSideEffect('x',10).V().values('age').math('_ / x')
g.withSack(1).V(1).repeat(sack(sum).by(constant(1))).times(10).emit().sack().math('sin _')
g.V().math('_+1').by('age') //1-
The "age" property is not productive for all vertices and therefore those values are filtered.
The operators supported by the calculator include: *, +, /, ^, and %. Furthermore, the following built in
functions are provided:
-
abs: absolute value -
acos: arc cosine -
asin: arc sine -
atan: arc tangent -
cbrt: cubic root -
ceil: nearest upper integer -
cos: cosine -
cosh: hyperbolic cosine -
exp: euler’s number raised to the power (e^x) -
floor: nearest lower integer -
log: logarithmus naturalis (base e) -
log10: logarithm (base 10) -
log2: logarithm (base 2) -
sin: sine -
sinh: hyperbolic sine -
sqrt: square root -
tan: tangent -
tanh: hyperbolic tangent -
signum: signum function
Additional References
Max Step
The max()-step (map) operates on a stream of comparable objects and determines which is the last object according
to its natural order in the stream.
gremlin> g.V().values('age').max()
==>35
gremlin> g.V().repeat(both()).times(3).values('age').max()
==>35
gremlin> g.V().values('name').max()
==>vadasg.V().values('age').max()
g.V().repeat(both()).times(3).values('age').max()
g.V().values('name').max()When called as max(local) it determines the maximum value of the current, local object (not the objects in the
traversal stream). This works for Collection and Comparable-type objects.
gremlin> g.V().values('age').fold().max(local)
==>35g.V().values('age').fold().max(local)When there are null values being evaluated the null objects are ignored, but if all values are recognized as null
the return value is null.
gremlin> g.inject(null,10, 9, null).max()
==>10
gremlin> g.inject([null,null,null]).max(local)
==>nullg.inject(null,10, 9, null).max()
g.inject([null,null,null]).max(local)Additional References
Mean Step
The mean()-step (map) operates on a stream of numbers and determines the average of those numbers.
gremlin> g.V().values('age').mean()
==>30.75
gremlin> g.V().repeat(both()).times(3).values('age').mean() //// (1)
==>30.645833333333332
gremlin> g.V().repeat(both()).times(3).values('age').dedup().mean()
==>30.75g.V().values('age').mean()
g.V().repeat(both()).times(3).values('age').mean() //// (1)
g.V().repeat(both()).times(3).values('age').dedup().mean()-
Realize that traversers are being bulked by
repeat(). There may be more of a particular number than another, thus altering the average.
When called as mean(local) it determines the mean of the current, local object (not the objects in the traversal
stream). This works for Collection and Number-type objects.
gremlin> g.V().values('age').fold().mean(local)
==>30.75g.V().values('age').fold().mean(local)If mean() encounters null values, they will be ignored (i.e. their traversers not counted toward toward the
divisor). If all traversers are null then the stream will return null.
gremlin> g.inject(null,10, 9, null).mean()
==>9.5
gremlin> g.inject([null,null,null]).mean(local)
==>nullg.inject(null,10, 9, null).mean()
g.inject([null,null,null]).mean(local)Additional References
Merge Step
The merge()-step (map) combines collections like lists and maps. It expects an incoming traverser to contain a
collection objection and will combine that object with its specified argument which must be of a matching type. This is
also known as the union operation. If the incoming traverser or its associated argument do not meet the expected type,
the step will throw an IllegalArgumentException if any other type is encountered (including null). This step differs
from the combine()-step in that it doesn’t allow duplicates.
gremlin> g.V().values("name").fold().merge(["james","jen","marko","vadas"])
==>[jen,ripple,peter,vadas,james,josh,lop,marko]
gremlin> g.V().values("name").fold().merge(__.constant("james").fold())
==>[ripple,peter,vadas,james,josh,lop,marko]
gremlin> g.V().hasLabel('software').elementMap().merge([year:2009])
==>[name:lop,label:software,lang:java,year:2009,id:3]
==>[name:ripple,label:software,lang:java,year:2009,id:5]g.V().values("name").fold().merge(["james","jen","marko","vadas"])
g.V().values("name").fold().merge(__.constant("james").fold())
g.V().hasLabel('software').elementMap().merge([year:2009])Additional References
MergeEdge Step
The mergeE() step is used to add edges and their properties to a graph in a "create
if not exist" fashion. The mergeE() step can also be used to find edges matching a given
pattern. The input passed to mergeE() can be either a Map, or a child traversal that
produces a Map.
|
Note
|
There is a corresponding mergeV() step that can be used when creating vertices.
|
Additionally, option() modulators may be combined with mergeE() to take action depending on
whether a vertex was created, or already existed. There are various ways that mergeE() can
be used. The simplest being to provide a single Map of keys and values, along with the
source and target vertex IDs, as a parameter. A T.id and a T.label may also be provided but
this is optional. The mergeE() step can be used directly from the GraphTraversalSource - g,
or in the middle of a traversal. For a match with an existing vertex to occur, all values
in the Map must exist on a vertex; otherwise, a new vertex will be created. The examples
that follow show how mergeE() can be used to add relationships between dogs in the graph.
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])
==>v[1]
gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy']) //// (1)
==>v[2]
gremlin> g.mergeE([(T.label):'Sibling',created:'2022-02-07',(Direction.from):1,(Direction.to):2]) //// (2)
==>e[2][1-Sibling->2]
gremlin> g.E().elementMap()
==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])
g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy']) //// (1)
g.mergeE([(T.label):'Sibling',created:'2022-02-07',(Direction.from):1,(Direction.to):2]) //// (2)
g.E().elementMap()-
Create two vertices with ID values of 1 and 2.
-
Create a "Sibling" relationship between the vertices.
|
Note
|
The example above is written with gremlin-groovy and evaluated in Gremlin Console as a Groovy script thus
allowing Groovy syntax for initializing a Map.
|
For a mergeE() step to succeed, both the from and to vertices must already exist. It
is not possible to create new vertices directly using mergeE(), but mergeV() and mergeE()
steps can be combined, in a single query, to achieve that goal.
|
Note
|
The mergeE() step will not create vertices that do not exist. In those cases an
error will be returned.
|
If the Direction enum has been statically included, its explicit use can be omitted from
the query.
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])
==>v[1]
gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])
==>v[2]
gremlin> g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):1,(to):2])
==>e[2][1-Sibling->2]
gremlin> g.E().elementMap()
==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])
g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])
g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):1,(to):2])
g.E().elementMap()One or more option() steps can be used to control the behavior when an edge is created or
updated. Similar to mergeV(), the onCreate Map inherits from the main merge argument - any
existence criteria in the main merge argument (T.id, T.label, Direction.OUT, Direction.IN)
will be automatically carried over to the onCreate action, and these existence criteria cannot be overriden
in the onCreate Map.
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])
==>v[1]
gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])
==>v[2]
gremlin> g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]).
mergeE(select('map')).
option(Merge.onCreate,[created:'2022-02-07']). //// (1)
option(Merge.onMatch,[updated:'2022-02-07'])
==>e[2][1-Sibling->2]
gremlin> g.E().elementMap()
==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]
gremlin> g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]).
mergeE(select('map')).
option(Merge.onCreate,[created:'2022-02-07']).
option(Merge.onMatch,[updated:'2022-02-07']) //// (2)
==>e[2][1-Sibling->2]
gremlin> g.E().elementMap()
==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07,updated:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby'])
g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])
g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]).
mergeE(select('map')).
option(Merge.onCreate,[created:'2022-02-07']). //// (1)
option(Merge.onMatch,[updated:'2022-02-07'])
g.E().elementMap()
g.withSideEffect('map',[(T.label):'Sibling',(from):1,(to):2]).
mergeE(select('map')).
option(Merge.onCreate,[created:'2022-02-07']).
option(Merge.onMatch,[updated:'2022-02-07']) //// (2)
g.E().elementMap()-
The edge did not exist - set the created date.
-
The edge did exist - set the updated date.
More than one edge can be created by a single mergeE() operation. This is done by
injecting a list of maps into the traversal and letting them stream into the mergeE()
step.
gremlin> maps = [[(T.label):'Siblings',(from):1,(to):2],
[(T.label):'Siblings',(from):1,(to):3]]
==>[label:Siblings,OUT:1,IN:2]
==>[label:Siblings,OUT:1,IN:3]
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby']) //// (1)
==>v[1]
gremlin> g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])
==>v[2]
gremlin> g.mergeV([(T.id):3,(T.label):'Dog',name:'Dax'])
==>v[3]
gremlin> g.inject(maps).unfold().mergeE() //// (2)
==>e[3][1-Siblings->2]
==>e[4][1-Siblings->3]
gremlin> g.E().elementMap()
==>[id:3,label:Siblings,IN:[id:2,label:Dog],OUT:[id:1,label:Dog]]
==>[id:4,label:Siblings,IN:[id:3,label:Dog],OUT:[id:1,label:Dog]]maps = [[(T.label):'Siblings',(from):1,(to):2],
[(T.label):'Siblings',(from):1,(to):3]]
g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby']) //// (1)
g.mergeV([(T.id):2,(T.label):'Dog',name:'Brandy'])
g.mergeV([(T.id):3,(T.label):'Dog',name:'Dax'])
g.inject(maps).unfold().mergeE() //// (2)
g.E().elementMap()-
Create three dogs.
-
Stream the edge maps into
mergeE()steps.
The mergeE step can be combined with the mergeV step (or any other step producing a Vertex) using the
Merge.outV and Merge.inV option modulators. These options can be used to "late-bind" the OUT and IN
vertices in the main merge argument and in the onCreate argument:
gremlin> g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby']).as('Toby').
mergeV([(T.id):2,(T.label):'Dog',name:'Brandy']).as('Brandy').
mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]).
option(Merge.outV, select('Toby')).
option(Merge.inV, select('Brandy'))
==>e[2][1-Sibling->2]
gremlin> g.E().elementMap()
==>[id:2,label:Sibling,IN:[id:2,label:Dog],OUT:[id:1,label:Dog],created:2022-02-07]g.mergeV([(T.id):1,(T.label):'Dog',name:'Toby']).as('Toby').
mergeV([(T.id):2,(T.label):'Dog',name:'Brandy']).as('Brandy').
mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]).
option(Merge.outV, select('Toby')).
option(Merge.inV, select('Brandy'))
g.E().elementMap()The Merge.outV and Merge.inV tokens can be used as placeholders for values for Direction.OUT and Direction.IN
respectively in the mergeE arguments. These options can produce Vertices, as in the example above, or they can
specify Maps, which will be used to search for Vertices in the graph. This is useful when the exact T.id of
the from/to vertices is not known in advance:
gremlin> g.mergeV([(T.label):'Dog',name:'Toby'])
==>v[0]
gremlin> g.mergeV([(T.label):'Dog',name:'Brandy'])
==>v[2]
gremlin> g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]).
option(Merge.outV, [(T.label):'Dog',name:'Toby']).
option(Merge.inV, [(T.label):'Dog',name:'Brandy'])
==>e[4][0-Sibling->2]
gremlin> g.E().elementMap()
==>[id:4,label:Sibling,IN:[id:2,label:Dog],OUT:[id:0,label:Dog],created:2022-02-07]g.mergeV([(T.label):'Dog',name:'Toby'])
g.mergeV([(T.label):'Dog',name:'Brandy'])
g.mergeE([(T.label):'Sibling',created:'2022-02-07',(from):Merge.outV,(to):Merge.inV]).
option(Merge.outV, [(T.label):'Dog',name:'Toby']).
option(Merge.inV, [(T.label):'Dog',name:'Brandy'])
g.E().elementMap()Additional References
MergeVertex Step
The mergeV() -step is used to add vertices and their properties to a graph in a "create
if not exist" fashion. The mergeV() step can also be used to find vertices matching a given
pattern. The input passed to mergeV() can be either a Map, or a child Traversal that
produces a Map.
|
Note
|
There is a corresponding mergeE() step that can be used when creating edges.
|
Additionally, option() modulators may be combined with mergeV() to take action depending on
whether a vertex was created, or already existed. There are various ways mergeV() can
be used. The simplest being to provide a single Map of keys and values as a parameter. A T.id
and a T.label may also be provided but this is optional. The mergeV() step can be used directly
from the GraphTraversalSource - g, or in the middle of a traversal. For a match with an
existing vertex to occur, all values in the Map must exist on a vertex; otherwise, a new
vertex will be created. The examples that follow show how mergeV() can be used to add some
dogs to the graph.
gremlin> g.mergeV([name: 'Brandy']) //// (1)
==>v[0]
gremlin> g.V().has('name','Brandy')
==>v[0]
gremlin> g.mergeV([(T.label):'Dog',name:'Scamp', age:12]) //// (2)
==>v[2]
gremlin> g.V().hasLabel('Dog').valueMap()
==>[name:[Scamp],age:[12]]
gremlin> g.mergeV([(T.id):300, (T.label):'Dog', name:'Toby', age:10]) //// (3)
==>v[300]
gremlin> g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)
==>[id:2,label:Dog,name:[Scamp],age:[12]]
==>[id:300,label:Dog,name:[Toby],age:[10]]g.mergeV([name: 'Brandy']) //// (1)
g.V().has('name','Brandy')
g.mergeV([(T.label):'Dog',name:'Scamp', age:12]) //// (2)
g.V().hasLabel('Dog').valueMap()
g.mergeV([(T.id):300, (T.label):'Dog', name:'Toby', age:10]) //// (3)
g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)-
Create a vertex for Brandy as no other matching ones exist yet.
-
Create a vertex for Scamp and also add a Dog label his age.
-
Create a vertex for Toby with an
T.idof 300.
|
Note
|
The example above is written with gremlin-groovy and evaluated in Gremlin Console as a Groovy script thus
allowing Groovy syntax for initializing a Map.
|
If a vertex already exists that matches the map passed to mergeV(), the existing
vertex will be returned, otherwise a new one will be created. In this way, mergeV()
provides "get or create" semantics.
gremlin> g.mergeV([name: 'Brandy']) //// (1)
==>v[0]g.mergeV([name: 'Brandy']) //1-
A vertex for Brandy already exists so return it. A new one is not created.
It’s important to note that every key/value pair passed to mergeV() must already exist on
one or more vertices for there to be a match. If a match is found, the vertex, or
vertices, representing that match will be returned. If a vertex representing a dog called
Brandy already exists, but it does not have an "age" property, the mergeV() below will not
find a match and a new vertex will be created.
gremlin> g.addV('Dog').property('name','Brandy') //// (1)
==>v[0]
gremlin> g.mergeV([(T.label):'Dog',name:'Brandy',age:13]) //// (2)
==>v[2]g.addV('Dog').property('name','Brandy') //// (1)
g.mergeV([(T.label):'Dog',name:'Brandy',age:13]) //2-
Create a vertex for Brandy with no age property.
-
A new vertex is created as there is no exact match to any existing vertices.
A common scenario is to search for a vertex with a known T.id and if it exists return that
vertex. If it does not exist, create it. As we have seen, one way to do this is to pass
the T.id and all properties directly to mergeV(). Another is to use Merge.onCreate. Note
that the Map specified for Match.onCreate does not need to include the T.id already present
in the original search. The values provided to the mergeV() Map are inherited by the onCreate
action and combined with the Map provided to Merge.onCreate. Overrides of the T.id or T.label
in the onCreate Map are prohibited.
gremlin> g.mergeV([(T.id):300]).
option(Merge.onCreate,[(T.label):'Dog', name:'Toby', age:10])
==>v[300]g.mergeV([(T.id):300]).
option(Merge.onCreate,[(T.label):'Dog', name:'Toby', age:10])To take specific action when the vertex already exists, Merge.onMatch can be used. The
second parameter to the option step can be either a Map whose values are used to update
the vertex or another Gremlin traversal that generates a Map.
|
Note
|
If mergeV() is given an empty Map; such as mergeV([:]), it will match, and
return, every vertex in the graph. This is the same behavior seen with V([]).
|
gremlin> g.mergeV([(T.id):300]).
option(Merge.onCreate,[(T.label):'Dog', name:'Toby', age:10]). //// (1)
option(Merge.onMatch,[age:11]) //// (2)
==>v[300]
gremlin> g.withSideEffect('new-data',[age:11]).
mergeV([(T.id):300]).
option(Merge.onCreate,[(T.label):'Dog', name:'Toby', age:10]).
option(Merge.onMatch,select('new-data')) //// (3)
==>v[300]
gremlin> g.V(300).valueMap().with(WithOptions.tokens)
==>[id:300,label:Dog,name:[Toby],age:[11]]g.mergeV([(T.id):300]).
option(Merge.onCreate,[(T.label):'Dog', name:'Toby', age:10]). //// (1)
option(Merge.onMatch,[age:11]) //// (2)
g.withSideEffect('new-data',[age:11]).
mergeV([(T.id):300]).
option(Merge.onCreate,[(T.label):'Dog', name:'Toby', age:10]).
option(Merge.onMatch,select('new-data')) //// (3)
g.V(300).valueMap().with(WithOptions.tokens)-
If no match found create the vertex using these values.
-
If a match is found, change the age property value.
-
Change the age property by selecting from the
new-datamap.
It is sometimes helpful to incorporate fail() step into scenarios where there is a need to stop the traversal
for one event or the other:
gremlin> g.mergeV([(T.id): 1]).
......1> option(onCreate, fail("vertex did not exist")).
......2> option(onMatch, [modified: 2022])
fail() Step Triggered
======================================================================================================================================================================
Message > vertex did not exist
Traverser> false
Bulk > 1
Traversal> fail("vertex did not exist")
Parent > TinkerMergeVertexStep [mergeV([(T.id):((int) 1)]).option(Merge.onCreate,__.fail("vertex did not exist")).option(Merge.onMatch,[("modified"):((int) 2022)])]
Metadata > {}
======================================================================================================================================================================When working with multi-properties, there are two ways to specify them for mergeV(). First, you can specify them
individually using a CardinalityValue as the value in the Map. The CardinalityValue allows you to specify the
value as well as the Cardinality for that value. Note that it is only possible to specify one value with this syntax
even if you are using set or list.
gremlin> g.mergeV([(T.label):'Dog', name:'Max']). //// (1)
option(onCreate, [alias: set('Maximus')]). //// (2)
property(set,'alias','Maxamillion') //// (3)
==>v[0]
gremlin> g.V().has('name','Max').valueMap().with(WithOptions.tokens)
==>[id:0,label:Dog,name:[Max],alias:[Maximus,Maxamillion]]g.mergeV([(T.label):'Dog', name:'Max']). //// (1)
option(onCreate, [alias: set('Maximus')]). //// (2)
property(set,'alias','Maxamillion') //// (3)
g.V().has('name','Max').valueMap().with(WithOptions.tokens)-
Find or create a vertex for Max.
-
If Max is not found then add an alias of
setcardinality. -
Whether Max was found or created, add another alias with
setcardinality.
The second option is to specify Cardinality for the entire range of values as follows:
gremlin> g.mergeV([(T.label):'Dog', name:'Max']).
option(onCreate, [alias: 'Maximus', city: 'Boston'], set) //// (1)
==>v[0]
gremlin> g.mergeV([(T.label):'Dog', name:'Max']).
option(onCreate, [alias: 'Maximus', city: single('Boston')], set) //// (2)
==>v[0]g.mergeV([(T.label):'Dog', name:'Max']).
option(onCreate, [alias: 'Maximus', city: 'Boston'], set) //// (1)
g.mergeV([(T.label):'Dog', name:'Max']).
option(onCreate, [alias: 'Maximus', city: single('Boston')], set) //2-
If Max is created then set the alias and city with cardinality of
set. -
If Max is created then set the alias with cardinality of
setand city with cardinalitysingle.
More than one vertex can be created by a single mergeV() operation. This is done by
injecting a List of Map objects into the traversal and letting them stream into the mergeV()
step.
gremlin> maps = [[(T.label) : 'Dog', name: 'Toby' , breed: 'Golden Retriever'],
[(T.label) : 'Dog', name: 'Brandy', breed: 'Golden Retriever'],
[(T.label) : 'Dog', name: 'Scamp' , breed: 'King Charles Spaniel'],
[(T.label) : 'Dog', name: 'Shadow', breed: 'Mixed'],
[(T.label) : 'Dog', name: 'Rocket', breed: 'Golden Retriever'],
[(T.label) : 'Dog', name: 'Dax' , breed: 'Mixed'],
[(T.label) : 'Dog', name: 'Baxter', breed: 'Mixed'],
[(T.label) : 'Dog', name: 'Zoe' , breed: 'Corgi'],
[(T.label) : 'Dog', name: 'Pixel' , breed: 'Mixed']]
==>[label:Dog,name:Toby,breed:Golden Retriever]
==>[label:Dog,name:Brandy,breed:Golden Retriever]
==>[label:Dog,name:Scamp,breed:King Charles Spaniel]
==>[label:Dog,name:Shadow,breed:Mixed]
==>[label:Dog,name:Rocket,breed:Golden Retriever]
==>[label:Dog,name:Dax,breed:Mixed]
==>[label:Dog,name:Baxter,breed:Mixed]
==>[label:Dog,name:Zoe,breed:Corgi]
==>[label:Dog,name:Pixel,breed:Mixed]
gremlin> g.inject(maps).unfold().mergeV()
==>v[0]
==>v[3]
==>v[6]
==>v[9]
==>v[12]
==>v[15]
==>v[18]
==>v[21]
==>v[24]
gremlin> g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)
==>[id:0,label:Dog,name:[Toby],breed:[Golden Retriever]]
==>[id:18,label:Dog,name:[Baxter],breed:[Mixed]]
==>[id:3,label:Dog,name:[Brandy],breed:[Golden Retriever]]
==>[id:21,label:Dog,name:[Zoe],breed:[Corgi]]
==>[id:6,label:Dog,name:[Scamp],breed:[King Charles Spaniel]]
==>[id:24,label:Dog,name:[Pixel],breed:[Mixed]]
==>[id:9,label:Dog,name:[Shadow],breed:[Mixed]]
==>[id:12,label:Dog,name:[Rocket],breed:[Golden Retriever]]
==>[id:15,label:Dog,name:[Dax],breed:[Mixed]]maps = [[(T.label) : 'Dog', name: 'Toby' , breed: 'Golden Retriever'],
[(T.label) : 'Dog', name: 'Brandy', breed: 'Golden Retriever'],
[(T.label) : 'Dog', name: 'Scamp' , breed: 'King Charles Spaniel'],
[(T.label) : 'Dog', name: 'Shadow', breed: 'Mixed'],
[(T.label) : 'Dog', name: 'Rocket', breed: 'Golden Retriever'],
[(T.label) : 'Dog', name: 'Dax' , breed: 'Mixed'],
[(T.label) : 'Dog', name: 'Baxter', breed: 'Mixed'],
[(T.label) : 'Dog', name: 'Zoe' , breed: 'Corgi'],
[(T.label) : 'Dog', name: 'Pixel' , breed: 'Mixed']]
g.inject(maps).unfold().mergeV()
g.V().hasLabel('Dog').valueMap().with(WithOptions.tokens)Another useful pattern that can be used with mergeV() involves putting multiple maps in a
list and selecting different maps based on the action being taken. The examples below use
a list containing three maps. The first containing just the ID to be searched for. The
second map contains all the information to use when the vertex is created. The third map
contains additional information that will be applied if an existing vertex is found.
gremlin> g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]).as('m').
mergeV(select('m').limit(local,1)). //// (1)
option(Merge.onCreate, select('m').range(local,1,2)). //// (2)
option(Merge.onMatch, select('m').tail(local)) //// (3)
==>v[400]
gremlin> g.V(400).valueMap().with(WithOptions.tokens)
==>[id:400,label:Dog,name:[Pixel],age:[1]]
gremlin> g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]).as('m').
mergeV(select('m').limit(local,1)).
option(Merge.onCreate, select('m').range(local,1,2)).
option(Merge.onMatch, select('m').tail(local)) //// (4)
==>v[400]
gremlin> g.V(400).valueMap().with(WithOptions.tokens) //// (5)
==>[id:400,label:Dog,name:[Pixel],updated:[2022-02-1],age:[1]]g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]).as('m').
mergeV(select('m').limit(local,1)). //// (1)
option(Merge.onCreate, select('m').range(local,1,2)). //// (2)
option(Merge.onMatch, select('m').tail(local)) //// (3)
g.V(400).valueMap().with(WithOptions.tokens)
g.inject([[(T.id):400],[(T.label):'Dog',name:'Pixel',age:1],[updated:'2022-02-1']]).as('m').
mergeV(select('m').limit(local,1)).
option(Merge.onCreate, select('m').range(local,1,2)).
option(Merge.onMatch, select('m').tail(local)) //// (4)
g.V(400).valueMap().with(WithOptions.tokens) //5-
Use the first map to search for a vertex with an ID of 400.
-
If the vertex was not found, use the second map to create it.
-
If the vertex was found, add an
updatedproperty. -
Pixel exists now, so we will take this option.
-
The
updatedproperty has now been added.
Additional References
Min Step
The min()-step (map) operates on a stream of comparable objects and determines which is the first object according
to its natural order in the stream.
gremlin> g.V().values('age').min()
==>27
gremlin> g.V().repeat(both()).times(3).values('age').min()
==>27
gremlin> g.V().values('name').min()
==>joshg.V().values('age').min()
g.V().repeat(both()).times(3).values('age').min()
g.V().values('name').min()When called as min(local) it determines the minimum value of the current, local object (not the objects in the
traversal stream). This works for Collection and Comparable-type objects.
gremlin> g.V().values('age').fold().min(local)
==>27g.V().values('age').fold().min(local)When there are null values being evaluated the null objects are ignored, but if all values are recognized as null
the return value is null.
gremlin> g.inject(null,10, 9, null).min()
==>9
gremlin> g.inject([null,null,null]).min(local)
==>nullg.inject(null,10, 9, null).min()
g.inject([null,null,null]).min(local)Additional References
None Step
It is possible to filter list traversers using none()-step (filter). Every item in the list will be tested against
the supplied predicate and if none of the items pass then the traverser is passed along the stream, otherwise it is
filtered. Empty lists are passed along but null or non-iterable traversers are filtered out.
|
Note
|
Prior to release 4.0.0, none() was a traversal discarding step primarily used by iterate(). This step has
since been renamed to discard()
|
gremlin> g.V().values('age').fold().none(gt(25)) //// (1)g.V().values('age').fold().none(gt(25)) //1-
Return the list of ages only if no one’s age is greater than 25.
Additional References
Not Step
The not()-step (filter) removes objects from the traversal stream when the traversal provided as an argument
returns an object.
|
Groovy
|
The term |
|
Python
|
The term |
gremlin> g.V().not(hasLabel('person')).elementMap()
==>[id:3,label:software,name:lop,lang:java]
==>[id:5,label:software,name:ripple,lang:java]
gremlin> g.V().hasLabel('person').
not(out('created').count().is(gt(1))).values('name') //// (1)
==>marko
==>vadas
==>peterg.V().not(hasLabel('person')).elementMap()
g.V().hasLabel('person').
not(out('created').count().is(gt(1))).values('name') //1-
josh created two projects and vadas none
Additional References
Option Step
Additional References
Optional Step
The optional()-step (branch/flatMap) returns the result of the specified traversal if it yields a result else it returns the calling
element, i.e. the identity().
gremlin> g.V(2).optional(out('knows')) //// (1)
==>v[2]
gremlin> g.V(2).optional(__.in('knows')) //// (2)
==>v[1]g.V(2).optional(out('knows')) //// (1)
g.V(2).optional(__.in('knows')) //2-
vadas does not have an outgoing knows-edge so vadas is returned.
-
vadas does have an incoming knows-edge so marko is returned.
optional is particularly useful for lifting entire graphs when used in conjunction with path or tree.
gremlin> g.V().hasLabel('person').optional(out('knows').optional(out('created'))).path() //// (1)
==>[v[1],v[2]]
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
==>[v[2]]
==>[v[4]]
==>[v[6]]g.V().hasLabel('person').optional(out('knows').optional(out('created'))).path() //1-
Returns the paths of everybody followed by who they know followed by what they created.
Additional References
Or Step
The or()-step ensures that at least one of the provided traversals yield a result (filter). Please see
and() for and-semantics.
|
Python
|
The term |
gremlin> g.V().or(
__.outE('created'),
__.inE('created').count().is(gt(1))).
values('name')
==>marko
==>lop
==>josh
==>peterg.V().or(
__.outE('created'),
__.inE('created').count().is(gt(1))).
values('name')The or()-step can take an arbitrary number of traversals. At least one of the traversals must produce at least one
output for the original traverser to pass to the next step.
An infix notation can be used as well.
gremlin> g.V().where(outE('created').or().outE('knows')).values('name')
==>marko
==>josh
==>peterg.V().where(outE('created').or().outE('knows')).values('name')Additional References
Order Step
When the objects of the traversal stream need to be sorted, order()-step (map) can be leveraged.
gremlin> g.V().values('name').order()
==>josh
==>lop
==>marko
==>peter
==>ripple
==>vadas
gremlin> g.V().values('name').order().by(desc)
==>vadas
==>ripple
==>peter
==>marko
==>lop
==>josh
gremlin> g.V().hasLabel('person').order().by('age', asc).values('name')
==>vadas
==>marko
==>josh
==>peterg.V().values('name').order()
g.V().values('name').order().by(desc)
g.V().hasLabel('person').order().by('age', asc).values('name')One of the most traversed objects in a traversal is an Element. An element can have properties associated with it
(i.e. key/value pairs). In many situations, it is desirable to sort an element traversal stream according to a
comparison of their properties.
gremlin> g.V().values('name')
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().order().by('name',asc).values('name')
==>josh
==>lop
==>marko
==>peter
==>ripple
==>vadas
gremlin> g.V().order().by('name',desc).values('name')
==>vadas
==>ripple
==>peter
==>marko
==>lop
==>josh
gremlin> g.V().both().order().by('age') //// (1)
==>v[2]
==>v[1]
==>v[1]
==>v[1]
==>v[4]
==>v[4]
==>v[4]
==>v[6]g.V().values('name')
g.V().order().by('name',asc).values('name')
g.V().order().by('name',desc).values('name')
g.V().both().order().by('age') //1-
The "age" property is not productive for all vertices and therefore those values are filtered.
The order()-step allows the user to provide an arbitrary number of comparators for primary, secondary, etc. sorting.
In the example below, the primary ordering is based on the outgoing created-edge count. The secondary ordering is
based on the age of the person.
gremlin> g.V().hasLabel('person').order().by(outE('created').count(), asc).
by('age', asc).values('name')
==>vadas
==>marko
==>peter
==>josh
gremlin> g.V().hasLabel('person').order().by(outE('created').count(), asc).
by('age', desc).values('name')
==>vadas
==>peter
==>marko
==>joshg.V().hasLabel('person').order().by(outE('created').count(), asc).
by('age', asc).values('name')
g.V().hasLabel('person').order().by(outE('created').count(), asc).
by('age', desc).values('name')Randomizing the order of the traversers at a particular point in the traversal is possible with Order.shuffle.
gremlin> g.V().hasLabel('person').order().by(shuffle)
==>v[4]
==>v[1]
==>v[2]
==>v[6]
gremlin> g.V().hasLabel('person').order().by(shuffle)
==>v[2]
==>v[1]
==>v[6]
==>v[4]g.V().hasLabel('person').order().by(shuffle)
g.V().hasLabel('person').order().by(shuffle)It is possible to use order(local) to order the current local object and not the entire traversal stream. This works for
Collection- and Map-type objects. For any other object, the object is returned unchanged.
gremlin> g.V().values('age').fold().order(local).by(desc) //// (1)
==>[35,32,29,27]
gremlin> g.V().values('age').order(local).by(desc) //// (2)
==>29
==>27
==>32
==>35
gremlin> g.V().groupCount().by(inE().count()).order(local).by(values, desc) //// (3)
==>[1:3,0:2,3:1]
gremlin> g.V().groupCount().by(inE().count()).order(local).by(keys, asc) //// (4)
==>[0:2,1:3,3:1]g.V().values('age').fold().order(local).by(desc) //// (1)
g.V().values('age').order(local).by(desc) //// (2)
g.V().groupCount().by(inE().count()).order(local).by(values, desc) //// (3)
g.V().groupCount().by(inE().count()).order(local).by(keys, asc) //4-
The ages are gathered into a list and then that list is sorted in decreasing order.
-
The ages are not gathered and thus
order(local)is "ordering" single integers and thus, does nothing. -
The
groupCount()map is ordered by its values in decreasing order. -
The
groupCount()map is ordered by its keys in increasing order.
|
Note
|
The values and keys enums are from Column which is used to select "columns" from a Map, Map.Entry, or Path.
|
If a property key does not exist, then it will be treated as null which will sort it first for Order.asc and last
for Order.desc.
gremlin> g.V().order().by("age").elementMap()
==>[id:2,label:person,name:vadas,age:27]
==>[id:1,label:person,name:marko,age:29]
==>[id:4,label:person,name:josh,age:32]
==>[id:6,label:person,name:peter,age:35]g.V().order().by("age").elementMap()|
Note
|
Prior to version 3.3.4, ordering was defined by Order.incr for ascending order and Order.decr for descending
order. Those tokens were deprecated and eventually removed in 3.5.0.
|
Additional References
PageRank Step
The pageRank()-step (map/sideEffect) calculates PageRank using
PageRankVertexProgram.
|
Important
|
The pageRank()-step is a VertexComputing-step and as such, can only be used against a graph that
supports GraphComputer (OLAP).
|
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().pageRank().with(PageRank.propertyName, 'friendRank').values('pageRank')
gremlin> g.V().hasLabel('person').
pageRank().
with(PageRank.edges, __.outE('knows')).
with(PageRank.propertyName, 'friendRank').
order().by('friendRank',desc).
elementMap('name','friendRank')
==>[id:1,label:person,friendRank:0.5839416733381598,name:marko]
==>[id:6,label:person,friendRank:0.5839416733381598,name:peter]
==>[id:4,label:person,friendRank:0.8321166533236799,name:josh]
==>[id:2,label:person,friendRank:0.8321166533236799,name:vadas]g = traversal().with(graph).withComputer()
g.V().pageRank().with(PageRank.propertyName, 'friendRank').values('pageRank')
g.V().hasLabel('person').
pageRank().
with(PageRank.edges, __.outE('knows')).
with(PageRank.propertyName, 'friendRank').
order().by('friendRank',desc).
elementMap('name','friendRank')Note the use of the with() modulating step which provides configuration options to the algorithm. It takes
configuration keys from the PageRank and is automatically imported to the Gremlin Console.
The explain()-step can be used to understand how the traversal is compiled into multiple
GraphComputer jobs.
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().hasLabel('person').
pageRank().
with(PageRank.edges, __.outE('knows')).
with(PageRank.propertyName, 'friendRank').
order().by('friendRank',desc).
elementMap('name','friendRank').explain()
==>Traversal Explanation
======================================================================================================================================================================================================================================================================================
Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])]
ConnectiveStrategy [D] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), OrderGlobalStep([[value(friendRank), desc]]), ElementMapStep([name, friendRank])]
VertexProgramStrategy [D] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
IdentityRemovalStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
MatchPredicateStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
PathProcessorStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
ByModulatorOptimizationStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
EarlyLimitStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
FilterRankingStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
InlineFilterStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
IncidentToAdjacentStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
AdjacentToIncidentStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
RepeatUnrollStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
CountStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
PathRetractionStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
LazyBarrierStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
OrderLimitStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
MessagePassingReductionStrategy [O] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
TinkerGraphCountStrategy [P] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
TinkerGraphStepStrategy [P] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
ProfileStrategy [F] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
ComputerFinalizationStrategy [T] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
ComputerVerificationStrategy [V] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
StandardVerificationStrategy [V] [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]
Final Traversal [TraversalVertexProgramStep([GraphStep(vertex,[]), HasStep([~label.eq(person)])],graphfilter[none]), PageRankVertexProgramStep([VertexStep(OUT,[knows],edge)],friendRank,20,graphfilter[none]), TraversalVertexProgramStep([OrderGlobalStep([[va
lue(friendRank), desc]]), ElementMapStep([name, friendRank])],graphfilter[none]), ComputerResultStep]g = traversal().with(graph).withComputer()
g.V().hasLabel('person').
pageRank().
with(PageRank.edges, __.outE('knows')).
with(PageRank.propertyName, 'friendRank').
order().by('friendRank',desc).
elementMap('name','friendRank').explain()Additional References
Path Step
A traverser is transformed as it moves through a series of steps within a traversal. The history of the traverser is
realized by examining its path with path()-step (map).

gremlin> g.V().out().out().values('name')
==>ripple
==>lop
gremlin> g.V().out().out().values('name').path()
==>[v[1],v[4],v[5],ripple]
==>[v[1],v[4],v[3],lop]
gremlin> g.V().both().path().by('age') //// (1)
==>[29,27]
==>[29,32]
==>[27,29]
==>[32,29]g.V().out().out().values('name')
g.V().out().out().values('name').path()
g.V().both().path().by('age') //1-
The "age" property is not productive for all vertices and therefore those values are filtered.
If edges are required in the path, then be sure to traverse those edges explicitly.
gremlin> g.V().outE().inV().outE().inV().path()
==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]
==>[v[1],e[8][1-knows->4],v[4],e[11][4-created->3],v[3]]g.V().outE().inV().outE().inV().path()It is possible to post-process the elements of the path in a round-robin fashion via by().
gremlin> g.V().out().out().path().by('name').by('age')
==>[marko,32,ripple]
==>[marko,32,lop]g.V().out().out().path().by('name').by('age')Finally, because by()-based post-processing, nothing prevents triggering yet another traversal. In the traversal
below, for each element of the path traversed thus far, if its a person (as determined by having an age-property),
then get all of their creations, else if its a creation, get all the people that created it.
gremlin> g.V().out().out().path().by(
choose(hasLabel('person'),
out('created').values('name'),
__.in('created').values('name')).fold())
==>[[lop],[ripple,lop],[josh]]
==>[[lop],[ripple,lop],[marko,josh,peter]]g.V().out().out().path().by(
choose(hasLabel('person'),
out('created').values('name'),
__.in('created').values('name')).fold())gremlin> g.V().has('person','name','vadas').as('e').
in('knows').
out('knows').where(neq('e')).
path().by('name') //// (1)
==>[vadas,marko,josh]
gremlin> g.V().has('person','name','vadas').as('e').
in('knows').as('m').
out('knows').where(neq('e')).
path().to('m').by('name') //// (2)
==>[vadas,marko]
gremlin> g.V().has('person','name','vadas').as('e').
in('knows').as('m').
out('knows').where(neq('e')).
path().from('m').by('name') //// (3)
==>[marko,josh]g.V().has('person','name','vadas').as('e').
in('knows').
out('knows').where(neq('e')).
path().by('name') //// (1)
g.V().has('person','name','vadas').as('e').
in('knows').as('m').
out('knows').where(neq('e')).
path().to('m').by('name') //// (2)
g.V().has('person','name','vadas').as('e').
in('knows').as('m').
out('knows').where(neq('e')).
path().from('m').by('name') //3-
Obtain the full path from vadas to josh.
-
Save the middle node, marko, and use the
to()modulator to show only the path from vadas to marko -
Use the
from()mdoulator to show only the path from marko to josh
|
Warning
|
Generating path information is expensive as the history of the traverser is stored into a Java list. With
numerous traversers, there are numerous lists. Moreover, in an OLAP GraphComputer environment
this becomes exceedingly prohibitive as there are traversers emanating from all vertices in the graph in parallel.
In OLAP there are optimizations provided for traverser populations, but when paths are calculated (and each traverser
is unique due to its history), then these optimizations are no longer possible.
|
Path Data Structure
The Path data structure is an ordered list of objects, where each object is associated to a Set<String> of
labels. An example is presented below to demonstrate both the Path API as well as how a traversal yields labeled paths.

gremlin> path = g.V(1).as('a').has('name').as('b').
out('knows').out('created').as('c').
has('name','ripple').values('name').as('d').
identity().as('e').path().next()
==>v[1]
==>v[4]
==>v[5]
==>ripple
gremlin> path.size()
==>4
gremlin> path.objects()
==>v[1]
==>v[4]
==>v[5]
==>ripple
gremlin> path.labels()
==>[b,a]
==>[]
==>[c]
==>[d,e]
gremlin> path.a
==>v[1]
gremlin> path.b
==>v[1]
gremlin> path.c
==>v[5]
gremlin> path.d == path.e
==>truepath = g.V(1).as('a').has('name').as('b').
out('knows').out('created').as('c').
has('name','ripple').values('name').as('d').
identity().as('e').path().next()
path.size()
path.objects()
path.labels()
path.a
path.b
path.c
path.d == path.eAdditional References
PeerPressure Step
The peerPressure()-step (map/sideEffect) clusters vertices using PeerPressureVertexProgram.
|
Important
|
The peerPressure()-step is a VertexComputing-step and as such, can only be used against a graph that supports GraphComputer (OLAP).
|
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().peerPressure().with(PeerPressure.propertyName, 'cluster').values('cluster')
==>1
==>1
==>1
==>1
==>1
==>6
gremlin> g.V().hasLabel('person').
peerPressure().
with(PeerPressure.propertyName, 'cluster').
group().
by('cluster').
by('name')
==>[1:[marko,vadas,josh],6:[peter]]g = traversal().with(graph).withComputer()
g.V().peerPressure().with(PeerPressure.propertyName, 'cluster').values('cluster')
g.V().hasLabel('person').
peerPressure().
with(PeerPressure.propertyName, 'cluster').
group().
by('cluster').
by('name')Note the use of the with() modulating step which provides configuration options to the algorithm. It takes
configuration keys from the PeerPressure class and is automatically imported to the Gremlin Console.
Additional References
Product Step
The product()-step (map) calculates the cartesian product between the incoming list traverser and the provided list
argument. This step only expects list data (array or Iterable) and will throw an IllegalArgumentException if any
other type is encountered (including null).
gremlin> g.V().values("name").fold().product(["james","jen"])
==>[[marko,james],[marko,jen],[vadas,james],[vadas,jen],[lop,james],[lop,jen],[josh,james],[josh,jen],[ripple,james],[ripple,jen],[peter,james],[peter,jen]]
gremlin> g.V().values("name").fold().product(__.V().has("age").limit(1).values("age").fold())
==>[[marko,29],[vadas,29],[lop,29],[josh,29],[ripple,29],[peter,29]]g.V().values("name").fold().product(["james","jen"])
g.V().values("name").fold().product(__.V().has("age").limit(1).values("age").fold())Additional References
Profile Step
The profile()-step (sideEffect) exists to allow developers to profile their traversals to determine statistical
information like step runtime, counts, etc.
|
Warning
|
Profiling a Traversal will impede the Traversal’s performance. This overhead is mostly excluded from the profile results, but durations are not exact. Thus, durations are best considered in relation to each other. |
gremlin> g.V().out('created').repeat(both()).times(3).hasLabel('person').values('age').sum().profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.077 21.56
VertexStep(OUT,[created],vertex) 4 4 0.046 12.87
NoOpBarrierStep(2500) 4 2 0.026 7.35
VertexStep(BOTH,vertex) 10 4 0.012 3.53
NoOpBarrierStep(2500) 10 3 0.013 3.82
VertexStep(BOTH,vertex) 24 7 0.016 4.50
NoOpBarrierStep(2500) 24 5 0.018 5.22
VertexStep(BOTH,vertex) 58 11 0.021 5.84
NoOpBarrierStep(2500) 58 6 0.028 7.90
HasStep([~label.eq(person)]) 48 4 0.028 7.78
PropertiesStep([age],value) 48 4 0.025 7.17
SumGlobalStep 1 1 0.044 12.47
>TOTAL - - 0.360 -g.V().out('created').repeat(both()).times(3).hasLabel('person').values('age').sum().profile()The profile()-step generates a TraversalMetrics sideEffect object that contains the following information:
-
Step: A step within the traversal being profiled. -
Count: The number of represented traversers that passed through the step. -
Traversers: The number of traversers that passed through the step. -
Time (ms): The total time the step was actively executing its behavior. -
% Dur: The percentage of total time spent in the step.
 It is important to understand the difference between "Count"
and "Traversers". Traversers can be merged and as such, when two traversers are "the same" they may be aggregated
into a single traverser. That new traverser has a
It is important to understand the difference between "Count"
and "Traversers". Traversers can be merged and as such, when two traversers are "the same" they may be aggregated
into a single traverser. That new traverser has a Traverser.bulk() that is the sum of the two merged traverser
bulks. On the other hand, the Count represents the sum of all Traverser.bulk() results and thus, expresses the
number of "represented" (not enumerated) traversers. Traversers will always be less than or equal to Count.
For traversal compilation information, please see explain()-step.
Additional References
Project Step
The project()-step (map) projects the current object into a Map<String,Object> keyed by provided labels. It is similar
to select()-step, save that instead of retrieving and modulating historic traverser state, it modulates
the current state of the traverser.
gremlin> g.V().has('name','marko').
project('id', 'name', 'out', 'in').
by(id).
by('name').
by(outE().count()).
by(inE().count())
==>[id:1,name:marko,out:3,in:0]
gremlin> g.V().has('name','marko').
project('name', 'friendsNames').
by('name').
by(out('knows').values('name').fold())
==>[name:marko,friendsNames:[vadas,josh]]
gremlin> g.V().out('created').
project('a','b').
by('name').
by(__.in('created').count()).
order().by(select('b'),desc).
select('a')
==>lop
==>lop
==>lop
==>ripple
gremlin> g.V().project('n','a').by('name').by('age') //// (1)
==>[n:marko,a:29]
==>[n:vadas,a:27]
==>[n:lop]
==>[n:josh,a:32]
==>[n:ripple]
==>[n:peter,a:35]g.V().has('name','marko').
project('id', 'name', 'out', 'in').
by(id).
by('name').
by(outE().count()).
by(inE().count())
g.V().has('name','marko').
project('name', 'friendsNames').
by('name').
by(out('knows').values('name').fold())
g.V().out('created').
project('a','b').
by('name').
by(__.in('created').count()).
order().by(select('b'),desc).
select('a')
g.V().project('n','a').by('name').by('age') //1-
The "age" property is not productive for all vertices and therefore those values are filtered and the key not present in the
Map.
Additional References
Program Step
The program()-step (map/sideEffect) is the "lambda" step for GraphComputer jobs. The step takes a
VertexProgram as an argument and will process the incoming graph accordingly. Thus, the user
can create their own VertexProgram and have it execute within a traversal. The configuration provided to the
vertex program includes:
-
gremlin.vertexProgramStep.rootTraversalis a serialization of aPureTraversalform of the root traversal. -
gremlin.vertexProgramStep.stepIdis the step string id of theprogram()-step being executed.
The user supplied VertexProgram can leverage that information accordingly within their vertex program. Example uses
are provided below.
|
Warning
|
Developing a VertexProgram is for expert users. Moreover, developing one that can be used effectively within
a traversal requires yet more expertise. This information is recommended to advanced users with a deep understanding of the
mechanics of Gremlin OLAP (GraphComputer).
|
private TraverserSet<Object> haltedTraversers;
public void loadState(Graph graph, Configuration configuration) {
VertexProgram.super.loadState(graph, configuration);
this.traversal = PureTraversal.loadState(configuration, VertexProgramStep.ROOT_TRAVERSAL, graph);
this.programStep = new TraversalMatrix<>(this.traversal.get()).getStepById(configuration.getString(ProgramVertexProgramStep.STEP_ID));
// if the traversal sideEffects will be used in the computation, add them as memory compute keys
this.memoryComputeKeys.addAll(MemoryTraversalSideEffects.getMemoryComputeKeys(this.traversal.get()));
// if master-traversal traversers may be propagated, create a memory compute key
this.memoryComputeKeys.add(MemoryComputeKey.of(TraversalVertexProgram.HALTED_TRAVERSERS, Operator.addAll, false, false));
// returns an empty traverser set if there are no halted traversers
this.haltedTraversers = TraversalVertexProgram.loadHaltedTraversers(configuration);
}
public void storeState(Configuration configuration) {
VertexProgram.super.storeState(configuration);
// if halted traversers is null or empty, it does nothing
TraversalVertexProgram.storeHaltedTraversers(configuration, this.haltedTraversers);
}
public void setup(Memory memory) {
if(!this.haltedTraversers.isEmpty()) {
// do what you like with the halted master traversal traversers
}
// once used, no need to keep that information around (master)
this.haltedTraversers = null;
}
public void execute(Vertex vertex, Messenger messenger, Memory memory) {
// once used, no need to keep that information around (workers)
if(null != this.haltedTraversers)
this.haltedTraversers = null;
if(vertex.property(TraversalVertexProgram.HALTED_TRAVERSERS).isPresent()) {
// haltedTraversers in execute() represent worker-traversal traversers
// for example, from a traversal of the form g.V().out().program(...)
TraverserSet<Object> haltedTraversers = vertex.value(TraversalVertexProgram.HALTED_TRAVERSERS);
// create a new halted traverser set that can be used by the next OLAP job in the chain
// these are worker-traversers that are distributed throughout the graph
TraverserSet<Object> newHaltedTraversers = new TraverserSet<>();
haltedTraversers.forEach(traverser -> {
newHaltedTraversers.add(traverser.split(traverser.get().toString(), this.programStep));
});
vertex.property(VertexProperty.Cardinality.single, TraversalVertexProgram.HALTED_TRAVERSERS, newHaltedTraversers);
// it is possible to create master-traversers that are localized to the master traversal (this is how results are ultimately delivered back to the user)
memory.add(TraversalVertexProgram.HALTED_TRAVERSERS,
new TraverserSet<>(this.traversal().get().getTraverserGenerator().generate("an example", this.programStep, 1l)));
}
public boolean terminate(Memory memory) {
// the master-traversal will have halted traversers
assert memory.exists(TraversalVertexProgram.HALTED_TRAVERSERS);
TraverserSet<String> haltedTraversers = memory.get(TraversalVertexProgram.HALTED_TRAVERSERS);
// it will only have the traversers sent to the master traversal via memory
assert haltedTraversers.stream().map(Traverser::get).filter(s -> s.equals("an example")).findAny().isPresent();
// it will not contain the worker traversers distributed throughout the vertices
assert !haltedTraversers.stream().map(Traverser::get).filter(s -> !s.equals("an example")).findAny().isPresent();
return true;
}|
Note
|
The test case ProgramTest in gremlin-test has an example vertex program called TestProgram that demonstrates
all the various ways in which traversal and traverser information is propagated within a vertex program and ultimately
usable by other vertex programs (including TraversalVertexProgram) down the line in an OLAP compute chain.
|
Finally, an example is provided using PageRankVertexProgram which doesn’t use pageRank()-step.
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().hasLabel('person').
program(PageRankVertexProgram.build().property('rank').create(graph)).
order().by('rank', asc).
elementMap('name', 'rank')
==>[id:2,label:person,name:vadas,rank:0.14598540152719103]
==>[id:1,label:person,name:marko,rank:0.11375510357865538]
==>[id:6,label:person,name:peter,rank:0.11375510357865538]
==>[id:4,label:person,name:josh,rank:0.14598540152719103]g = traversal().with(graph).withComputer()
g.V().hasLabel('person').
program(PageRankVertexProgram.build().property('rank').create(graph)).
order().by('rank', asc).
elementMap('name', 'rank')Properties Step
The properties()-step (map) extracts properties from an Element in the traversal stream.
gremlin> g.V(1).properties()
==>vp[name->marko]
==>vp[location->san diego]
==>vp[location->santa cruz]
==>vp[location->brussels]
==>vp[location->santa fe]
gremlin> g.V(1).properties('location').valueMap()
==>[startTime:1997,endTime:2001]
==>[startTime:2001,endTime:2004]
==>[startTime:2004,endTime:2005]
==>[startTime:2005]
gremlin> g.V(1).properties('location').has('endTime').valueMap()
==>[startTime:1997,endTime:2001]
==>[startTime:2001,endTime:2004]
==>[startTime:2004,endTime:2005]g.V(1).properties()
g.V(1).properties('location').valueMap()
g.V(1).properties('location').has('endTime').valueMap()Additional References
Property Step
The property()-step is used to add properties to the elements of the graph (sideEffect). Unlike addV() and
addE(), property() is a full sideEffect step in that it does not return the property it created, but the element
that streamed into it. Moreover, if property() follows an addV() or addE(), then it is "folded" into the
previous step to enable vertex and edge creation with all its properties in one creation operation.
gremlin> g.V(1).property('country','usa')
==>v[1]
gremlin> g.V(1).property('city','santa fe').property('state','new mexico').valueMap()
==>[country:[usa],city:[santa fe],name:[marko],state:[new mexico],age:[29]]
gremlin> g.V(1).property(['city': 'santa fe', 'state': 'new mexico']) //// (1)
==>v[1]
gremlin> g.V(1).property(list,'age',35) //// (2)
==>v[1]
gremlin> g.V(1).property(list, ['city': 'santa fe', 'state': 'new mexico']) //// (3)
==>v[1]
gremlin> g.V(1).valueMap()
==>[country:[usa],city:[santa fe,santa fe],name:[marko],state:[new mexico,new mexico],age:[29,35]]
gremlin> g.V(1).property(list, ['age': single(36), 'city': 'wilmington', 'state': 'delaware']) //// (4)
==>v[1]
gremlin> g.V(1).valueMap()
==>[country:[usa],city:[santa fe,santa fe,wilmington],name:[marko],state:[new mexico,new mexico,delaware],age:[36]]
gremlin> g.V(1).property('friendWeight',outE('knows').values('weight').sum(),'acl','private') //// (5)
==>v[1]
gremlin> g.V(1).properties('friendWeight').valueMap() //// (6)
==>[acl:private]
gremlin> g.addV().property(T.label,'person').valueMap().with(WithOptions.tokens) //// (7)
==>[id:13,label:person]
gremlin> g.addV().property(null) //// (8)
==>v[14]
gremlin> g.addV().property(set, null)
==>v[15]g.V(1).property('country','usa')
g.V(1).property('city','santa fe').property('state','new mexico').valueMap()
g.V(1).property(['city': 'santa fe', 'state': 'new mexico']) //// (1)
g.V(1).property(list,'age',35) //// (2)
g.V(1).property(list, ['city': 'santa fe', 'state': 'new mexico']) //// (3)
g.V(1).valueMap()
g.V(1).property(list, ['age': single(36), 'city': 'wilmington', 'state': 'delaware']) //// (4)
g.V(1).valueMap()
g.V(1).property('friendWeight',outE('knows').values('weight').sum(),'acl','private') //// (5)
g.V(1).properties('friendWeight').valueMap() //// (6)
g.addV().property(T.label,'person').valueMap().with(WithOptions.tokens) //// (7)
g.addV().property(null) //// (8)
g.addV().property(set, null)-
Properties can also take a
Mapas an argument. -
For vertices, a cardinality can be provided for vertex properties.
-
If a cardinality is specified for a
Mapthen that cardinality will be used for all properties in the map. -
Assign the
Cardinalityindividually to override the specifiedlistor the default cardinality if not specified. -
It is possible to select the property value (as well as key) via a traversal.
-
For vertices, the
property()-step can add meta-properties. -
The label value can be specified as a property only at the time a vertex is added and if one is not specified in the addV()
-
If you pass a
nullvalue for the Map this will be treated as a no-op and the input will be returned
Additional References
PropertyMap Step
The propertiesMap()-step yields a Map representation of the properties of an element.
gremlin> g.V().propertyMap()
==>[name:[vp[name->marko]],age:[vp[age->29]]]
==>[name:[vp[name->vadas]],age:[vp[age->27]]]
==>[name:[vp[name->lop]],lang:[vp[lang->java]]]
==>[name:[vp[name->josh]],age:[vp[age->32]]]
==>[name:[vp[name->ripple]],lang:[vp[lang->java]]]
==>[name:[vp[name->peter]],age:[vp[age->35]]]
gremlin> g.V().propertyMap('age')
==>[age:[vp[age->29]]]
==>[age:[vp[age->27]]]
==>[]
==>[age:[vp[age->32]]]
==>[]
==>[age:[vp[age->35]]]
gremlin> g.V().propertyMap('age','blah')
==>[age:[vp[age->29]]]
==>[age:[vp[age->27]]]
==>[]
==>[age:[vp[age->32]]]
==>[]
==>[age:[vp[age->35]]]
gremlin> g.E().propertyMap()
==>[weight:p[weight->0.5]]
==>[weight:p[weight->1.0]]
==>[weight:p[weight->0.4]]
==>[weight:p[weight->1.0]]
==>[weight:p[weight->0.4]]
==>[weight:p[weight->0.2]]g.V().propertyMap()
g.V().propertyMap('age')
g.V().propertyMap('age','blah')
g.E().propertyMap()Additional References
Range Step
As traversers propagate through the traversal, it is possible to only allow a certain number of them to pass through
with range()-step (filter). When the low-end of the range is not met, objects are continued to be iterated. When
within the low (inclusive) and high (exclusive) range, traversers are emitted. When above the high range, the traversal
breaks out of iteration. Finally, the use of -1 on the high range will emit remaining traversers after the low range
begins.
gremlin> g.V().range(0,3)
==>v[1]
==>v[2]
==>v[3]
gremlin> g.V().range(1,3)
==>v[2]
==>v[3]
gremlin> g.V().range(1, -1)
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V().repeat(both()).times(1000000).emit().range(6,10)
==>v[1]
==>v[5]
==>v[3]
==>v[1]g.V().range(0,3)
g.V().range(1,3)
g.V().range(1, -1)
g.V().repeat(both()).times(1000000).emit().range(6,10)The range()-step can also be applied with Scope.local, in which case it operates on the incoming collection.
For example, it is possible to produce a Map<String, String> for each traversed path, but containing only the second
property value (the "b" step).
gremlin> g.V().as('a').out().as('b').in().as('c').select('a','b','c').by('name').range(local,1,2)
==>[b:lop]
==>[b:lop]
==>[b:lop]
==>[b:vadas]
==>[b:josh]
==>[b:ripple]
==>[b:lop]
==>[b:lop]
==>[b:lop]
==>[b:lop]
==>[b:lop]
==>[b:lop]g.V().as('a').out().as('b').in().as('c').select('a','b','c').by('name').range(local,1,2)The next example uses the The Crew toy data set. It produces a List<String> containing the
second and third location for each vertex.
gremlin> g.V().valueMap().select('location').range(local, 1, 3)
==>[santa cruz,brussels]
==>[dulles,purcellville]
==>[baltimore,oakland]
==>[kaiserslautern,aachen]g.V().valueMap().select('location').range(local, 1, 3)Additional References
Read Step
The read()-step is not really a "step" but a step modulator in that it modifies the functionality of the io()-step.
More specifically, it tells the io()-step that it is expected to use its configuration to read data from some
location. Please see the documentation for io()-step for more complete details on usage.
Additional References
Repeat Step

The repeat()-step (branch) is used for looping over a traversal given some break predicate. Below are some
examples of repeat()-step in action.
gremlin> g.V(1).repeat(out()).times(2).path().by('name') //// (1)
==>[marko,josh,ripple]
==>[marko,josh,lop]
gremlin> g.V().until(has('name','ripple')).
repeat(out()).path().by('name') //// (2)
==>[marko,josh,ripple]
==>[josh,ripple]
==>[ripple]g.V(1).repeat(out()).times(2).path().by('name') //// (1)
g.V().until(has('name','ripple')).
repeat(out()).path().by('name') //2-
do-while semantics stating to do
out()2 times. -
while-do semantics stating to break if the traverser is at a vertex named "ripple".
|
Important
|
There are two modulators for repeat(): until() and emit(). If until() comes after repeat() it is
do/while looping. If until() comes before repeat() it is while/do looping. If emit() is placed after repeat(),
it is evaluated on the traversers leaving the repeat-traversal. If emit() is placed before repeat(), it is
evaluated on the traversers prior to entering the repeat-traversal.
|
The repeat()-step also supports an "emit predicate", where the predicate for an empty argument emit() is
true (i.e. emit() == emit{true}). With emit(), the traverser is split in two — the traverser exits the code
block as well as continues back within the code block (assuming until() holds true).
gremlin> g.V(1).repeat(out()).times(2).emit().path().by('name') //// (1)
==>[marko,lop]
==>[marko,vadas]
==>[marko,josh]
==>[marko,josh,ripple]
==>[marko,josh,lop]
gremlin> g.V(1).emit().repeat(out()).times(2).path().by('name') //// (2)
==>[marko]
==>[marko,lop]
==>[marko,vadas]
==>[marko,josh]
==>[marko,josh,ripple]
==>[marko,josh,lop]g.V(1).repeat(out()).times(2).emit().path().by('name') //// (1)
g.V(1).emit().repeat(out()).times(2).path().by('name') //2-
The
emit()comes afterrepeat()and thus, emission happens after therepeat()traversal is executed. Thus, no one vertex paths exist. -
The
emit()comes beforerepeat()and thus, emission happens prior to therepeat()traversal being executed. Thus, one vertex paths exist.
The emit()-modulator can take an arbitrary predicate.
gremlin> g.V(1).repeat(out()).times(2).emit(has('lang')).path().by('name')
==>[marko,lop]
==>[marko,josh,ripple]
==>[marko,josh,lop]g.V(1).repeat(out()).times(2).emit(has('lang')).path().by('name')
gremlin> g.V(1).repeat(out()).times(2).emit().path().by('name')
==>[marko,lop]
==>[marko,vadas]
==>[marko,josh]
==>[marko,josh,ripple]
==>[marko,josh,lop]g.V(1).repeat(out()).times(2).emit().path().by('name')The first time through the repeat(), the vertices lop, vadas, and josh are seen. Given that loops==1, the
traverser repeats. However, because the emit-predicate is declared true, those vertices are emitted. The next time through
repeat(), the vertices traversed are ripple and lop (Josh’s created projects, as lop and vadas have no out edges).
Given that loops==2, the until-predicate fails and ripple and lop are emitted.
Therefore, the traverser has seen the vertices: lop, vadas, josh, ripple, and lop.
repeat()-steps may be nested inside each other or inside the emit() or until() predicates and they can also be 'named' by passing a string as the first parameter to repeat(). The loop counter of a named repeat step can be accessed within the looped context with loops(loopName) where loopName is the name set whe creating the repeat()-step.
gremlin> g.V(1).
repeat(out("knows")).
until(repeat(out("created")).emit(has("name", "lop"))) //// (1)
==>v[4]
gremlin> g.V(6).
repeat('a', both('created').simplePath()).
emit(repeat('b', both('knows')).
until(loops('b').as('b').where(loops('a').as('b'))).
hasId(2)).dedup() //// (2)
==>v[4]g.V(1).
repeat(out("knows")).
until(repeat(out("created")).emit(has("name", "lop"))) //// (1)
g.V(6).
repeat('a', both('created').simplePath()).
emit(repeat('b', both('knows')).
until(loops('b').as('b').where(loops('a').as('b'))).
hasId(2)).dedup() //2-
Starting from vertex 1, keep going taking outgoing 'knows' edges until the vertex was created by 'lop'.
-
Starting from vertex 6, keep taking created edges in either direction until the vertex is same distance from vertex 2 over knows edges as it is from vertex 6 over created edges.
Finally, note that both emit() and until() can take a traversal and in such, situations, the predicate is
determined by traversal.hasNext(). A few examples are provided below.
gremlin> g.V(1).repeat(out()).until(hasLabel('software')).path().by('name') //// (1)
==>[marko,lop]
==>[marko,josh,ripple]
==>[marko,josh,lop]
gremlin> g.V(1).emit(hasLabel('person')).repeat(out()).path().by('name') //// (2)
==>[marko]
==>[marko,vadas]
==>[marko,josh]
gremlin> g.V(1).repeat(out()).until(outE().count().is(0)).path().by('name') //// (3)
==>[marko,lop]
==>[marko,vadas]
==>[marko,josh,ripple]
==>[marko,josh,lop]g.V(1).repeat(out()).until(hasLabel('software')).path().by('name') //// (1)
g.V(1).emit(hasLabel('person')).repeat(out()).path().by('name') //// (2)
g.V(1).repeat(out()).until(outE().count().is(0)).path().by('name') //3-
Starting from vertex 1, keep taking outgoing edges until a software vertex is reached.
-
Starting from vertex 1, and in an infinite loop, emit the vertex if it is a person and then traverser the outgoing edges.
-
Starting from vertex 1, keep taking outgoing edges until a vertex is reached that has no more outgoing edges.
|
Warning
|
The anonymous traversal of emit() and until() (not repeat()) process their current objects "locally."
In OLAP, where the atomic unit of computing is the vertex and its local "star graph," it is important that the
anonymous traversals do not leave the confines of the vertex’s star graph. In other words, they can not traverse to
an adjacent vertex’s properties or edges.
|
Additional References
Replace Step
The replace()-step (map) returns a string with the specified characters in the original string replaced with the new
characters. Any null arguments will be a no-op and the original string is returned. Null values from the incoming
traversers are not processed and remain as null when returned. If the incoming traverser is a non-String value then
an IllegalArgumentException will be thrown.
gremlin> g.inject('that', 'this', 'test', null).replace('h', 'j') //// (1)
==>tjat
==>tjis
==>test
==>null
gremlin> g.inject('hello world').replace(null, 'j') //// (2)
==>hello world
gremlin> g.V().hasLabel("software").values("name").replace("p", "g") //// (3)
==>log
==>riggle
gremlin> g.V().hasLabel("software").values("name").fold().replace(local, "p", "g") //// (4)
==>[log,riggle]g.inject('that', 'this', 'test', null).replace('h', 'j') //// (1)
g.inject('hello world').replace(null, 'j') //// (2)
g.V().hasLabel("software").values("name").replace("p", "g") //// (3)
g.V().hasLabel("software").values("name").fold().replace(local, "p", "g") //4-
Replace "h" in the strings with "j".
-
Null inputs are ignored and the original string is returned.
-
Return software names with "p" replaced by "g".
-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
replace(String,String)
replace(Scope,String,String)
Reverse Step
The reverse()-step (map) returns the reverse of the incoming list traverser. Single values (including null) are not
processed and are added back to the Traversal Stream unchanged. If the incoming traverser is a String value then the
reversed String will be returned.
gremlin> g.V().values("name").reverse() //// (1)
==>okram
==>sadav
==>pol
==>hsoj
==>elppir
==>retep
gremlin> g.V().values("name").order().fold().reverse() //// (2)
==>[vadas,ripple,peter,marko,lop,josh]g.V().values("name").reverse() //// (1)
g.V().values("name").order().fold().reverse() //2-
Reverse the order of the characters in each name.
-
Fold all the names into a list in ascending order and then reverse the list’s ordering (into descending).
RTrim Step
The rTrim()-step (map) returns a string with trailing whitespace removed. Null values are not processed and remain
as null when returned. If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.inject(" hello ", " world ", null).rTrim()
==> hello
==> world
==>null
gremlin> g.inject([" hello ", " world ", null]).rTrim(local) //// (1)
==>[ hello, world,null]g.inject(" hello ", " world ", null).rTrim()
g.inject([" hello ", " world ", null]).rTrim(local) //1-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Sack Step
 A traverser can contain a local data structure called a "sack".
The
A traverser can contain a local data structure called a "sack".
The sack()-step is used to read and write sacks (sideEffect or map). Each sack of each traverser is created
when using GraphTraversal.withSack(initialValueSupplier,splitOperator?,mergeOperator?).
-
Initial value supplier: A
Supplierproviding the initial value of each traverser’s sack. -
Split operator: a
UnaryOperatorthat clones the traverser’s sack when the traverser splits. If no split operator is provided, thenUnaryOperator.identity()is assumed. -
Merge operator: A
BinaryOperatorthat unites two traverser’s sack when they are merged. If no merge operator is provided, then traversers with sacks can not be merged.
Two trivial examples are presented below to demonstrate the initial value supplier. In the first example below, a
traverser is created at each vertex in the graph (g.V()), with a 1.0 sack (withSack(1.0f)), and then the sack
value is accessed (sack()). In the second example, a random float supplier is used to generate sack values.
gremlin> g.withSack(1.0f).V().sack()
==>1.0
==>1.0
==>1.0
==>1.0
==>1.0
==>1.0
gremlin> rand = new Random()
==>java.util.Random@3d951cc7
gremlin> g.withSack {rand.nextFloat()}.V().sack()
==>0.7612473
==>0.18528676
==>0.93462235
==>0.6009229
==>0.75515115
==>0.21070653g.withSack(1.0f).V().sack()
rand = new Random()
g.withSack {rand.nextFloat()}.V().sack()A more complicated initial value supplier example is presented below where the sack values are used in a running
computation and then emitted at the end of the traversal. When an edge is traversed, the edge weight is multiplied
by the sack value (sack(mult).by('weight')). Note that the by()-modulator can be any arbitrary traversal.
gremlin> g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2)
==>v[5]
==>v[3]
gremlin> g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).sack()
==>1.0
==>0.4
gremlin> g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).path().
by().by('weight')
==>[v[1],1.0,v[4],1.0,v[5]]
==>[v[1],1.0,v[4],0.4,v[3]]
gremlin> g.V().sack(assign).by('age').sack() //// (1)
==>29
==>27
==>32
==>35g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2)
g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).sack()
g.withSack(1.0f).V().repeat(outE().sack(mult).by('weight').inV()).times(2).path().
by().by('weight')
g.V().sack(assign).by('age').sack() //1-
The "age" property is not productive for all vertices and therefore those values are filtered during the assignment.
 When complex objects are used (i.e. non-primitives), then a
split operator should be defined to ensure that each traverser gets a clone of its parent’s sack. The first example
does not use a split operator and as such, the same map is propagated to all traversers (a global data structure). The
second example, demonstrates how
When complex objects are used (i.e. non-primitives), then a
split operator should be defined to ensure that each traverser gets a clone of its parent’s sack. The first example
does not use a split operator and as such, the same map is propagated to all traversers (a global data structure). The
second example, demonstrates how Map.clone() ensures that each traverser’s sack contains a unique, local sack.
gremlin> g.withSack {[:]}.V().out().out().
sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack() // BAD: single map
==>[ripple:java]
==>[ripple:java,lop:java]
gremlin> g.withSack {[:]}{it.clone()}.V().out().out().
sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack() // GOOD: cloned map
==>[ripple:java]
==>[lop:java]g.withSack {[:]}.V().out().out().
sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack() // BAD: single map
g.withSack {[:]}{it.clone()}.V().out().out().
sack {m,v -> m[v.value('name')] = v.value('lang'); m}.sack() // GOOD: cloned map|
Note
|
For primitives (i.e. integers, longs, floats, etc.), a split operator is not required as a primitives are encoded in the memory address of the sack, not as a reference to an object. |
If a merge operator is not provided, then traversers with sacks can not be bulked. However, in many situations,
merging the sacks of two traversers at the same location is algorithmically sound and good to provide so as to gain
the bulking optimization. In the examples below, the binary merge operator is Operator.sum. Thus, when two traverser
merge, their respective sacks are added together.
gremlin> g.withSack(1.0d).V(1).out('knows').in('knows') //// (1)
==>v[1]
==>v[1]
gremlin> g.withSack(1.0d).V(1).out('knows').in('knows').sack() //// (2)
==>1.0
==>1.0
gremlin> g.withSack(1.0d, sum).V(1).out('knows').in('knows').sack() //// (3)
==>2.0
==>2.0
gremlin> g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier() //// (4)
==>v[1]
==>v[1]
gremlin> g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (5)
==>0.5
==>0.5
gremlin> g.withSack(1.0d,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (6)
==>1.0
==>1.0
gremlin> g.withBulk(false).withSack(1.0f,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (7)
==>1.0
gremlin> g.withBulk(false).withSack(1.0f).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (8)
==>0.5
==>0.5
gremlin>g.withSack(1.0d).V(1).out('knows').in('knows') //// (1)
g.withSack(1.0d).V(1).out('knows').in('knows').sack() //// (2)
g.withSack(1.0d, sum).V(1).out('knows').in('knows').sack() //// (3)
g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier() //// (4)
g.withSack(1.0d).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (5)
g.withSack(1.0d,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (6)
g.withBulk(false).withSack(1.0f,sum).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (7)
g.withBulk(false).withSack(1.0f).V(1).local(outE('knows').barrier(normSack).inV()).in('knows').barrier().sack() //// (8)-
We find vertex 1 twice because he knows two other people
-
Without a merge operation the sack values are 1.0.
-
When specifying
sumas the merge operation, the sack values are 2.0 because of bulking -
Like 1, but using barrier internally
-
The
local(…barrier(normSack)…)ensures that all traversers leaving vertex 1 have an evenly distributed amount of the initial 1.0 "energy" (50-50), i.e. the sack is 0.5 on each result -
Like 3, but using
sumas merge operator leads to the expected 1.0 -
There is now a single traverser with bulk of 2 and sack of 1.0 and thus, setting
withBulk(false)`yields the expected 1.0 -
Like 7, but without the
sumoperator
Additional References
Sample Step
The sample()-step is useful for sampling some number of traversers previous in the traversal.
gremlin> g.V().outE().sample(1).values('weight')
==>0.4
gremlin> g.V().outE().sample(1).by('weight').values('weight')
==>1.0
gremlin> g.V().outE().sample(2).by('weight').values('weight')
==>1.0
==>0.5
gremlin> g.V().both().sample(2).by('age') //// (1)
==>v[1]
==>v[1]g.V().outE().sample(1).values('weight')
g.V().outE().sample(1).by('weight').values('weight')
g.V().outE().sample(2).by('weight').values('weight')
g.V().both().sample(2).by('age') //1-
The "age" property is not productive for all vertices and therefore those values are not considered when sampling.
One of the more interesting use cases for sample() is when it is used in conjunction with local().
The combination of the two steps supports the execution of random walks.
In the example below, the traversal starts are vertex 1 and selects one edge to traverse based on a probability
distribution generated by the weights of the edges. The output is always a single path as by selecting a single edge,
the traverser never splits and continues down a single path in the graph.
gremlin> g.V(1).
repeat(local(bothE().sample(1).by('weight').otherV())).
times(5)
==>v[4]
gremlin> g.V(1).
repeat(local(bothE().sample(1).by('weight').otherV())).
times(5).
path()
==>[v[1],e[8][1-knows->4],v[4],e[8][1-knows->4],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4]]
gremlin> g.V(1).
repeat(local(bothE().sample(1).by('weight').otherV())).
times(10).
path()
==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[8][1-knows->4],v[4],e[11][4-created->3],v[3]]g.V(1).
repeat(local(bothE().sample(1).by('weight').otherV())).
times(5)
g.V(1).
repeat(local(bothE().sample(1).by('weight').otherV())).
times(5).
path()
g.V(1).
repeat(local(bothE().sample(1).by('weight').otherV())).
times(10).
path()As a clarification, note that in the above example local() is not strictly required as it only does the random walk
over a single vertex, but note what happens without it if multiple vertices are traversed:
gremlin> g.V().repeat(bothE().sample(1).by('weight').otherV()).times(5).path()
==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[8][1-knows->4],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]g.V().repeat(bothE().sample(1).by('weight').otherV()).times(5).path()The use of local() ensures that the traversal over bothE() occurs once per vertex traverser that passes through,
thus allowing one random walk per vertex.
gremlin> g.V().repeat(local(bothE().sample(1).by('weight').otherV())).times(5).path()
==>[v[1],e[7][1-knows->2],v[2],e[7][1-knows->2],v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6],e[12][6-created->3],v[3]]
==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[11][4-created->3],v[3],e[11][4-created->3],v[4],e[8][1-knows->4],v[1]]
==>[v[3],e[9][1-created->3],v[1],e[7][1-knows->2],v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]
==>[v[4],e[8][1-knows->4],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1]]
==>[v[5],e[10][4-created->5],v[4],e[10][4-created->5],v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[7][1-knows->2],v[2]]
==>[v[6],e[12][6-created->3],v[3],e[9][1-created->3],v[1],e[7][1-knows->2],v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4]]g.V().repeat(local(bothE().sample(1).by('weight').otherV())).times(5).path()So, while not strictly required, it is likely better to be explicit with the use of local() so that the proper intent
of the traversal is expressed.
Additional References
Select Step
Functional languages make use of function composition and
lazy evaluation to create complex computations from primitive operations. This is exactly what Traversal does. One
of the differentiating aspects of Gremlin’s data flow approach to graph processing is that the flow need not always go
"forward," but in fact, can go back to a previously seen area of computation. Examples include path()
as well as the select()-step (map). There are two general ways to use select()-step.
-
Select labeled steps within a path (as defined by
as()in a traversal). -
Select objects out of a
Map<String,Object>flow (i.e. a sub-map).
The first use case is demonstrated via example below.
gremlin> g.V().as('a').out().as('b').out().as('c') // no select
==>v[5]
==>v[3]
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')
==>[a:v[1],b:v[4],c:v[5]]
==>[a:v[1],b:v[4],c:v[3]]
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b')
==>[a:v[1],b:v[4]]
==>[a:v[1],b:v[4]]
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b').by('name')
==>[a:marko,b:josh]
==>[a:marko,b:josh]
gremlin> g.V().as('a').out().as('b').out().as('c').select('a') //// (1)
==>v[1]
==>v[1]
gremlin> g.V(1).as('a').both().as('b').select('a','b').by('age')
==>[a:29,b:27]
==>[a:29,b:32]g.V().as('a').out().as('b').out().as('c') // no select
g.V().as('a').out().as('b').out().as('c').select('a','b','c')
g.V().as('a').out().as('b').out().as('c').select('a','b')
g.V().as('a').out().as('b').out().as('c').select('a','b').by('name')
g.V().as('a').out().as('b').out().as('c').select('a') //// (1)
g.V(1).as('a').both().as('b').select('a','b').by('age')-
If the selection is one step, no map is returned.
-
The "age" property is not productive for all vertices and therefore those values are filtered.
When there is only one label selected, then a single object is returned. This is useful for stepping back in a computation and easily moving forward again on the object reverted to.
gremlin> g.V().out().out()
==>v[5]
==>v[3]
gremlin> g.V().out().out().path()
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
gremlin> g.V().as('x').out().out().select('x')
==>v[1]
==>v[1]
gremlin> g.V().out().as('x').out().select('x')
==>v[4]
==>v[4]
gremlin> g.V().out().out().as('x').select('x') // pointless
==>v[5]
==>v[3]g.V().out().out()
g.V().out().out().path()
g.V().as('x').out().out().select('x')
g.V().out().as('x').out().select('x')
g.V().out().out().as('x').select('x') // pointless|
Note
|
When executing a traversal with select() on a standard traversal engine (i.e. OLTP), select() will do its
best to avoid calculating the path history and instead, will rely on a global data structure for storing the currently
selected object. As such, if only a subset of the path walked is required, select() should be used over the more
resource intensive path()-step.
|
When the set of keys or values (i.e. columns) of a path or map are needed, use select(keys) and select(values),
respectively. This is especially useful when one is only interested in the top N elements in a groupCount()
ranking.
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> g.V().hasLabel('song').out('followedBy').groupCount().by('name').
order(local).by(values,desc).limit(local, 5)
==>[PLAYING IN THE BAND:107,JACK STRAW:99,TRUCKING:94,DRUMS:92,ME AND MY UNCLE:86]
gremlin> g.V().hasLabel('song').out('followedBy').groupCount().by('name').
order(local).by(values,desc).limit(local, 5).select(keys)
==>[PLAYING IN THE BAND,JACK STRAW,TRUCKING,DRUMS,ME AND MY UNCLE]
gremlin> g.V().hasLabel('song').out('followedBy').groupCount().by('name').
order(local).by(values,desc).limit(local, 5).select(keys).unfold()
==>PLAYING IN THE BAND
==>JACK STRAW
==>TRUCKING
==>DRUMS
==>ME AND MY UNCLEg = traversal().with(graph)
g.io('data/grateful-dead.xml').read().iterate()
g.V().hasLabel('song').out('followedBy').groupCount().by('name').
order(local).by(values,desc).limit(local, 5)
g.V().hasLabel('song').out('followedBy').groupCount().by('name').
order(local).by(values,desc).limit(local, 5).select(keys)
g.V().hasLabel('song').out('followedBy').groupCount().by('name').
order(local).by(values,desc).limit(local, 5).select(keys).unfold()Similarly, for extracting the values from a path or map.
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> g.V().hasLabel('song').out('sungBy').groupCount().by('name') //// (1)
==>[All:9,Weir_Garcia:1,Lesh:19,Weir_Kreutzmann:1,Pigpen_Garcia:1,Pigpen:36,Unknown:6,Weir_Bralove:1,Joan_Baez:10,Suzanne_Vega:2,Welnick:10,Lesh_Pigpen:1,Elvin_Bishop:4,Neil_Young:1,Garcia_Weir_Lesh:1,Hunter:3,Hornsby:4,Jon_Hendricks:2,Weir_Hart:3,Lesh_Mydland:1,Mydland_Lesh:1,instrumental:1,Garcia:146,Hart:2,Welnick_Bralove:1,Weir:99,Garcia_Dawson:1,Pigpen_Weir_Mydland:2,Jorma_Kaukonen:4,Joey_Covington:2,Allman_Brothers:1,Garcia_Lesh:3,Boz_Scaggs:1,Pigpen?:1,Keith_Godchaux:1,Etta_James:1,Weir_Wasserman:1,Hall_and_Oates:2,Grateful_Dead:17,Spencer_Davis:2,Pigpen_Mydland:3,Beach_Boys:3,Donna:4,Bo_Diddley:7,Bob_Dylan:22,Hart_Kreutzmann:2,Weir_Mydland:3,Lesh_Hart_Kreutzmann:1,Stephen_Stills:2,Mydland:18,Neville_Brothers:2,Weir_Hart_Welnick:1,Garcia_Lesh_Weir:1,Garcia_Weir:3,Neal_Cassady:1,John_Fogerty:5,Donna_Godchaux:2,Pigpen_Weir:8,Garcia_Kreutzmann:2,None:6]
gremlin> g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values) //// (2)
==>[9,1,19,1,1,36,6,1,10,2,10,1,4,1,1,3,4,2,3,1,1,1,146,2,1,99,1,2,4,2,1,3,1,1,1,1,1,2,17,2,3,3,4,7,22,2,3,1,2,18,2,1,1,3,1,5,2,8,2,6]
gremlin> g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values).unfold().
groupCount().order(local).by(values,desc).limit(local, 5) //// (3)
==>[1:22,2:12,3:7,4:4,6:2]g = traversal().with(graph)
g.io('data/grateful-dead.xml').read().iterate()
g.V().hasLabel('song').out('sungBy').groupCount().by('name') //// (1)
g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values) //// (2)
g.V().hasLabel('song').out('sungBy').groupCount().by('name').select(values).unfold().
groupCount().order(local).by(values,desc).limit(local, 5) //3-
Which artist sung how many songs?
-
Get an anonymized set of song repertoire sizes.
-
What are the 5 most common song repertoire sizes?
|
Warning
|
Note that by()-modulation is not supported with select(keys) and select(values).
|
There is also an option to supply a Pop operation to select() to manipulate List objects in the Traverser:
gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(first, "a")
==>v[1]
==>v[1]
gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(last, "a")
==>v[5]
==>v[3]
gremlin> g.V(1).as("a").repeat(out().as("a")).times(2).select(all, "a")
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]g.V(1).as("a").repeat(out().as("a")).times(2).select(first, "a")
g.V(1).as("a").repeat(out().as("a")).times(2).select(last, "a")
g.V(1).as("a").repeat(out().as("a")).times(2).select(all, "a")In addition to the previously shown examples, where select() was used to select an element based on a static key, select() can also accept a traversal
that emits a key.
|
Warning
|
Since the key used by select(<traversal>) cannot be determined at compile time, the TraversalSelectStep enables full path tracking.
|
gremlin> g.withSideEffect("alias", ["marko":"okram"]).V(). //// (1)
values("name").sack(assign). //// (2)
optional(select("alias").select(sack())) //// (3)
==>okram
==>vadas
==>lop
==>josh
==>ripple
==>peterg.withSideEffect("alias", ["marko":"okram"]).V(). //// (1)
values("name").sack(assign). //// (2)
optional(select("alias").select(sack())) //3-
Inject a name alias map and start the traversal from all vertices.
-
Select all
namevalues and store them as the current traverser’s sack value. -
Optionally select the alias for the current name from the injected map.
Using Where with Select
Like match()-step, it is possible to use where(), as where is a filter that processes
Map<String,Object> streams.
gremlin> g.V().as('a').out('created').in('created').as('b').select('a','b').by('name') //// (1)
==>[a:marko,b:marko]
==>[a:marko,b:josh]
==>[a:marko,b:peter]
==>[a:josh,b:josh]
==>[a:josh,b:marko]
==>[a:josh,b:josh]
==>[a:josh,b:peter]
==>[a:peter,b:marko]
==>[a:peter,b:josh]
==>[a:peter,b:peter]
gremlin> g.V().as('a').out('created').in('created').as('b').
select('a','b').by('name').where('a',neq('b')) //// (2)
==>[a:marko,b:josh]
==>[a:marko,b:peter]
==>[a:josh,b:marko]
==>[a:josh,b:peter]
==>[a:peter,b:marko]
==>[a:peter,b:josh]
gremlin> g.V().as('a').out('created').in('created').as('b').
select('a','b'). //// (3)
where('a',neq('b')).
where(__.as('a').out('knows').as('b')).
select('a','b').by('name')
==>[a:marko,b:josh]g.V().as('a').out('created').in('created').as('b').select('a','b').by('name') //// (1)
g.V().as('a').out('created').in('created').as('b').
select('a','b').by('name').where('a',neq('b')) //// (2)
g.V().as('a').out('created').in('created').as('b').
select('a','b'). //// (3)
where('a',neq('b')).
where(__.as('a').out('knows').as('b')).
select('a','b').by('name')-
A standard
select()that generates aMap<String,Object>of variables bindings in the path (i.e.aandb) for the sake of a running example. -
The
select().by('name')projects each binding vertex to their name property value andwhere()operates to ensure respectiveaandbstrings are not the same. -
The first
select()projects a vertex binding set. A binding is filtered ifavertex equalsbvertex. A binding is filtered ifadoesn’t knowb. The second and finalselect()projects the name of the vertices.
Additional References
ShortestPath step
The shortestPath()-step provides an easy way to find shortest non-cyclic paths in a graph. It is configurable
using the with()-modulator with the options given below.
|
Important
|
The shortestPath()-step is a VertexComputing-step and as such, can only be used against a graph
that supports GraphComputer (OLAP).
|
| Key | Type | Description | Default |
|---|---|---|---|
|
|
Sets a filter traversal for the end vertices (e.g. |
all vertices ( |
|
|
Sets a |
|
|
|
Sets the |
|
|
|
Sets the distance limit for all shortest paths. |
none |
|
|
Whether to include edges in the result or not. |
|
gremlin> g = g.withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().shortestPath() //// (1)
==>[v[2],v[1]]
==>[v[2],v[1],v[3]]
==>[v[2],v[1],v[3],v[6]]
==>[v[2],v[1],v[4]]
==>[v[2]]
==>[v[2],v[1],v[4],v[5]]
==>[v[5],v[4],v[1]]
==>[v[5],v[4],v[3]]
==>[v[5],v[4],v[3],v[6]]
==>[v[5],v[4]]
==>[v[5],v[4],v[1],v[2]]
==>[v[5]]
==>[v[3],v[1]]
==>[v[3]]
==>[v[3],v[6]]
==>[v[3],v[4]]
==>[v[3],v[1],v[2]]
==>[v[3],v[4],v[5]]
==>[v[1]]
==>[v[1],v[3]]
==>[v[1],v[3],v[6]]
==>[v[1],v[4]]
==>[v[1],v[2]]
==>[v[1],v[4],v[5]]
==>[v[4],v[1]]
==>[v[4],v[3]]
==>[v[4],v[3],v[6]]
==>[v[4]]
==>[v[4],v[1],v[2]]
==>[v[4],v[5]]
==>[v[6],v[3],v[1]]
==>[v[6],v[3]]
==>[v[6]]
==>[v[6],v[3],v[4]]
==>[v[6],v[3],v[1],v[2]]
==>[v[6],v[3],v[4],v[5]]
gremlin> g.V().has('person','name','marko').shortestPath() //// (2)
==>[v[1]]
==>[v[1],v[2]]
==>[v[1],v[3],v[6]]
==>[v[1],v[3]]
==>[v[1],v[4]]
==>[v[1],v[4],v[5]]
gremlin> g.V().shortestPath().with(ShortestPath.target, __.has('name','peter')) //// (3)
==>[v[1],v[3],v[6]]
==>[v[2],v[1],v[3],v[6]]
==>[v[4],v[3],v[6]]
==>[v[3],v[6]]
==>[v[5],v[4],v[3],v[6]]
==>[v[6]]
gremlin> g.V().shortestPath().
with(ShortestPath.edges, Direction.IN).
with(ShortestPath.target, __.has('name','josh')) //// (4)
==>[v[3],v[4]]
==>[v[4]]
==>[v[5],v[4]]
gremlin> g.V().has('person','name','marko').
shortestPath().
with(ShortestPath.target, __.has('name','josh')) //// (5)
==>[v[1],v[4]]
gremlin> g.V().has('person','name','marko').
shortestPath().
with(ShortestPath.target, __.has('name','josh')).
with(ShortestPath.distance, 'weight') //// (6)
==>[v[1],v[3],v[4]]
gremlin> g.V().has('person','name','marko').
shortestPath().
with(ShortestPath.target, __.has('name','josh')).
with(ShortestPath.includeEdges, true) //// (7)
==>[v[1],e[8][1-knows->4],v[4]]g = g.withComputer()
g.V().shortestPath() //// (1)
g.V().has('person','name','marko').shortestPath() //// (2)
g.V().shortestPath().with(ShortestPath.target, __.has('name','peter')) //// (3)
g.V().shortestPath().
with(ShortestPath.edges, Direction.IN).
with(ShortestPath.target, __.has('name','josh')) //// (4)
g.V().has('person','name','marko').
shortestPath().
with(ShortestPath.target, __.has('name','josh')) //// (5)
g.V().has('person','name','marko').
shortestPath().
with(ShortestPath.target, __.has('name','josh')).
with(ShortestPath.distance, 'weight') //// (6)
g.V().has('person','name','marko').
shortestPath().
with(ShortestPath.target, __.has('name','josh')).
with(ShortestPath.includeEdges, true) //7-
Find all shortest paths.
-
Find all shortest paths from
marko. -
Find all shortest paths to
peter. -
Find all in-directed paths to
josh. -
Find all shortest paths from
markotojosh. -
Find all shortest paths from
markotojoshusing a custom distance property. -
Find all shortest paths from
markotojoshand include edges in the result.
gremlin> g.inject(g.withComputer().V().shortestPath().
with(ShortestPath.distance, 'weight').
with(ShortestPath.includeEdges, true).
with(ShortestPath.maxDistance, 1).toList().toArray()).
map(unfold().values('name','weight').fold()) //// (1)
==>[marko]
==>[marko,0.5,vadas]
==>[marko,0.4,lop,0.4,josh]
==>[marko,0.4,lop,0.2,peter]
==>[marko,0.4,lop]
==>[vadas,0.5,marko]
==>[vadas]
==>[vadas,0.5,marko,0.4,lop]
==>[lop,0.4,marko]
==>[lop,0.4,marko,0.5,vadas]
==>[lop,0.4,josh]
==>[lop,0.2,peter]
==>[lop]
==>[josh,0.4,lop,0.4,marko]
==>[josh]
==>[josh,1.0,ripple]
==>[josh,0.4,lop,0.2,peter]
==>[josh,0.4,lop]
==>[ripple,1.0,josh]
==>[ripple]
==>[peter,0.2,lop,0.4,marko]
==>[peter,0.2,lop,0.4,josh]
==>[peter]
==>[peter,0.2,lop]g.inject(g.withComputer().V().shortestPath().
with(ShortestPath.distance, 'weight').
with(ShortestPath.includeEdges, true).
with(ShortestPath.maxDistance, 1).toList().toArray()).
map(unfold().values('name','weight').fold()) //1-
Find all shortest paths using a custom distance property and limit the distance to 1. Inject the result into a OLTP
GraphTraversalin order to be able to select properties from all elements in all paths.
Additional References
SideEffect Step
The sideEffect() step performs some operation on the traverser and passes it to the next step in the process. Please
see the General Steps section for more information.
Additional References
SimplePath Step

When it is important that a traverser not repeat its path through the graph, simplePath()-step should be used
(filter). The path information of the traverser is analyzed and if the path has repeated
objects in it, the traverser is filtered. If cyclic behavior is desired, see cyclicPath().
gremlin> g.V(1).both().both()
==>v[1]
==>v[4]
==>v[6]
==>v[1]
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(1).both().both().simplePath()
==>v[4]
==>v[6]
==>v[5]
==>v[3]
gremlin> g.V(1).both().both().simplePath().path()
==>[v[1],v[3],v[4]]
==>[v[1],v[3],v[6]]
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]
gremlin> g.V(1).both().both().simplePath().by('age') //// (1)
gremlin> g.V().out().as('a').out().as('b').out().as('c').
simplePath().by(label).
path()
gremlin> g.V().out().as('a').out().as('b').out().as('c').
simplePath().
by(label).
from('b').
to('c').
path().
by('name')g.V(1).both().both()
g.V(1).both().both().simplePath()
g.V(1).both().both().simplePath().path()
g.V(1).both().both().simplePath().by('age') //// (1)
g.V().out().as('a').out().as('b').out().as('c').
simplePath().by(label).
path()
g.V().out().as('a').out().as('b').out().as('c').
simplePath().
by(label).
from('b').
to('c').
path().
by('name')-
The "age" property is not productive for all vertices and therefore those values are filtered.
By using the from() and to() modulators traversers can ensure that only certain sections of the path are acyclic.
gremlin> g.addV().property(id, 'A').as('a').
addV().property(id, 'B').as('b').
addV().property(id, 'C').as('c').
addV().property(id, 'D').as('d').
addE('link').from('a').to('b').
addE('link').from('b').to('c').
addE('link').from('c').to('d').iterate()
gremlin> g.V('A').repeat(both().simplePath()).times(3).path() //// (1)
==>[v[A],v[B],v[C],v[D]]
gremlin> g.V('D').repeat(both().simplePath()).times(3).path() //// (2)
==>[v[D],v[C],v[B],v[A]]
gremlin> g.V('A').as('a').
repeat(both().simplePath().from('a')).times(3).as('b').
repeat(both().simplePath().from('b')).times(3).path() //// (3)
==>[v[A],v[B],v[C],v[D],v[C],v[B],v[A]]g.addV().property(id, 'A').as('a').
addV().property(id, 'B').as('b').
addV().property(id, 'C').as('c').
addV().property(id, 'D').as('d').
addE('link').from('a').to('b').
addE('link').from('b').to('c').
addE('link').from('c').to('d').iterate()
g.V('A').repeat(both().simplePath()).times(3).path() //// (1)
g.V('D').repeat(both().simplePath()).times(3).path() //// (2)
g.V('A').as('a').
repeat(both().simplePath().from('a')).times(3).as('b').
repeat(both().simplePath().from('b')).times(3).path() //3-
Traverse all acyclic 3-hop paths starting from vertex
A -
Traverse all acyclic 3-hop paths starting from vertex
D -
Traverse all acyclic 3-hop paths starting from vertex
Aand from there again all 3-hop paths. The second path may cross the vertices from the first path.
Additional References
Skip Step
The skip()-step is analogous to range()-step save that the higher end range is set to -1.
gremlin> g.V().values('age').order()
==>27
==>29
==>32
==>35
gremlin> g.V().values('age').order().skip(2)
==>32
==>35
gremlin> g.V().values('age').order().range(2, -1)
==>32
==>35g.V().values('age').order()
g.V().values('age').order().skip(2)
g.V().values('age').order().range(2, -1)The skip()-step can also be applied with Scope.local, in which case it operates on the incoming collection.
gremlin> g.V().hasLabel('person').filter(outE('created')).as('p'). //// (1)
map(out('created').values('name').fold()).
project('person','primary','other').
by(select('p').by('name')).
by(limit(local, 1)). //// (2)
by(skip(local, 1)) //// (3)
==>[person:marko,primary:lop,other:[]]
==>[person:josh,primary:ripple,other:[lop]]
==>[person:peter,primary:lop,other:[]]g.V().hasLabel('person').filter(outE('created')).as('p'). //// (1)
map(out('created').values('name').fold()).
project('person','primary','other').
by(select('p').by('name')).
by(limit(local, 1)). //// (2)
by(skip(local, 1)) //3-
For each person who created something…
-
…select the first project (random order) as
primaryand… -
…select all other projects as
other.
Additional References
Split Step
The split()-step (map) returns a list of strings created by splitting the incoming string traverser around the
matches of the given separator. A null separator will split the string by whitespaces. An empty string separator will split on each character.
Null values from the incoming traversers are not processed and remain as null when returned. If the incoming traverser is a non-String value then an
IllegalArgumentException will be thrown.
gremlin> g.inject("that", "this", "test", null).split("h") //// (1)
==>[t,at]
==>[t,is]
==>[test]
==>null
gremlin> g.V().hasLabel("person").values("name").split("a") //// (2)
==>[m,rko]
==>[v,d,s]
==>[josh]
==>[peter]
gremlin> g.inject("helloworld", "hello world", "hello world").split(null) //// (3)
==>[helloworld]
==>[hello,world]
==>[hello,world]
gremlin> g.inject("hello", "world", null).split("") //// (4)
==>[h,e,l,l,o]
==>[w,o,r,l,d]
==>null
gremlin> g.V().hasLabel("person").values("name").fold().split(local, "a") //// (5)
==>[[m,rko],[v,d,s],[josh],[peter]]g.inject("that", "this", "test", null).split("h") //// (1)
g.V().hasLabel("person").values("name").split("a") //// (2)
g.inject("helloworld", "hello world", "hello world").split(null) //// (3)
g.inject("hello", "world", null).split("") //// (4)
g.V().hasLabel("person").values("name").fold().split(local, "a") //5-
Split the strings by "h".
-
Split person names by "a".
-
Splitting by null will split by whitespaces.
-
Splitting by "" will split by each character.
-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list of results.
Additional References
split(String)
split(Scope, String)
Subgraph Step
Extracting a portion of a graph from a larger one for analysis, visualization or other purposes is a fairly common
use case for graph analysts and developers. The subgraph()-step (sideEffect) provides a way to produce an
edge-induced subgraph from virtually any traversal.
The following example demonstrates how to produce the "knows" subgraph:
gremlin> subGraph = g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph').next() //// (1)
==>tinkergraph[vertices:3 edges:2]
gremlin> sg = traversal().with(subGraph)
==>graphtraversalsource[tinkergraph[vertices:3 edges:2], standard]
gremlin> sg.E() //// (2)
==>e[7][1-knows->2]
==>e[8][1-knows->4]subGraph = g.E().hasLabel('knows').subgraph('subGraph').cap('subGraph').next() //// (1)
sg = traversal().with(subGraph)
sg.E() //2-
As this function produces "edge-induced" subgraphs,
subgraph()must be called at edge steps. -
The subgraph contains only "knows" edges.
A more common subgraphing use case is to get all of the graph structure surrounding a single vertex:
gremlin> subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(3).cap('subGraph').next() //// (1)
==>tinkergraph[vertices:4 edges:4]
gremlin> sg = traversal().with(subGraph)
==>graphtraversalsource[tinkergraph[vertices:4 edges:4], standard]
gremlin> sg.E()
==>e[8][1-knows->4]
==>e[9][1-created->3]
==>e[11][4-created->3]
==>e[12][6-created->3]subGraph = g.V(3).repeat(__.inE().subgraph('subGraph').outV()).times(3).cap('subGraph').next() //// (1)
sg = traversal().with(subGraph)
sg.E()-
Starting at vertex
3, traverse 3 steps away on in-edges, outputting all of that into the subgraph.
The above example is purposely brief so as to focus on subgraph() usage, however, it may not be the most optimal
method for constructing the subgraph. For instance, if the graph had cycles, it would attempt to reconstruct parts
of the subgraph which are already present. The duplicates would not be created, but it would involve some unnecessary
processing. If the only interest of the traversal was to populate the subgraph, it would be better to include
simplePath() to filter out those cycles, as in .inE().subgraph('subGraph').outV().simplePath(). From another
perspective, it might also make some sense to use dedup() to avoid traversing the same vertices repeatedly where
two vertices shared the multiple edges between them, as in .inE().dedup().subgraph('subGraph').outV().dedup().
There can be multiple subgraph() calls within the same traversal. Each operating against either the same graph
(i.e. same side-effect key) or different graphs (i.e. different side-effect keys).
gremlin> t = g.V().outE('knows').subgraph('knowsG').inV().outE('created').subgraph('createdG').
inV().inE('created').subgraph('createdG').iterate()
gremlin> traversal().with(t.sideEffects.get('knowsG')).E()
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> traversal().with(t.sideEffects.get('createdG')).E()
==>e[9][1-created->3]
==>e[10][4-created->5]
==>e[11][4-created->3]
==>e[12][6-created->3]t = g.V().outE('knows').subgraph('knowsG').inV().outE('created').subgraph('createdG').
inV().inE('created').subgraph('createdG').iterate()
traversal().with(t.sideEffects.get('knowsG')).E()
traversal().with(t.sideEffects.get('createdG')).E()TinkerGraph is the ideal (and default) Graph into which a subgraph is extracted as it’s fast, in-memory, and supports
user-supplied identifiers which can be any Java object. It is this last feature that needs some focus as many
TinkerPop-enabled graphs have complex identifier types and TinkerGraph’s ability to consume those makes it a perfect
host for an incoming subgraph. However care needs to be taken when using the elements of the TinkerGraph subgraph.
The original graph’s identifiers may be preserved, but the elements of the graph are now TinkerGraph objects like,
TinkerVertex and TinkerEdge. As a result, they can not be used directly in Gremlin running against the original
graph. For example, the following traversal would likely return an error:
Vertex v = sg.V().has('name','marko').next(); //1
List<Vertex> vertices = g.V(v).out().toList(); //2-
Here "sg" is a reference to a TinkerGraph subgraph and "v" is a
TinkerVertex. -
The
g.V(v)has the potential to fail as "g" is the originalGraphinstance and not a TinkerGraph - it could reject theTinkerVertexinstance as it will not recognize it.
It is safer to wrap the TinkerVertex in a ReferenceVertex or simply reference the id() as follows:
Vertex v = sg.V().has('name','marko').next();
List<Vertex> vertices = g.V(v.id()).out().toList();
// OR
Vertex v = new ReferenceVertex(sg.V().has('name','marko').next());
List<Vertex> vertices = g.V(v).out().toList();Additional References
Substring Step
The substring()-step (map) returns a substring with a 0-based start index (inclusive) and optionally an end index (exclusive) specified.
If the start index is negative then it will begin at the specified index counted from the end of the string, or 0 if exceeding the string length.
Likewise, if the end index is negative then it will end at the specified index counted from the end of the string, or 0 if exceeding the string length.
End index is optional, if it is not specified or if it exceeds the length of the string then all remaining characters will
be returned. End index ≤ start index will return the empty string. Null values are not processed and remain as null when returned.
If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.inject("test", "hello world", null).substring(1, 8)
==>est
==>ello wo
==>null
gremlin> g.inject("hello world").substring(-4) //// (1)
==>orld
gremlin> g.inject("hello world").substring(2, 0) //// (2)
==>
gremlin> g.V().hasLabel("software").values("name").substring(2)
==>p
==>pple
gremlin> g.V().hasLabel("software").values("name").fold().substring(local, 2) //// (3)
==>[p,pple]g.inject("test", "hello world", null).substring(1, 8)
g.inject("hello world").substring(-4) //// (1)
g.inject("hello world").substring(2, 0) //// (2)
g.V().hasLabel("software").values("name").substring(2)
g.V().hasLabel("software").values("name").fold().substring(local, 2) //3-
Negative start index, the first character is read by counting from the end of the string
-
Length of 0 specified will return the empty string
-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
substring(int)
substring(Scope,int)
substring(int,int)
substring(Scope,int,int)
Sum Step
The sum()-step (map) operates on a stream of numbers and sums the numbers together to yield a result. Note that
the current traverser number is multiplied by the traverser bulk to determine how many such numbers are being
represented.
gremlin> g.V().values('age').sum()
==>123
gremlin> g.V().repeat(both()).times(3).values('age').sum()
==>1471g.V().values('age').sum()
g.V().repeat(both()).times(3).values('age').sum()When called as sum(local) it determines the sum of the current, local object (not the objects in the traversal
stream). This works for Collection-type objects.
gremlin> g.V().values('age').fold().sum(local)
==>123g.V().values('age').fold().sum(local)When there are null values being evaluated the null objects are ignored, but if all values are recognized as null
the return value is null.
gremlin> g.inject(null,10, 9, null).sum()
==>19
gremlin> g.inject([null,null,null]).sum(local)
==>nullg.inject(null,10, 9, null).sum()
g.inject([null,null,null]).sum(local)Additional References
Tail Step

The tail()-step is analogous to limit()-step, except that it emits the last n-objects instead of
the first n-objects.
gremlin> g.V().values('name').order()
==>josh
==>lop
==>marko
==>peter
==>ripple
==>vadas
gremlin> g.V().values('name').order().tail() //// (1)
==>vadas
gremlin> g.V().values('name').order().tail(1) //// (2)
==>vadas
gremlin> g.V().values('name').order().tail(3) //// (3)
==>peter
==>ripple
==>vadasg.V().values('name').order()
g.V().values('name').order().tail() //// (1)
g.V().values('name').order().tail(1) //// (2)
g.V().values('name').order().tail(3) //3-
Last name (alphabetically).
-
Same as statement 1.
-
Last three names.
The tail()-step can also be applied with Scope.local, in which case it operates on the incoming collection.
gremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(tail(local)).values('name') //// (1)
==>ripple
==>lop
gremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local) //// (2)
==>ripple
==>lop
gremlin> g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local, 2) //// (3)
==>[ripple]
==>[lop]
gremlin> g.V().elementMap().tail(local) //// (4)
==>[age:29]
==>[age:27]
==>[lang:java]
==>[age:32]
==>[lang:java]
==>[age:35]g.V().as('a').out().as('a').out().as('a').select('a').by(tail(local)).values('name') //// (1)
g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local) //// (2)
g.V().as('a').out().as('a').out().as('a').select('a').by(unfold().values('name').fold()).tail(local, 2) //// (3)
g.V().elementMap().tail(local) //4-
Only the most recent name from the "a" step (
List<Vertex>becomesVertex). -
Same result as statement 1 (
List<String>becomesString). -
List<String>for each path containing the last two names from the 'a' step. -
Map<String, Object>for each vertex, but containing only the last property value.
Additional References
TimeLimit Step
In many situations, a graph traversal is not about getting an exact answer as its about getting a relative ranking.
A classic example is recommendation. What is desired is a
relative ranking of vertices, not their absolute rank. Next, it may be desirable to have the traversal execute for
no more than 2 milliseconds. In such situations, timeLimit()-step (filter) can be used.

|
Note
|
The method clock(int runs, Closure code) is a utility preloaded in the Gremlin Console
that can be used to time execution of a body of code.
|
gremlin> g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()
==>v[1]=2744208
==>v[3]=2744208
==>v[4]=2744208
==>v[2]=1136688
==>v[5]=1136688
==>v[6]=1136688
gremlin> clock(1) {g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}
==>1.039267
gremlin> g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()
==>v[1]=2744208
==>v[3]=2744208
==>v[4]=2744208
==>v[2]=1136688
==>v[5]=1136688
==>v[6]=1136688
gremlin> clock(1) {g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}
==>0.9587859999999999g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()
clock(1) {g.V().repeat(both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}
g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()
clock(1) {g.V().repeat(timeLimit(2).both().groupCount('m')).times(16).cap('m').order(local).by(values,desc).next()}In essence, the relative order is respected, even through the number of traversers at each vertex is not. The primary
benefit being that the calculation is guaranteed to complete at the specified time limit (in milliseconds). Finally,
note that the internal clock of timeLimit()-step starts when the first traverser enters it. When the time limit is
reached, any next() evaluation of the step will yield a NoSuchElementException and any hasNext() evaluation will
yield false.
Additional References
To Step
The to()-step is not an actual step, but instead is a "step-modulator" similar to as() and
by(). If a step is able to accept traversals or strings then to() is the
means by which they are added. The general pattern is step().to(). See from()-step.
The list of steps that support to()-modulation are: simplePath(), cyclicPath(),
path(), and addE().
Additional References
ToLower Step
The toLower()-step (map) returns the lowercase representation of incoming string or list of string traverser. Null values are not processed and remain as null when returned.
If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.inject("HELLO", "wORlD", null).toLower()
==>hello
==>world
==>null
gremlin> g.inject(["HELLO", "wORlD", null]).toLower(Scope.local) //// (1)
==>[hello,world,null]g.inject("HELLO", "wORlD", null).toLower()
g.inject(["HELLO", "wORlD", null]).toLower(Scope.local) //1-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
ToUpper Step
The toUpper()-step (map) returns the uppercase representation of incoming string or list of string traverser. Null values are not processed and remain as null when returned.
If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.inject("hello", "wORlD", null).toUpper()
==>HELLO
==>WORLD
==>null
gremlin> g.V().values("name").toUpper() //// (1)
==>MARKO
==>VADAS
==>LOP
==>JOSH
==>RIPPLE
==>PETER
gremlin> g.V().values("name").fold().toUpper(local) //// (2)
==>[MARKO,VADAS,LOP,JOSH,RIPPLE,PETER]g.inject("hello", "wORlD", null).toUpper()
g.V().values("name").toUpper() //// (1)
g.V().values("name").fold().toUpper(local) //2-
Returns the upper case representation of all vertex names.
-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Additional References
Tree Step
From any one element (i.e. vertex or edge), the emanating paths from that element can be aggregated to form a
tree. Gremlin provides tree()-step (sideEffect) for such
this situation.

gremlin> tree = g.V().out().out().tree().next()
==>v[1]={v[4]={v[3]={}, v[5]={}}}tree = g.V().out().out().tree().next()It is important to see how the paths of all the emanating traversers are united to form the tree.

The resultant tree data structure can then be manipulated (see Tree JavaDoc).
gremlin> tree = g.V().out().out().tree().by('name').next()
==>marko={josh={ripple={}, lop={}}}
gremlin> tree['marko']
==>josh={ripple={}, lop={}}
gremlin> tree['marko']['josh']
==>ripple={}
==>lop={}
gremlin> tree.getObjectsAtDepth(3)
==>ripple
==>loptree = g.V().out().out().tree().by('name').next()
tree['marko']
tree['marko']['josh']
tree.getObjectsAtDepth(3)Note that when using by()-modulation, tree nodes are combined based on projection uniqueness, not on the
uniqueness of the original objects being projected. For instance:
gremlin> g.V().has('name','josh').out('created').values('name').tree() //// (1)
==>[v[4]:[v[3]:[lop:[]],v[5]:[ripple:[]]]]
gremlin> g.V().has('name','josh').out('created').values('name').
tree().by('name').by(label).by() //// (2)
==>[josh:[software:[ripple:[],lop:[]]]]g.V().has('name','josh').out('created').values('name').tree() //// (1)
g.V().has('name','josh').out('created').values('name').
tree().by('name').by(label).by() //2-
When the
tree()is created, vertex 3 and 5 are unique and thus, form unique branches in the tree structure. -
When the
tree()isby()-modulated bylabel, then vertex 3 and 5 are both "software" and thus are merged to a single node in the tree.
Additional References
Trim Step
The trim()-step (map) returns a string with leading and leading whitespace removed. Null values are not processed and remain
as null when returned. If the incoming traverser is a non-String value then an IllegalArgumentException will be thrown.
gremlin> g.inject(" hello ", " world ", null).trim()
==>hello
==>world
==>null
gremlin> g.inject([" hello ", " world ", null]).trim(Scope.local) //// (1)
==>[hello,world,null]g.inject(" hello ", " world ", null).trim()
g.inject([" hello ", " world ", null]).trim(Scope.local) //1-
Use
Scope.localto operate on individual string elements inside incoming list, which will return a list.
Unfold Step
If the object reaching unfold() (flatMap) is an iterator, iterable, or map, then it is unrolled into a linear
form. If not, then the object is simply emitted. Please see fold() step for the inverse behavior.
gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34])
==>gremlin
==>[1.23,2.34]
==>[v[3],v[2],v[4]]
gremlin> g.V(1).out().fold().inject('gremlin',[1.23,2.34]).unfold()
==>gremlin
==>1.23
==>2.34
==>v[3]
==>v[2]
==>v[4]g.V(1).out().fold().inject('gremlin',[1.23,2.34])
g.V(1).out().fold().inject('gremlin',[1.23,2.34]).unfold()Note that unfold() does not recursively unroll iterators. Instead, repeat() can be used to for recursive unrolling.
gremlin> inject(1,[2,3,[4,5,[6]]])
==>1
==>[2,3,[4,5,[6]]]
gremlin> inject(1,[2,3,[4,5,[6]]]).unfold()
==>1
==>2
==>3
==>[4,5,[6]]
gremlin> inject(1,[2,3,[4,5,[6]]]).repeat(unfold()).until(count(local).is(1)).unfold()
==>1
==>2
==>3
==>4
==>5
==>6inject(1,[2,3,[4,5,[6]]])
inject(1,[2,3,[4,5,[6]]]).unfold()
inject(1,[2,3,[4,5,[6]]]).repeat(unfold()).until(count(local).is(1)).unfold()Additional References
Union Step

The union()-step (branch) supports the merging of the results of an arbitrary number of traversals. When a
traverser reaches a union()-step, it is copied to each of its internal steps. The traversers emitted from union()
are the outputs of the respective internal traversals.
gremlin> g.V(4).union(
__.in().values('age'),
out().values('lang'))
==>29
==>java
==>java
gremlin> g.V(4).union(
__.in().values('age'),
out().values('lang')).path()
==>[v[4],v[1],29]
==>[v[4],v[5],java]
==>[v[4],v[3],java]
gremlin> g.union(V().has('person','name','vadas'),
V().has('software','name','lop').in('created'))
==>v[2]
==>v[1]
==>v[4]
==>v[6]g.V(4).union(
__.in().values('age'),
out().values('lang'))
g.V(4).union(
__.in().values('age'),
out().values('lang')).path()
g.union(V().has('person','name','vadas'),
V().has('software','name','lop').in('created'))Additional References
Until Step
The until-step is not an actual step, but is instead a step modulator for repeat() (find more
documentation on the until() there).
Additional References
V Step
The V()-step is meant to read vertices from the graph and is usually used to start a GraphTraversal, but can also
be used mid-traversal.
gremlin> g.V(1) //// (1)
==>v[1]
gremlin> g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person') //// (2)
==>e[0][1-uses->3]
==>e[13][1-uses->5]
==>e[14][2-uses->3]
==>e[15][2-uses->5]
==>e[16][4-uses->3]
==>e[17][4-uses->5]g.V(1) //// (1)
g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person') //2-
Find the vertex by its unique identifier (i.e.
T.id) - not all graphs will use a numeric value for their identifier. -
An example where
V()is used both as a start step and in the middle of a traversal.
|
Note
|
Whether a mid-traversal V() uses an index or not, depends on a) whether suitable index exists and b) if the
particular graph system provider implemented this functionality.
|
gremlin> g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person').toString() //// (1)
==>[GraphStep(vertex,[]), HasStep([name.within([marko, vadas, josh])])@[person], GraphStep(vertex,[]), HasStep([name.within([lop, ripple])]), AddEdgeStep({label=[uses], ~from=[[SelectOneStep(last,person,null)]]})]
gremlin> g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person').iterate().toString() //// (2)
==>[TinkerGraphStep(vertex,[name.within([marko, vadas, josh])])@[person], TinkerGraphStep(vertex,[name.within([lop, ripple])]), AddEdgeStep({label=[uses], ~from=[[SelectOneStep(last,person,null)]]}), DiscardStep]g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person').toString() //// (1)
g.V().has('name', within('marko', 'vadas', 'josh')).as('person').
V().has('name', within('lop', 'ripple')).addE('uses').from('person').iterate().toString() //2-
Normally the
V()-step will iterate over all vertices. However, graph strategies can foldHasContainer's into aGraphStepto allow index lookups. -
Whether the graph system provider supports mid-traversal
V()index lookups or not can easily be determined by inspecting thetoString()output of the iterated traversal. Ifhasconditions were folded into theV()-step, an index - if one exists - will be used.
Additional References
Value Step
The value()-step (map) takes a Property and extracts the value from it.
gremlin> g.V(1).properties().value()
==>marko
==>san diego
==>santa cruz
==>brussels
==>santa fe
gremlin> g.V(1).properties().properties().value()
==>1997
==>2001
==>2001
==>2004
==>2004
==>2005
==>2005g.V(1).properties().value()
g.V(1).properties().properties().value()Additional References
ValueMap Step
The valueMap()-step yields a Map representation of the properties of an element.
|
Important
|
This step is the precursor to the elementMap()-step. Users should typically
choose elementMap() unless they utilize multi-properties. elementMap() effectively mimics the functionality of
valueMap(true).by(unfold()) as a single step.
|
gremlin> g.V().valueMap()
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[lop],lang:[java]]
==>[name:[josh],age:[32]]
==>[name:[ripple],lang:[java]]
==>[name:[peter],age:[35]]
gremlin> g.V().valueMap('age')
==>[age:[29]]
==>[age:[27]]
==>[]
==>[age:[32]]
==>[]
==>[age:[35]]
gremlin> g.V().valueMap('age','blah')
==>[age:[29]]
==>[age:[27]]
==>[]
==>[age:[32]]
==>[]
==>[age:[35]]
gremlin> g.E().valueMap()
==>[weight:0.5]
==>[weight:1.0]
==>[weight:0.4]
==>[weight:1.0]
==>[weight:0.4]
==>[weight:0.2]g.V().valueMap()
g.V().valueMap('age')
g.V().valueMap('age','blah')
g.E().valueMap()It is important to note that the map of a vertex maintains a list of values for each key. The map of an edge or vertex-property represents a single property (not a list). The reason is that vertices in TinkerPop leverage vertex properties which support multiple values per key. Using the "The Crew" toy graph, the point is made explicit.
gremlin> g.V().valueMap()
==>[name:[marko],location:[san diego,santa cruz,brussels,santa fe]]
==>[name:[stephen],location:[centreville,dulles,purcellville]]
==>[name:[matthias],location:[bremen,baltimore,oakland,seattle]]
==>[name:[daniel],location:[spremberg,kaiserslautern,aachen]]
==>[name:[gremlin]]
==>[name:[tinkergraph]]
gremlin> g.V().has('name','marko').properties('location')
==>vp[location->san diego]
==>vp[location->santa cruz]
==>vp[location->brussels]
==>vp[location->santa fe]
gremlin> g.V().has('name','marko').properties('location').valueMap()
==>[startTime:1997,endTime:2001]
==>[startTime:2001,endTime:2004]
==>[startTime:2004,endTime:2005]
==>[startTime:2005]g.V().valueMap()
g.V().has('name','marko').properties('location')
g.V().has('name','marko').properties('location').valueMap()To turn list of values into single items, the by() modulator can be used as shown below.
gremlin> g.V().valueMap().by(unfold())
==>[name:marko,location:san diego]
==>[name:stephen,location:centreville]
==>[name:matthias,location:bremen]
==>[name:daniel,location:spremberg]
==>[name:gremlin]
==>[name:tinkergraph]
gremlin> g.V().valueMap('name','location').by().by(unfold())
==>[name:[marko],location:san diego]
==>[name:[stephen],location:centreville]
==>[name:[matthias],location:bremen]
==>[name:[daniel],location:spremberg]
==>[name:[gremlin]]
==>[name:[tinkergraph]]g.V().valueMap().by(unfold())
g.V().valueMap('name','location').by().by(unfold())If the id, label, key, and value of the Element is desired, then the with() modulator can be used to
trigger its insertion into the returned map.
gremlin> g.V().hasLabel('person').valueMap().with(WithOptions.tokens)
==>[id:1,label:person,name:[marko],location:[san diego,santa cruz,brussels,santa fe]]
==>[id:7,label:person,name:[stephen],location:[centreville,dulles,purcellville]]
==>[id:8,label:person,name:[matthias],location:[bremen,baltimore,oakland,seattle]]
==>[id:9,label:person,name:[daniel],location:[spremberg,kaiserslautern,aachen]]
gremlin> g.V().hasLabel('person').valueMap('name').with(WithOptions.tokens, WithOptions.labels)
==>[label:person,name:[marko]]
==>[label:person,name:[stephen]]
==>[label:person,name:[matthias]]
==>[label:person,name:[daniel]]
gremlin> g.V().hasLabel('person').properties('location').valueMap().with(WithOptions.tokens, WithOptions.values)
==>[value:san diego,startTime:1997,endTime:2001]
==>[value:santa cruz,startTime:2001,endTime:2004]
==>[value:brussels,startTime:2004,endTime:2005]
==>[value:santa fe,startTime:2005]
==>[value:centreville,startTime:1990,endTime:2000]
==>[value:dulles,startTime:2000,endTime:2006]
==>[value:purcellville,startTime:2006]
==>[value:bremen,startTime:2004,endTime:2007]
==>[value:baltimore,startTime:2007,endTime:2011]
==>[value:oakland,startTime:2011,endTime:2014]
==>[value:seattle,startTime:2014]
==>[value:spremberg,startTime:1982,endTime:2005]
==>[value:kaiserslautern,startTime:2005,endTime:2009]
==>[value:aachen,startTime:2009]g.V().hasLabel('person').valueMap().with(WithOptions.tokens)
g.V().hasLabel('person').valueMap('name').with(WithOptions.tokens, WithOptions.labels)
g.V().hasLabel('person').properties('location').valueMap().with(WithOptions.tokens, WithOptions.values)Additional References
Values Step
The values()-step (map) extracts the values of properties from an Element in the traversal stream.
gremlin> g.V(1).values()
==>marko
==>san diego
==>santa cruz
==>brussels
==>santa fe
gremlin> g.V(1).values('location')
==>san diego
==>santa cruz
==>brussels
==>santa fe
gremlin> g.V(1).properties('location').values()
==>1997
==>2001
==>2001
==>2004
==>2004
==>2005
==>2005g.V(1).values()
g.V(1).values('location')
g.V(1).properties('location').values()Additional References
Vertex Steps

The vertex steps (flatMap) are fundamental to the Gremlin language. Via these steps, its possible to "move" on the graph — i.e. traverse.
-
out(string…): Move to the outgoing adjacent vertices given the edge labels. -
in(string…): Move to the incoming adjacent vertices given the edge labels. -
both(string…): Move to both the incoming and outgoing adjacent vertices given the edge labels. -
outE(string…): Move to the outgoing incident edges given the edge labels. -
inE(string…): Move to the incoming incident edges given the edge labels. -
bothE(string…): Move to both the incoming and outgoing incident edges given the edge labels. -
outV(): Move to the outgoing vertex. -
inV(): Move to the incoming vertex. -
bothV(): Move to both vertices. -
otherV(): Move to the vertex that was not the vertex that was moved from.
|
Groovy
|
The term |
|
Javascript
|
The term |
|
Python
|
The term |
gremlin> g.V(4)
==>v[4]
gremlin> g.V(4).outE() //// (1)
==>e[10][4-created->5]
==>e[11][4-created->3]
gremlin> g.V(4).inE('knows') //// (2)
==>e[8][1-knows->4]
gremlin> g.V(4).inE('created') //// (3)
gremlin> g.V(4).bothE('knows','created','blah')
==>e[10][4-created->5]
==>e[11][4-created->3]
==>e[8][1-knows->4]
gremlin> g.V(4).bothE('knows','created','blah').otherV()
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(4).both('knows','created','blah')
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(4).outE().inV() //// (4)
==>v[5]
==>v[3]
gremlin> g.V(4).out() //// (5)
==>v[5]
==>v[3]
gremlin> g.V(4).inE().outV()
==>v[1]
gremlin> g.V(4).inE().bothV()
==>v[1]
==>v[4]g.V(4)
g.V(4).outE() //// (1)
g.V(4).inE('knows') //// (2)
g.V(4).inE('created') //// (3)
g.V(4).bothE('knows','created','blah')
g.V(4).bothE('knows','created','blah').otherV()
g.V(4).both('knows','created','blah')
g.V(4).outE().inV() //// (4)
g.V(4).out() //// (5)
g.V(4).inE().outV()
g.V(4).inE().bothV()-
All outgoing edges.
-
All incoming knows-edges.
-
All incoming created-edges.
-
Moving forward touching edges and vertices.
-
Moving forward only touching vertices.
Additional References
Where Step
The where()-step filters the current object based on either the object itself (Scope.local) or the path history
of the object (Scope.global) (filter). This step is typically used in conjunction with either
match()-step or select()-step, but can be used in isolation.
gremlin> g.V(1).as('a').out('created').in('created').where(neq('a')) //// (1)
==>v[4]
==>v[6]
gremlin> g.withSideEffect('a',['josh','peter']).V(1).out('created').in('created').values('name').where(within('a')) //// (2)
==>josh
==>peter
gremlin> g.V(1).out('created').in('created').where(out('created').count().is(gt(1))).values('name') //// (3)
==>joshg.V(1).as('a').out('created').in('created').where(neq('a')) //// (1)
g.withSideEffect('a',['josh','peter']).V(1).out('created').in('created').values('name').where(within('a')) //// (2)
g.V(1).out('created').in('created').where(out('created').count().is(gt(1))).values('name') //3-
Who are marko’s collaborators, where marko can not be his own collaborator? (predicate)
-
Of the co-creators of marko, only keep those whose name is josh or peter. (using a sideEffect)
-
Which of marko’s collaborators have worked on more than 1 project? (using a traversal)
|
Important
|
Please see match().where() and select().where()
for how where() can be used in conjunction with Map<String,Object> projecting steps — i.e. Scope.local.
|
A few more examples of filtering an arbitrary object based on a anonymous traversal is provided below.
gremlin> g.V().where(out('created')).values('name') //// (1)
==>marko
==>josh
==>peter
gremlin> g.V().out('knows').where(out('created')).values('name') //// (2)
==>josh
gremlin> g.V().where(out('created').count().is(gte(2))).values('name') //// (3)
==>josh
gremlin> g.V().where(out('knows').where(out('created'))).values('name') //// (4)
==>marko
gremlin> g.V().where(__.not(out('created'))).where(__.in('knows')).values('name') //// (5)
==>vadas
gremlin> g.V().where(__.not(out('created')).and().in('knows')).values('name') //// (6)
==>vadas
gremlin> g.V().as('a').out('knows').as('b').
where('a',gt('b')).
by('age').
select('a','b').
by('name') //// (7)
==>[a:marko,b:vadas]
gremlin> g.V().as('a').out('knows').as('b').
where('a',gt('b').or(eq('b'))).
by('age').
by('age').
by(__.in('knows').values('age')).
select('a','b').
by('name') //// (8)
==>[a:marko,b:vadas]
==>[a:marko,b:josh]
gremlin> g.V().as('a').both().both().as('b').
where('a',eq('b')).by('age') //// (9)
==>v[1]
==>v[1]
==>v[1]
==>v[2]
==>v[4]
==>v[4]
==>v[4]
==>v[6]g.V().where(out('created')).values('name') //// (1)
g.V().out('knows').where(out('created')).values('name') //// (2)
g.V().where(out('created').count().is(gte(2))).values('name') //// (3)
g.V().where(out('knows').where(out('created'))).values('name') //// (4)
g.V().where(__.not(out('created'))).where(__.in('knows')).values('name') //// (5)
g.V().where(__.not(out('created')).and().in('knows')).values('name') //// (6)
g.V().as('a').out('knows').as('b').
where('a',gt('b')).
by('age').
select('a','b').
by('name') //// (7)
g.V().as('a').out('knows').as('b').
where('a',gt('b').or(eq('b'))).
by('age').
by('age').
by(__.in('knows').values('age')).
select('a','b').
by('name') //// (8)
g.V().as('a').both().both().as('b').
where('a',eq('b')).by('age') //9-
What are the names of the people who have created a project?
-
What are the names of the people that are known by someone one and have created a project?
-
What are the names of the people how have created two or more projects?
-
What are the names of the people who know someone that has created a project? (This only works in OLTP — see the
WARNINGbelow) -
What are the names of the people who have not created anything, but are known by someone?
-
The concatenation of
where()-steps is the same as a singlewhere()-step with an and’d clause. -
Marko knows josh and vadas but is only older than vadas.
-
Marko is younger than josh, but josh knows someone equal in age to marko (which is marko).
-
The "age" property is not productive for all vertices and therefore those values are filtered.
|
Warning
|
The anonymous traversal of where() processes the current object "locally". In OLAP, where the atomic unit
of computing is the vertex and its local "star graph," it is important that the anonymous traversal does not leave
the confines of the vertex’s star graph. In other words, it can not traverse to an adjacent vertex’s properties or
edges.
|
Additional References
With Step
The with()-step is not an actual step, but is instead a "step modulator" which modifies the behavior of the step
prior to it. The with()-step provides additional "configuration" information to steps that implement the Configuring
interface. Steps that allow for this type of modulation will explicitly state so in their documentation.
|
Javascript
|
The term |
|
Python
|
The term |
Write Step
The write()-step is not really a "step" but a step modulator in that it modifies the functionality of the io()-step.
More specifically, it tells the io()-step that it is expected to use its configuration to write data to some
location. Please see the documentation for io()-step for more complete details on usage.
Additional References
Traversal Parameterization
A subset of gremlin steps are able to accept parameterized arguments also known as GValues. GValues can be used to
provide protection against gremlin-injection attacks in cases where untrusted and unsanitized inputs must be passed as
step arguments. Additionally, use of GValues may offer performance benefits in certain environments by making use of
some query caching capabilities. Note that the reference implementation of the gremlin language and gremlin-server do
not have such a query caching mechanism, and thus will not see any performance improvements through parameterization. Users
should consult the documentation of their specific graph system details of potential performance benefits via parameterization.
|
Note
|
There are unique considerations regarding parameters when using gremlin-groovy scripts. Groovy allows for parameterization
at arbitrary points in the query in addition to the subset of parameterizable steps documented here. Groovy is also bound by
a comparatively slow script compilation, which makes parameterization essential for performant execution of gremlin-groovy scripts.
|
| Step | Parameterizable arguments |
|---|---|
String edgeLabel |
|
String vertexLabel |
|
String…edgeLabels |
|
String…edgeLabels |
|
Map params |
|
double probability |
|
Object values |
|
String delimiter |
|
E e/value |
|
Object values |
|
Object values |
|
Vertex fromVertex |
|
String label |
|
String label, String… labels |
|
String…edgeLabels |
|
String…edgeLabels |
|
Object values |
|
Long limit |
|
Object values |
|
Map searchCreate |
|
Map searchCreate |
|
M token, Map m |
|
String…edgeLabels |
|
String…edgeLabels |
|
Object values |
|
Long low, Long high |
|
Long limit |
|
Long limit |
|
String… edgeLabels, Vertex toVertex |
|
String…edgeLabels |
Additional References
A Note on Predicates
A P is a predicate of the form Function<Object,Boolean>. That is, given some object, return true or false. As of
the release of TinkerPop 3.4.0, Gremlin also supports simple text predicates, which only work on String values. The TextP
text predicates extend the P predicates, but are specialized in that they are of the form Function<String,Boolean>.
The provided predicates are outlined in the table below and are used in various steps such as has()-step,
where()-step, is()-step, etc. Two new additional TextP predicate members were added in the
TinkerPop 3.6.0 release that allow working with regular expressions. These are TextP.regex and TextP.notRegex
| Predicate | Description |
|---|---|
|
Is the incoming object equal to the provided object? |
|
Is the incoming object not equal to the provided object? |
|
Is the incoming number less than the provided number? |
|
Is the incoming number less than or equal to the provided number? |
|
Is the incoming number greater than the provided number? |
|
Is the incoming number greater than or equal to the provided number? |
|
Is the incoming number greater than the first provided number and less than the second? |
|
Is the incoming number less than the first provided number or greater than the second? |
|
Is the incoming number greater than or equal to the first provided number and less than the second? |
|
Is the incoming object in the array of provided objects? |
|
Is the incoming object not in the array of the provided objects? |
|
Does the incoming |
|
Does the incoming |
|
Does the incoming |
|
Does the incoming |
|
Does the incoming |
|
Does the incoming |
|
Does the incoming |
|
Does the incoming |
|
Note
|
The TinkerPop reference implementation uses the Java Pattern and Matcher classes for it regular expression
engine. Other implementations may decide to use a different regular expression engine. It’s a good idea to check
the documentation for the implementation you are using to verify the allowed regular expression syntax.
|
gremlin> eq(2)
==>eq(2)
gremlin> not(neq(2)) //// (1)
==>eq(2)
gremlin> not(within('a','b','c'))
==>without([a, b, c])
gremlin> not(within('a','b','c')).test('d') //// (2)
==>true
gremlin> not(within('a','b','c')).test('a')
==>false
gremlin> within(1,2,3).and(not(eq(2))).test(3) //// (3)
==>true
gremlin> inside(1,4).or(eq(5)).test(3) //// (4)
==>true
gremlin> inside(1,4).or(eq(5)).test(5)
==>true
gremlin> between(1,2) //// (5)
==>and(gte(1), lt(2))
gremlin> not(between(1,2))
==>or(lt(1), gte(2))eq(2)
not(neq(2)) //// (1)
not(within('a','b','c'))
not(within('a','b','c')).test('d') //// (2)
not(within('a','b','c')).test('a')
within(1,2,3).and(not(eq(2))).test(3) //// (3)
inside(1,4).or(eq(5)).test(3) //// (4)
inside(1,4).or(eq(5)).test(5)
between(1,2) //// (5)
not(between(1,2))-
The
not()of aP-predicate is anotherP-predicate. -
P-predicates are arguments to various steps which internallytest()the incoming value. -
P-predicates can be and’d together. -
P-predicates can be or' together. -
and()is aP-predicate and thus, aP-predicate can be composed of multipleP-predicates.
|
Tip
|
To reduce the verbosity of predicate expressions, it is good to
import static org.apache.tinkerpop.gremlin.process.traversal.P.*.
|
The following example demonstrates how the regex() predicate is used and it demonstrates an important point. When
using regex(), the string is considered a match to the pattern if any substring matches the pattern. It is therefore
important to use the appropriate boundary matchers (e.g. $ for end of a line) to ensure a proper match.
gremlin> g.V().has('person', 'name', regex('peter')).values('name')
==>peter
gremlin> g.V().has('person', 'name', regex('r')).values('name')
==>marko
==>peter
gremlin> g.V().has('person', 'name', regex('r$')).values('name')
==>peterg.V().has('person', 'name', regex('peter')).values('name')
g.V().has('person', 'name', regex('r')).values('name')
g.V().has('person', 'name', regex('r$')).values('name')Finally, note that where()-step takes a P<String>. The provided string value refers to a variable
binding, not to the explicit string value.
gremlin> g.V().as('a').both().both().as('b').count()
==>30
gremlin> g.V().as('a').both().both().as('b').where('a',neq('b')).count()
==>18g.V().as('a').both().both().as('b').count()
g.V().as('a').both().both().as('b').where('a',neq('b')).count()A Note on Barrier Steps
 Gremlin is primarily a
lazy, stream processing language. This means that Gremlin fully
processes (to the best of its abilities) any traversers currently in the traversal pipeline before getting more data
from the start/head of the traversal. However, there are numerous situations in which a completely lazy computation
is not possible (or impractical). When a computation is not lazy, a "barrier step" exists. There are three types of
barriers:
Gremlin is primarily a
lazy, stream processing language. This means that Gremlin fully
processes (to the best of its abilities) any traversers currently in the traversal pipeline before getting more data
from the start/head of the traversal. However, there are numerous situations in which a completely lazy computation
is not possible (or impractical). When a computation is not lazy, a "barrier step" exists. There are three types of
barriers:
-
CollectingBarrierStep: All of the traversers prior to the step are put into a collection and then processed in some way (e.g. ordered) prior to the collection being "drained" one-by-one to the next step. Examples include:order(),sample(),aggregate(),barrier(). -
ReducingBarrierStep: All of the traversers prior to the step are processed by a reduce function and once all the previous traversers are processed, a single "reduced value" traverser is emitted to the next step. Note that the path history leading up to a reducing barrier step is destroyed given its many-to-one nature. Examples include:fold(),count(),sum(),max(),min(). -
SupplyingBarrierStep: All of the traversers prior to the step are iterated (no processing) and then some provided supplier yields a single traverser to continue to the next step. Examples include:cap().
In Gremlin OLAP (see TraversalVertexProgram), a barrier is introduced at the end of
every adjacent vertex step. This means that the traversal does its best to compute as much as
possible at the current, local vertex. What it can’t compute without referencing an adjacent vertex is aggregated
into a barrier collection. When there are no more traversers at the local vertex, the barriered traversers are the
messages that are propagated to remote vertices for further processing.
A Note on Scopes
The Scope enum has two constants: Scope.local and Scope.global. Scope determines whether the particular step
being scoped is with respects to the current object (local) at that step or to the entire stream of objects up to that
step (global).
|
Python
|
The term |
gremlin> g.V().has('name','marko').out('knows').count() //// (1)
==>2
gremlin> g.V().has('name','marko').out('knows').fold().count() //// (2)
==>1
gremlin> g.V().has('name','marko').out('knows').fold().count(local) //// (3)
==>2
gremlin> g.V().has('name','marko').out('knows').fold().count(global) //// (4)
==>1g.V().has('name','marko').out('knows').count() //// (1)
g.V().has('name','marko').out('knows').fold().count() //// (2)
g.V().has('name','marko').out('knows').fold().count(local) //// (3)
g.V().has('name','marko').out('knows').fold().count(global) //4-
Marko knows 2 people.
-
A list of Marko’s friends is created and thus, one object is counted (the single list).
-
A list of Marko’s friends is created and a
local-count yields the number of objects in that list. -
count(global)is the same ascount()as the default behavior for most scoped steps isglobal.
The steps that support scoping are:
-
count(): count the local collection or global stream. -
dedup(): dedup the local collection of global stream. -
max(): get the max value in the local collection or global stream. -
mean(): get the mean value in the local collection or global stream. -
min(): get the min value in the local collection or global stream. -
order(): order the objects in the local collection or global stream. -
range(): clip the local collection or global stream. -
limit(): clip the local collection or global stream. -
sample(): sample objects from the local collection or global stream. -
tail(): get the tail of the objects in the local collection or global stream.
A few more examples of the use of Scope are provided below:
gremlin> g.V().both().group().by(label).select('software').dedup(local)
==>[v[3],v[5]]
gremlin> g.V().groupCount().by(label).select(values).min(local)
==>2
gremlin> g.V().groupCount().by(label).order(local).by(values,desc)
==>[person:4,software:2]
gremlin> g.V().fold().sample(local,2)
==>[v[5],v[6]]g.V().both().group().by(label).select('software').dedup(local)
g.V().groupCount().by(label).select(values).min(local)
g.V().groupCount().by(label).order(local).by(values,desc)
g.V().fold().sample(local,2)Finally, note that local()-step is a "hard-scoped step" that transforms any internal traversal into a
locally-scoped operation. A contrived example is provided below:
gremlin> g.V().fold().local(unfold().count())
==>6
gremlin> g.V().fold().count(local)
==>6g.V().fold().local(unfold().count())
g.V().fold().count(local)A Note On Lambdas
 A lambda is a function
that can be referenced by software and thus, passed around like any other piece of data. In Gremlin, lambdas make it
possible to generalize the behavior of a step such that custom steps can be created (on-the-fly) by the user. However,
it is advised to avoid using lambdas if possible.
A lambda is a function
that can be referenced by software and thus, passed around like any other piece of data. In Gremlin, lambdas make it
possible to generalize the behavior of a step such that custom steps can be created (on-the-fly) by the user. However,
it is advised to avoid using lambdas if possible.
gremlin> g.V().filter{it.get().value('name') == 'marko'}.
flatMap{it.get().vertices(OUT,'created')}.
map {it.get().value('name')} //// (1)
==>lop
gremlin> g.V().has('name','marko').out('created').values('name') //// (2)
==>lopg.V().filter{it.get().value('name') == 'marko'}.
flatMap{it.get().vertices(OUT,'created')}.
map {it.get().value('name')} //// (1)
g.V().has('name','marko').out('created').values('name') //2-
A lambda-rich Gremlin traversal which should and can be avoided. (bad)
-
The same traversal (result), but without using lambdas. (good)
Gremlin attempts to provide the user a comprehensive collection of steps in the hopes that the user will never need to leverage a lambda in practice. It is advised that users only leverage a lambda if and only if there is no corresponding lambda-less step that encompasses the desired functionality. The reason being, lambdas can not be optimized by Gremlin’s compiler strategies as they can not be programmatically inspected (see traversal strategies). It is also not currently possible to send a natively written lambda for remote execution to Gremlin-Server or a driver that supports remote execution.
In many situations where a lambda could be used, either a corresponding step exists or a traversal can be provided in
its place. A TraversalLambda behaves like a typical lambda, but it can be optimized and it yields less objects than
the corresponding pure-lambda form.
gremlin> g.V().out().out().path().by {it.value('name')}.
by {it.value('name')}.
by {g.V(it).in('created').values('name').fold().next()} //// (1)
==>[marko,josh,[josh]]
==>[marko,josh,[marko,josh,peter]]
gremlin> g.V().out().out().path().by('name').
by('name').
by(__.in('created').values('name').fold()) //// (2)
==>[marko,josh,[josh]]
==>[marko,josh,[marko,josh,peter]]g.V().out().out().path().by {it.value('name')}.
by {it.value('name')}.
by {g.V(it).in('created').values('name').fold().next()} //// (1)
g.V().out().out().path().by('name').
by('name').
by(__.in('created').values('name').fold()) //2-
The length-3 paths have each of their objects transformed by a lambda. (bad)
-
The length-3 paths have their objects transformed by a lambda-less step and a traversal lambda. (good)
TraversalStrategy
 A
A TraversalStrategy analyzes a Traversal and, if the traversal
meets its criteria, can mutate it accordingly. Traversal strategies are executed at compile-time and form the foundation
of the Gremlin traversal machine’s compiler. There are 5 categories of strategies which are itemized below:
-
There is an application-level feature that can be embedded into the traversal logic (decoration).
-
There is a more efficient way to express the traversal at the TinkerPop level (optimization).
-
There is a more efficient way to express the traversal at the graph system/language/driver level (provider optimization).
-
There are some final adjustments/cleanups/analyses required before executing the traversal (finalization).
-
There are certain traversals that are not legal for the application or traversal engine (verification).
|
Note
|
The explain()-step shows the user how each registered strategy mutates the traversal.
|
TinkerPop ships with a generous number of TraversalStrategy definitions, most of which are applied implicitly when
executing a gremlin traversal. Users and providers can add TraversalStrategy definitions for particular needs. The
following sections detail how traversal strategies are applied and defined and describe a collection of traversal
strategies that are generally useful to end-users.
Application
One can explicitly add or remove TraversalStrategy strategies on the GraphTraversalSource with the withStrategies()
and withoutStrategies() start steps, see the ReadOnlyStrategy and the
barrier() step for examples. End users typically do this as part of issuing a gremlin traversal, either
on a locally opened graph or a remotely accessed graph. However, when configuring Gremlin Server, traversal strategies
can also be applied on exposed GraphTraversalSource instances and as part of an Authorizer implementation, see
Gremlin Server Authorization.
Therefore, one should keep the following in mind when modifying the list of TraversalStrategy strategies:
-
A
TraversalStrategyadded to the traversal can be removed again later on. An example is theconf/gremlin-server-modern-readonly.yamlfile from the Gremlin Server distribution, which applies theReadOnlyStrategyto theGraphTraversalSourcethat remote clients can connect to. However, a remote client can remove it on its turn by applying thewithoutStrategies()step with theReadOnlyStrategy. -
When a
TraversalStrategyof a particular type is added, it replaces any instances of its type that exist prior to it. Multiple instances of aTraversalStrategycan therefore not be registered and their functionality is no way merged automatically. Therefore, if there is a particular strategy registered whose functionality needs to be changed it is important to either find and modify the existing instance or construct a new one copying the options to keep from the old to the new instance.
Definition
A simple OptimizationStrategy is the IdentityRemovalStrategy.
public final class IdentityRemovalStrategy extends AbstractTraversalStrategy<TraversalStrategy.OptimizationStrategy> implements TraversalStrategy.OptimizationStrategy {
private static final IdentityRemovalStrategy INSTANCE = new IdentityRemovalStrategy();
private IdentityRemovalStrategy() {
}
@Override
public void apply(Traversal.Admin<?, ?> traversal) {
if (traversal.getSteps().size() <= 1)
return;
for (IdentityStep<?> identityStep : TraversalHelper.getStepsOfClass(IdentityStep.class, traversal)) {
if (identityStep.getLabels().isEmpty() || !(identityStep.getPreviousStep() instanceof EmptyStep)) {
TraversalHelper.copyLabels(identityStep, identityStep.getPreviousStep(), false);
traversal.removeStep(identityStep);
}
}
}
public static IdentityRemovalStrategy instance() {
return INSTANCE;
}
}This strategy simply removes any IdentityStep steps in the Traversal as aStep().identity().identity().bStep()
is equivalent to aStep().bStep(). For those traversal strategies that require other strategies to execute prior or
post to the strategy, then the following two methods can be defined in TraversalStrategy (with defaults being an
empty set). If the TraversalStrategy is in a particular traversal category (i.e. decoration, optimization,
provider-optimization, finalization, or verification), then priors and posts are only possible within the respective category.
public Set<Class<? extends S>> applyPrior();
public Set<Class<? extends S>> applyPost();|
Important
|
TraversalStrategy categories are sorted within their category and the categories are then executed in
the following order: decoration, optimization, provider optimization, finalization, and verification. If a designed strategy
does not fit cleanly into these categories, then it can implement TraversalStrategy and its prior and posts can reference
strategies within any category. However, such generalization are strongly discouraged.
|
An example of a GraphSystemOptimizationStrategy is provided below.
g.V().has('name','marko')The expression above can be executed in a O(|V|) or O(log(|V|) fashion in TinkerGraph
depending on whether there is or is not an index defined for "name."
public final class TinkerGraphStepStrategy extends AbstractTraversalStrategy<TraversalStrategy.ProviderOptimizationStrategy> implements TraversalStrategy.ProviderOptimizationStrategy {
private static final TinkerGraphStepStrategy INSTANCE = new TinkerGraphStepStrategy();
private TinkerGraphStepStrategy() {
}
@Override
public void apply(Traversal.Admin<?, ?> traversal) {
if (TraversalHelper.onGraphComputer(traversal))
return;
for (GraphStep originalGraphStep : TraversalHelper.getStepsOfClass(GraphStep.class, traversal)) {
TinkerGraphStep<?, ?> tinkerGraphStep = new TinkerGraphStep<>(originalGraphStep);
TraversalHelper.replaceStep(originalGraphStep, tinkerGraphStep, traversal);
Step<?, ?> currentStep = tinkerGraphStep.getNextStep();
while (currentStep instanceof HasStep || currentStep instanceof NoOpBarrierStep) {
if (currentStep instanceof HasStep) {
for (HasContainer hasContainer : ((HasContainerHolder) currentStep).getHasContainers()) {
if (!GraphStep.processHasContainerIds(tinkerGraphStep, hasContainer))
tinkerGraphStep.addHasContainer(hasContainer);
}
TraversalHelper.copyLabels(currentStep, currentStep.getPreviousStep(), false);
traversal.removeStep(currentStep);
}
currentStep = currentStep.getNextStep();
}
}
}
public static TinkerGraphStepStrategy instance() {
return INSTANCE;
}
}The traversal is redefined by simply taking a chain of has()-steps after g.V() (TinkerGraphStep) and providing
their HasContainers to TinkerGraphStep. Then its up to TinkerGraphStep to determine if an appropriate index exists.
Given that the strategy uses non-TinkerPop provided steps, it should go into the ProviderOptimizationStrategy category
to ensure the added step does not interfere with the assumptions of the OptimizationStrategy strategies.
gremlin> t = g.V().has('name','marko'); null
==>null
gremlin> t.toString()
==>[GraphStep(vertex,[]), HasStep([name.eq(marko)])]
gremlin> t.iterate(); null
==>null
gremlin> t.toString()
==>[TinkerGraphStep(vertex,[name.eq(marko)]), DiscardStep]t = g.V().has('name','marko'); null
t.toString()
t.iterate(); null
t.toString()|
Warning
|
The reason that OptimizationStrategy and ProviderOptimizationStrategy are two different categories is
that optimization strategies should only rewrite the traversal using TinkerPop steps. This ensures that the
optimizations executed at the end of the optimization strategy round are TinkerPop compliant. From there, provider
optimizations can analyze the traversal and rewrite the traversal as desired using graph system specific steps (e.g.
replacing GraphStep.HasStep…HasStep with TinkerGraphStep). If provider optimizations use graph system specific
steps and implement OptimizationStrategy, then other TinkerPop optimizations may fail to optimize the traversal or
mis-understand the graph system specific step behaviors (e.g. ProviderVertexStep extends VertexStep) and yield
incorrect semantics.
|
Finally, here is a complicated traversal that has various components that are optimized by the default TinkerPop strategies.
gremlin> g.V().hasLabel('person'). //// (1)
and(has('name'), //// (2)
has('name','marko'),
filter(has('age',gt(20)))). //// (3)
match(__.as('a').has('age',lt(32)), //// (4)
__.as('a').repeat(outE().inV()).times(2).as('b')). //// (5)
where('a',neq('b')). //// (6)
where(__.as('b').both().count().is(gt(1))). //// (7)
select('b'). //// (8)
groupCount().
by(out().count()). //// (9)
explain()
==>Traversal Explanation
=========================================================================================================================================================================================================================================================================================
Original Traversal [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartS
tep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
ConnectiveStrategy [D] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartS
tep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
IdentityRemovalStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartS
tep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
ByModulatorOptimizationStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartS
tep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
EarlyLimitStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)]]), WherePredicateStep(a,neq(b)), WhereTraversalStep([WhereStartS
tep(b), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
MatchPredicateStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndSt
ep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])
]
FilterRankingStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), AndStep([[TraversalFilterStep([PropertiesStep([name],value)])], [HasStep([name.eq(marko)])], [TraversalFilterStep([HasStep([age.gt(20)])])]]), MatchStep(null,AND,[[MatchStartStep(a), HasS
tep([age.lt(32)]), MatchEndStep(null)], [MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeVertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndSt
ep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])
]
InlineFilterStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],value)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), RepeatStep([VertexStep(OUT,edge), EdgeV
ertexStep(IN), RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), C
ountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
IncidentToAdjacentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],value)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), RepeatStep([VertexStep(OUT,vertex), Rep
eatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,vertex), CountGlobalStep, Is
Step(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,vertex), CountGlobalStep])]
AdjacentToIncidentStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), RepeatStep([VertexStep(OUT,vertex),
RepeatEndStep],until(loops(2)),emit(false)), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), CountGlobalStep, I
sStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
RepeatUnrollStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), VertexStep(O
UT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null
)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
CountStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), VertexStep(O
UT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1)
)]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
PathRetractionStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), VertexStep(O
UT,vertex), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalStep(0,2), CountGlobalStep, IsStep(gt(1)
)]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
LazyBarrierStrategy [O] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), NoOpBarrierS
tep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), Range
GlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
TinkerGraphCountStrategy [P] [GraphStep(vertex,[]), HasStep([~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), NoOpBarrierS
tep(2500), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), Range
GlobalStep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), NoOpBarrierStep(250
0), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalS
tep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
ProfileStrategy [F] [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), NoOpBarrierStep(250
0), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalS
tep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), NoOpBarrierStep(250
0), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalS
tep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]
Final Traversal [TinkerGraphStep(vertex,[~label.eq(person)]), TraversalFilterStep([PropertiesStep([name],property)]), HasStep([name.eq(marko), age.gt(20), age.lt(32)])@[a], MatchStep(null,AND,[[MatchStartStep(a), VertexStep(OUT,vertex), NoOpBarrierStep(250
0), VertexStep(OUT,vertex), NoOpBarrierStep(2500), MatchEndStep(b)], [MatchStartStep(a), WherePredicateStep(null,neq(b)), MatchEndStep(null)], [MatchStartStep(b), WhereTraversalStep([WhereStartStep(null), VertexStep(BOTH,edge), RangeGlobalS
tep(0,2), CountGlobalStep, IsStep(gt(1))]), MatchEndStep(null)]]), SelectOneStep(last,b,null), GroupCountStep([VertexStep(OUT,edge), CountGlobalStep])]g.V().hasLabel('person'). //// (1)
and(has('name'), //// (2)
has('name','marko'),
filter(has('age',gt(20)))). //// (3)
match(__.as('a').has('age',lt(32)), //// (4)
__.as('a').repeat(outE().inV()).times(2).as('b')). //// (5)
where('a',neq('b')). //// (6)
where(__.as('b').both().count().is(gt(1))). //// (7)
select('b'). //// (8)
groupCount().
by(out().count()). //// (9)
explain()-
TinkerGraphStepStrategypulls inhas()-step predicates for global, graph-centric index lookups. -
FilterRankStrategysorts filter steps by their time/space execution costs. -
InlineFilterStrategyde-nests filters to increase the likelihood of filter concatenation and aggregation. -
InlineFilterStrategypulls out named predicates frommatch()-step to more easily allow provider strategies to use indices. -
RepeatUnrollStrategywill unroll loops andIncidentToAdjacentStrategywill turnoutE().inV()-patterns intoout(). -
MatchPredicateStrategywill pull inwhere()-steps so that they can be subjected tomatch()-steps runtime query optimizer. -
CountStrategywill limit the traversal to only the number of traversers required for thecount().is(x)-check. -
PathRetractionStrategywill remove paths from the traversers and increase the likelihood of bulking as path data is not required afterselect('b'). -
AdjacentToIncidentStrategywill turnout()intooutE()to increase data access locality.
EdgeLabelVerificationStrategy
EdgeLabelVerificationStrategy prevents traversals from writing traversals that do not explicitly specify and edge
label when using steps like out(), 'in()', 'both()' and their related E oriented steps, providing the
option to throw an exception, log a warning or do both when one of these keys is encountered in a mutating step.
EdgeLabelVerificationStrategy verificationStrategy = EdgeLabelVerificationStrategy.build()
.throwException().create()
// results in VerificationException - as out() does not have a label specified
g.withStrategies(verificationStrategy).V(1).out().iterate();// results in VerificationException - as out() does not have a label specified
g.withStrategies(new EdgeLabelVerificationStrategy(throwException: true))
.V(1).out().iterate()// results in VerificationException - as out() does not have a label specified
g.WithStrategies(new EdgeLabelVerificationStrategy(throwException: true))
.V(1).Out().Iterate();// results in Error - as out() does not have a label specified
g.withStrategies(new EdgeLabelVerificationStrategy(throwException: true))
.V(1).out().iterate();// results in Error - as out() does not have a label specified
g.withStrategies(EdgeLabelVerificationStrategy(throwException=true))
.V(1).out().iterate()ElementIdStrategy
ElementIdStrategy provides control over element identifiers. Some Graph implementations, such as TinkerGraph,
allow specification of custom identifiers when creating elements:
gremlin> g = traversal().withEmbedded(TinkerGraph.open())
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> v = g.addV().property(id,'42a').next()
==>v[42a]
gremlin> g.V('42a')
==>v[42a]g = traversal().withEmbedded(TinkerGraph.open())
v = g.addV().property(id,'42a').next()
g.V('42a')Other Graph implementations generate element identifiers automatically and cannot be assigned.
As a helper, ElementIdStrategy can be used to make identifier assignment possible by using vertex and edge indices
under the hood. Note that this demonstration is using TinkerGraph for convenience, however in practice
ElementIdStrategy offers little value in a Graph which allows custom identifiers.
gremlin> strategy = ElementIdStrategy.build().create()
==>ElementIdStrategy
gremlin> g = traversal().withEmbedded(TinkerGraph.open()).withStrategies(strategy)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.addV().property(id, '42a').id()
==>42a
gremlin> g.V().elementMap()
==>[id:0,label:vertex,__id:42a]strategy = ElementIdStrategy.build().create()
g = traversal().withEmbedded(TinkerGraph.open()).withStrategies(strategy)
g.addV().property(id, '42a').id()
g.V().elementMap()|
Important
|
The key that is used to store the assigned identifier should be indexed in the underlying graph database. If it is not indexed, then lookups for the elements that use these identifiers will perform a linear scan. |
EventStrategy
The purpose of the EventStrategy is to raise events to one or more MutationListener objects as changes to the
underlying Graph occur within a Traversal. Such a strategy is useful for logging changes, triggering certain
actions based on change, or any application that needs notification of some mutating operation during a Traversal.
If the transaction is rolled back, the event queue is reset.
The following events are raised to the MutationListener:
-
New vertex
-
New edge
-
Vertex property changed
-
Edge property changed
-
Vertex property removed
-
Edge property removed
-
Vertex removed
-
Edge removed
To start processing events from a Traversal first implement the MutationListener interface. An example of this
implementation is the ConsoleMutationListener which writes output to the console for each event. The following
console session displays the basic usage:
gremlin> import org.apache.tinkerpop.gremlin.process.traversal.step.util.event.*
==>org.apache.tinkerpop.gremlin.process.traversal.step.util.event.*
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> l = new ConsoleMutationListener(graph)
==>MutationListener[tinkergraph[vertices:6 edges:6]]
gremlin> strategy = EventStrategy.build().addListener(l).create()
==>EventStrategy
gremlin> g = traversal().with(graph).withStrategies(strategy)
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.addV().property('name','stephen')
Vertex [v[0]] added to graph [tinkergraph[vertices:7 edges:6]]
==>v[0]
gremlin> g.V().has('name','stephen').
property(list, 'location', 'centreville', 'startTime', 1990, 'endTime', 2000).
property(list, 'location', 'dulles', 'startTime', 2000, 'endTime', 2006).
property(list, 'location', 'purcellville', 'startTime', 2006)
Vertex [v[0]] property [vp[empty]] change to [centreville] in graph [tinkergraph[vertices:7 edges:6]]
Vertex [v[0]] property [vp[empty]] change to [dulles] in graph [tinkergraph[vertices:7 edges:6]]
Vertex [v[0]] property [vp[empty]] change to [purcellville] in graph [tinkergraph[vertices:7 edges:6]]
==>v[0]
gremlin> g.V().has('name','stephen').
property(set, 'location', 'purcellville', 'startTime', 2006, 'endTime', 2019)
Vertex [v[0]] property [vp[location->purcellville]] change to [purcellville] in graph [tinkergraph[vertices:7 edges:6]]
==>v[0]
gremlin> g.E().drop()
Edge [e[7][1-knows->2]] removed from graph [tinkergraph[vertices:7 edges:6]]
Edge [e[8][1-knows->4]] removed from graph [tinkergraph[vertices:7 edges:5]]
Edge [e[9][1-created->3]] removed from graph [tinkergraph[vertices:7 edges:4]]
Edge [e[10][4-created->5]] removed from graph [tinkergraph[vertices:7 edges:3]]
Edge [e[11][4-created->3]] removed from graph [tinkergraph[vertices:7 edges:2]]
Edge [e[12][6-created->3]] removed from graph [tinkergraph[vertices:7 edges:1]]import org.apache.tinkerpop.gremlin.process.traversal.step.util.event.*
graph = TinkerFactory.createModern()
l = new ConsoleMutationListener(graph)
strategy = EventStrategy.build().addListener(l).create()
g = traversal().with(graph).withStrategies(strategy)
g.addV().property('name','stephen')
g.V().has('name','stephen').
property(list, 'location', 'centreville', 'startTime', 1990, 'endTime', 2000).
property(list, 'location', 'dulles', 'startTime', 2000, 'endTime', 2006).
property(list, 'location', 'purcellville', 'startTime', 2006)
g.V().has('name','stephen').
property(set, 'location', 'purcellville', 'startTime', 2006, 'endTime', 2019)
g.E().drop()By default, the EventStrategy is configured with an EventQueue that raises events as they occur within execution
of a Step. As such, the final line of Gremlin execution that drops all edges shows a bit of an inconsistent count,
where the removed edge count is accounted for after the event is raised. The strategy can also be configured with a
TransactionalEventQueue that captures the changes within a transaction and does not allow them to fire until the
transaction is committed.
|
Warning
|
EventStrategy is not meant for usage in tracking global mutations across separate processes. In other
words, a mutation in one JVM process is not raised as an event in a different JVM process. In addition, events are
not raised when mutations occur outside of the Traversal context.
|
Another default configuration for EventStrategy revolves around the concept of "detachment". Graph elements are
detached from the graph as copies when passed to referring mutation events. Therefore, when adding a new Vertex in
TinkerGraph, the event will not contain a TinkerVertex but will instead include a DetachedVertex. This behavior
can be modified with the detach() method on the EventStrategy.Builder which accepts the following inputs: null
meaning no detachment and the return of the original element, DetachedFactory which is the same as the default
behavior, and ReferenceFactory which will return "reference" elements only with no properties.
|
Important
|
If setting the detach() configuration to null, be aware that transactional graphs will likely create a
new transaction immediately following the commit() that raises the events. The graph elements raised in the events
may also not behave as "snapshots" at the time of their creation as they are "live" references to actual database
elements.
|
PartitionStrategy

PartitionStrategy partitions the vertices and edges of a graph into String named partitions (i.e. buckets,
subgraphs, etc.). The idea behind PartitionStrategy is presented in the image above where each element is in a
single partition (represented by its color). Partitions can be read from, written to, and linked/joined by edges
that span one or two partitions (e.g. a tail vertex in one partition and a head vertex in another).
There are three primary configurations in PartitionStrategy:
-
Partition Key - The property key that denotes a String value representing a partition.
-
Write Partition - A
Stringdenoting what partition all future written elements will be in. -
Read Partitions - A
Set<String>of partitions that can be read from.
The best way to understand PartitionStrategy is via example.
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> strategyA = new PartitionStrategy(partitionKey: "_partition", writePartition: "a", readPartitions: ["a"])
==>PartitionStrategy
gremlin> strategyB = new PartitionStrategy(partitionKey: "_partition", writePartition: "b", readPartitions: ["b"])
==>PartitionStrategy
gremlin> gA = traversal().with(graph).withStrategies(strategyA)
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> gA.addV() // this vertex has a property of {_partition:"a"}
==>v[0]
gremlin> gB = traversal().with(graph).withStrategies(strategyB)
==>graphtraversalsource[tinkergraph[vertices:7 edges:6], standard]
gremlin> gB.addV() // this vertex has a property of {_partition:"b"}
==>v[13]
gremlin> gA.V()
==>v[0]
gremlin> gB.V()
==>v[13]graph = TinkerFactory.createModern()
strategyA = new PartitionStrategy(partitionKey: "_partition", writePartition: "a", readPartitions: ["a"])
strategyB = new PartitionStrategy(partitionKey: "_partition", writePartition: "b", readPartitions: ["b"])
gA = traversal().with(graph).withStrategies(strategyA)
gA.addV() // this vertex has a property of {_partition:"a"}
gB = traversal().with(graph).withStrategies(strategyB)
gB.addV() // this vertex has a property of {_partition:"b"}
gA.V()
gB.V()The following examples demonstrate the above PartitionStrategy definition for "strategyA" in other programming
languages:
PartitionStrategy strategyA = PartitionStrategy.build().partitionKey("_partition")
.writePartition("a")
.readPartitions("a").create();PartitionStrategy strategyA = new PartitionStrategy(
partitionKey: "_partition", writePartition: "a",
readPartitions: new List<string>(){"a"});const strategyA = new PartitionStrategy(partitionKey: "_partition", writePartition: "a", readPartitions: ["a"])strategyA = PartitionStrategy(partitionKey="_partition", writePartition="a", readPartitions=["a"])Partitions may also extend to VertexProperty elements if the Graph can support meta-properties and if the
includeMetaProperties value is set to true when the PartitionStrategy is built. The partitionKey will be
stored in the meta-properties of the VertexProperty and blind the traversal to those properties. Please note that
the VertexProperty will only be hidden by way of the Traversal itself. For example, calling Vertex.property(k)
bypasses the context of the PartitionStrategy and will thus allow all properties to be accessed.
By writing elements to particular partitions and then restricting read partitions, the developer is able to create multiple graphs within a single address space. Moreover, by supporting references between partitions, it is possible to merge those multiple graphs (i.e. join partitions).
ReadOnlyStrategy
ReadOnlyStrategy is largely self-explanatory. A Traversal that has this strategy applied will throw an
IllegalStateException if the Traversal has any mutating steps within it.
ReadOnlyStrategy verificationStrategy = ReadOnlyStrategy.instance();
// results in VerificationException
g.withStrategies(verificationStrategy).addV('person').iterate();// results in VerificationException
g.withStrategies(ReadOnlyStrategy).addV('person').iterate();// results in VerificationException
g.WithStrategies(new ReadOnlyStrategy()).addV("person").Iterate();// results in Error
g.withStrategies(new ReadOnlyStrategy()).addV("person").iterate();// results in Error
g.withStrategies(ReadOnlyStrategy).addV("person").iterate()ReservedKeysVerificationStrategy
ReservedKeysVerificationStrategy prevents traversals from adding property keys that are protected, providing the
option to throw an exception, log a warning or do both when one of these keys is encountered in a mutating step. By
default "id" and "label" are considered "reserved" but the default can be changed by building with the
reservedKeys() options and supply a Set of keys to trigger the VerificationException.
ReservedKeysVerificationStrategy verificationStrategy = ReservedKeysVerificationStrategy.build()
.throwException().create()
// results in VerificationException
g.withStrategies(verificationStrategy).addV('person').property("id",123).iterate();// results in VerificationException
g.withStrategies(new ReservedKeysVerificationStrategy(throwException: true))
.addV('person').property("id",123).iterate()// results in VerificationException
g.WithStrategies(new ReservedKeysVerificationStrategy(throwException: true))
.AddV('person').Property("id",123).Iterate();// results in Error
g.withStrategies(new ReservedKeysVerificationStrategy(throwException: true))
.addV('person').property("id",123).iterate();// results in Error
g.withStrategies(ReservedKeysVerificationStrategy(throwException=true))
.addV('person').property("id",123).iterate()SeedStrategy
There are number of components of the Gremlin language that, by design, can produce non-deterministic results:
To get these steps to return deterministic results, SeedStrategy allows assignment of a seed value to the Random
operations of the steps. The following example demonstrates the random nature of shuffle:
gremlin> g.V().values('name').fold().order(local).by(shuffle)
==>[ripple,peter,vadas,josh,lop,marko]
gremlin> g.V().values('name').fold().order(local).by(shuffle)
==>[marko,lop,peter,josh,ripple,vadas]
gremlin> g.V().values('name').fold().order(local).by(shuffle)
==>[lop,marko,josh,peter,vadas,ripple]
gremlin> g.V().values('name').fold().order(local).by(shuffle)
==>[josh,marko,vadas,lop,ripple,peter]
gremlin> g.V().values('name').fold().order(local).by(shuffle)
==>[peter,josh,marko,vadas,lop,ripple]g.V().values('name').fold().order(local).by(shuffle)
g.V().values('name').fold().order(local).by(shuffle)
g.V().values('name').fold().order(local).by(shuffle)
g.V().values('name').fold().order(local).by(shuffle)
g.V().values('name').fold().order(local).by(shuffle)With SeedStrategy in place, however, the same order is applied each time:
gremlin> seedStrategy = SeedStrategy.build().seed(999998L).create()
==>SeedStrategy
gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
==>[peter,josh,marko,lop,ripple,vadas]
gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
==>[peter,josh,marko,lop,ripple,vadas]
gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
==>[peter,josh,marko,lop,ripple,vadas]
gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
==>[peter,josh,marko,lop,ripple,vadas]
gremlin> g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
==>[peter,josh,marko,lop,ripple,vadas]seedStrategy = SeedStrategy.build().seed(999998L).create()
g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)
g.withStrategies(seedStrategy).V().values('name').fold().order(local).by(shuffle)|
Important
|
SeedStrategy only makes specific steps behave in a deterministic fashion and does not necessarily make
the entire traversal deterministic itself. If the underlying graph database or processing engine happens to not
guarantee iteration order, then it is possible that the final result of the traversal will appear to be
non-deterministic. In these cases, it would be necessary to enforce a deterministic iteration with order() prior to
these steps that make use of randomness to return results.
|
SubgraphStrategy
SubgraphStrategy is similar to PartitionStrategy in that it constrains a Traversal to certain vertices, edges,
and vertex properties as determined by a Traversal-based criterion defined individually for each.
gremlin> graph = TinkerFactory.createTheCrew()
==>tinkergraph[vertices:6 edges:14]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:6 edges:14], standard]
gremlin> g.V().as('a').values('location').as('b'). //// (1)
select('a','b').by('name').by()
==>[a:marko,b:san diego]
==>[a:marko,b:santa cruz]
==>[a:marko,b:brussels]
==>[a:marko,b:santa fe]
==>[a:stephen,b:centreville]
==>[a:stephen,b:dulles]
==>[a:stephen,b:purcellville]
==>[a:matthias,b:bremen]
==>[a:matthias,b:baltimore]
==>[a:matthias,b:oakland]
==>[a:matthias,b:seattle]
==>[a:daniel,b:spremberg]
==>[a:daniel,b:kaiserslautern]
==>[a:daniel,b:aachen]
gremlin> g = g.withStrategies(new SubgraphStrategy(vertexProperties: hasNot('endTime'))) //// (2)
==>graphtraversalsource[tinkergraph[vertices:6 edges:14], standard]
gremlin> g.V().as('a').values('location').as('b'). //// (3)
select('a','b').by('name').by()
==>[a:marko,b:santa fe]
==>[a:stephen,b:purcellville]
==>[a:matthias,b:seattle]
==>[a:daniel,b:aachen]
gremlin> g.V().as('a').values('location').as('b').
select('a','b').by('name').by().explain()
==>Traversal Explanation
================================================================================================================================================================================================================================================
Original Traversal [GraphStep(vertex,[])@[a], PropertiesStep([location],value)@[b], SelectStep(last,[a, b],[value(name), identity])]
SubgraphStrategy [D] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
ConnectiveStrategy [D] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
IdentityRemovalStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
ByModulatorOptimizationStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
EarlyLimitStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
MatchPredicateStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
FilterRankingStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), TraversalFilterStep([NotStep([PropertiesStep([endTime],value)])]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
InlineFilterStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],value)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
IncidentToAdjacentStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],value)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
AdjacentToIncidentStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
RepeatUnrollStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
CountStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
PathRetractionStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
LazyBarrierStrategy [O] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
TinkerGraphCountStrategy [P] [GraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
TinkerGraphStepStrategy [P] [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
ProfileStrategy [F] [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
StandardVerificationStrategy [V] [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]
Final Traversal [TinkerGraphStep(vertex,[])@[a], PropertiesStep([location],property), NotStep([PropertiesStep([endTime],property)]), PropertyValueStep@[b], SelectStep(last,[a, b],[value(name), identity])]graph = TinkerFactory.createTheCrew()
g = traversal().with(graph)
g.V().as('a').values('location').as('b'). //// (1)
select('a','b').by('name').by()
g = g.withStrategies(new SubgraphStrategy(vertexProperties: hasNot('endTime'))) //// (2)
g.V().as('a').values('location').as('b'). //// (3)
select('a','b').by('name').by()
g.V().as('a').values('location').as('b').
select('a','b').by('name').by().explain()-
Get all vertices and their vertex property locations.
-
Create a
SubgraphStrategywhere vertex properties must not have anendTime-property (thus, the current location). -
Get all vertices and their current vertex property locations.
The following examples demonstrate the above SubgraphStrategy definition in other programming languages:
g.withStrategies(SubgraphStrategy.build().vertexProperties(hasNot("endTime")).create());g.WithStrategies(new SubgraphStrategy(vertexProperties: HasNot("endTime")));g.withStrategies(new SubgraphStrategy(vertexProperties: hasNot("endTime")));g.withStrategies(new SubgraphStrategy(vertexProperties=hasNot("endTime")))|
Important
|
This strategy is implemented such that the vertices attached to an Edge must both satisfy the vertex
criterion (if present) in order for the Edge to be considered a part of the subgraph.
|
The example below uses all three filters: vertex, edge, and vertex property. People vertices must have lived in more than three places, edges must be labeled "develops," and vertex properties must be the persons current location or a non-location property.
gremlin> graph = TinkerFactory.createTheCrew()
==>tinkergraph[vertices:6 edges:14]
gremlin> g = traversal().with(graph).withStrategies(SubgraphStrategy.build().
vertices(or(hasNot('location'),properties('location').count().is(gt(3)))).
edges(hasLabel('develops')).
vertexProperties(or(hasLabel(neq('location')),hasNot('endTime'))).create())
==>graphtraversalsource[tinkergraph[vertices:6 edges:14], standard]
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,location:santa fe]
==>[id:8,label:person,name:matthias,location:seattle]
==>[id:10,label:software,name:gremlin]
==>[id:11,label:software,name:tinkergraph]
gremlin> g.E().elementMap()
==>[id:13,label:develops,IN:[id:10,label:software],OUT:[id:1,label:person],since:2009]
==>[id:14,label:develops,IN:[id:11,label:software],OUT:[id:1,label:person],since:2010]
==>[id:21,label:develops,IN:[id:10,label:software],OUT:[id:8,label:person],since:2012]
gremlin> g.V().outE().inV().
path().
by('name').
by().
by('name')
==>[marko,e[13][1-develops->10],gremlin]
==>[marko,e[14][1-develops->11],tinkergraph]
==>[matthias,e[21][8-develops->10],gremlin]graph = TinkerFactory.createTheCrew()
g = traversal().with(graph).withStrategies(SubgraphStrategy.build().
vertices(or(hasNot('location'),properties('location').count().is(gt(3)))).
edges(hasLabel('develops')).
vertexProperties(or(hasLabel(neq('location')),hasNot('endTime'))).create())
g.V().elementMap()
g.E().elementMap()
g.V().outE().inV().
path().
by('name').
by().
by('name')VertexProgramDenyStrategy
Like the ReadOnlyStrategy, the VertexProgramDenyStrategy denies the execution of specific traversals. A Traversal
that has the VertexProgramDenyStrategy applied will throw an IllegalStateException if it uses the
withComputer() step. This TraversalStrategy can be useful for configuring GraphTraversalSource instances in
Gremlin Server with the ScriptFileGremlinPlugin.
gremlin> oltpOnly = g.withStrategies(VertexProgramDenyStrategy.instance())
==>graphtraversalsource[tinkergraph[vertices:5 edges:7], standard]
gremlin> oltpOnly.withComputer().V().elementMap()
The TraversalSource does not allow the use of a GraphComputer
Type ':help' or ':h' for help.
Display stack trace? [yN]Domain Specific Languages
Gremlin is a domain specific language (DSL) for traversing graphs. It operates in the language of vertices, edges and properties. Typically, applications built with Gremlin are not of the graph domain, but instead model their domain within a graph. For example, the "modern" toy graph models software and person domain objects with the relationships between them (i.e. a person "knows" another person and a person "created" software).
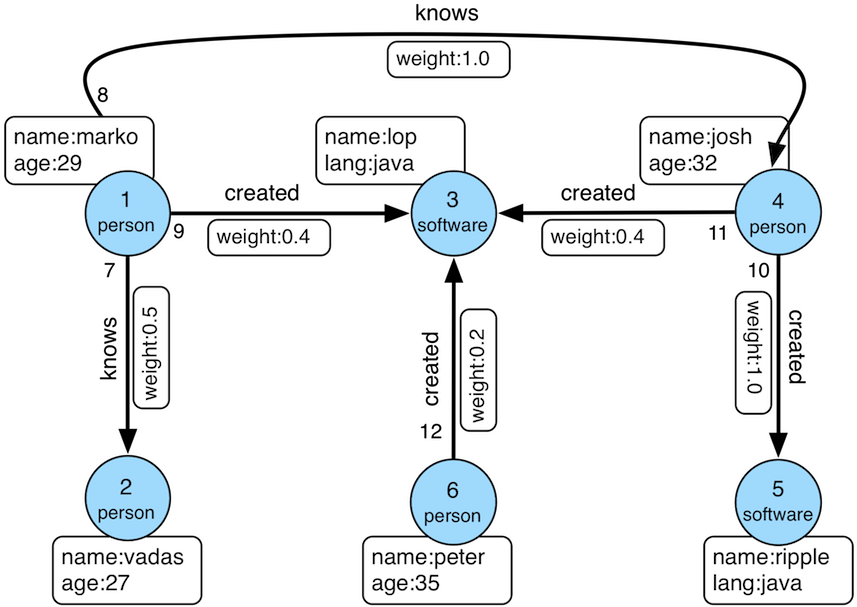{kind=link}
An analyst who wanted to find out if "marko" knows "josh" could write the following Gremlin:
g.V().hasLabel('person').has('name','marko').
out('knows').hasLabel('person').has('name','josh').hasNext()While this method achieves the desired answer, it requires the analyst to traverse the graph in the domain language of the graph rather than the domain language of the social network. A more natural way for the analyst to write this traversal might be:
g.persons('marko').knows('josh').hasNext()In the statement above, the traversal is written in the language of the domain, abstracting away the underlying graph structure from the query. The two traversal results are equivalent and, indeed, the "Social DSL" produces the same set of traversal steps as the "Graph DSL" thus producing equivalent strategy application and performance runtimes.
To further the example of the Social DSL consider the following:
// Graph DSL - find the number of persons who created at least 2 projects
g.V().hasLabel('person').
where(outE("created").count().is(P.gte(2))).count()
// Social DSL - find the number of persons who created at least 2 projects
social.persons().where(createdAtLeast(2)).count()
// Graph DSL - determine the age of the youngest friend "marko" has
g.V().hasLabel('person').has('name','marko').
out("knows").hasLabel("person").values("age").min()
// Social DSL - determine the age of the youngest friend "marko" has
social.persons("marko").youngestFriendsAge()Learn more about how to implement these DSLs in the Gremlin Language Variants section specific to the programming language of interest.
Translators

There are times when is helpful to translate Gremlin from one programming language to another. Perhaps a large Gremlin
example is found on StackOverflow written in Java, but the programming language the developer has chosen is Python.
Fortunately, TinkerPop has developed Translator infrastructure that will convert Gremlin from one programming
language syntax to another.
The GremlinTranslator class is capable of translating gremlin-lang syntax scripts into any of the following
gremlin language syntaxes: Java, Python, .Net, Go, JavaScript, Groovy. There is additionally a special anonymizing
translator which strips out arguments which could potentially contain sensitive information.
import org.apache.tinkerpop.gremlin.language.translator.GremlinTranslator;
import org.apache.tinkerpop.gremlin.language.translator.Translator;
// Java
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.JAVA).getTranslated();
// Returns: "g.V().hasLabel(\"person\", \"software\", \"class\")"
// Python
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.PYTHON).getTranslated();
// Returns: "g.V().has_label('person', 'software', 'class')"
// .Net
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.DOTNET).getTranslated();
// Returns: "g.V().HasLabel(\"person\", \"software\", \"class\")"
// Go
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.GO).getTranslated();
// Returns: "g.V().HasLabel(\"person\", \"software\", \"class\")"
// JavaScript
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.JAVASCRIPT).getTranslated();
// Returns: "g.V().hasLabel(\"person\", \"software\", \"class\")"
// Groovy
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.GROOVY).getTranslated();
// Returns: "g.V().hasLabel('person', 'software', 'class')"
// Anonymized
GremlinTranslator.translate("g.V().hasLabel('person', 'software', 'class')", Translator.ANONYMIZED).getTranslated();
// Returns: "g.V().hasLabel(string0, string1, string2)"Each GLV is capable of producing a gremlin-lang script from a Traversal, which can be fed into GremlinTranslator to
convert into any of the supported syntaxes. Each GLV has a unique interface, but the pattern is quite similar from one
to the next:
GraphTraversal t = g.V().hasLabel("person");
String script = t.asAdmin().getGremlinLang().getGremlin();
// Returns: "g.V().hasLabel(\"person\")"t = g.V().has_label('person')
script = t.gremlin_lang.get_gremlin()
# Returns: "g.V().hasLabel('person')"The GraphComputer
 TinkerPop provides two primary means of interacting with a
graph: online transaction processing (OLTP) and
online analytical processing (OLAP). OLTP-based
graph systems allow the user to query the graph in real-time. However, typically, real-time performance is only
possible when a local traversal is enacted. A local traversal is one that starts at a particular vertex (or small set
of vertices) and touches a small set of connected vertices (by any arbitrary path of arbitrary length). In short, OLTP
queries interact with a limited set of data and respond on the order of milliseconds or seconds. On the other hand,
with OLAP graph processing, the entire graph is processed and thus, every vertex and edge is analyzed (some times
more than once for iterative, recursive algorithms). Due to the amount of data being processed, the results are
typically not returned in real-time and for massive graphs (i.e. graphs represented across a cluster of machines),
results can take on the order of minutes or hours.
TinkerPop provides two primary means of interacting with a
graph: online transaction processing (OLTP) and
online analytical processing (OLAP). OLTP-based
graph systems allow the user to query the graph in real-time. However, typically, real-time performance is only
possible when a local traversal is enacted. A local traversal is one that starts at a particular vertex (or small set
of vertices) and touches a small set of connected vertices (by any arbitrary path of arbitrary length). In short, OLTP
queries interact with a limited set of data and respond on the order of milliseconds or seconds. On the other hand,
with OLAP graph processing, the entire graph is processed and thus, every vertex and edge is analyzed (some times
more than once for iterative, recursive algorithms). Due to the amount of data being processed, the results are
typically not returned in real-time and for massive graphs (i.e. graphs represented across a cluster of machines),
results can take on the order of minutes or hours.
-
OLTP: real-time, limited data accessed, random data access, sequential processing, querying
-
OLAP: long running, entire data set accessed, sequential data access, parallel processing, batch processing

The image above demonstrates the difference between Gremlin OLTP and Gremlin OLAP. With Gremlin OLTP, the graph is
walked by moving from vertex-to-vertex via incident edges. With Gremlin OLAP, all vertices are provided a
VertexProgram. The programs send messages to one another with the topological structure of the graph acting as the
communication network (though random message passing possible). In many respects, the messages passed are like
the OLTP traversers moving from vertex-to-vertex. However, all messages are moving independent of one another, in
parallel. Once a vertex program is finished computing, TinkerPop’s OLAP engine supports any number
MapReduce jobs over the resultant graph.
|
Important
|
GraphComputer was designed from the start to be used within a multi-JVM, distributed environment — in other words, a multi-machine compute cluster. As such, all the computing objects must be able to be migrated
between JVMs. The pattern promoted is to store state information in a Configuration object to later be regenerated
by a loading process. It is important to realize that VertexProgram, MapReduce, and numerous particular instances
rely heavily on the state of the computing classes (not the structure, but the processes) to be stored in a
Configuration.
|
VertexProgram
 GraphComputer takes a
GraphComputer takes a VertexProgram. A VertexProgram can be thought of
as a piece of code that is executed at each vertex in logically parallel manner until some termination condition is
met (e.g. a number of iterations have occurred, no more data is changing in the graph, etc.). A submitted
VertexProgram is copied to all the workers in the graph. A worker is not an explicit concept in the API, but is
assumed of all GraphComputer implementations. At minimum each vertex is a worker (though this would be inefficient
due to the fact that each vertex would maintain a VertexProgram). In practice, the workers partition the vertex set
and are responsible for the execution of the VertexProgram over all the vertices within their sphere of influence.
The workers orchestrate the execution of the VertexProgram.execute() method on all their vertices in an
bulk synchronous parallel (BSP) fashion. The vertices
are able to communicate with one another via messages. There are two kinds of messages in Gremlin OLAP:
MessageScope.Local and MessageScope.Global. A local message is a message to an adjacent vertex. A global
message is a message to any arbitrary vertex in the graph. Once the VertexProgram has completed its execution,
any number of MapReduce jobs are evaluated. MapReduce jobs are provided by the user via GraphComputer.mapReduce()
or by the VertexProgram via VertexProgram.getMapReducers().

The example below demonstrates how to submit a VertexProgram to a graph’s GraphComputer. GraphComputer.submit()
yields a Future<ComputerResult>. The ComputerResult has the resultant computed graph which can be a full copy
of the original graph (see Hadoop-Gremlin) or a view over the original graph (see
TinkerGraph). The ComputerResult also provides access to computational side-effects called Memory
(which includes, for example, runtime, number of iterations, results of MapReduce jobs, and VertexProgram-specific
memory manipulations).
gremlin> result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()
==>result[tinkergraph[vertices:6 edges:0],memory[size:0]]
gremlin> result.memory().runtime
==>19
gremlin> g = traversal().with(result.graph())
==>graphtraversalsource[tinkergraph[vertices:6 edges:0], standard]
gremlin> g.V().elementMap()
==>[id:1,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865547,name:marko,age:29]
==>[id:2,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719114,name:vadas,age:27]
==>[id:3,label:software,gremlin.pageRankVertexProgram.pageRank:0.30472009079122514,name:lop,lang:java]
==>[id:4,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719114,name:josh,age:32]
==>[id:5,label:software,gremlin.pageRankVertexProgram.pageRank:0.17579889899708243,name:ripple,lang:java]
==>[id:6,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865547,name:peter,age:35]result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()
result.memory().runtime
g = traversal().with(result.graph())
g.V().elementMap()|
Note
|
This model of "vertex-centric graph computing" was made popular by Google’s Pregel graph engine. In the open source world, this model is found in OLAP graph computing systems such as Giraph, Hama. TinkerPop extends the popularized model with integrated post-processing MapReduce jobs over the vertex set. |
MapReduce
The BSP model proposed by Pregel stores the results of the computation in a distributed manner as properties on the
elements in the graph. In many situations, it is necessary to aggregate those resultant properties into a single
result set (i.e. a statistic). For instance, assume a VertexProgram that computes a nominal cluster for each vertex
(i.e. a graph clustering algorithm). At the end of the
computation, each vertex will have a property denoting the cluster it was assigned to. TinkerPop provides the
ability to answer global questions about the clusters. For instance, in order to answer the following questions,
MapReduce jobs are required:
-
How many vertices are in each cluster? (presented below)
-
How many unique clusters are there? (presented below)
-
What is the average age of each vertex in each cluster?
-
What is the degree distribution of the vertices in each cluster?
A compressed representation of the MapReduce API in TinkerPop is provided below. The key idea is that the
map-stage processes all vertices to emit key/value pairs. Those values are aggregated on their respective key
for the reduce-stage to do its processing to ultimately yield more key/value pairs.
public interface MapReduce<MK, MV, RK, RV, R> {
public void map(final Vertex vertex, final MapEmitter<MK, MV> emitter);
public void reduce(final MK key, final Iterator<MV> values, final ReduceEmitter<RK, RV> emitter);
// there are more methods
}|
Important
|
The vertex that is passed into the MapReduce.map() method does not contain edges. The vertex only
contains original and computed vertex properties. This reduces the amount of data required to be loaded and ensures
that MapReduce is used for post-processing computed results. All edge-based computing should be accomplished in the
VertexProgram.
|

The MapReduce extension to GraphComputer is made explicit when examining the
PeerPressureVertexProgram and corresponding ClusterPopulationMapReduce.
In the code below, the GraphComputer result returns the computed on Graph as well as the Memory of the
computation (ComputerResult). The memory maintain the results of any MapReduce jobs. The cluster population
MapReduce result states that there are 5 vertices in cluster 1 and 1 vertex in cluster 6. This can be verified
(in a serial manner) by looking at the PeerPressureVertexProgram.CLUSTER property of the resultant graph. Notice
that the property is "hidden" unless it is directly accessed via name.
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> result = graph.compute().program(PeerPressureVertexProgram.build().create()).mapReduce(ClusterPopulationMapReduce.build().create()).submit().get()
==>result[tinkergraph[vertices:6 edges:0],memory[size:1]]
gremlin> result.memory().get('clusterPopulation')
==>1=5
==>6=1
gremlin> g = traversal().with(result.graph())
==>graphtraversalsource[tinkergraph[vertices:6 edges:0], standard]
gremlin> g.V().values(PeerPressureVertexProgram.CLUSTER).groupCount().next()
==>1=5
==>6=1
gremlin> g.V().elementMap()
==>[id:1,label:person,gremlin.peerPressureVertexProgram.cluster:1,name:marko,age:29]
==>[id:2,label:person,gremlin.peerPressureVertexProgram.cluster:1,name:vadas,age:27]
==>[id:3,label:software,gremlin.peerPressureVertexProgram.cluster:1,name:lop,lang:java]
==>[id:4,label:person,gremlin.peerPressureVertexProgram.cluster:1,name:josh,age:32]
==>[id:5,label:software,gremlin.peerPressureVertexProgram.cluster:1,name:ripple,lang:java]
==>[id:6,label:person,gremlin.peerPressureVertexProgram.cluster:6,name:peter,age:35]graph = TinkerFactory.createModern()
result = graph.compute().program(PeerPressureVertexProgram.build().create()).mapReduce(ClusterPopulationMapReduce.build().create()).submit().get()
result.memory().get('clusterPopulation')
g = traversal().with(result.graph())
g.V().values(PeerPressureVertexProgram.CLUSTER).groupCount().next()
g.V().elementMap()If there are numerous statistics desired, then its possible to register as many MapReduce jobs as needed. For
instance, the ClusterCountMapReduce determines how many unique clusters were created by the peer pressure algorithm.
Below both ClusterCountMapReduce and ClusterPopulationMapReduce are computed over the resultant graph.
gremlin> result = graph.compute().program(PeerPressureVertexProgram.build().create()).
mapReduce(ClusterPopulationMapReduce.build().create()).
mapReduce(ClusterCountMapReduce.build().create()).submit().get()
==>result[tinkergraph[vertices:6 edges:0],memory[size:2]]
gremlin> result.memory().clusterPopulation
==>1=5
==>6=1
gremlin> result.memory().clusterCount
==>2result = graph.compute().program(PeerPressureVertexProgram.build().create()).
mapReduce(ClusterPopulationMapReduce.build().create()).
mapReduce(ClusterCountMapReduce.build().create()).submit().get()
result.memory().clusterPopulation
result.memory().clusterCount|
Important
|
The MapReduce model of TinkerPop does not support MapReduce chaining. Thus, the order in which the
MapReduce jobs are executed is irrelevant. This is made apparent when realizing that the map()-stage takes a
Vertex as its input and the reduce()-stage yields key/value pairs. Thus, the results of reduce can not fed back
into a map().
|
A Collection of VertexPrograms
TinkerPop provides a collection of VertexPrograms that implement common algorithms. This section discusses the various implementations.
|
Important
|
The vertex programs presented are what are provided as of TinkerPop 4.0.0-SNAPSHOT. Over time, with future releases, more algorithms will be added. |
PageRankVertexProgram
 PageRank is perhaps the
most popular OLAP-oriented graph algorithm. This eigenvector centrality
variant was developed by Brin and Page of Google. PageRank defines a centrality value for all vertices in the graph,
where centrality is defined recursively where a vertex is central if it is connected to central vertices. PageRank is
an iterative algorithm that converges to a steady state distribution. If
the pageRank values are normalized to 1.0, then the pageRank value of a vertex is the probability that a random walker
will be seen that that vertex in the graph at any arbitrary moment in time. In order to help developers understand the
methods of a
PageRank is perhaps the
most popular OLAP-oriented graph algorithm. This eigenvector centrality
variant was developed by Brin and Page of Google. PageRank defines a centrality value for all vertices in the graph,
where centrality is defined recursively where a vertex is central if it is connected to central vertices. PageRank is
an iterative algorithm that converges to a steady state distribution. If
the pageRank values are normalized to 1.0, then the pageRank value of a vertex is the probability that a random walker
will be seen that that vertex in the graph at any arbitrary moment in time. In order to help developers understand the
methods of a VertexProgram, the PageRankVertexProgram code is analyzed below.
public class PageRankVertexProgram implements VertexProgram<Double> { //1
public static final String PAGE_RANK = "gremlin.pageRankVertexProgram.pageRank";
private static final String EDGE_COUNT = "gremlin.pageRankVertexProgram.edgeCount";
private static final String PROPERTY = "gremlin.pageRankVertexProgram.property";
private static final String VERTEX_COUNT = "gremlin.pageRankVertexProgram.vertexCount";
private static final String ALPHA = "gremlin.pageRankVertexProgram.alpha";
private static final String EPSILON = "gremlin.pageRankVertexProgram.epsilon";
private static final String MAX_ITERATIONS = "gremlin.pageRankVertexProgram.maxIterations";
private static final String EDGE_TRAVERSAL = "gremlin.pageRankVertexProgram.edgeTraversal";
private static final String INITIAL_RANK_TRAVERSAL = "gremlin.pageRankVertexProgram.initialRankTraversal";
private static final String TELEPORTATION_ENERGY = "gremlin.pageRankVertexProgram.teleportationEnergy";
private static final String CONVERGENCE_ERROR = "gremlin.pageRankVertexProgram.convergenceError";
private MessageScope.Local<Double> incidentMessageScope = MessageScope.Local.of(__::outE); //2
private MessageScope.Local<Double> countMessageScope = MessageScope.Local.of(new MessageScope.Local.ReverseTraversalSupplier(this.incidentMessageScope));
private PureTraversal<Vertex, Edge> edgeTraversal = null;
private PureTraversal<Vertex, ? extends Number> initialRankTraversal = null;
private double alpha = 0.85d;
private double epsilon = 0.00001d;
private int maxIterations = 20;
private String property = PAGE_RANK; //3
private Set<VertexComputeKey> vertexComputeKeys;
private Set<MemoryComputeKey> memoryComputeKeys;
private PageRankVertexProgram() {
}
@Override
public void loadState(final Graph graph, final Configuration configuration) { //4
if (configuration.containsKey(INITIAL_RANK_TRAVERSAL))
this.initialRankTraversal = PureTraversal.loadState(configuration, INITIAL_RANK_TRAVERSAL, graph);
if (configuration.containsKey(EDGE_TRAVERSAL)) {
this.edgeTraversal = PureTraversal.loadState(configuration, EDGE_TRAVERSAL, graph);
this.incidentMessageScope = MessageScope.Local.of(() -> this.edgeTraversal.get().clone());
this.countMessageScope = MessageScope.Local.of(new MessageScope.Local.ReverseTraversalSupplier(this.incidentMessageScope));
}
this.alpha = configuration.getDouble(ALPHA, this.alpha);
this.epsilon = configuration.getDouble(EPSILON, this.epsilon);
this.maxIterations = configuration.getInt(MAX_ITERATIONS, 20);
this.property = configuration.getString(PROPERTY, PAGE_RANK);
this.vertexComputeKeys = new HashSet<>(Arrays.asList(
VertexComputeKey.of(this.property, false),
VertexComputeKey.of(EDGE_COUNT, true))); //5
this.memoryComputeKeys = new HashSet<>(Arrays.asList(
MemoryComputeKey.of(TELEPORTATION_ENERGY, Operator.sum, true, true),
MemoryComputeKey.of(VERTEX_COUNT, Operator.sum, true, true),
MemoryComputeKey.of(CONVERGENCE_ERROR, Operator.sum, false, true)));
}
@Override
public void storeState(final Configuration configuration) {
VertexProgram.super.storeState(configuration);
configuration.setProperty(ALPHA, this.alpha);
configuration.setProperty(EPSILON, this.epsilon);
configuration.setProperty(PROPERTY, this.property);
configuration.setProperty(MAX_ITERATIONS, this.maxIterations);
if (null != this.edgeTraversal)
this.edgeTraversal.storeState(configuration, EDGE_TRAVERSAL);
if (null != this.initialRankTraversal)
this.initialRankTraversal.storeState(configuration, INITIAL_RANK_TRAVERSAL);
}
@Override
public GraphComputer.ResultGraph getPreferredResultGraph() {
return GraphComputer.ResultGraph.NEW;
}
@Override
public GraphComputer.Persist getPreferredPersist() {
return GraphComputer.Persist.VERTEX_PROPERTIES;
}
@Override
public Set<VertexComputeKey> getVertexComputeKeys() { //6
return this.vertexComputeKeys;
}
@Override
public Optional<MessageCombiner<Double>> getMessageCombiner() {
return (Optional) PageRankMessageCombiner.instance();
}
@Override
public Set<MemoryComputeKey> getMemoryComputeKeys() {
return this.memoryComputeKeys;
}
@Override
public Set<MessageScope> getMessageScopes(final Memory memory) {
final Set<MessageScope> set = new HashSet<>();
set.add(memory.isInitialIteration() ? this.countMessageScope : this.incidentMessageScope);
return set;
}
@Override
public PageRankVertexProgram clone() {
try {
final PageRankVertexProgram clone = (PageRankVertexProgram) super.clone();
if (null != this.initialRankTraversal)
clone.initialRankTraversal = this.initialRankTraversal.clone();
return clone;
} catch (final CloneNotSupportedException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
@Override
public void setup(final Memory memory) {
memory.set(TELEPORTATION_ENERGY, null == this.initialRankTraversal ? 1.0d : 0.0d);
memory.set(VERTEX_COUNT, 0.0d);
memory.set(CONVERGENCE_ERROR, 1.0d);
}
@Override
public void execute(final Vertex vertex, Messenger<Double> messenger, final Memory memory) { //7
if (memory.isInitialIteration()) {
messenger.sendMessage(this.countMessageScope, 1.0d); //8
memory.add(VERTEX_COUNT, 1.0d);
} else {
final double vertexCount = memory.<Double>get(VERTEX_COUNT);
final double edgeCount;
double pageRank;
if (1 == memory.getIteration()) {
edgeCount = IteratorUtils.reduce(messenger.receiveMessages(), 0.0d, (a, b) -> a + b);
vertex.property(VertexProperty.Cardinality.single, EDGE_COUNT, edgeCount);
pageRank = null == this.initialRankTraversal ?
0.0d :
TraversalUtil.apply(vertex, this.initialRankTraversal.get()).doubleValue(); //9
} else {
edgeCount = vertex.value(EDGE_COUNT);
pageRank = IteratorUtils.reduce(messenger.receiveMessages(), 0.0d, (a, b) -> a + b); //10
}
//////////////////////////
final double teleporationEnergy = memory.get(TELEPORTATION_ENERGY);
if (teleporationEnergy > 0.0d) {
final double localTerminalEnergy = teleporationEnergy / vertexCount;
pageRank = pageRank + localTerminalEnergy;
memory.add(TELEPORTATION_ENERGY, -localTerminalEnergy);
}
final double previousPageRank = vertex.<Double>property(this.property).orElse(0.0d);
memory.add(CONVERGENCE_ERROR, Math.abs(pageRank - previousPageRank));
vertex.property(VertexProperty.Cardinality.single, this.property, pageRank);
memory.add(TELEPORTATION_ENERGY, (1.0d - this.alpha) * pageRank);
pageRank = this.alpha * pageRank;
if (edgeCount > 0.0d)
messenger.sendMessage(this.incidentMessageScope, pageRank / edgeCount);
else
memory.add(TELEPORTATION_ENERGY, pageRank);
}
}
@Override
public boolean terminate(final Memory memory) { //11
boolean terminate = memory.<Double>get(CONVERGENCE_ERROR) < this.epsilon || memory.getIteration() >= this.maxIterations;
memory.set(CONVERGENCE_ERROR, 0.0d);
return terminate;
}
@Override
public String toString() {
return StringFactory.vertexProgramString(this, "alpha=" + this.alpha + ", epsilon=" + this.epsilon + ", iterations=" + this.maxIterations);
}
}-
PageRankVertexProgramimplementsVertexProgram<Double>because the messages it sends are Java doubles. -
The default path of energy propagation is via outgoing edges from the current vertex.
-
The resulting PageRank values for the vertices are stored as a vertex property.
-
A vertex program is constructed using an Apache
Configurationto ensure easy dissemination across a cluster of JVMs. -
EDGE_COUNTis a transient "scratch data" compute key whilePAGE_RANKis not. -
A vertex program must define the "compute keys" that are the properties being operated on during the computation.
-
The "while"-loop of the vertex program.
-
In order to determine how to distribute the energy to neighbors, a "1"-count is used to determine how many incident vertices exist for the
MessageScope. -
Initially, each vertex is provided an equal amount of energy represented as a double.
-
Energy is aggregated, computed on according to the PageRank algorithm, and then disseminated according to the defined
MessageScope.Local. -
The computation is terminated after epsilon-convergence is met or a pre-defined number of iterations have taken place.
The above PageRankVertexProgram is used as follows.
gremlin> result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()
==>result[tinkergraph[vertices:6 edges:0],memory[size:0]]
gremlin> result.memory().runtime
==>6
gremlin> g = traversal().with(result.graph())
==>graphtraversalsource[tinkergraph[vertices:6 edges:0], standard]
gremlin> g.V().elementMap()
==>[id:1,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865541,name:marko,age:29]
==>[id:2,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719106,name:vadas,age:27]
==>[id:3,label:software,gremlin.pageRankVertexProgram.pageRank:0.3047200907912249,name:lop,lang:java]
==>[id:4,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719106,name:josh,age:32]
==>[id:5,label:software,gremlin.pageRankVertexProgram.pageRank:0.17579889899708231,name:ripple,lang:java]
==>[id:6,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865541,name:peter,age:35]result = graph.compute().program(PageRankVertexProgram.build().create()).submit().get()
result.memory().runtime
g = traversal().with(result.graph())
g.V().elementMap()Note that GraphTraversal provides a pageRank()-step.
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().pageRank().elementMap()
==>[id:5,label:software,gremlin.pageRankVertexProgram.pageRank:0.17579889899708231,name:ripple,lang:java]
==>[id:6,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865541,name:peter,age:35]
==>[id:3,label:software,gremlin.pageRankVertexProgram.pageRank:0.3047200907912249,name:lop,lang:java]
==>[id:1,label:person,gremlin.pageRankVertexProgram.pageRank:0.11375510357865541,name:marko,age:29]
==>[id:2,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719106,name:vadas,age:27]
==>[id:4,label:person,gremlin.pageRankVertexProgram.pageRank:0.14598540152719106,name:josh,age:32]
gremlin> g.V().pageRank().
with(PageRank.propertyName, 'pageRank').
with(PageRank.times, 5).
order().
by('pageRank').
elementMap()
==>[id:6,label:person,pageRank:0.1136216612614133,name:peter,age:35]
==>[id:2,label:person,pageRank:0.14598422136890216,name:vadas,age:27]
==>[id:5,label:software,pageRank:0.1756689971547068,name:ripple,lang:java]
==>[id:3,label:software,pageRank:0.3051192375846622,name:lop,lang:java]
==>[id:4,label:person,pageRank:0.14598422136890216,name:josh,age:32]
==>[id:1,label:person,pageRank:0.1136216612614133,name:marko,age:29]g = traversal().with(graph).withComputer()
g.V().pageRank().elementMap()
g.V().pageRank().
with(PageRank.propertyName, 'pageRank').
with(PageRank.times, 5).
order().
by('pageRank').
elementMap()PeerPressureVertexProgram
The PeerPressureVertexProgram is a clustering algorithm that assigns a nominal value to each vertex in the graph.
The nominal value represents the vertex’s cluster. If two vertices have the same nominal value, then they are in the
same cluster. The algorithm proceeds in the following manner.
-
Every vertex assigns itself to a unique cluster ID (initially, its vertex ID).
-
Every vertex determines its per neighbor vote strength as 1.0d / incident edges count.
-
Every vertex sends its cluster ID and vote strength to its adjacent vertices as a
Pair<Serializable,Double> -
Every vertex generates a vote energy distribution of received cluster IDs and changes its current cluster ID to the most frequent cluster ID.
-
If there is a tie, then the cluster with the lowest
toString()comparison is selected.
-
-
Steps 3 and 4 repeat until either a max number of iterations has occurred or no vertex has adjusted its cluster anymore.
Note that GraphTraversal provides a peerPressure()-step.
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().peerPressure().with(PeerPressure.propertyName, 'cluster').elementMap()
==>[id:1,label:person,cluster:1,name:marko,age:29]
==>[id:3,label:software,cluster:1,name:lop,lang:java]
==>[id:5,label:software,cluster:1,name:ripple,lang:java]
==>[id:4,label:person,cluster:1,name:josh,age:32]
==>[id:2,label:person,cluster:1,name:vadas,age:27]
==>[id:6,label:person,cluster:6,name:peter,age:35]
gremlin> g.V().peerPressure().
with(PeerPressure.edges,outE('knows')).
with(PeerPressure.propertyName, 'cluster').
elementMap()
==>[id:2,label:person,cluster:1,name:vadas,age:27]
==>[id:1,label:person,cluster:1,name:marko,age:29]
==>[id:3,label:software,cluster:3,name:lop,lang:java]
==>[id:4,label:person,cluster:1,name:josh,age:32]
==>[id:5,label:software,cluster:5,name:ripple,lang:java]
==>[id:6,label:person,cluster:6,name:peter,age:35]g = traversal().with(graph).withComputer()
g.V().peerPressure().with(PeerPressure.propertyName, 'cluster').elementMap()
g.V().peerPressure().
with(PeerPressure.edges,outE('knows')).
with(PeerPressure.propertyName, 'cluster').
elementMap()ConnectedComponentVertexProgram
The ConnectedComponentVertexProgram identifies Connected Component
instances in a graph. See connectedComponent()-step for more information.
ShortestPathVertexProgram
The ShortestPathVertexProram provides an easy way to find shortest non-cyclic paths in the graph. It provides several options to configure
the output format, the start- and end-vertices, the direction, a custom distance function, as well as a distance limitation. By default it just
finds all undirected, shortest paths in the graph.
gremlin> spvp = ShortestPathVertexProgram.build().create() //// (1)
==>ShortestPathVertexProgram[includeEdges=false]
gremlin> result = graph.compute().program(spvp).submit().get() //// (2)
==>result[tinkergraph[vertices:6 edges:6],memory[size:1]]
gremlin> result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS) //// (3)
==>[v[1],v[2]]
==>[v[2]]
==>[v[3],v[1],v[2]]
==>[v[4],v[1],v[2]]
==>[v[5],v[4],v[1],v[2]]
==>[v[6],v[3],v[1],v[2]]
==>[v[1],v[4]]
==>[v[2],v[1],v[4]]
==>[v[3],v[4]]
==>[v[4]]
==>[v[5],v[4]]
==>[v[6],v[3],v[4]]
==>[v[1]]
==>[v[2],v[1]]
==>[v[3],v[1]]
==>[v[4],v[1]]
==>[v[5],v[4],v[1]]
==>[v[6],v[3],v[1]]
==>[v[1],v[3]]
==>[v[2],v[1],v[3]]
==>[v[3]]
==>[v[4],v[3]]
==>[v[5],v[4],v[3]]
==>[v[6],v[3]]
==>[v[1],v[3],v[6]]
==>[v[2],v[1],v[3],v[6]]
==>[v[3],v[6]]
==>[v[4],v[3],v[6]]
==>[v[5],v[4],v[3],v[6]]
==>[v[6]]
==>[v[1],v[4],v[5]]
==>[v[2],v[1],v[4],v[5]]
==>[v[3],v[4],v[5]]
==>[v[4],v[5]]
==>[v[5]]
==>[v[6],v[3],v[4],v[5]]spvp = ShortestPathVertexProgram.build().create() //// (1)
result = graph.compute().program(spvp).submit().get() //// (2)
result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS) //3-
Create a
ShortestPathVertexProgramwith its default configuration. -
Execute the
ShortestPathVertexProgram. -
Get all shortest paths from the results memory.
gremlin> spvp = ShortestPathVertexProgram.build().includeEdges(true).create() //// (1)
==>ShortestPathVertexProgram[includeEdges=true]
gremlin> result = graph.compute().program(spvp).submit().get() //// (2)
==>result[tinkergraph[vertices:6 edges:6],memory[size:1]]
gremlin> result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS) //// (3)
==>[v[1],e[7][1-knows->2],v[2]]
==>[v[2]]
==>[v[3],e[9][1-created->3],v[1],e[7][1-knows->2],v[2]]
==>[v[4],e[8][1-knows->4],v[1],e[7][1-knows->2],v[2]]
==>[v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1],e[7][1-knows->2],v[2]]
==>[v[6],e[12][6-created->3],v[3],e[9][1-created->3],v[1],e[7][1-knows->2],v[2]]
==>[v[1]]
==>[v[2],e[7][1-knows->2],v[1]]
==>[v[3],e[9][1-created->3],v[1]]
==>[v[4],e[8][1-knows->4],v[1]]
==>[v[5],e[10][4-created->5],v[4],e[8][1-knows->4],v[1]]
==>[v[6],e[12][6-created->3],v[3],e[9][1-created->3],v[1]]
==>[v[1],e[8][1-knows->4],v[4]]
==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4]]
==>[v[3],e[11][4-created->3],v[4]]
==>[v[4]]
==>[v[5],e[10][4-created->5],v[4]]
==>[v[6],e[12][6-created->3],v[3],e[11][4-created->3],v[4]]
==>[v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]
==>[v[2],e[7][1-knows->2],v[1],e[8][1-knows->4],v[4],e[10][4-created->5],v[5]]
==>[v[3],e[11][4-created->3],v[4],e[10][4-created->5],v[5]]
==>[v[4],e[10][4-created->5],v[5]]
==>[v[5]]
==>[v[6],e[12][6-created->3],v[3],e[11][4-created->3],v[4],e[10][4-created->5],v[5]]
==>[v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6]]
==>[v[2],e[7][1-knows->2],v[1],e[9][1-created->3],v[3],e[12][6-created->3],v[6]]
==>[v[3],e[12][6-created->3],v[6]]
==>[v[4],e[11][4-created->3],v[3],e[12][6-created->3],v[6]]
==>[v[5],e[10][4-created->5],v[4],e[11][4-created->3],v[3],e[12][6-created->3],v[6]]
==>[v[6]]
==>[v[1],e[9][1-created->3],v[3]]
==>[v[2],e[7][1-knows->2],v[1],e[9][1-created->3],v[3]]
==>[v[3]]
==>[v[4],e[11][4-created->3],v[3]]
==>[v[5],e[10][4-created->5],v[4],e[11][4-created->3],v[3]]
==>[v[6],e[12][6-created->3],v[3]]spvp = ShortestPathVertexProgram.build().includeEdges(true).create() //// (1)
result = graph.compute().program(spvp).submit().get() //// (2)
result.memory().get(ShortestPathVertexProgram.SHORTEST_PATHS) //3-
Create a
ShortestPathVertexProgramas before, but configure it to include edges in the result. -
Execute the
ShortestPathVertexProgram. -
Get all shortest paths from the results memory.
The ShortestPathVertexProgram.Builder provides the following configuration methods:
| Method | Description | Default |
|---|---|---|
|
Sets a filter traversal for the start vertices (e.g. |
all vertices ( |
|
Sets a filter traversal for the end vertices. |
all vertices |
|
Sets the direction to traverse during the shortest path discovery. |
|
|
Sets a traversal that emits the edges to traverse from the current vertex. |
|
|
Sets the edge property to use for the distance calculations. |
none |
|
Sets the traversal that calculates the distance for the current edge. |
|
|
Limits the shortest path distance. |
none |
|
Whether to include edges in shortest paths or not. |
|
|
Important
|
If a maximum distance is provided, the discovery process will only stop to follow a path at this distance if there was no custom distance property or traversal provided. Custom distances can be negative, hence exceeding the maximum distance doesn’t mean that there can’t be any more valid paths. However, paths will be filtered at the end, when no more non-cyclic paths can be found. The bottom line is that custom distance properties or traversals can lead to much longer runtimes and a much higher memory consumption. |
Note that GraphTraversal provides a shortestPath()-step.
CloneVertexProgram
The CloneVertexProgram (known in versions prior to 3.2.10 as BulkDumperVertexProgram) copies a whole graph from
any graph InputFormat to any graph OutputFormat. TinkerPop provides the following:
-
OutputFormat-
GraphSONOutputFormat -
GryoOutputFormat -
ScriptOutputFormat
-
-
InputFormat-
GraphSONInputFormat -
GryoInputFormat -
ScriptInputFormat).
-
An example is provided in the SparkGraphComputer section.
Graph Providers should consider writing their own OutputFormat and InputFormat which would allow bulk loading and
export capabilities through this VertexProgram. This topic is discussed further in the
Provider Documentation.
TraversalVertexProgram
 The
The TraversalVertexProgram is a "special" VertexProgram in
that it can be executed via a Traversal and a GraphComputer. In Gremlin, it is possible to have
the same traversal executed using either the standard OLTP-engine or the GraphComputer OLAP-engine. The difference
being where the traversal is submitted.
|
Note
|
This model of graph traversal in a BSP system was first implemented by the Faunus graph analytics engine and originally described in Local and Distributed Traversal Engines. |
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V().both().hasLabel('person').values('age').groupCount().next() // OLTP
==>32=3
==>35=1
==>27=1
==>29=3
gremlin> g = traversal().with(graph).withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().both().hasLabel('person').values('age').groupCount().next() // OLAP
==>32=3
==>35=1
==>27=1
==>29=3g = traversal().with(graph)
g.V().both().hasLabel('person').values('age').groupCount().next() // OLTP
g = traversal().with(graph).withComputer()
g.V().both().hasLabel('person').values('age').groupCount().next() // OLAP
In the OLAP example above, a TraversalVertexProgram is (logically) sent to each vertex in the graph. Each instance
evaluation requires (logically) 5 BSP iterations and each iteration is interpreted as such:
-
g.V(): Put a traverser on each vertex in the graph. -
both(): Propagate each traverser to the verticesboth-adjacent to its current vertex. -
hasLabel('person'): If the vertex is not a person, kill the traversers at that vertex. -
values('age'): Have all the traversers reference the integer age of their current vertex. -
groupCount(): Count how many times a particular age has been seen.
While 5 iterations were presented, in fact, TraversalVertexProgram will execute the traversal in only
2 iterations. The reason being is that g.V().both() and hasLabel('person').values('age').groupCount() can be
executed in a single iteration as any message sent would simply be to the current executing vertex. Thus, a simple optimization
exists in Gremlin OLAP called "reflexive message passing" which simulates non-message-passing BSP iterations within a
single BSP iteration.
The same OLAP traversal can be executed using the standard graph.compute() model, though at the expense of verbosity.
TraversalVertexProgram provides a fluent Builder for constructing a TraversalVertexProgram. The specified
traversal() can be either a direct Traversal object or a
JSR-223 script that will generate a
Traversal. There is no benefit to using the model below. It is demonstrated to help elucidate how Gremlin OLAP traversals
are ultimately compiled for execution on a GraphComputer.
gremlin> result = graph.compute().program(TraversalVertexProgram.build().traversal(g.V().both().hasLabel('person').values('age').groupCount('a')).create()).submit().get()
==>result[tinkergraph[vertices:6 edges:6],memory[size:2]]
gremlin> result.memory().a
==>32=3
==>35=1
==>27=1
==>29=3
gremlin> result.memory().iteration
==>1
gremlin> result.memory().runtime
==>6result = graph.compute().program(TraversalVertexProgram.build().traversal(g.V().both().hasLabel('person').values('age').groupCount('a')).create()).submit().get()
result.memory().a
result.memory().iteration
result.memory().runtimeDistributed Gremlin Gotchas
Gremlin OLTP is not identical to Gremlin OLAP.
|
Important
|
There are two primary theoretical differences between Gremlin OLTP and Gremlin OLAP. First, Gremlin OLTP
(via Traversal) leverages a depth-first execution engine.
Depth-first execution has a limited memory footprint due to lazy evaluation.
On the other hand, Gremlin OLAP (via TraversalVertexProgram) leverages a
breadth-first execution engine which maintains a larger memory
footprint, but a better time complexity due to vertex-local traversers being able to be "bulked." The second difference
is that Gremlin OLTP is executed in a serial/streaming fashion, while Gremlin OLAP is executed in a parallel/step-wise fashion. These two
fundamental differences lead to the behaviors enumerated below.
|

-
Traversal sideEffects are represented as a distributed data structure across
GraphComputerworkers. It is not possible to get a global view of a sideEffect until after an iteration has occurred and global sideEffects are re-broadcasted to the workers. In some situations, a "stale" local representation of the sideEffect is sufficient to ensure the intended semantics of the traversal are respected. However, this is not generally true so be wary of traversals that require global views of a sideEffect. To ensure a fresh global representation, usebarrier()prior to accessing the global sideEffect. Note that this only comes into play with custom steps and lambda steps. The standard Gremlin step library is respective of OLAP semantics. -
When evaluating traversals that rely on path information (i.e. the history of the traversal), practical computational limits can easily be reached due the combinatoric explosion of data. With path computing enabled, every traverser is unique and thus, must be enumerated as opposed to being counted/merged. The difference being a collection of paths vs. a single 64-bit long at a single vertex. In other words, bulking is very unlikely with traversers that maintain path information. For more information on this concept, please see Faunus Provides Big Graph Data.
-
Steps that are concerned with the global ordering of traversers do not have a meaningful representation in OLAP. For example, what does
order()-step mean when all traversers are being processed in parallel? Even if the traversers were aggregated and ordered, then at the next step they would return to being executed in parallel and thus, in an unpredictable order. Whenorder()-like steps are executed at the end of a traversal (i.e the final step),TraversalVertexProgramensures a serial representation is ordered accordingly. Moreover, it is intelligent enough to maintain the ordering ofg.V().hasLabel("person").order().by("age").values("name"). However, the OLAP traversalg.V().hasLabel("person").order().by("age").out().values("name")will lose the original ordering as theout()-step will rebroadcast traversers across the cluster.
Graph Filter
Most OLAP jobs do not require the entire source graph to faithfully execute their VertexProgram. For instance, if
PageRankVertexProgram is only going to compute the centrality of people in the friendship-graph, then the following
GraphFilter can be applied.
graph.computer().
vertices(hasLabel("person")).
vertexProperties(__.properties("name")).
edges(bothE("knows")).
program(PageRankVertexProgram...)There are three methods for constructing a GraphFilter.
-
vertices(Traversal<Vertex,Vertex>): A traversal that will be used that can only analyze a vertex and its properties. If the traversalhasNext(), the inputVertexis passed to theGraphComputer. -
vertexProperties(Traversal<Vertex, ? extends Property<?>): A traversal that will either let the vertex property pass or not. -
edges(Traversal<Vertex,Edge>): A traversal that will iterate all legal edges for the source vertex.
GraphFilter is a "push-down predicate" that providers can reason on to determine the most efficient way to provide
graph data to the GraphComputer.
|
Important
|
Apache TinkerPop provides GraphFilterStrategy traversal strategy which analyzes a submitted
OLAP traversal and, if possible, creates an appropriate GraphFilter automatically. For instance, g.V().count() would
yield a GraphFilter.edges(limit(0)). Thus, for traversal submissions, users typically do not need to be aware of creating
graph filters explicitly. Users can use the explain()-step to see the GraphFilter generated by GraphFilterStrategy.
|
Gremlin Applications
Gremlin applications represent tools that are built on top of the core APIs to help expose common functionality to users when working with graphs. There are two key applications:
-
Gremlin Console - A REPL environment for interactive development and analysis
-
Gremlin Server - A server that hosts a Gremlin Traversal Machine thus enabling remote Gremlin execution
 Gremlin is designed to be extensible, making it possible for users
and graph system/language providers to customize it to their needs. Such extensibility is also found in the Gremlin
Console and Server, where a universal plugin system makes it possible to extend their capabilities. One of the
important aspects of the plugin system is the ability to help the user install the plugins through the command line
thus automating the process of gathering dependencies and other error prone activities.
Gremlin is designed to be extensible, making it possible for users
and graph system/language providers to customize it to their needs. Such extensibility is also found in the Gremlin
Console and Server, where a universal plugin system makes it possible to extend their capabilities. One of the
important aspects of the plugin system is the ability to help the user install the plugins through the command line
thus automating the process of gathering dependencies and other error prone activities.
The process of plugin installation is handled by Grape, which helps resolve
dependencies into the classpath. It is therefore important to ensure that Grape is properly configured in order to
use the automated capabilities of plugin installation. Grape is configured by ~/.groovy/grapeConfig.xml and
generally speaking, if that file is not present, the default settings will suffice. However, they will not suffice
if a required dependency is not in one of the default configured repositories. Please see the
Customize Ivy settings section of the Grape documentation for more details on
the defaults. For current TinkerPop plugins and dependencies the following configuration which is also the default
for Ivy should be acceptable:
<ivysettings>
<settings defaultResolver="downloadGrapes"/>
<resolvers>
<chain name="downloadGrapes" returnFirst="true">
<filesystem name="cachedGrapes">
<ivy pattern="${user.home}/.groovy/grapes/[organisation]/[module]/ivy-[revision].xml"/>
<artifact pattern="${user.home}/.groovy/grapes/[organisation]/[module]/[type]s/[artifact]-[revision](-[classifier]).[ext]"/>
</filesystem>
<ibiblio name="localm2" root="${user.home.url}/.m2/repository/" checkmodified="true" changingPattern=".*" changingMatcher="regexp" m2compatible="true"/>
<ibiblio name="jcenter" root="https://jcenter.bintray.com/" m2compatible="true"/>
<ibiblio name="ibiblio" m2compatible="true"/>
</chain>
</resolvers>
</ivysettings>|
Tip
|
Please see the Developer Documentation for additional configuration options when working with "snapshot" releases. |
Gremlin Console
 The Gremlin Console is an interactive terminal or
REPL that can be used to traverse graphs
and interact with the data that they contain. It represents the most common method for performing ad hoc graph
analysis, small to medium sized data loading projects and other exploratory functions. The Gremlin Console is
highly extensible, featuring a rich plugin system that allows new tools, commands,
DSLs, etc. to be exposed to users.
The Gremlin Console is an interactive terminal or
REPL that can be used to traverse graphs
and interact with the data that they contain. It represents the most common method for performing ad hoc graph
analysis, small to medium sized data loading projects and other exploratory functions. The Gremlin Console is
highly extensible, featuring a rich plugin system that allows new tools, commands,
DSLs, etc. to be exposed to users.
To start the Gremlin Console, run gremlin.sh or gremlin.bat (gremlin-java8.bat for Java 8):
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin loaded: tinkerpop.server
plugin loaded: tinkerpop.utilities
plugin loaded: tinkerpop.tinkergraph
gremlin>|
Note
|
If the above plugins are not loaded then they will need to be enabled or else certain examples will not work.
If using the standard Gremlin Console distribution, then the plugins should be enabled by default. See below for
more information on the :plugin use command to manually enable plugins. These plugins, with the exception of
tinkerpop.tinkergraph, cannot be removed from the Console as they are a part of the gremlin-console.jar itself.
These plugins can only be deactivated.
|
The Gremlin Console is loaded and ready for commands. Recall that the console hosts the Gremlin-Groovy language. Please review Groovy for help on Groovy-related constructs. In short, Groovy is a superset of Java. What works in Java, works in Groovy. However, Groovy provides many shorthands to make it easier to interact with the Java API. Moreover, Gremlin provides many neat shorthands to make it easier to express paths through a property graph.
gremlin> i = 'goodbye'
==>goodbye
gremlin> j = 'self'
==>self
gremlin> i + " " + j
==>goodbye self
gremlin> "${i} ${j}"
==>goodbye selfi = 'goodbye'
j = 'self'
i + " " + j
"${i} ${j}"The "toy" graph provides a way to get started with Gremlin quickly.
gremlin> g = traversal().with(TinkerFactory.createModern())
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.V()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V().values('name')
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().has('name','marko').out('knows').values('name')
==>vadas
==>joshg = traversal().with(TinkerFactory.createModern())
g.V()
g.V().values('name')
g.V().has('name','marko').out('knows').values('name')|
Tip
|
When using Gremlin-Groovy in a Groovy class file, add static { GremlinLoader.load() } to the head of the file.
|
Console Commands
In addition to the standard commands of the Groovy Shell, Gremlin adds some other useful operations. The following table outlines the most commonly used commands:
| Command | Alias | Description |
|---|---|---|
:help |
:? |
Displays list of commands and descriptions. When followed by a command name, it will display more specific help on that particular item. |
:exit |
:x |
Ends the Console session. |
import |
:i |
Import a class into the Console session. |
:cls |
:C |
Clear the screen of the Console. |
:clear |
:c |
Sometimes the Console can get into a state where the command buffer no longer understands input (e.g. a misplaced |
:load |
:l |
Load a file or URL into the command buffer for execution. |
:install |
:+ |
Imports a Maven library and its dependencies into the Console. |
:uninstall |
:- |
Removes a Maven library and its dependencies. A restart of the console is required for removal to fully take effect. |
:plugin |
:pin |
Plugin management functions to list, activate and deactivate available plugins. |
|
Note
|
The Console also exposes the :record command which is inherited from the Groovy Shell.
|
Interrupting Evaluations
If there is some input that is taking too long to evaluate or to iterate through, use ctrl+c to attempt to interrupt
that process. It is an "attempt" in the sense that the long running process is only informed of the interruption by
the user and must respond to it (as with any call to interrupt() on a Thread). A Traversal will typically respond
to such requests as do most commands.
gremlin> java.util.stream.IntStream.range(0, 1000).iterator()
==>0
==>1
==>2
==>3
==>4
...
==>348
==>349
==>350
==>351
==>352
Execution interrupted by ctrl+c
gremlin>Console Preferences
Preferences are set with :set name value. Values can contain spaces when quoted. All preferences are reset by :purge preferences
| Preference | Type | Description |
|---|---|---|
max-iteration |
int |
Controls the maximum number of results that the Console will display. Default: 100 results. |
colors |
bool |
Enable ANSI color rendering. Default: true |
warnings |
bool |
Enable display of remote execution warnings. Default: true |
gremlin.color |
colors |
Color of the ASCII art gremlin on startup. |
info.color |
colors |
Color of "info" type messages. |
error.color |
colors |
Color of "error" type messages. |
vertex.color |
colors |
Color of vertices results. |
edge.color |
colors |
Color of edges in results. |
string.color |
colors |
Colors of strings in results. |
number.color |
colors |
Color of numbers in results. |
T.color |
colors |
Color of Tokens in results. |
input.prompt.color |
colors |
Color of the input prompt. |
result.prompt.color |
colors |
Color of the result prompt. |
input.prompt |
string |
Text of the input prompt. |
result.prompt |
string |
Text of the result prompt. |
result.indicator.null |
string |
Text of the void/no results indicator - setting to empty string (i.e. "" at the command line) will print no result line in these cases. |
Colors can contain a comma-separated combination of 1 each of foreground, background, and attribute.
| Foreground | Background | Attributes |
|---|---|---|
black |
bg_black |
bold |
blue |
bg_blue |
faint |
cyan |
bg_cyan |
underline |
green |
bg_green |
|
magenta |
bg_magenta |
|
red |
bg_red |
|
white |
bg_white |
|
yellow |
bg_yellow |
Example:
:set gremlin.color bg_black,green,boldDependencies and Plugin Usage
The Gremlin Console can dynamically load external code libraries and make them available to the user. Furthermore,
those dependencies may contain Gremlin plugins which can expand the language, provide useful functions, etc. These
important console features are managed by the :install and :plugin commands.
The following Gremlin Console session demonstrates the basics of these features:
gremlin> :plugin list //1
==>tinkerpop.server[active]
==>tinkerpop.utilities[active]
==>tinkerpop.sugar
==>tinkerpop.tinkergraph[active]
gremlin> :plugin use tinkerpop.sugar //2
==>tinkerpop.sugar activated
gremlin> :install org.apache.tinkerpop neo4j-gremlin 4.0.0-SNAPSHOT //3
==>loaded: [org.apache.tinkerpop, neo4j-gremlin, 4.0.0-SNAPSHOT]
gremlin> :plugin list //4
==>tinkerpop.server[active]
==>tinkerpop.utilities[active]
==>tinkerpop.sugar
==>tinkerpop.tinkergraph[active]
==>tinkerpop.neo4j
gremlin> :plugin use tinkerpop.neo4j //5
==>tinkerpop.neo4j activated
gremlin> :plugin list //6
==>tinkerpop.server[active]
==>tinkerpop.sugar[active]
==>tinkerpop.utilities[active]
==>tinkerpop.neo4j[active]
==>tinkerpop.tinkergraph[active]-
Show a list of "available" plugins. The list of "available" plugins is determined by the classes available on the Console classpath. Plugins need to be "active" for their features to be available.
-
To make a plugin "active" execute the
:plugin usecommand and specify the name of the plugin to enable. -
Sometimes there are external dependencies that would be useful within the Console. To bring those in, execute
:installand specify the Maven coordinates for the dependency. -
Note that there is a "tinkerpop.neo4j" plugin available, but it is not yet "active".
-
Again, to use the "tinkerpop.neo4j" plugin, it must be made "active" with
:plugin use. -
Now when the plugin list is displayed, the "tinkerpop.neo4j" plugin is displayed as "active".
|
Warning
|
Plugins must be compatible with the version of the Gremlin Console (or Gremlin Server) being used. Attempts
to use incompatible versions cannot be guaranteed to work. Moreover, be prepared for dependency conflicts in
third-party plugins that may only be resolved via manual jar removal from the ext/{plugin} directory.
|
|
Tip
|
It is possible to manage plugin activation and deactivation by manually editing the ext/plugins.txt file which
contains the class names of the "active" plugins. It is also possible to clear dependencies added by :install by
deleting them from the ext directory.
|
Execution Mode
For automated tasks and batch executions of Gremlin, it can be useful to execute Gremlin scripts in "execution" mode
from the command line. Consider the following file named gremlin.groovy:
graph = TinkerFactory.createModern()
g = traversal().with(graph)
g.V().each { println it }This script creates the toy graph and then iterates through all its vertices printing each to the system out. To
execute this script from the command line, gremlin.sh has the -e option used as follows:
$ bin/gremlin.sh -e gremlin.groovy
v[1]
v[2]
v[3]
v[4]
v[5]
v[6]It is also possible to pass arguments to scripts. Any parameters following the file name specification are treated as arguments to the script. They are collected into a list and passed in as a variable called "args". The following Gremlin script is exactly like the previous one, but it makes use of the "args" option to filter the vertices printed to system out:
graph = TinkerFactory.createModern()
g = traversal().with(graph)
g.V().has('name',args[0]).each { println it }When executed from the command line a parameter can be supplied:
$ bin/gremlin.sh -e gremlin.groovy marko
v[1]
$ bin/gremlin.sh -e gremlin.groovy vadas
v[2]It is also possible to pass multiple scripts by specifying multiple -e options. The scripts will execute in the order
in which they are specified. Note that only the arguments from the last script executed will be preserved in the console.
Finally, if the arguments conflict with the reserved flags to which gremlin.sh responds, double quotes can be used to
wrap all the arguments to the option:
$ bin/gremlin.sh -e "gremlin.groovy -e -i --color"Interactive Mode
The Gremlin Console can be started in an "interactive" mode. Interactive mode is like execution mode but the console will not exit at the completion of the script, even if the script completes unsuccessfully. In such a case, it will simply stop processing on the line of the script that failed. In this way, the state of the console is such that a user could examine the state of things up to the point of failure, which might make the script easier to debug.
In addition to debugging, interactive mode is a helpful way for users to initialize their console environment to
avoid otherwise repetitive typing. For example, a user who spends a lot of time working with the TinkerPop "modern"
graph might create a script called init.groovy like:
graph = TinkerFactory.createModern()
g = traversal().with(graph)and then start Gremlin Console as follows:
$ bin/gremlin.sh -i init.groovy
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin> g.V()
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]Note that the user can now reference g (and graph for that matter) at startup without having to directly type that
variable initialization code into the console.
As in execution mode, it is also possible to pass multiple scripts by specifying multiple -i options. See the
Execution Mode Section for more information on the specifics of that capability.
Docker Image
The Gremlin Console can also be started as a Docker image:
$ docker run -it tinkerpop/gremlin-console:4.0.0-SNAPSHOT
Feb 25, 2018 3:47:24 PM java.util.prefs.FileSystemPreferences$1 run
INFO: Created user preferences directory.
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin>The Docker image offers the same options as the standalone Console. It can be used for example to execute scripts:
$ docker run -it tinkerpop/gremlin-console:4.0.0-SNAPSHOT -e gremlin.groovy
v[1]
v[2]
v[3]
v[4]
v[5]
v[6]Gremlin Server
 Gremlin Server provides a way to remotely execute Gremlin against one
or more
Gremlin Server provides a way to remotely execute Gremlin against one
or more Graph instances hosted within it. The benefits of using Gremlin Server include:
-
Allows any Gremlin Structure-enabled graph (i.e. implements the
GraphAPI on the JVM) to exist as a standalone server, which in turn enables the ability for multiple clients to communicate with the same graph database. -
Enables execution of ad hoc queries through remotely submitted Gremlin.
-
Provides a method for non-JVM languages which may not have a Gremlin Traversal Machine (e.g. Python, Javascript, Go, etc.) to communicate with the TinkerPop stack on the JVM.
-
Exposes numerous methods for extension and customization to include serialization options, remote commands, etc.
|
Note
|
Gremlin Server is the replacement for Rexster. |
|
Note
|
Please see the Provider Documentation for information on how to develop a driver for Gremlin Server. |
By default, communication with Gremlin Server occurs over HTTP/1.1. The TinkerPop HTTP API is described in the HTTP provider documentation.
|
Warning
|
Gremlin Server allows for the execution of remotely submitted "scripts" (i.e. arbitrary code sent by a client to the server). Developers should consider the security implications involved in running Gremlin Server without the appropriate precautions. Please review the Security Section and more specifically, the Script Execution Section for more information. |
Starting Gremlin Server
Gremlin Server comes packaged with a script called bin/gremlin-server.sh to get it started (use gremlin-server.bat
on Windows):
$ bin/gremlin-server.sh conf/gremlin-server-modern.yaml
[INFO] GremlinServer
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-modern.yaml
[INFO] MetricManager - Configured Metrics Slf4jReporter configured with interval=180000ms and loggerName=org.apache.tinkerpop.gremlin.server.Settings$Slf4jReporterMetrics
[INFO] DefaultGraphManager - Graph [graph] was successfully configured via [conf/tinkergraph-empty.properties].
[INFO] ServerGremlinExecutor - Initialized Gremlin thread pool. Threads in pool named with pattern gremlin-*
[INFO] ServerGremlinExecutor - Initialized GremlinExecutor and preparing GremlinScriptEngines instances.
[INFO] ServerGremlinExecutor - Initialized gremlin-groovy GremlinScriptEngine and registered metrics
[INFO] ServerGremlinExecutor - A GraphTraversalSource is now bound to [g] with graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
[INFO] GremlinServer - Executing start up LifeCycleHook
[INFO] Logger$info - Loading 'modern' graph data.
[INFO] GremlinServer - idleConnectionTimeout was set to 0 which resolves to 0 seconds when configuring this value - this feature will be disabled
[INFO] GremlinServer - keepAliveInterval was set to 0 which resolves to 0 seconds when configuring this value - this feature will be disabled
[INFO] AbstractChannelizer - Configured application/vnd.gremlin-v4.0+json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV4
[INFO] AbstractChannelizer - Configured application/json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV4
[INFO] AbstractChannelizer - Configured application/vnd.graphbinary-v4.0 with org.apache.tinkerpop.gremlin.util.ser.GraphBinaryMessageSerializerV4
[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 4 and boss thread pool of 1.
[INFO] GremlinServer$1 - Channel started at port 8182.Gremlin Server is configured by the provided YAML file conf/gremlin-server-modern.yaml.
That file tells Gremlin Server many things such as:
-
The host and port to serve on
-
Thread pool sizes
-
Where to report metrics gathered by the server
-
The serializers to make available
-
The Gremlin
ScriptEngineinstances to expose and external dependencies to inject into them -
Graphinstances to expose
The log messages that printed above show a number of things, but most importantly, there is a Graph instance named
graph that is exposed in Gremlin Server. This graph is an in-memory TinkerGraph and was empty at the start of the
server. An initialization script at scripts/generate-modern.groovy was executed during startup. Its contents are
as follows:
// an init script that returns a Map allows explicit setting of global bindings.
def globals = [:]
// Generates the modern graph into an "empty" TinkerGraph via LifeCycleHook.
// Note that the name of the key in the "global" map is unimportant.
globals << [hook : [
onStartUp: { ctx ->
ctx.logger.info("Loading 'modern' graph data.")
org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerFactory.generateModern(graph)
}
] as LifeCycleHook]
// define the default TraversalSource to bind queries to - this one will be named "g".
globals << [g : traversal().withEmbedded(graph)]The script above initializes a Map and assigns two key/values to it. The first, assigned to "hook", defines a
LifeCycleHook for Gremlin Server. The "hook" provides a way to tie script code into the Gremlin Server startup and
shutdown sequences. The LifeCycleHook has two methods that can be implemented: onStartUp and onShutDown.
These events are called once at Gremlin Server start and once at Gremlin Server stop. This is an important point
because code outside of the "hook" is executed for each ScriptEngine creation (multiple may be created when
"sessions" are enabled) and therefore the LifeCycleHook provides a way to ensure that a script is only executed a
single time. In this case, the startup hook loads the "modern" graph into the empty TinkerGraph instance, preparing
it for use. The second key/value pair assigned to the Map, named "g", defines a TraversalSource from the Graph
bound to the "graph" variable in the YAML configuration file. This variable g, as well as any other variable
assigned to the Map, will be made available as variables for future remote script executions. In more general
terms, any key/value pairs assigned to a Map returned from the initialization script will become variables that
are global to all requests. In addition, any functions that are defined will be cached for future use.
|
Warning
|
Transactions on graphs in initialization scripts are not closed automatically after the script finishes executing. It is up to the script to properly commit or rollback transactions in the script itself. |
Connecting via Drivers
 TinkerPop offers client-side drivers for the Gremlin Server that
communicates via the TinkerPop HTTP API in a variety of languages:
TinkerPop offers client-side drivers for the Gremlin Server that
communicates via the TinkerPop HTTP API in a variety of languages:
These drivers provide methods to send Gremlin based requests and get back traversal results as a response. The requests
are script-based or traversal-based. Traversals are internally translated into a gremlin-lang compatible script.
Traversals are still the recommended way to send Gremlin as it has better integration with your language of choice. The
difference between sending scripts and sending traversals are demonstrated below in some basic examples:
// script
Cluster cluster = Cluster.open();
Client client = cluster.connect();
Map<String,Object> params = new HashMap<>();
params.put("name","marko");
List<Result> list = client.submit("g.V().has('person','name',name).out('knows')", params).all().get();
// traversal
GraphTraversalSource g = traversal().with(DriverRemoteConnection.using("localhost",8182,"g"));
List<Vertex> list = g.V().has("person","name","marko").out("knows").toList();// script
def cluster = Cluster.open()
def client = cluster.connect()
def list = client.submit("g.V().has('person','name',name).out('knows')", [name: "marko"]).all().get();
// traversal
def g = traversal().with(DriverRemoteConnection.using("localhost",8182,"g"))
def list = g.V().has('person','name','marko').out('knows').toList()// script
var gremlinServer = new GremlinServer("localhost", 8182);
using (var gremlinClient = new GremlinClient(gremlinServer))
{
var bindings = new Dictionary<string, object>
{
{"name", "marko"}
};
var response =
await gremlinClient.SubmitWithSingleResultAsync<object>("g.V().has('person','name',name).out('knows')",
bindings);
}
// bytecode
using (var gremlinClient = new GremlinClient(new GremlinServer("localhost", 8182)))
{
var g = Traversal().With(new DriverRemoteConnection(gremlinClient));
var list = g.V().Has("person", "name", "marko").Out("knows").ToList();
}// script
const client = new Client('ws://localhost:45940/gremlin', { traversalSource: "g" });
const conn = client.open();
const list = conn.submit("g.V().has('person','name',name).out('knows')",{name: 'marko'}).then(function (response) { ... });
// traversal
const g = gtraversal().with(new DriverRemoteConnection('ws://localhost:8182/gremlin'));
const list = g.V().has("person","name","marko").out("knows").toList();# script
client = Client('ws://localhost:8182/gremlin', 'g')
list = client.submit("g.V().has('person','name',name).out('knows')",{'name': 'marko'}).all()
# traversal
g = traversal().with(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))
list = g.V().has("person","name","marko").out("knows").toList()// script
client, err := NewClient("ws://localhost:8182/gremlin")
resultSet, err := client.SubmitWithOptions("g.V().has('person','name',name).out('knows')",
new(RequestOptionsBuilder).AddBinding("name", "marko").Create())
result, err := resultSet.All()
// traversal
remote, err := NewDriverRemoteConnection("ws://localhost:8182/gremlin")
g := Traversal_().With(remote)
list, err := g.V().Has("person", "name", "marko").Out("knows").ToList()The advantage of traversals over scripts should be apparent from the above examples. Scripts are just strings that are embedded in code (in the above examples, the strings are Groovy-based) whereas traversal based requests are themselves code written in the native language of use. Obviously, the advantage of the Gremlin being actual code is that there are checks (e.g. compile-time, auto-complete and other IDE support, language level checks, etc.) that help validate the Gremlin during the development process.
TinkerPop makes an effort to ensure a high-level of consistency among the drivers and their features, but there are differences in capabilities and features as they are each developed independently. The Java driver was the first and is therefore the most advanced. Please see the related documentation for the driver of interest for more information and details in the Gremlin Drivers and Variants Section of this documentation.
Connecting via Console
Gremlin Console can be used to send remote traversals to a running Gremlin Server. Start Gremlin Console as follows:
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
gremlin>Remote traversals can then be constructed as follows.
gremlin> g = traversal().with('conf/remote-graph.properties')
==>graphtraversalsource[emptygraph[empty], standard]
gremlin>
gremlin> g.V().values('name')
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().has('name','marko').out('created').values('name')
==>lop
gremlin> g.E().label().groupCount()
==>[created:4,knows:2]
gremlin>
gremlin> g.close()
==>nullg = traversal().with('conf/remote-graph.properties')
g.V().values('name')
g.V().has('name','marko').out('created').values('name')
g.E().label().groupCount()
g.close()One can also construct remote traversal source via DRC, as well as via client to submit scripts.
// with DRC
g = traversal().with(DriverRemoteConnection.using("localhost",8182,"g"))
g.V().count()
// with client
client = Cluster.build("localhost").port(8182).create().connect()
client.submit("g.V().count()")Connecting via HTTP
 The HTTP endpoint provides for a communication protocol familiar to
most developers, with a wide support of programming languages, tools and libraries for accessing it. As a result, HTTP
provides a fast way to get started with Gremlin Server.
The HTTP endpoint provides for a communication protocol familiar to
most developers, with a wide support of programming languages, tools and libraries for accessing it. As a result, HTTP
provides a fast way to get started with Gremlin Server.
Gremlin Server implements the TinkerPop HTTP API. It provides a single endpoint which allows for the submission of a Gremlin script as a request. For each request, it returns a response containing the serialized results of that script.
The HttpChannelizer is already configured in the gremlin-server-modern.yaml file that is packaged with the Gremlin
Server distribution. To utilize it, start Gremlin Server as follows:
bin/gremlin-server.sh conf/gremlin-server-modern.yamlOnce the server has started, issue a request. Here’s an example with cURL:
curl -X POST -d "{\"gremlin\":\"100-1\"}" "http://localhost:8182"returns:
{
"result": {
"data": {
"@type": "g:List",
"@value": [
{
"@type": "g:Int32",
"@value": 99
}
]
}
},
"status": {
"code": 200
}
}POST is the only supported method for this endpoint. This means that GET with query parameters is not supported.
It is also preferred that Gremlin scripts be parameterized when possible via bindings:
curl -X POST -d "{\"gremlin\":\"100-x\", \"bindings\":{\"x\":1}}" "http://localhost:8182"The bindings argument is a Map of variables where the keys become available as variables in the Gremlin script.
Note that parameterization of requests is critical to performance, as repeated script compilation can be avoided on
each request.
|
Note
|
It is possible to pass bindings via GET based requests. Query string arguments prefixed with "bindings." will
be treated as parameters, where that prefix will be removed and the value following the period will become the
parameter name. In other words, bindings.x will create a parameter named "x" that can be referenced in the submitted
Gremlin script. The caveat is that these arguments will always be treated as String values. To ensure that data
types are preserved or to pass complex objects such as lists or maps, use POST which will at least support the
allowed JSON data types.
|
|
Note
|
The Gremlin Server doesn’t support HTTP pipelining. Attempts to use this feature will cause the server to throw an error and may lead to results being sent out-of-order. |
Passing the Accept header with a valid MIME type will trigger the server to return the result in a particular format.
Note that in addition to the formats available given the server’s serializers configuration, there is also a basic
text/plain format which produces a text representation of results similar to the Gremlin Console:
$ curl -H "Accept:text/plain" -X POST -d "{\"gremlin\":\"g.V()\"}" "http://localhost:8182"
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]Finally, as Gremlin Server can host multiple ScriptEngine instances (e.g. gremlin-groovy, nashorn), it is
possible to define the language to utilize to process the request:
curl -X POST -d "{\"gremlin\":\"100-x\", \"language\":\"gremlin-groovy\", \"bindings\":{\"x\":1}}" "http://localhost:8182"By default this value is set to gremlin-groovy. If using a GET operation, this value can be set as a query
string argument with by setting the language key.
Configuring
The gremlin-server.sh file serves multiple purposes. It can be used to "install" dependencies to the Gremlin
Server path. For example, to be able to configure and use other Graph implementations, the dependencies must be
made available to Gremlin Server. To do this, use the install switch and supply the Maven coordinates for the
dependency to "install". For example, to use Neo4j in Gremlin Server:
bin/gremlin-server.sh install org.apache.tinkerpop neo4j-gremlin 4.0.0-SNAPSHOTThis command will "grab" the appropriate dependencies and copy them to the ext directory of Gremlin Server, which
will then allow them to be "used" the next time the server is started. To uninstall dependencies, simply delete them
from the ext directory.
bin/gremlin-server.sh has several other options.
| Parameter | Description |
|---|---|
start |
Start the server in the background. |
stop |
Shutdown the server. |
restart |
Shutdown a running server then start it again. |
status |
Check if the server is running. |
console |
Start the server in the foreground. Use ^C to kill it. |
install <group> <artifact> <version> |
Install dependencies into the server. "-i" exists for backwards compatibility but is deprecated. |
<conf file> |
Start the server in the foreground using the provided YAML config file. |
The bin/gremlin-server.sh script can be customized with environment variables in bin/gremlin-server.conf.
| Variable | Description |
|---|---|
DEBUG |
Enable debugging of the startup script |
GREMLIN_HOME |
The Gremlin Server install directory. Use this if the script has trouble finding itself. |
GREMLIN_YAML |
The default server YAML file (conf/gremlin-server.yaml) |
LOG_DIR |
Location of gremlin.log where stdout/stderr are captured (logs/) |
PID_DIR |
Location of gremlin.pid |
RUNAS |
User to run the server as |
JAVA_HOME |
Java install location. Will use $JAVA_HOME/bin/java |
JAVA_OPTIONS |
Options passed to the JVM |
As mentioned earlier, Gremlin Server is configured though a YAML file. By default, Gremlin Server will look for a
file called conf/gremlin-server.yaml to configure itself on startup. To override this default, set GREMLIN_YAML in
bin/gremlin-server.conf or supply the file to use to bin/gremlin-server.sh as in:
bin/gremlin-server.sh conf/gremlin-server-min.yaml|
Warning
|
On Windows, gremlin-server.bat will always start in the foreground. When no parameter is provided, it will
start with the default conf/gremlin-server.yaml file.
|
The following table describes the various YAML configuration options that Gremlin Server expects:
| Key | Description | Default |
|---|---|---|
authentication.authenticator |
The fully qualified classname of an |
|
authentication.authenticationHandler |
The fully qualified classname of an |
none |
authentication.config |
A |
none |
authorization.authorizer |
The fully qualified classname of an |
none |
authorization.config |
A |
none |
channelizer |
The fully qualified classname of the |
|
enableAuditLog |
The |
false |
graphManager |
The fully qualified classname of the |
|
graphs |
A |
none |
gremlinPool |
The number of "Gremlin" threads available to execute actual scripts in a |
0 |
host |
The name of the host to bind the server to. |
localhost |
idleConnectionTimeout |
Time in milliseconds that the server will allow a channel to not receive requests from a client before it automatically closes. If enabled, the value provided should typically exceed the amount of time given to |
0 |
keepAliveInterval |
Time in milliseconds that the server will allow a channel to not send responses to a client before it sends a "ping" to see if it is still present. If it is present, the client should respond with a "pong" which will thus reset the |
0 |
maxAccumulationBufferComponents |
Maximum number of request components that can be aggregated for a message. |
1024 |
maxChunkSize |
The maximum length of the content or each chunk. If the content length exceeds this value, the transfer encoding of the decoded request will be converted to 'chunked' and the content will be split into multiple |
8192 |
maxRequestContentLength |
The maximum length of the aggregated content for a request message. Works in concert with |
10485760 |
maxHeaderSize |
The maximum length of all headers. |
8192 |
maxInitialLineLength |
The maximum length of the initial line (e.g. "GET / HTTP/1.0") processed in a request, which essentially controls the maximum length of the submitted URI. |
4096 |
maxParameters |
The maximum number of parameters that can be passed on a request. Larger numbers may impact performance for scripts. This configuration only applies to the |
16 |
maxWorkQueueSize |
The maximum size the general processing queue can grow before the |
8192 |
metrics.consoleReporter.enabled |
Turns on console reporting of metrics. |
false |
metrics.consoleReporter.interval |
Time in milliseconds between reports of metrics to console. |
180000 |
metrics.csvReporter.enabled |
Turns on CSV reporting of metrics. |
false |
metrics.csvReporter.fileName |
The file to write metrics to. |
none |
metrics.csvReporter.interval |
Time in milliseconds between reports of metrics to file. |
180000 |
metrics.gangliaReporter.addressingMode |
Set to |
none |
metrics.gangliaReporter.enabled |
Turns on Ganglia reporting of metrics. Additional setup is required. |
false |
metrics.gangliaReporter.host |
Define the Ganglia host to report Metrics to. |
localhost |
metrics.gangliaReporter.interval |
Time in milliseconds between reports of metrics for Ganglia. |
180000 |
metrics.gangliaReporter.port |
Define the Ganglia port to report Metrics to. |
8649 |
metrics.graphiteReporter.enabled |
Turns on Graphite reporting of metrics. Additional setup is required. |
false |
metrics.graphiteReporter.host |
Define the Graphite host to report Metrics to. |
localhost |
metrics.graphiteReporter.interval |
Time in milliseconds between reports of metrics for Graphite. |
180000 |
metrics.graphiteReporter.port |
Define the Graphite port to report Metrics to. |
2003 |
metrics.graphiteReporter.prefix |
Define a "prefix" to append to metrics keys reported to Graphite. |
none |
metrics.jmxReporter.enabled |
Turns on JMX reporting of metrics. |
false |
metrics.slf4jReporter.enabled |
Turns on SLF4j reporting of metrics. |
false |
metrics.slf4jReporter.interval |
Time in milliseconds between reports of metrics to SLF4j. |
180000 |
port |
The port to bind the server to. |
8182 |
resultIterationBatchSize |
Defines the size in which the result of a request is "batched" back to the client. In other words, if set to |
64 |
scriptEngines |
A |
gremlin-lang |
scriptEngines.<name>.imports |
A comma separated list of classes/packages to make available to the |
none |
scriptEngines.<name>.staticImports |
A comma separated list of "static" imports to make available to the |
none |
scriptEngines.<name>.scripts |
A comma separated list of script files to execute on |
none |
scriptEngines.<name>.config |
A |
none |
evaluationTimeout |
The amount of time in milliseconds before a request evaluation and iteration of result times out. This feature can be turned off by setting the value to |
30000 |
serializers |
A |
empty |
serializers[X].className |
The full class name of the |
none |
serializers[X].config |
A |
none |
ssl.enabled |
Determines if SSL is turned on or not. |
false |
ssl.keyStore |
The private key in JKS or PKCS#12 format. |
none |
ssl.keyStorePassword |
The password of the |
none |
ssl.keyStoreType |
|
none |
ssl.needClientAuth |
Optional. One of NONE, REQUIRE. Enables client certificate authentication at the enforcement level specified. Can be used in combination with Authenticator. |
none |
ssl.sslCipherSuites |
The list of JSSE ciphers to support for SSL connections. If specified, only the ciphers that are listed and supported will be enabled. If not specified, the JVM default is used. |
none |
ssl.sslEnabledProtocols |
The list of SSL protocols to support for SSL connections. If specified, only the protocols that are listed and supported will be enabled. If not specified, the JVM default is used. |
none |
ssl.trustStore |
Required when needClientAuth is REQUIRE. Trusted certificates for verifying the remote endpoint’s certificate. If this value is not provided and SSL is enabled, the default |
none |
ssl.trustStorePassword |
The password of the |
none |
strictTransactionManagement |
Set to |
false |
threadPoolBoss |
The number of threads available to Gremlin Server for accepting connections. Should always be set to |
1 |
threadPoolWorker |
The number of threads available to Gremlin Server for processing non-blocking reads and writes. |
1 |
useEpollEventLoop |
Try to use epoll event loops (works only on Linux os) instead of netty NIO. |
false |
writeBufferHighWaterMark |
If the number of bytes in the network send buffer exceeds this value then the channel is no longer writeable, accepting no additional writes until buffer is drained and the |
65536 |
writeBufferLowWaterMark |
Once the number of bytes queued in the network send buffer exceeds the |
32768 |
See the Metrics section for more information on how to configure Ganglia and Graphite.
Serialization
Gremlin Server can accept requests and return results using different serialization formats. Serializers implement the
MessageSerializer interface. In doing so, they express the list of mime types they expect to support. When
configuring multiple serializers it is possible for two or more serializers to support the same mime type. Such a
situation may be common with a generic mime type such as application/json. Serializers are added in the order that
they are encountered in the configuration file and the first one added for a specific mime type will not be overridden
by other serializers that also support it.
The format of the serialization is configured by the serializers setting described in the table above. Note that
some serializers have additional configuration options as defined by the serializers[X].config setting. The
config setting is a Map where the keys and values get passed to the serializer at its initialization. The
available and/or expected keys are dependent on the serializer being used. Gremlin Server comes packaged with two
different serializers: GraphSON and GraphBinary.
|
Warning
|
Irrespective of the serialization format chosen, it is highly recommended that the serialization format is
specified explicitly. For example, prefer application/vnd.gremlin-v3.0+json to application/json. Use of the drivers
tend to take care of this issue internally, but for all other mechanisms it is best to ensure the Accept type is
defined this way to avoid possible breaking changes or unexpected results, as defaults may vary from server to server.
|
|
Warning
|
When connecting with drivers, never try to specify a serialization format that does not have embedded types.
The drivers are designed to use that type information to properly produce results in the programming language’s type
system and may not function correctly without it. Generally speaking, GraphBinary is always the best choice for the
drivers.
|
GraphSON
The GraphSON serializer produces human-readable output in JSON format and is a good configuration choice for those trying to use TinkerPop from non-JVM languages. JSON obviously has wide support across virtually all major programming languages and can be consumed by a wide variety of tools. The format itself is described in the IO Documentation. The following table shows the available GraphSON serializers that can be configured:
| Version | Embedded Types | Mime Type | Class |
|---|---|---|---|
4.0 |
yes |
|
|
4.0 |
no |
|
|
The above serializer classes can be found in the org.apache.tinkerpop.gremlin.util.ser package of gremlin-util.
|
Note
|
Gremlin can produce results that cannot be serialized with untyped GraphSON as the result simply cannot fit
the structure JSON inherently allows. A simple example would be g.V().groupCount() which returns a Map. A Map
is no problem for JSON, but the key to this Map is a Vertex, which is a complex object, and cannot be a key in
JSON which only allows String keys. Untyped GraphSON will simply convert the Vertex to a String for purpose of
serialization and as a result that data and type is lost. If this information is needed, switch to a typed format or
adjust the Gremlin query in some way to return it in a different form that fits JSON structure.
|
Configuring GraphSON in the Gremlin Server configuration looks like this:
- { className: org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV4 }Gremlin Server is configured by default with GraphSON 4.0 as shown above. It has the following configuration option:
| Key | Description | Default |
|---|---|---|
ioRegistries |
A list of |
none |
It is possible for two serializers to bind to the same mime type such as application/json. When such conflicts arise,
Gremlin Server will use the order of the serializers to determine priority such that the first serializer to bind to a
type will be used and the others ignored. The following log message will indicate how the server is ultimately configured:
|
Note
|
The below examples use GraphSON 1.0 and GraphSON 3.0 for example purposes, however, they are no longer available. |
[INFO] AbstractChannelizer - Configured application/json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV1
[INFO] AbstractChannelizer - Configured application/vnd.gremlin-v3.0+json with org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3
[INFO] AbstractChannelizer - application/json already has org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV1 configured - it will not be replaced by org.apache.tinkerpop.gremlin.util.ser.GraphSONMessageSerializerV3, change order of serialization configuration if this is not desired.Given the above, using GraphSON 3.0 under this configuration will require that the user specific the type:
$ curl -X POST -d "{\"gremlin\":\"100-1\"}" "http://localhost:8182"
{"requestId":"f8720ad9-2c8b-4eef-babe-21792a3e3157","status":{"message":"","code":200,"attributes":{}},"result":{"data":[99],"meta":{}}}
$ curl -H "Accept:application/vnd.gremlin-v3.0+json" -X POST -d "{\"gremlin\":\"100-1\"}" "http://localhost:8182"
{"requestId":"9fdf0892-d86c-41f2-94b5-092785c473eb","status":{"message":"","code":200,"attributes":{"@type":"g:Map","@value":[]}},"result":{"data":{"@type":"g:List","@value":[{"@type":"g:Int32","@value":99}]},"meta":{"@type":"g:Map","@value":[]}}GraphBinary
GraphBinary is a binary serialization format suitable for object trees, designed to reduce serialization overhead on both the client and the server, as well as limiting the size of the payload that is transmitted over the wire. The format itself is described in the IO Documentation.
- { className: org.apache.tinkerpop.gremlin.util.ser.GraphBinaryMessageSerializerV4 }It has the MIME type of application/vnd.graphbinary-v4.0 and the following configuration options:
| Key | Description | Default |
|---|---|---|
ioRegistries |
A list of |
none |
builder |
Name of the |
none |
As described above, there are multiple ways in which to register serializers for GraphBinary-based serialization.
Metrics
Gremlin Server produces metrics about its operations that can yield some insight into how it is performing. These metrics are exposed in a variety of ways:
The configuration of each of these outputs is described in the Gremlin Server Configuring section. Note that Graphite and Ganglia are not included as part of the Gremlin Server distribution and must be installed to the server manually.
bin/gremlin-server.sh install com.codahale.metrics metrics-ganglia 3.0.2
bin/gremlin-server.sh install com.codahale.metrics metrics-graphite 3.0.2|
Warning
|
Gremlin Server is built to work with Metrics 3.0.2. Usage of other versions may lead to unexpected problems. |
|
Note
|
Installing Ganglia will include org.acplt:oncrpc, which is an LGPL licensed dependency.
|
Regardless of the output, the metrics gathered are the same. Each metric is prefixed with
org.apache.tinkerpop.gremlin.server.GremlinServer and the following metrics are reported:
-
channels.paused- The current number of open channels (HTTP and Websocket) that have their writes to buffer paused when thewriteBufferHighWaterMarkconfiguration is exceeded. -
channels.total- The current number of open channels (HTTP and Websocket). -
channels.write-pauses- The total number of pauses across all channels (HTTP and Websocket) to buffer writes where thewriteBufferHighWaterMarkconfiguration is exceeded, with mean rate, as well as the 1, 5, and 15-minute rates. -
engine-name.session.session-id.*- Metrics related to differentGremlinScriptEngineinstances configured for session-based requests where "engine-name" will be the actual name of the engine, such as "gremlin-groovy" and "session-id" will be the identifier for the session itself. -
engine-name.sessionless.*- Metrics related to differentGremlinScriptEngineinstances configured for sessionless requests where "engine-name" will be the actual name of the engine, such as "gremlin-groovy". -
errors- The number of total errors, mean rate, as well as the 1, 5, and 15-minute error rates. -
op.eval- The number of script evaluations, mean rate, 1, 5, and 15 minute rates, minimum, maximum, median, mean, and standard deviation evaluation times, as well as the 75th, 95th, 98th, 99th and 99.9th percentile evaluation times (note that these time apply to both sessionless and in-session requests). -
op.traversal- The number ofTraversalbytecode-based executions, mean rate, 1, 5, and 15 minute rates, minimum, maximum, median, mean, and standard deviation evaluation times, as well as the 75th, 95th, 98th, 99th and 99.9th percentile evaluation times. -
sessions- The number of sessions open at the time the metric was last measured. -
user-agent.*- Counts the number of connection requests from clients providing a given user agent.
|
Note
|
Gremlin Server has a limit of 10000 unique user agents to be tracked by metrics. If this cap is exceeded
any additional unique user agents will be counted as user-agent.other.
|
As A Service
Gremlin server can be configured to run as a service.
Init.d (SysV)
Link bin/gremlin-server.sh to init.d
Be sure to set RUNAS to the service user in bin/gremlin-server.conf
# Install
ln -s /path/to/apache-tinkerpop-gremlin-server-4.0.0-SNAPSHOT/bin/gremlin-server.sh /etc/init.d/gremlin-server
# Systems with chkconfig/service. E.g. Fedora, Red Hat
chkconfig --add gremlin-server
# Start
service gremlin-server start
# Or call directly
/etc/init.d/gremlin-server restartSystemd
To install, copy the service template below to /etc/systemd/system/gremlin.service
and update the paths /path/to/apache-tinkerpop-gremlin-server with the actual install path of Gremlin Server.
[Unit]
Description=Apache TinkerPop Gremlin Server daemon
Documentation=https://tinkerpop.apache.org/
After=network.target
[Service]
Type=forking
ExecStart=/path/to/apache-tinkerpop-gremlin-server/bin/gremlin-server.sh start
ExecStop=/path/to/apache-tinkerpop-gremlin-server/bin/gremlin-server.sh stop
PIDFile=/path/to/apache-tinkerpop-gremlin-server/run/gremlin.pid
[Install]
WantedBy=multi-user.targetEnable the service with systemctl enable gremlin-server
Start the service with systemctl start gremlin-server
Security
 Gremlin Server provides for several features that aid in the
security of the graphs that it exposes. In particular it supports SSL for transport layer security, authentication,
authorization and protective measures against malicious script execution. Client SSL options are described in the
Gremlin Drivers and Variants" sections with varying capability depending on the driver
chosen. Script execution options are covered "at the end of this section". This section
starts with authentication.
Gremlin Server provides for several features that aid in the
security of the graphs that it exposes. In particular it supports SSL for transport layer security, authentication,
authorization and protective measures against malicious script execution. Client SSL options are described in the
Gremlin Drivers and Variants" sections with varying capability depending on the driver
chosen. Script execution options are covered "at the end of this section". This section
starts with authentication.
By default, Gremlin Server supports HTTP basic authentication.
By default, Gremlin Server is configured to allow all requests to be processed (i.e. no authentication). To enable
authentication, Gremlin Server must be configured with an Authenticator implementation in its YAML file. Gremlin
Server comes packaged with an implementation called SimpleAuthenticator for plain text authentication using HTTP
BASIC.
Plain text authentication
The SimpleAuthenticator supports handling basic authentication requests from http clients. It validates
username/password pairs against a graph database, which must be provided to it as part of the configuration.
authentication: {
authenticator: org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator,
config: {
credentialsDb: conf/tinkergraph-credentials.properties}}A quick way to get started with the SimpleAuthenticator is to use TinkerGraph for the "credentials graph" and the
"sample" credential graph that is packaged with the server. To secure the transport for the credentials,
SSL should be enabled. For this Quick Start, a self-signed certificate will be created but this should not
be used in a production environment.
Generate the self-signed SSL certificate:
$ keytool -genkey -alias localhost -keyalg RSA -keystore server.jks
Enter keystore password:
Re-enter new password:
What is your first and last name?
[Unknown]: localhost
What is the name of your organizational unit?
[Unknown]:
What is the name of your organization?
[Unknown]:
What is the name of your City or Locality?
[Unknown]:
What is the name of your State or Province?
[Unknown]:
What is the two-letter country code for this unit?
[Unknown]:
Is CN=localhost, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct?
[no]: yes
Enter key password for <localhost>
(RETURN if same as keystore password):Next, uncomment the keyStore and keyStorePassword lines in conf/gremlin-server-secure.yaml.
ssl: {
enabled: true,
sslEnabledProtocols: [TLSv1.2],
keyStore: server.jks,
keyStorePassword: changeit
}$ bin/gremlin-server.sh conf/gremlin-server-secure.yaml
[INFO] GremlinServer -
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-secure.yaml
...
[INFO] AbstractChannelizer - SSL enabled
[INFO] SimpleAuthenticator - Initializing authentication with the org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator
[INFO] SimpleAuthenticator - CredentialGraph initialized at CredentialGraph{graph=tinkergraph[vertices:1 edges:0]}
[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 8 and boss thread pool of 1.
[INFO] GremlinServer$1 - Channel started at port 8182.When SSL is enabled on the server, it must also be enabled on the client when connecting. To connect to
Gremlin Server with the gremlin-driver, set the credentials, enableSsl, and trustStore
when constructing the Cluster.
Cluster cluster = Cluster.build().credentials("stephen", "password")
.enableSsl(true).trustStore("server.jks").create();If connecting with Gremlin Console, which utilizes gremlin-driver for remote script execution, use the provided
conf/remote-secure.yaml file when defining the remote. That file contains configuration for the username and
password as well as enablement of SSL from the client side. Be sure to configure the trustStore if using self-signed
certificates.
Similarly, Gremlin Server can be configured for REST and security. Follow the steps above for configuring the SSL certificate.
$ bin/gremlin-server.sh conf/gremlin-server-rest-secure.yaml
[INFO] GremlinServer -
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-secure.yaml
...
[INFO] AbstractChannelizer - SSL enabled
[INFO] SimpleAuthenticator - Initializing authentication with the org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator
[INFO] SimpleAuthenticator - CredentialGraph initialized at CredentialGraph{graph=tinkergraph[vertices:1 edges:0]}
[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 8 and boss thread pool of 1.
[INFO] GremlinServer$1 - Channel started at port 8182.Once the server has started, issue a request passing the credentials with an Authentication header, as described in RFC2617. Here’s a HTTP Basic authentication example with cURL:
curl -X POST --insecure -u stephen:password -d "{\"gremlin\":\"100-1\"}" "https://localhost:8182"Credentials Graph DSL
The "credentials graph", which has been mentioned in previous sections, is used by Gremlin Server to hold the list of
users who can authenticate to the server. It is possible to use virtually any Graph instance for this task as long
as it complies to a defined schema. The credentials graph stores users as vertices with the label of "user". Each
"user" vertex has two properties: username and password. Naturally, these are both String values. The password
must not be stored in plain text and should be hashed.
|
Important
|
Be sure to define an index on the username property, as this will be used for lookups. If supported by
the Graph, consider specifying a unique constraint as well.
|
To aid with the management of a credentials graph, Gremlin Server provides a Gremlin Console plugin which can be used to add and remove users so as to ensure that the schema is adhered to, thus ensuring compatibility with Gremlin Server. In addition, as it is a plugin, it works naturally in the Gremlin Console as an extension of its capabilities (though one could use it programmatically, if desired). This plugin is distributed with the Gremlin Console so it does not have to be "installed". It does however need to be activated:
gremlin> :plugin use tinkerpop.credentials
==>tinkerpop.credentials activatedPlease see the example usage as follows:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> graph.createIndex("username",Vertex.class)
==>null
gremlin> credentials = traversal(CredentialTraversalSource.class).with(graph)
==>credentialtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> credentials.user("stephen","password")
==>v[0]
gremlin> credentials.user("daniel","better-password")
==>v[3]
gremlin> credentials.user("marko","rainbow-dash")
==>v[6]
gremlin> credentials.users("marko").elementMap()
==>[id:6,label:user,password:$2a$04$ICwYbzXI.4GtmCQgqwzJ2.m0iFhdlWzuNZSSDplGcKfc61uTgWJAm,username:marko]
gremlin> credentials.users().count()
==>3
gremlin> credentials.users("daniel").drop()
gremlin> credentials.users().count()
==>2graph = TinkerGraph.open()
graph.createIndex("username",Vertex.class)
credentials = traversal(CredentialTraversalSource.class).with(graph)
credentials.user("stephen","password")
credentials.user("daniel","better-password")
credentials.user("marko","rainbow-dash")
credentials.users("marko").elementMap()
credentials.users().count()
credentials.users("daniel").drop()
credentials.users().count()|
Note
|
The Credentials DSL is built using TinkerPop’s DSL Annotation Processor described here. |
|
Important
|
In the above example, an empty in-memory TinkerGraph was used for demonstrating the API of the DSL. Obviously, this data will not be retained and usable with Gremlin Server. It would be important to configure TinkerGraph to persist that data or to manually persist it (e.g. write the graph data to Gryo) once changes are complete. Alternatively, use a persistent graph to hold the credentials and configure Gremlin Server accordingly. |
Authorization
While authentication determines which clients can connect to Gremlin Server, authorization regulates which elements of the exposed graphs a specific user is allowed to create, read, update or delete (CRUD). Authorization in Gremlin Server can take place at two instances. Before execution a user request can be allowed or denied based on the presence of operations such as:
-
reading from a GraphTraversalSource
-
writing to a GraphTraversalSource
-
presence of lambdas in bytecode
-
script execution
-
VertexProgramexecution (OLAP) -
removal or modification of
TraversalStrategyinstances
During execution the applied traversal strategies influence the results and side-effects of a given query.
|
Important
|
Authorization is a feature of Gremlin Server, but is not implemented as an element of the server protocol and therefore Remote Graph Providers may not have this feature or may not implement it in this particular way. Please consult the documentation of the graph you are using to determine what authorization features it supports. |
Mechanisms
Gremlin Server supports three mechanisms to configure authorization:
-
With the
ScriptFileGremlinPlugina groovy script is configured that instantiates theGraphTraversalSourcesthat can be accessed by client requests. Using thewithStrategies()gremlin start step, one can apply so-called TraversalStrategy instances to theseGraphTraversalSourceinstances, some of which can serve for authorization purposes (ReadOnlyStrategy,LambdaRestrictionStrategy,VertexProgramRestrictionStrategy,SubgraphStrategy,PartitionStrategy,EdgeLabelVerificationStrategy), provided that users are not allowed to remove or modify theseTraversalStrategyinstances afterwards. TheScriptFileGremlinPluginis found in the yaml configuration file for Gremlin Server:scriptEngines: { gremlin-groovy: { plugins: { org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample.groovy]}}}} -
Administrators can configure an authorizer class, an implementation of the
Authorizerinterface. An authorizer receives a request before it is executed and it can decide to pass or deny the request, based on the information it has available on the requesting user or can seek externally. -
Apart from passing or denying requests, an
Authorizerimplementation can actively modify the request, in particular add theTraversalStrategyinstances mentioned in item 1.
|
Important
|
This section is written with gremlin bytecode requests in mind. Realizing authorization for script requests
is hardly feasible, because such requests get full access to Gremlin Server’s execution environment. Although the section
Protecting Script Execution explains how the client access to this environment can be restricted, it is not possible to deny
execution of GraphFactory.open() or GraphTraversalSource.getGraph() methods without resorting to TinkerPop
implementation details (that is, internal API’s that can change without notice).
|
|
Important
|
4.0 Milestone Release - These authorization mechanisms don’t currently apply due to the removal of Bytecode. |
The three mechanisms for authorization each have their merits in terms of simplicity and flexibility. The table below gives an overview.
| Type (mechanism) | GraphTraversalSources | Groups | Bytecode analysis |
|---|---|---|---|
Implicit (init script) |
all accessible |
one |
|
Passive (pass/deny) |
selected access |
few |
hybrid |
Active (inject) |
selected access |
many |
hybrid |
With implicit authorization (only adding restricting TraversalStrategy instances in the initialization script of
Gremlin Server) all authenticated users can access all hosted GraphTraversalSources and all face the same
restrictions. One would need separate Gremlin Server instances for each authorization policy and apply an authenticator
that restricts access to a group of users (that is, supports in authorization).
The other extreme is the active authorization solution that injects the restricting Strategies into the user request,
following a policy that takes into account both the authenticated user and the original request. While this solution is
the most flexible and can support an almost unlimited number of authorization policies, it is somewhat complex to
implement. In particular, applying the SubgraphStrategy requires knowledge about the schema of the graph.
The passive authorization solution perhaps provides a middle ground to start implementing authorization. This
solution assumes that the SubgraphStrategy is applied in the Gremlin Server initialization script, because compliance
with a subgraph restriction can only be determined during the actual execution of the gremlin traversal. Note that the
same graph can be reused with different SubgraphStrategies. Now, authorization policies can be defined in terms of
accessible GraphTraversalSources and the authorizer can simply match the requested access to a GraphTraversalSource
against the policies applicable to the authenticated user. Like for the active authorization solution, other restrictions
such as read only access can be either applied at authorization time as policy in the authorizer itself or at request
execution time as a result of an applied Strategy (denoted as 'hybrid' bytecode analysis in the table). A code
example pursuing the former option is provided in the next section.
|
Important
|
4.0 Milestone Release - passive and active authorization mechanisms are not supported in this milestone because bytecode has been replaced with GremlinLang. |
|
Note
|
Gremlin Server is not shipped with Authorizer implementations, because these would heavily depend on the external
systems to integrate with, e.g. LDAP systems or
Apache Ranger . However, third-party implementations can be
offered as gremlin plugins.
|
Code example
The two java classes below provide an example implementation of the Authorizer interface; they originate from
Gremlin Server’s test package.
If you copy the files into a project, build them into a jar and add the jar to Gremlin Server’s CLASSPATH, you can use
them by adding the following to Gremlin Server’s yaml configuration file:
authentication: {
authenticator: org.apache.tinkerpop.gremlin.server.auth.SimpleAuthenticator,
config: {
credentialsDb: conf/tinkergraph-credentials.properties}}
authorization: {
authorizer: org.yourpackage.AllowListAuthorizer,
config: {
authorizationAllowList: your/path/allow-list.yaml}}The AllowListAuthorizer supports granting groups of users access to statically configured GraphTraversalSource
instances and to the "sandbox", where sandbox means that the group is allowed anything unless restricted by Gremlin
Server’s sandbox. For denying mutating steps and OLAP operations in bytecode requests, the
AllowListAuthorizer relies on the ReadOnlyStrategy and VertexProgramRestrictionStrategy being present in the
GraphTraversalSource. However, it always denies the use of lambdas in bytecode requests unless the user has the
"sandbox" grant. It uses the BytecodeHelper.getLambdaLanguage() method to detect these.
The grants to groups of users can be configured in a simple yaml file. In addition to the special value "sandbox" for a grant for string based requests and lambdas, the special value "anonymous" can be used to denote any user.
package org.yourpackage;
import org.apache.tinkerpop.gremlin.util.message.RequestMessage;
import org.apache.tinkerpop.gremlin.process.computer.traversal.strategy.verification.VertexProgramRestrictionStrategy;
import org.apache.tinkerpop.gremlin.process.traversal.Bytecode;
import org.apache.tinkerpop.gremlin.process.traversal.TraversalSource;
import org.apache.tinkerpop.gremlin.process.traversal.strategy.decoration.SubgraphStrategy;
import org.apache.tinkerpop.gremlin.process.traversal.strategy.verification.ReadOnlyStrategy;
import org.apache.tinkerpop.gremlin.server.Settings.AuthorizationSettings;
import org.apache.tinkerpop.gremlin.server.auth.AuthenticatedUser;
import java.util.*;
/**
* Authorizes a user per request, based on a list that grants access to {@link TraversalSource} instances for
* bytecode requests and to gremlin server's sandbox for string requests and lambdas. The {@link
* AuthorizationSettings}.config must have an authorizationAllowList entry that contains the name of a YAML file.
* This authorizer is for demonstration purposes only. It does not scale well in the number of users regarding
* memory usage and administrative burden.
*/
public class AllowListAuthorizer implements Authorizer {
public static final String SANDBOX = "sandbox";
public static final String REJECT_BYTECODE = "User not authorized for bytecode requests on %s";
public static final String REJECT_LAMBDA = "lambdas";
public static final String REJECT_MUTATE = "the ReadOnlyStrategy";
public static final String REJECT_OLAP = "the VertexProgramRestrictionStrategy";
public static final String REJECT_SUBGRAPH = "the SubgraphStrategy";
public static final String REJECT_STRING = "User not authorized for string-based requests.";
public static final String KEY_AUTHORIZATION_ALLOWLIST = "authorizationAllowList";
// Collections derived from the list with allowed users for fast lookups
private final Map<String, List<String>> usernamesByTraversalSource = new HashMap<>();
private final Set<String> usernamesSandbox = new HashSet<>();
/**
* This method is called once upon system startup to initialize the {@code AllowListAuthorizer}.
*/
@Override
public void setup(final Map<String,Object> config) {
AllowList allowList;
final String file = (String) config.get(KEY_AUTHORIZATION_ALLOWLIST);
try {
allowList = AllowList.read(file);
} catch (Exception e) {
throw new IllegalArgumentException(String.format("Failed to read list with allowed users from %s", file));
}
for (Map.Entry<String, List<String>> entry : allowList.grants.entrySet()) {
if (!entry.getKey().equals(SANDBOX)) {
usernamesByTraversalSource.put(entry.getKey(), new ArrayList<>());
}
for (final String group : entry.getValue()) {
if (allowList.groups.get(group) == null) {
throw new RuntimeException(String.format("Group '%s' not defined in file with allowed users.", group));
}
if (entry.getKey().equals(SANDBOX)) {
usernamesSandbox.addAll(allowList.groups.get(group));
} else {
usernamesByTraversalSource.get(entry.getKey()).addAll(allowList.groups.get(group));
}
}
}
}
/**
* Checks whether a user is authorized to have a gremlin bytecode request from a client answered and raises an
* {@link AuthorizationException} if this is not the case. For a request to be authorized, the user must either
* have a grant for the requested {@link TraversalSource}, without using lambdas, mutating steps or OLAP, or have a
* sandbox grant.
*
* @param user {@link AuthenticatedUser} that needs authorization.
* @param bytecode The gremlin {@link Bytecode} request to authorize the user for.
* @param aliases A {@link Map} with a single key/value pair that maps the name of the {@link TraversalSource} in the
* {@link Bytecode} request to name of one configured in Gremlin Server.
* @return The original or modified {@link Bytecode} to be used for further processing.
*/
@Override
public Bytecode authorize(final AuthenticatedUser user, final Bytecode bytecode, final Map<String, String> aliases) throws AuthorizationException {
final Set<String> usernames = new HashSet<>();
for (final String resource: aliases.values()) {
usernames.addAll(usernamesByTraversalSource.get(resource));
}
final boolean userHasTraversalSourceGrant = usernames.contains(user.getName()) || usernames.contains(AuthenticatedUser.ANONYMOUS_USERNAME);
final boolean userHasSandboxGrant = usernamesSandbox.contains(user.getName()) || usernamesSandbox.contains(AuthenticatedUser.ANONYMOUS_USERNAME);
final boolean runsLambda = BytecodeHelper.getLambdaLanguage(bytecode).isPresent();
final boolean touchesReadOnlyStrategy = bytecode.toString().contains(ReadOnlyStrategy.class.getSimpleName());
final boolean touchesOLAPRestriction = bytecode.toString().contains(VertexProgramRestrictionStrategy.class.getSimpleName());
// This element becomes obsolete after resolving TINKERPOP-2473 for allowing only a single instance of each traversal strategy.
final boolean touchesSubgraphStrategy = bytecode.toString().contains(SubgraphStrategy.class.getSimpleName());
final List<String> rejections = new ArrayList<>();
if (runsLambda) {
rejections.add(REJECT_LAMBDA);
}
if (touchesReadOnlyStrategy) {
rejections.add(REJECT_MUTATE);
}
if (touchesOLAPRestriction) {
rejections.add(REJECT_OLAP);
}
if (touchesSubgraphStrategy) {
rejections.add(REJECT_SUBGRAPH);
}
String rejectMessage = REJECT_BYTECODE;
if (rejections.size() > 0) {
rejectMessage += " using " + String.join(", ", rejections);
}
rejectMessage += ".";
if ( (!userHasTraversalSourceGrant || runsLambda || touchesOLAPRestriction || touchesReadOnlyStrategy || touchesSubgraphStrategy) && !userHasSandboxGrant) {
throw new AuthorizationException(String.format(rejectMessage, aliases.values()));
}
return bytecode;
}
/**
* Checks whether a user is authorized to have a script request from a gremlin client answered and raises an
* {@link AuthorizationException} if this is not the case.
*
* @param user {@link AuthenticatedUser} that needs authorization.
* @param msg {@link RequestMessage} in which the {@link org.apache.tinkerpop.gremlin.util.Tokens}.ARGS_GREMLIN argument can contain an arbitrary succession of script statements.
*/
public void authorize(final AuthenticatedUser user, final RequestMessage msg) throws AuthorizationException {
if (!usernamesSandbox.contains(user.getName())) {
throw new AuthorizationException(REJECT_STRING);
}
}
}package org.yourpackage;
import org.yaml.snakeyaml.TypeDescription;
import org.yaml.snakeyaml.Yaml;
import org.yaml.snakeyaml.constructor.Constructor;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.List;
import java.util.Map;
import java.util.Optional;
/**
* AllowList for the AllowListAuthorizer as configured by a YAML file.
*/
public class AllowList {
/**
* Holds lists of groups by grant. A grant is either a TraversalSource name or the "sandbox" value. With the
* sandbox grant users can access all TraversalSource instances and execute groovy scripts as string based
* requests or as lambda functions, only limited by Gremlin Server's sandbox definition.
*/
public Map<String, List<String>> grants;
/**
* Holds lists of user names by groupname. The "anonymous" user name can be used to denote any user.
*/
public Map<String, List<String>> groups;
/**
* Read a configuration from a YAML file into an {@link AllowList} object.
*
* @param file the location of a AllowList YAML configuration file
* @return An {@link Optional} object wrapping the created {@link AllowList}
*/
public static AllowList read(final String file) throws Exception {
final InputStream stream = new FileInputStream(new File(file));
final Constructor constructor = new Constructor(AllowList.class);
final TypeDescription allowListDescription = new TypeDescription(AllowList.class);
allowListDescription.putMapPropertyType("grants", String.class, Object.class);
allowListDescription.putMapPropertyType("groups", String.class, Object.class);
constructor.addTypeDescription(allowListDescription);
final Yaml yaml = new Yaml(constructor);
return yaml.loadAs(stream, AllowList.class);
}
}allow-list.yaml:
grants: {
gclassic: [groupclassic],
gmodern: [groupmodern],
gcrew: [groupclassic, groupmodern],
ggrateful: [groupgrateful],
sandbox: [groupsandbox]
}
groups: {
groupclassic: [userclassic],
groupmodern: [usermodern, stephen],
groupsink: [usersink],
groupgrateful: [anonymous],
groupsandbox: [usersandbox, marko]
}Protecting Script Execution
It is important to remember that Gremlin Server exposes GremlinScriptEngine instances that allows for remote execution
of arbitrary code on the server. Obviously, this situation can represent a security risk or, more minimally, provide
ways for "bad" scripts to be inadvertently executed. A simple example of a "valid" Gremlin script that would cause
some problems would be, while(true) {}, which would consume a thread in the Gremlin pool indefinitely, thus
preventing it from serving other requests. Sending enough of these kinds of scripts would eventually consume all
available threads and Gremlin Server would stop responding.
Scripts have access to the full power of their language and the JVM on which they are running. This means that they
can access certain APIs that have nothing to do with Gremlin itself, such as java.lang.System or the java.io
and java.net packages. Scripts offer developers a lot of flexibility, but having that flexibility comes at the cost
of safety. A Gremlin Server instance that is not secured appropriately provides for a big security risk.
The previous sections discussed methods for securing Gremlin Server through authentication and encryption, which is a
good first step in protection. Another layer of protection comes in the form of specific configurations for the
GremlinGroovyScriptEngine. A user can configure the script engine with a GroovyCompilerGremlinPlugin
implementation. Consider the basic configuration from the Gremlin Server YAML file:
scriptEngines: {
gremlin-groovy: {
plugins: { org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {},
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {},
org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]},
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample.groovy]}}}}This configuration can be expanded to include a the GroovyCompilerGremlinPlugin:
scriptEngines: {
gremlin-groovy: {
plugins: { org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {},
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {}
org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]},
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample-secure.groovy]},
org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyCompilerGremlinPlugin: {enableThreadInterrupt: true}}}}This configuration sets up the script engine with to ensure that loops (like while) will respect interrupt requests.
With this configuration in place, a remote execution as follows, now times out rather than consuming the thread
continuously:
client = Cluster.build("localhost").port(8182).create().connect()
==>org.apache.tinkerpop.gremlin.driver.Client$ClusteredClient@42ff9a77
client.submit("while(true) { }")
org.apache.tinkerpop.gremlin.driver.exception.ResponseException: A timeout occurred during traversal evaluation of [RequestMessage{, fields={bindings={}, language=gremlin-groovy, batchSize=64}, gremlin=while(true) { }}] - consider increasing the limit given to evaluationTimeoutThe GroovyCompilerGremlinPlugin has a number of configuration options:
| Customizer | Description |
|---|---|
|
Allows for three configurations: |
|
Allows configuration of the Groovy |
|
Injects checks for thread interruption, thus allowing the script to potentially respect calls to |
|
The amount of time in milliseconds a script is allowed to compile before a warning message is sent to the logs. |
|
Determines if the global function cache is enabled. By default, this value is |
|
The cache specification for the |
|
This setting is for use when |
|
Note
|
Consult the latest Groovy Documentation for information on the differences on the various compilation options. It is important to understand the impact that these configuration will have on submitted scripts before enabling this feature. |
|
Important
|
TinkerPop does not offer an end-to-end out-of-the-box solution to perfectly protect against bad actors
submitting nefarious scripts. The configurations to follow which discuss the SimpleSandboxExtension and
FileSandboxExtension are meant to represent example implementations that users and providers can gain some
inspiration from in developing their own solutions. Please consult the documentation of your TinkerPop implementation
to determine how scripts are "secured" as many providers have taken their own approaches to solving this problem.
|
Securing scripts (i.e. preventing access to certain methods) is a bit more complicated of a story. As an example,
TinkerPop implemented some basic "sandbox" implementations as described in this
blog post to try to demonstrate a method by which script
security could be achieved. Consider the following configuration of the GroovyCompilerGremlinPlugin:
scriptEngines: {
gremlin-groovy: {
plugins: { org.apache.tinkerpop.gremlin.server.jsr223.GremlinServerGremlinPlugin: {},
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPlugin: {}
org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyCompilerGremlinPlugin: {enableThreadInterrupt: true, compilation: COMPILE_STATIC, extensions: org.apache.tinkerpop.gremlin.groovy.jsr223.customizer.SimpleSandboxExtension},
org.apache.tinkerpop.gremlin.jsr223.ImportGremlinPlugin: {classImports: [java.lang.Math], methodImports: [java.lang.Math#*]},
org.apache.tinkerpop.gremlin.jsr223.ScriptFileGremlinPlugin: {files: [scripts/empty-sample-secure.groovy]}}}}This configuration uses the SimpleSandboxExtension, which blocks calls to methods on the System class, thereby
preventing someone from remotely killing the server:
gremlin> :> System.exit(0)
Script8.groovy: 1: [Static type checking] - Not authorized to call this method: java.lang.System#exit(int)
@ line 1, column 1.
System.exit(0)
^
1 errorThe SimpleSandboxExtension is by no means a "complete" implementation protecting against all manner of nefarious
scripts, but it does provide an example for how such a capability might be implemented. A slightly more advanced
example is offered in the FileSandboxExtension which uses a configuration file to allow certain classes and methods.
The configuration file is YAML-based and an example is presented as follows:
autoTypeUnknown: true
methodWhiteList:
- java\.lang\.Boolean.*
- java\.lang\.Byte.*
- java\.lang\.Character.*
- java\.lang\.Double.*
- java\.lang\.Enum.*
- java\.lang\.Float.*
- java\.lang\.Integer.*
- java\.lang\.Long.*
- java\.lang\.Math.*
- java\.lang\.Number.*
- java\.lang\.Object.*
- java\.lang\.Short.*
- java\.lang\.String.*
- java\.lang\.StringBuffer.*
- java\.lang\.System#currentTimeMillis\(\)
- java\.lang\.System#nanoTime\(\)
- java\.lang\.Throwable.*
- java\.lang\.Void.*
- java\.util\..*
- org\.codehaus\.groovy\.runtime\.DefaultGroovyMethods.*
- org\.codehaus\.groovy\.runtime\.InvokerHelper#runScript\(java\.lang\.Class,java\.lang\.String\[\]\)
- org\.codehaus\.groovy\.runtime\.StringGroovyMethods.*
- groovy\.lang\.Script#<init>\(groovy.lang.Binding\)
- org\.apache\.tinkerpop\.gremlin\.structure\..*
- org\.apache\.tinkerpop\.gremlin\.process\..*
- org\.apache\.tinkerpop\.gremlin\.process\.computer\..*
- org\.apache\.tinkerpop\.gremlin\.process\.computer\.bulkloading\..*
- org\.apache\.tinkerpop\.gremlin\.process\.computer\.clustering\.peerpressure\.*
- org\.apache\.tinkerpop\.gremlin\.process\.computer\.ranking\.pagerank\.*
- org\.apache\.tinkerpop\.gremlin\.process\.computer\.traversal\..*
- org\.apache\.tinkerpop\.gremlin\.process\.traversal\..*
- org\.apache\.tinkerpop\.gremlin\.process\.traversal\.dsl\.graph\..*
- org\.apache\.tinkerpop\.gremlin\.process\.traversal\.engine\..*
- org\.apache\.tinkerpop\.gremlin\.server\.util\.LifeCycleHook.*
staticVariableTypes:
graph: org.apache.tinkerpop.gremlin.structure.Graph
g: org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSourceThere are three keys in this configuration file that control different aspects of the sandbox:
-
autoTypeUnknown- When set totrue, unresolved variables are typed asObject. -
methodWhiteList- A white list of classes and methods that follow a regex pattern which can then be matched against method descriptors to determine if they can be executed. The method descriptor is the fully-qualified class name of the method, its name and parameters. For example,Math.ceilwould have a descriptor ofjava.lang.Math#ceil(double). -
staticVariableTypes- A list of variables that will be used in theScriptEnginefor which the types are always known. In the above example, the variable "graph" will always be bound to aGraphinstance.
At Gremlin Server startup, the FileSandboxExtension looks in the root of Gremlin Server installation directory for a
file called sandbox.yaml and configures itself. To use a file in a different location set the
gremlinServerSandbox system property to the location of the file (e.g. -DgremlinServerSandbox=conf/my-sandbox.yaml).
A final thought on the topic of GroovyCompilerGremlinPlugin implementation is that it is not just for
"security" (though it is demonstrated in that capacity here). It can be used for a variety of features that
can fine tune the Groovy compilation process. Read more about compilation customization in the
Groovy Documentation.
Best Practices
The following sections define best practices for working with Gremlin Server.
Tuning
 Tuning Gremlin Server for a particular environment may require some
simple trial-and-error, but the following represent some basic guidelines that might be useful:
Tuning Gremlin Server for a particular environment may require some
simple trial-and-error, but the following represent some basic guidelines that might be useful:
-
Gremlin Server defaults to a very modest maximum heap size. Consider increasing this value for non-trivial uses. Maximum heap size (
-Xmx) is defined with theJAVA_OPTIONSsetting ingremlin-server.conf. -
TinkerPop tends to discourage the use of long traversals as they can introduce performance problems in some cases and in others simply fail with a
StackOverflowError. Aside from restructuring the traversal into multiple commands or stream based inserts, it may sometimes make sense to simply increase the stack size of the JVM for Gremlin Server by configuring an-Xsssetting inJAVA_OPTIONSofgremlin-server.conf. -
If Gremlin Server is processing scripts or lambdas in bytecode requests, consider fine tuning the JVM’s handling of the metaspace size. Consider modifying the
-XX:MetaspaceSize,-XX:MaxMetaspaceSize, and related settings given the expected workload. More discussion on this topic can be found in the Parameterized Scripts Section below. -
When configuring the size of
threadPoolWorkerstart with the default of1and increment by one as needed to a maximum of2*number of cores. -
The "right" size of the
gremlinPoolsetting is somewhat dependent on the type of requests that will be processed by Gremlin Server. As requests arrive to Gremlin Server they are decoded and queued to be processed by threads in this pool. When this pool is exhausted of threads, Gremlin Server will continue to accept incoming requests, but the queue will continue to grow. If left to grow too large, the server will begin to slow. When tuning around this setting, consider whether the bulk of the scripts being processed will be "fast" or "slow", where "fast" generally means being measured in the low hundreds of milliseconds and "slow" means anything longer than that. -
Requests that are "slow" can really hurt Gremlin Server if they are not properly accounted for. Since these requests block a thread until the job is complete or successfully interrupted, lots of long-run requests will eventually consume the
gremlinPoolpreventing other requests from getting processed from the queue.-
To limit the impact of this problem, consider properly setting the
evaluationTimeoutto something "sane". In other words, test the traversals being sent to Gremlin Server and determine the maximum time they take to evaluate and iterate over results, then set the timeout value accordingly. Also, consider setting a shorter global timeout for requests and then use longer per-request timeouts for those specific ones that might execute at a longer rate. -
Note that
evaluationTimeoutcan only attempt to interrupt the evaluation on timeout. It allows Gremlin Server to "ignore" the result of that evaluation, which means the thread in thegremlinPoolthat did the evaluation may still be consumed after the timeout if interruption does not succeed on the thread.
-
-
When using sessions, there are different options to consider depending on the
Channelizerimplementation being used:-
WebSocketChannelizerandWsAndHttpChannelizer- Both of these channelizers use thegremlinPoolonly for sessionless requests and construct a single threaded pool for each session created. In this way, these channelizers tend to optimize sessions to be long-lived. For short-lived sessions, which may be typical when using bytecode based remote transactions, quickly creating and destroying these sessions can be expensive. It is likely that there will be increased garbage collection times and frequency as well as a general increase in overall server processing.
-
-
Graph element serialization for
VertexandEdgecan be expensive, as their data structures are complex given the possible existence of multi-properties and meta-properties. When returning data from Gremlin Server only return the data that is required. For example, if only two properties of aVertexare needed then simply return the two rather than returning the entireVertexobject itself. Even with an entireVertex, it is typically much faster to issue the query asg.V(1).elementMap()thang.V(1), as the former returns aMapof the same data as aVertex, but without all the associated structure which can slow the response. -
Gremlin Server writes responses to a buffer held in direct memory prior to flushing them to the TCP socket. If the logs show
OutOfDirectMemoryError, particularly when thechannels.write-pausesmetric is high, it is likely caused by this buffer being filled. The buffer can fill when clients are slow to consume results being sent to them (e.g. network problems, underpowered client instances, etc.). Gremlin Server will attempt to throttle the speed at which the buffer gets filled by pausing writes for any channel that exceeds its allowed buffer space allotment as determined by thewriteBufferHighWaterMarkandwriteBufferLowWaterMarkdescribed in the Server Configuration Section. Pauses obviously increase latency, but do so for benefit of server stability in continuing to serve channels that have clients without issue consuming the results.-
Write pauses are generally considered a natural part of server operations, though a continuous amount of pausing means that threads used for query execution are tied up and are therefore preventing the processing of other requests. As a result, requests may begin to queue which further adds to server load and potential latency. Increasing the
writeBufferHighWaterMarkandwriteBufferLowWaterMarksettings could allow the server to delay pauses at the expense of direct memory and therefore allow more requests to be handled by freeing those query execution threads. -
Client applications should be selective in their retries. Quickly resending a query that triggered an
OutOfDirectMemoryErrorwithout giving the server time to recover will just further burden a taxed system. Even retry systems that use exponential back-off may not be suitable for these cases as early retries may land too quickly and therefore just queue another heavy request. -
Consider the shape of query results as they can have an impact on server performance. The "shape" refers to the form of the result given the query. For example,
g.V()andg.V().fold()both return the same results (i.e. all the vertices in the graph) but the former returns them one at a time in a stream and the latter collects them all in memory in aListand then returns the oneListresult. Writing queries in ways that allow results that can stream (only applies for websockets) is preferable and will allow the server to perform better. Another aspect of "shape" can come into play when returning data of individual graph elements. For example, theg.V()form of query will stream, but if eachVertexreturned has lots of properties (e.g. properties with large strings or heavy blobs), this could trigger scenarios where each streamed batch immediately exceedswriteBufferHighWaterMark. Simply exceeding thewriteBufferHighWaterMarkmay not trigger a pause as the server may quickly flush the buffer before the next batch, but one could see how easily a write pause could be triggered in that state. It could make sense to configure a smallerbatchSizefor queries results that have heavy individual objects in them as that would reduce the byte size of the batch and allow buffer flushes to happen more often (though that may be a cost in and of itself).
-
Parameterized Scripts
 If using
If using GremlinGroovyScriptEngine in Gremlin
Server, it is imperative to use script parameterization. Period. There are at least two good
reasons for doing so: script caching and protection from "Gremlin injection" (conceptually the same as the notion of
SQL injection).
|
Important
|
It is possible to use the GremlinLangScriptEngine in Gremlin Server as opposed to the
GremlinGroovyScriptEngine. The former makes use of gremlin-language and its ANTLR grammar for parsing Gremlin
scripts. This processing is different from the processing performed by Groovy and therefore spares users from the
concerns of this section. When considering parameterization, users should also consider the graph database they are
using to determine if it has native mechanisms that preclude the need for parameterization.
|
With respect to caching, Gremlin Server caches all scripts that are passed to it. The cache is keyed based on the
hash of the script. Therefore g.V(1) and g.V(2) will be recognized as two separate scripts in the cache. If that
script is parameterized to g.V(x) where x is passed as a parameter from the client, there will be no additional
compilation cost for future requests on that script. Compilation of a script should be considered "expensive" and
avoided when possible.
|
Important
|
The parameterized script of g.V(x) is keyed in the cache differently than g.V(y) or even g.V( x ).
Scripts must be exact string matches for recompilation to be avoided.
|
Cluster cluster = Cluster.open();
Client client = cluster.connect();
Map<String,Object> params = new HashMap<>();
params.put("x",4);
client.submit("[1,2,3,x]", params);The more parameters that are used in a script the more expensive the compilation step becomes. Gremlin Server has a
OpProcessor setting called maxParameters, which is mentioned in the OpProcessor Configuration
section. It controls the maximum number of parameters that can be passed to the server for script evaluation purposes.
Use of this setting can prevent accidental long run compilations, which individually are not terribly oppressive to
the server, but taken as a group under high concurrency would be considered detrimental.
On the topic of Gremlin injection, note that it is possible to take advantage of Gremlin scripts in the same fashion as SQL scripts that are submitted as strings. When using string building patterns for queries without proper input scrubbing, it would be quite simple to do:
String lbl = "person"
String nodeId = "mary').next();g.V().drop().iterate();g.V().has('id', 'thomas";
String query = "g.addV('" + lbl + "').property('identifier','" + nodeId + "')";
client.submit(query);The above case would drop() all vertices in the graph. By using script parameterization, there is a different outcome
in that the nodeId string is not treated as something executable, but rather as a literal string that just becomes
part of the "identifier" for the vertex on insertion:
String lbl = "person"
String nodeId = "mary').next();g.V().drop().iterate();g.V().has('id', 'thomas";
String query = "g.addV(lbl).property('identifier',nodeId)";
Map<String,Object> params = new HashMap<>();
params.put("lbl",lbl);
params.put("nodeId",nodeId);
client.submit(query, params);Groovy scripts create classes which get loaded to the JVM metaspace and to a Class cache. For those using script
parameterization, a typical application should not generate an overabundance of pressure on these two components of
Gremlin Server’s memory footprint. On the other hand, it’s not too hard to imagine a situation where problems might
emerge:
-
An application use case makes parameterization impossible and therefore all scripts are unique.
-
There is a bug in an applications parameterization code that is actually instead producing unique scripts.
-
A long running Gremlin Server takes lots of non-parameterized scripts from Gremlin Console or similar tools.
In these sorts of cases, Gremlin Server’s performance can be affected adversely as without some additional configuration the metaspace will grow indefinitely (possibly along with the general heap) triggering longer and more frequent rounds of garbage collection (GC). Some tuning of JVM settings can help abate this issue.
As a first guard against this problem consider setting the -XX:SoftRefLRUPolicyMSPerMB to release soft references
earlier. The ScriptEngine cache for created Class objects uses soft references and if the workload expectation is
such that cache hits will be low there is little need to keep such references around.
Perhaps the more important guards are related to the JVM metaspace. Start by setting the initial size of this space
with -XX:MetaspaceSize. When this value is exceeded it will trigger a GC round - it is essentially a threshold for
GC. The growth of this value can be capped with -XX:MaxMetaspaceSize (this value is unlimited by default). In an ideal
situation (i.e. parameterization), the -XX:MetaspaceSize should have a large enough setting so as to avoid early GC
rounds for metaspace, but outside of an ideal world (i.e. non-parameterization) it may not be smart to make this number
too large. Making the setting too large (and thus the -XX:MaxMetaspaceSize even larger) may trigger longer GC rounds
when they inevitably arrive.
In addition to those two metaspace settings it may also be useful to consider the following additional options:
-
MinMetaspaceFreeRatio- When the percentage for committed space available for class metadata is less than this value, then the threshold of metaspace GC will be raised, but only if the incremental size of the threshold meets the requirement set byMinMetaspaceExpansion. A larger number should make the metaspace grow more aggressively. -
MaxMetaspaceFreeRatio- When the percentage for committed space available for class metadata is more than this value, then the threshold of metaspace GC will be lowered, but only if the incremental size of the threshold meets the requirement set byMaxMetaspaceExpansion. A larger number should reduce the chance of the metaspace shrinking. -
MinMetaspaceExpansion- The minimum size by which the metaspace is expanded after a metaspace GC round. -
MaxMetaspaceExpansion`- If the incremental size exceedsMinMetaspaceExpansionbut less thanMaxMetaspaceExpansion, then the incremental size isMaxMetaspaceExpansion. If the incremental size exceedsMaxMetaspaceExpansion, then the incremental size isMinMetaspaceExpansionplus the original incremental size.
There really aren’t any general guidelines for how to initially set these values. Using profiling tools to examine GC trends is likely the best way to understand how a particular workload is affecting the metaspace and its relation to GC. Getting these settings "right" however will help ensure much more predictable Gremlin Server operations.
Properties of Elements
It was mentioned above at the start of this "Best Practices" section that serialization of graph elements (i.e.
Vertex, Edge, and VertexProperty) can be expensive and that it is best to only return the data that is required
by the requesting system. This point begs for further clarification as there are a number of ways to use and configure
Gremlin Server which might influence its interpretation.
To begin to discuss these nuances, first consider the method of making requests to Gremlin Server: script or traversal. For scripts, that will mean that users are sending string representation of Gremlin to the server directly through a driver or over HTTP. For bytecode, users will be utilize a Gremlin GLV which will construct bytecode for them and submit the request to the server upon iteration of their traversal.
In either case, it is important to also consider the method of "detachment". Detachment refers to the manner in which a graph element is disconnected from the graph for purpose of serialization. Depending on the case and configuration, graph elements may be detached with or without properties. Cases where they include properties is generally referred to as "detached elements" and cases where properties are not included are "reference elements".
With the type of request and detachment model in mind, it is now possible to discuss how best to consider element properties in relation to them all in concert.
By default, Gremlin Server configuration returns all properties.
To manage properties for each request you can use the with() configuration option
materializeProperties
g.with('materializeProperties', 'tokens').V()The tokens value for the materializeProperties means that only id and label should be returned.
Another option, all, can be used to indicate that all properties should be returned and is the default value.
In some cases it can be inconvenient to load Elements with properties due to large data size or for compatibility reasons.
That can be solved by utilizing ReferenceElementStrategy when creating the out-of-the-box GraphTraversalSource.
As the name suggests, this means that elements will be detached by reference and will therefore not have properties
included. The relevant configuration from the Gremlin Server initialization script looks like this:
globals << [g : traversal().with(graph).withStrategies(ReferenceElementStrategy)]This configuration is global to Gremlin Server and therefore all methods of connection will always return elements without properties. If this strategy is not included, then elements will be returned with properties.
Ultimately, the detachment model should have little impact to Gremlin usage if the best practice of specifying only the data required by the application is adhered to.
The best practice of requesting only the data the application needs:
Cluster cluster = Cluster.open();
Client client = cluster.connect();
ResultSet results = client.submit("g.V().hasLabel('person').elementMap('name')");
GraphTraversalSource g = traversal().with('conf/remote-graph.properties');
List<Vertex> results = g.V().hasLabel("person").elementMap('name').toList();Both of the above requests return a list of Map instances that contain the id, label and the "name" property.
Compatibility
It is not recommended to use 3.6.x or below driver versions with 3.7.x or above Gremlin Server, as some older drivers do not construct
graph elements with properties and thus are not designed to handle the returned properties by default; however, compatibility
can be achieved by configuring ReferenceElementStrategy in the server such that properties are not returned.
Per-request configuration option materializeProperties is not supported older driver versions.
Also note that older drivers of different language variants will handle incoming properties differently with different
serializers used. Drivers using GraphSON serializers will remain compatible, but may encounter deserialization errors
with GraphBinary. Below is a table documenting GLV behaviors using GraphBinary when properties are returned by the
default 3.7.x server, as well as if ReferenceElementStrategy is configured (i.e. mimic the behavior
of a 3.6.x server). This can be observed with the results of g.V().next(). Note that only gremlin-driver
and gremlin-javacript have the properties attribute in the Element objects, all other GLVs only have id and label.
3.6.x drivers with GraphBinary |
Behavior with default 3.7.x Server | Behavior with ReferenceElementStrategy |
|---|---|---|
|
Properties returned as empty iterator |
Properties returned as empty iterator |
|
Skips properties in Elements |
Skips properties in Elements |
|
Deserialization error |
Properties returned as empty list |
|
Deserialization error |
Skips properties in Elements |
|
Deserialization error |
Skips properties in Elements |
|
Tip
|
Consider utilizing ReferenceElementStrategy whenever creating a GraphTraversalSource in Java to ensure
the most portable Gremlin.
|
|
Note
|
For those interested, please see this post to the TinkerPop dev list which outlines the full history of this issue and related concerns. |
Cache Management
If Gremlin Server processes a large number of unique scripts, the global function cache will grow beyond the memory
available to Gremlin Server and an OutOfMemoryError will loom. Script parameterization goes a long way to solving
this problem and running out of memory should not be an issue for those cases. If it is a problem or if there is no
script parameterization due to a given use case, it is possible to better control the nature of the global function
cache from the client side, by issuing scripts with a parameter to help define how the garbage collector should treat
the references.
The parameter is called #jsr223.groovy.engine.keep.globals and has four options:
-
hard- available in the cache for the life of the JVM (default when not specified). -
soft- retained until memory is "low" and should be reclaimed before anOutOfMemoryErroris thrown. -
weak- garbage collected even when memory is abundant. -
phantom- removed immediately after being evaluated by theScriptEngine.
By specifying an option other than hard, an OutOfMemoryError in Gremlin Server should be avoided. Of course,
this approach will come with the downside that functions could be garbage collected and thus removed from the
cache, forcing Gremlin Server to recompile later if that script is later encountered.
Cluster cluster = Cluster.open();
Client client = cluster.connect();
Map<String,Object> params = new HashMap<>();
params.put("#jsr223.groovy.engine.keep.globals", "soft");
client.submit("def addItUp(x,y){x+y}", params);In cases where maintaining the expense of the global function cache is unecessary this cache can be disabled with the
globalFunctionCacheEnabled configuration on the GroovyCompilerGremlinPlugin.
Gremlin Server also has a "class map" cache which holds compiled scripts which helps avoid recompilation costs on
future requests. This cache can be tuned in the Gremlin Server configuration with the GroovyCompilerGremlinPlugin
in the following fashion:
scriptEngines: {
gremlin-groovy: {
plugins: { ...
org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyCompilerGremlinPlugin: {classMapCacheSpecification: "initialCapacity=1000,maximumSize=10000"},
...}The specifics for this comma delimited format can be found
here.
By default, the cache is set to softValues which means they are garbage collected in a globally least-recently-used
manner as memory gets low. For production systems, it is likely that a more predictable strategy be taken as shown
above with the use of the maximumSize.
Considering Transactions
Gremlin Server performs automated transaction handling for "sessionless" requests (i.e. no state between requests) and for "in-session" requests with that feature enabled. It will automatically commit or rollback transactions depending on the success or failure of the request.
Another aspect of Transaction Management that should be considered is the usage of the strictTransactionManagement
setting. It is false by default, but when set to true, it forces the user to pass aliases for all requests.
The aliases are then used to determine which graphs will have their transactions closed for that request. Running
Gremlin Server in this configuration should be more efficient when there are multiple graphs being hosted as
Gremlin Server will only close transactions on the graphs specified by the aliases. Keeping this setting false,
will simply have Gremlin Server close transactions on all graphs for every request.
Request Retry
The server has the ability to instruct the client that an error condition is transient and that the client should
simply retry the request later. In the event a client detects a ResponseStatusCode of SERVER_ERROR_TEMPORARY,
which is error code 596, the client may choose to retry that request. Note that drivers do not have the ability to
automatically retry and that it is up to the application to provide such logic.
Docker Image
The Gremlin Server can also be started as a Docker image:
$ docker run tinkerpop/gremlin-server:4.0.0-SNAPSHOT
[INFO] GremlinServer -
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server.yaml
...
[INFO] GremlinServer$1 - Gremlin Server configured with worker thread pool of 1, gremlin pool of 4 and boss thread pool of 1.
[INFO] GremlinServer$1 - Channel started at port 8182.By default, Gremlin Server listens on port 8182. So that port needs to be exposed if it should be reachable on the host:
$ docker run -p 8182:8182 tinkerpop/gremlin-server:4.0.0-SNAPSHOTArguments provided with docker run are forwarded to the script that starts Gremlin Server. This allows for example
to use an alternative config file:
$ docker run tinkerpop/gremlin-server:4.0.0-SNAPSHOT conf/gremlin-server-secure.yamlGremlin Plugins

Plugins provide a way to expand the features of Gremlin Console and Gremlin Server. The following sections describe the plugins that are available directly from TinkerPop. Please see the Provider Documentation for information on how to develop custom plugins.
Credentials Plugin
Gremlin Server supports an authentication model
where user credentials are stored inside of a Graph instance. This database can be managed with the
Credentials DSL, which can be installed in the console via the Credentials Plugin. This plugin
is packaged with the console, but is not enabled by default.
gremlin> :plugin use tinkerpop.credentials
==>tinkerpop.credentials activatedThis plugin imports the appropriate classes for managing the credentials graph.
Graph Plugins
This section does not refer to a specific Gremlin Plugin, but a class of them. Graph Plugins are typically created by
graph providers to make it easy to integrate their graph systems into Gremlin Console and Gremlin Server. As TinkerPop
provides two reference Graph implementations in TinkerGraph and Neo4j,
there is also one Gremlin Plugin for each of them.
The TinkerGraph plugin is installed and activated in the Gremlin Console by default and the sample configurations that
are supplied with the Gremlin Server distribution include the TinkerGraphGremlinPlugin as part of the default setup.
If using Neo4j, however, the plugin must be installed manually. Instructions for doing so can be found in the
Neo4j section.
Hadoop Plugin
![]() The Hadoop Plugin installs as part of
The Hadoop Plugin installs as part of hadoop-gremlin and provides
a number of imports and utility functions to the environment within which it is used. Those classes and functions
provide the basis for supporting OLAP based traversals with Gremlin. This plugin is defined in
greater detail in the Hadoop-Gremlin section.
Server Plugin
Gremlin Server remotely executes Gremlin scripts
that are submitted to it. The Server Plugin provides a way to submit scripts to Gremlin Server for remote
processing. Read more about the plugin and how it works in the Gremlin Server section on
Connecting via Console.
|
Note
|
This plugin is typically only useful to the Gremlin Console and is enabled in the there by default. |
The Server Plugin for remoting with the Gremlin Console should not be confused with a plugin of similar name that is
used by the server. GremlinServerGremlinPlugin is typically only configured in Gremlin Server and provides a number
of imports that are required for writing initialization scripts.
Spark Plugin
![]() The Spark Plugin installs as part of
The Spark Plugin installs as part of spark-gremlin and provides
a number of imports and utility functions to the environment within which it is used. Those classes and functions
provide the basis for supporting OLAP based traversals using Spark.
This plugin is defined in greater detail in the SparkGraphComputer section and is typically
installed in conjuction with the Hadoop-Plugin.
Sugar Plugin
 In previous versions of Gremlin-Groovy, there were numerous
syntactic sugars that users could rely on to make their traversals
more succinct. Unfortunately, many of these conventions made use of Java reflection
and thus, were not performant. In TinkerPop, these conveniences have been removed in support of the standard
Gremlin-Groovy syntax being both inline with Gremlin-Java syntax as well as always being the most performant
representation. However, for those users that would like to use the previous syntactic sugars (as well as new ones),
there is
In previous versions of Gremlin-Groovy, there were numerous
syntactic sugars that users could rely on to make their traversals
more succinct. Unfortunately, many of these conventions made use of Java reflection
and thus, were not performant. In TinkerPop, these conveniences have been removed in support of the standard
Gremlin-Groovy syntax being both inline with Gremlin-Java syntax as well as always being the most performant
representation. However, for those users that would like to use the previous syntactic sugars (as well as new ones),
there is SugarGremlinPlugin (a.k.a Gremlin-Groovy-Sugar).
|
Important
|
It is important that the sugar plugin is loaded in a Gremlin Console session prior to any manipulations of the respective TinkerPop objects as Groovy will cache unavailable methods and properties. |
gremlin> :plugin use tinkerpop.sugar
==>tinkerpop.sugar activated|
Tip
|
When using Sugar in a Groovy class file, add static { SugarLoader.load() } to the head of the file. Note that
SugarLoader.load() will automatically call GremlinLoader.load().
|
Graph Traversal Methods
If a GraphTraversal property is unknown and there is a corresponding method with said name off of GraphTraversal
then the property is assumed to be a method call. This enables the user to omit ( ) from the method name. However,
if the property does not reference a GraphTraversal method, then it is assumed to be a call to values(property).
gremlin> g.V //// (1)
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V.name //// (2)
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V.outE.weight //// (3)
==>0.4
==>0.5
==>1.0
==>1.0
==>0.4
==>0.2g.V //// (1)
g.V.name //// (2)
g.V.outE.weight //3-
There is no need for the parentheses in
g.V(). -
The traversal is interpreted as
g.V().values('name'). -
A chain of zero-argument step calls with a property value call.
Range Queries
The [x] and [x..y] range operators in Groovy translate to RangeStep calls.
gremlin> g.V[0..2]
==>v[1]
==>v[2]
gremlin> g.V[0..<2]
==>v[1]
gremlin> g.V[2]
==>v[3]g.V[0..2]
g.V[0..<2]
g.V[2]Logical Operators
The & and | operator are overloaded in SugarGremlinPlugin. When used, they introduce the AndStep and OrStep
markers into the traversal. See and() and or() for more information.
gremlin> g.V.where(outE('knows') & outE('created')).name //// (1)
==>marko
gremlin> t = g.V.where(outE('knows') | inE('created')).name; null //// (2)
==>null
gremlin> t.toString()
==>[GraphStep(vertex,[]), TraversalFilterStep([VertexStep(OUT,[knows],edge), OrStep, VertexStep(IN,[created],edge)]), PropertiesStep([name],value)]
gremlin> t
==>marko
==>lop
==>ripple
gremlin> t.toString()
==>[TinkerGraphStep(vertex,[]), OrStep([[VertexStep(OUT,[knows],edge)], [VertexStep(IN,[created],edge)]]), PropertiesStep([name],value)]g.V.where(outE('knows') & outE('created')).name //// (1)
t = g.V.where(outE('knows') | inE('created')).name; null //// (2)
t.toString()
t
t.toString()-
Introducing the
AndStepwith the&operator. -
Introducing the
OrStepwith the|operator.
Traverser Methods
It is rare that a user will ever interact with a Traverser directly. However, if they do, some method redirects exist
to make it easy.
gremlin> g.V().map{it.get().value('name')} // conventional
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V.map{it.name} // sugar
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peterg.V().map{it.get().value('name')} // conventional
g.V.map{it.name} // sugarUtilities Plugin
The Utilities Plugin provides various functions, helper methods and imports of external classes that are useful in the console.
|
Note
|
The Utilities Plugin is enabled in the Gremlin Console by default. |
Describe Graph
A good implementation of the Gremlin APIs will validate their features against the
Gremlin test suite. To learn more about a specific
implementation’s compliance with the test suite, use the describeGraph function. The following shows the output
for HadoopGraph:
gremlin> describeGraph(HadoopGraph)
==>
IMPLEMENTATION - org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
TINKERPOP TEST SUITE
- Compliant with (5 of 4 suites)
- Compliant with (5 of 11 suites)
> org.apache.tinkerpop.gremlin.structure.StructureStandardSuite
> org.apache.tinkerpop.gremlin.process.ProcessStandardSuite
> org.apache.tinkerpop.gremlin.process.ProcessComputerSuite
> org.apache.tinkerpop.gremlin.process.ProcessLimitedStandardSuite
> org.apache.tinkerpop.gremlin.process.ProcessLimitedComputerSuite
- Opts out of 17 individual tests
> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_both_both_count
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_repeatXoutX_timesX3X_count
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_repeatXoutX_timesX8X_count
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.CountTest$Traversals#g_V_repeatXoutX_timesX5X_asXaX_outXwrittenByX_asXbX_selectXa_bX_count
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.ProfileTest$Traversals#grateful_V_out_out_profile
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.ProfileTest$Traversals#grateful_V_out_out_profileXmetricsX
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_hasLabelXsongX_groupXaX_byXnameX_byXproperties_groupCount_byXlabelXX_out_capXaX
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_outXfollowedByX_group_byXsongTypeX_byXbothE_group_byXlabelX_byXweight_sumXX
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_repeatXbothXfollowedByXX_timesX2X_group_byXsongTypeX_byXcountX
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.traversal.step.sideEffect.GroupTest#g_V_repeatXbothXfollowedByXX_timesX2X_groupXaX_byXsongTypeX_byXcountX_capXaX
"Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute."
> org.apache.tinkerpop.gremlin.process.computer.GraphComputerTest#shouldStartAndEndWorkersForVertexProgramAndMapReduce
"Spark executes map and combine in a lazy fashion and thus, fails the blocking aspect of this test"
> org.apache.tinkerpop.gremlin.process.traversal.TraversalInterruptionTest#*
"The interruption model in the test can't guarantee interruption at the right time with HadoopGraph."
> org.apache.tinkerpop.gremlin.process.traversal.TraversalInterruptionComputerTest#*
"This test makes use of a sideEffect to enforce when a thread interruption is triggered and thus isn't applicable to HadoopGraph"
> org.apache.tinkerpop.gremlin.process.traversal.step.map.ReadTest$Traversals#g_io_readXxmlX
"Hadoop-Gremlin does not support reads/writes with GraphML."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.ReadTest$Traversals#g_io_read_withXreader_graphmlX
"Hadoop-Gremlin does not support reads/writes with GraphML."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.WriteTest$Traversals#g_io_writeXxmlX
"Hadoop-Gremlin does not support reads/writes with GraphML."
> org.apache.tinkerpop.gremlin.process.traversal.step.map.WriteTest$Traversals#g_io_write_withXwriter_graphmlX
"Hadoop-Gremlin does not support reads/writes with GraphML."
- NOTE -
The describeGraph() function shows information about a Graph implementation.
It uses information found in Java Annotations on the implementation itself to
determine this output and does not assess the actual code of the test cases of
the implementation itself. Compliant implementations will faithfully and
honestly supply these Annotations to provide the most accurate depiction of
their support.describeGraph(HadoopGraph)Gremlin Drivers and Variants

At this point, readers should be well familiar with the Introduction to this Reference Documentation and will likely be thinking about implementation details specific to the graph provider they have selected as well as the programming language they intend to use. The choice of programming language could have implications to the architecture and design of the application and the choice itself may have limits imposed upon it by the chosen graph provider. For example, a Remote Gremlin Provider will require the selection of a driver to interact with it. On the other hand, a graph system that is designed for embedded use, like TinkerGraph, needs the Java Virtual Machine (JVM) environment which is easily accessed with a JVM programming language. If however the programming language is not built for the JVM then it will require Gremlin Server in the architecture as well.
TinkerPop provides an array of drivers in different programming languages as a way to connect to a remote Gremlin Server or Remote Gremlin Provider. Drivers allow the developer to make requests to that remote system and get back results from the TinkerPop-enabled graphs hosted within. A driver can submit Gremlin strings and Gremlin traversals over this HTTP protocol. Gremlin strings are written in the scripting language made available by the remote system that the driver is connecting to (typically, Groovy-based). This connection approach is quite similar to what developers are likely familiar with when using JDBC and SQL.
The preferred approach is to use traversal-based requests, which essentially allows the ability to craft Gremlin directly in the programming language of choice. As Gremlin makes use of two fundamental programming constructs: function composition and function nesting, it is possible to embed the Gremlin language in any modern programming language. It is a far more natural way to program, because it enables IDE interaction, compile time checks, and language level checks that can help prevent errors prior to execution. The differences between these two approaches were outlined in the Connecting Via Drivers Section, which applies to Gremlin Server, but also to Remote Gremlin Providers.
In addition to the languages and drivers that TinkerPop supports, there are also third-party implementations, as well as extensions to the Gremlin language that might be specific to a particular graph provider. That listing can be found on the TinkerPop home page. Their description is beyond the scope of this documentation.
|
Tip
|
When possible, it is typically best to align the version of TinkerPop used on the client with the version supported on the server. While it is not impossible to have a different version between client and server, it may require additional configuration and/or a deeper knowledge of that changes introduced between versions. It’s simply safer to avoid the conflict, when allowed to do so. |
|
Important
|
Gremlin-Java is the canonical representation of Gremlin and any (proper) Gremlin language variant will emulate its structure as best as possible given the constructs of the host language. A strong correspondence between variants ensures that the general Gremlin reference documentation is applicable to all variants and that users moving between development languages can easily adopt the Gremlin variant for that language. |

The following sections describe each language variant and driver that is officially TinkerPop a part of the project, providing more detailed information about usage, configuration and known limitations.
Gremlin-Go
|
Important
|
4.0 Milestone Release - Gremlin-Go is not available in this milestone, please consider testing with Java or Python. |
 Apache TinkerPop’s Gremlin-Go implements Gremlin within the Go language and can therefore be used on different operating systems. Go’s syntax has the similar constructs as Java including
"dot notation" for function chaining (
Apache TinkerPop’s Gremlin-Go implements Gremlin within the Go language and can therefore be used on different operating systems. Go’s syntax has the similar constructs as Java including
"dot notation" for function chaining (a.b.c) and round bracket function arguments (a(b,c)). Something unlike Java is that Gremlin-Go requires a
gremlingo prefix when using the namespace (a(b()) vs gremlingo.a(gremlingo.T__.b())). Anyone familiar with Gremlin-Java will be able to work
with Gremlin-Go with relative ease. Moreover, there are a few added constructs to Gremlin-Go that make traversals a bit more
succinct.
To install the Gremlin-Go as a dependency for your project, run the following in the root directory of your project that contains your go.mod file:
go get github.com/apache/tinkerpop/gremlin-go/v3[optionally append @<version>, such as @v3.5.3]Connecting
The pattern for connecting is described in Connecting Gremlin and it basically distills down to
creating a GraphTraversalSource. A GraphTraversalSource is created from the anonymous Traversal_().
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin")
g := gremlingo.Traversal_().With(remote)If you need to additional parameters to connection setup, you can pass in a configuration function.
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin",
func(settings *DriverRemoteConnectionSettings) {
settings.TraversalSource = "gmodern"
})Gremlin-go supports plain text authentication. It can be set in the connection function.
remote, err := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin",
func(settings *DriverRemoteConnectionSettings) {
settings.TlsConfig = &tls.Config{InsecureSkipVerify: true}
settings.AuthInfo = gremlingo.BasicAuthInfo("login", "password")
})If you authenticate to a remote Gremlin Server or Remote Gremlin Provider, this server normally has SSL activated and the websockets url will start with 'wss://'.
Some connection options can also be set on individual requests made through the using With() step on the
TraversalSource. For instance to set request timeout to 500 milliseconds:
results, err := g.With("evaluationTimeout", 500).V().Out("knows").ToList()The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent and
evaluationTimeout.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following import provide most of the typical functionality required to use Gremlin:
import (
"github.com/apache/tinkerpop/gremlin-go/driver"
)These can be used analogously to how they are used in Gremlin-Java.
results, err := g.V().HasLabel("person").Has("age", gremlingo.T__.Is(gremlingo.P.Gt(30))).Order().By("age", gremlingo.Desc).ToList()
[v[6], v[4]]Configuration
The following table describes the various configuration options for the Gremlin-go Driver. They
can be passed to the NewClient or NewDriverRemoteConnection functions as configuration function arguments:
| Key | Description | Default |
|---|---|---|
TraversalSource |
Traversal source. |
"g" |
TransporterType |
Transporter type. |
Gorilla |
LogVerbosity |
Log verbosity. |
gremlingo.INFO |
Logger |
Instance of logger. |
log |
Language |
Language used for logging messages. |
language.English |
AuthInfo |
Authentification info, can be build with BasicAuthInfo() or HeaderAuthInfo(). |
empty |
TlsConfig |
TLS configuration. |
empty |
KeepAliveInterval |
Keep connection alive interval. |
5 seconds |
WriteDeadline |
Write deadline. |
3 seconds |
ConnectionTimeout |
Timeout for establishing connection. |
45 seconds |
NewConnectionThreshold |
Minimum amount of concurrent active traversals on a connection to trigger creation of a new connection. |
4 |
MaximumConcurrentConnections |
Maximum number of concurrent connections. |
number of runtime processors |
EnableCompression |
Flag to enable compression. |
false |
ReadBufferSize |
Specify I/O buffer sizes in bytes. If a buffer size is zero, then a useful default size is used |
0 |
WriteBufferSize |
Specify I/O buffer sizes in bytes. If a buffer size is zero, then a useful default size is used |
0 |
Session |
Session ID. |
"" |
EnableUserAgentOnConnect |
Enables sending a user agent to the server during connection requests. More details can be found in provider docs here. |
true |
Traversal Strategies
In order to add and remove traversal strategies from a traversal source, Gremlin-Go has a
TraversalStrategy interface along with a collection of functions that mirror the standard Gremlin-Java strategies.
promise := g.WithStrategies(gremlingo.ReadOnlyStrategy()).AddV("person").Property("name", "foo").Iterate()|
Note
|
Many of the TraversalStrategy classes in Gremlin-Go are proxies to the respective strategy on
Apache TinkerPop’s JVM-based Gremlin traversal machine. As such, their apply(Traversal) method does nothing. However,
the strategy is encoded in the Gremlin-Go bytecode and transmitted to the Gremlin traversal machine for
re-construction machine-side.
|
Transactions
To get a full understanding of this section, it would be good to start by reading the Transactions section of this documentation, which discusses transactions in the general context of TinkerPop itself. This section builds on that content by demonstrating the transactional syntax for Go.
remote, err := NewDriverRemoteConnection("ws://localhost:8182/gremlin")
g := gremlingo.Traversal_().With(remote)
// Create a Transaction.
tx := g.Tx()
// Spawn a new GraphTraversalSource, binding all traversals established from it to tx.
gtx, _ := tx.Begin()
// Execute a traversal within the transaction.
promise := g.AddV("person").Property("name", "Lyndon").Iterate()
err := <-promise
if err != nil {
// Rollback the transaction if an error occurs.
tx.rollback()
} else {
// Commit the transaction. The transaction can no longer be used and cannot be re-used.
// A new transaction can be spawned through g.Tx().
tx.Commit()
}The Lambda Solution
Supporting anonymous functions across languages is difficult as
most languages do not support lambda introspection and thus, code analysis. In Gremlin-Go, a Gremlin lambda should
be represented as a zero-arg callable that returns a string representation of the lambda expected for use in the
traversal. The lambda should be written as a Gremlin-Groovy string. When the lambda is represented in Bytecode its
language is encoded such that the remote connection host can infer which translator and ultimate execution engine to
use.
r, err := g.V().Out().Map(&gremlingo.Lambda{Script: "it.get().value('name').length()", Language: ""}).Sum().ToList()|
Tip
|
When running into situations where Groovy cannot properly discern a method signature based on the Lambda
instance created, it will help to fully define the closure in the lambda expression - so rather than
Script: "it.get().value('name')", Language: "gremlin-groovy", prefer Script: "x → x.get().value('name')", Language: "gremlin-groovy".
|
Finally, Gremlin Bytecode that includes lambdas requires that the traversal be processed by the
ScriptEngine. To avoid continued recompilation costs, it supports the encoding of bindings, which allow a remote
engine to to cache traversals that will be reused over and over again save that some parameterization may change. Thus,
instead of translating, compiling, and then executing each submitted bytecode, it is possible to simply execute.
r, err := g.V((&gremlingo.Bindings{}).Of("x", 1)).Out("created").Map(&gremlingo.Lambda{Script: "it.get().value('name').length()", Language: ""}).Sum().ToList()
// 3
r, err := g.V((&gremlingo.Bindings{}).Of("x", 4)).Out("created").Map(&gremlingo.Lambda{Script: "it.get().value('name').length()", Language: ""}).Sum().ToList()
// 9|
Warning
|
As explained throughout the documentation, when possible avoid lambdas. |
Submitting Scripts
The Client class implementation/interface is based on the Java Driver, with some restrictions. Most notably,
Gremlin-go does not yet implement the Cluster class. Instead, Client is instantiated directly.
Usage is as follows:
import "github.com/apache/tinkerpop/gremlin-go/v3/driver" //1
client, err := gremlingo.NewClient("ws://localhost:8182/gremlin") //2-
Import the Gremlin-Go module.
-
Opens a reference to
localhost- note that there are various configuration options that can be passed to theClientobject upon instantiation as keyword arguments.
Once a Client instance is ready, it is possible to issue some Gremlin:
resultSet, err := client.Submit("g.V().count()") //1
result, err := resultSet.All() //2
fmt.Println(result[0].GetString()) //3-
Submit a script that simply returns a Count of vertexes.
-
Get results from resultSet. Block until the script is evaluated and results are sent back by the server.
-
Use the result.
Per Request Settings
Both the Client and DriverRemoteConnection types have a SubmitWithOptions(traversalString, requestOptions) variant
of the standard Submit() method. These methods allow a RequestOptions struct to be passed in which will augment the
execution on the server. RequestOptions can be constructed
using RequestOptionsBuilder. A good use-case for this feature is to set a per-request override to the
evaluationTimeout so that it only applies to the current request.
options := new(RequestOptionsBuilder).
SetEvaluationTimeout(5000).
SetBatchSize(32).
SetMaterializeProperties("tokens").
AddBinding("x", 100).
Create()
resultSet, err := client.SubmitWithOptions("g.V(x).count()", options)The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent, evaluationTimeout and materializeProperties.
RequestOptions may also contain a map of variable bindings to be applied to the supplied
traversal string.
|
Important
|
The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiar
with bytecode may try g.with("evaluationTimeout", 500) within a script. Scripts with multiple traversals and multiple
timeouts will be interpreted as a sum of all timeouts identified in the script for that request.
|
resultSet, err := client.SubmitWithOptions("g.with('evaluationTimeout', 500).addV().iterate();"+
"g.addV().iterate();"+
"g.with('evaluationTimeout', 500).addV();", new(RequestOptionsBuilder).SetEvaluationTimeout(500).Create())
results, err := resultSet.All()In the above example, defines a timeout of 500 milliseconds, but the script has three traversals with
two internal settings for the timeout using with(). The request timeout used by the server will therefore be 1000
milliseconds (overriding the 500 which itself was an override for whatever configuration was on the server).
Domain Specific Languages
Writing a Gremlin Domain Specific Language (DSL) in Go requires embedding of several structs and interfaces:
-
GraphTraversal- which exposes the various steps used in traversal writing -
GraphTraversalSource- which spawnsGraphTraversalinstances -
AnonymousTraversal- which spawns anonymous traversals from steps
The Social DSL based on the "modern" toy graph might look like this:
// Optional syntactic sugar.
var __ = gremlingo.T__
var P = gremlingo.P
var gt = gremlingo.P.Gt
// Optional alias for import convenience.
type GraphTraversal = gremlingo.GraphTraversal
type GraphTraversalSource = gremlingo.GraphTraversalSource
type AnonymousTraversal = gremlingo.AnonymousTraversal
// Embed Graph traversal inside custom traversal struct to add custom traversal functions.
// In go, capitalizing the first letter exports (makes public) the struct/method to outside of package, for this example
// we have defined everything package private. In actual usage, please see fit to your application.
type socialTraversal struct {
*GraphTraversal
}
func (s *socialTraversal) knows(personName string) *socialTraversal {
return &socialTraversal{s.Out("knows").HasLabel("person").Has("name", personName)}
}
func (s *socialTraversal) youngestFriendsAge() *socialTraversal {
return &socialTraversal{s.Out("knows").HasLabel("person").Values("age").Min()}
}
func (s *socialTraversal) createdAtLeast(number int) *socialTraversal {
return &socialTraversal{s.OutE("created").Count().Is(gt(number))}
}
// Add custom social traversal source to spaw custom traversals.
type socialTraversalSource struct {
*GraphTraversalSource
}
// Define the source step function by adding steps to the bytecode.
func (sts *socialTraversalSource) persons(personNames ...interface{}) *socialTraversal {
t := sts.GetGraphTraversal()
t.Bytecode.AddStep("V")
t.Bytecode.AddStep("hasLabel", "person")
if personNames != nil {
t.Bytecode.AddStep("has", "name", P.Within(personNames...))
}
return &socialTraversal{t}
}
// Create the social anonymous traversal interface to embed and extend the anonymous traversal functions.
type iSocialAnonymousTraversal interface {
AnonymousTraversal
knows(personName string) *GraphTraversal
youngestFriendsAge() *GraphTraversal
createdAtLeast(number int) *GraphTraversal
}
// Add the struct to implement the iSocialAnonymousTraversal interface.
type socialAnonymousTraversal struct {
AnonymousTraversal
socialTraversal func() *socialTraversal
}
// Add the variable s__ to call anonymous traversal step functions in place of __.
var s__ iSocialAnonymousTraversal = &socialAnonymousTraversal{
__,
func() *socialTraversal {
return &socialTraversal{gremlingo.NewGraphTraversal(nil, gremlingo.NewBytecode(nil), nil)}
},
}
// Extended anonymous traversal functions need to return GraphTraversal for serialization purposes
func (sat *socialAnonymousTraversal) knows(personName string) *GraphTraversal {
return sat.socialTraversal().knows(personName).GraphTraversal
}
func (sat *socialAnonymousTraversal) youngestFriendsAge() *GraphTraversal {
return sat.socialTraversal().youngestFriendsAge().GraphTraversal
}
func (sat *socialAnonymousTraversal) createdAtLeast(number int) *GraphTraversal {
return sat.socialTraversal().createdAtLeast(number).GraphTraversal
}Using the DSL requires a social traversal source to be created from the default traversal source:
// Creating the driver remote connection as regular.
driverRemoteConnection, _ := gremlingo.NewDriverRemoteConnection("ws://localhost:8182/gremlin",
func(settings *gremlingo.DriverRemoteConnectionSettings) {
settings.TraversalSource = "gmodern"
})
defer driverRemoteConnection.Close()
// Create social traversal source from graph traversal source.
social := &socialTraversalSource{gremlingo.Traversal_().With(driverRemoteConnection)}
// We can now use the social traversal source as well as traversal steps
resBool, _ := social.persons("marko", "stephen").knows("josh").HasNext()
fmt.Println(resBool)
// Using the createdAtLeast step.
resCreated, _ := social.persons().createdAtLeast(1).Next()
fmt.Println(resCreated.GetString())
// Using the social anonymous traversal.
resAnon, _ := social.persons().Filter(s__.createdAtLeast(1)).Count().Next()
fmt.Println(resAnon.GetString())
// Note that error handling has been omitted with _ from the above examples.Differences
In situations where Go reserved words and global functions overlap with standard Gremlin steps and tokens, those bits of conflicting Gremlin get an underscore appended as a suffix. In addition, all function names start with a capital letter in order to be public:
Steps - And(), As(), Filter(), From(), Id(), Is(), In(), Max(), Min(), Not(), Or(), Range(), Sum(), With()
Tokens - Scope.Global, Scope.Local
Aliases
To make the code more readable and close to the Gremlin query language), you can use aliases. These aliases can be named with capital letters to be consistent with non-aliased steps but will result in exported variables which could be problematic if not being used in a top-level program (i.e. not a redistributable package).
var __ = gremlingo.T__
var gt = gremlingo.P.Gt
var order = gremlingo.Order
results, err := g.V().HasLabel("person").Has("age", __.Is(gt(30))).Order().By("age", order.Desc).ToList()List of useful aliases
// common
var __ = gremlingo.T__
var TextP = gremlingo.TextP
// predicates
var between = gremlingo.P.Between
var eq = gremlingo.P.Eq
var gt = gremlingo.P.Gt
var gte = gremlingo.P.Gte
var inside = gremlingo.P.Inside
var lt = gremlingo.P.Lt
var lte = gremlingo.P.Lte
var neq = gremlingo.P.Neq
var not = gremlingo.P.Not
var outside = gremlingo.P.Outside
var test = gremlingo.P.Test
var within = gremlingo.P.Within
var without = gremlingo.P.Without
var and = gremlingo.P.And
var or = gremlingo.P.Or
// sorting
var order = gremlingo.OrderFinally, the enum construct for Cardinality cannot have functions attached to it the way it can be done in Java,
therefore cardinality functions that take a value like list(), set(), and single() are referenced from a
CardinalityValue class rather than Cardinality itself.
Limitations
-
There is no default
settype in Go. Any set type code from server will be deserialized into slices with the list type implementation. To input a set into Gremlin-Go, a custom struct which implements thegremlingo.Setinterface will be serialized as a set.gremlingo.NewSimpleSetis a basic implementation of a set that is provided by Gremlin-Go that can be used to fulfill thegremlingo.Setinterface if desired.
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Go. They
can be found in GitHub here
and are designed to connect to a running Gremlin Server configured with the
conf/gremlin-server.yaml and conf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration file
conf/gremlin-server.yaml. To start a clean server, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, using conf/gremlin-server-modern.yaml.
To start a server with the Modern graph preloaded, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlEach example can now be run with the following commands:
go run connections.go
go run basic_gremlin.go
go run modern_traversals.goGremlin-Groovy
 Apache TinkerPop’s Gremlin-Groovy implements Gremlin within the
Apache Groovy language. As a JVM-based language variant, Gremlin-Groovy is backed by
Gremlin-Java constructs. Moreover, given its scripting nature, Gremlin-Groovy serves as the language of
Gremlin Console and Gremlin Server.
Apache TinkerPop’s Gremlin-Groovy implements Gremlin within the
Apache Groovy language. As a JVM-based language variant, Gremlin-Groovy is backed by
Gremlin-Java constructs. Moreover, given its scripting nature, Gremlin-Groovy serves as the language of
Gremlin Console and Gremlin Server.
compile group: 'org.apache.tinkerpop', name: 'gremlin-core', version: '4.0.0-SNAPSHOT'
compile group: 'org.apache.tinkerpop', name: 'gremlin-driver', version: '4.0.0-SNAPSHOT'Differences
In Groovy, as, in, and not are reserved words. Gremlin-Groovy does not allow these steps to be called
statically from the anonymous traversal __ and therefore, must always be prefixed with __. For instance:
g.V().as('a').in().as('b').where(__.not(__.as('a').out().as('b')))
Care needs to be taken when using the any(P) step as you may accidentally invoke Groovy’s any(Closure) method. This
typically happens when calling any() without arguments. You can tell if Groovy’s any has been called if the return
value is a boolean.
Since Groovy has access to the full JVM as Java does, it is possible to construct Date-like objects directly, but
the Gremlin language does offer a datetime() function that is exposed in the Gremlin Console and as a function for
Gremlin scripts sent to Gremlin Server. The function accepts the following forms of dates and times using a default
time zone offset of UTC(+00:00):
-
2018-03-22 -
2018-03-22T00:35:44 -
2018-03-22T00:35:44Z -
2018-03-22T00:35:44.741 -
2018-03-22T00:35:44.741Z -
2018-03-22T00:35:44.741+1600
Gremlin-Java
 Apache TinkerPop’s Gremlin-Java implements Gremlin within the
Java language and can be used by any Java Virtual Machine. Gremlin-Java is considered the canonical, reference
implementation of Gremlin and serves as the foundation by which all other Gremlin language variants should emulate.
As the Gremlin Traversal Machine that processes Gremlin queries is also written in Java, it can be used in all three
connection methods described in the Connecting Gremlin Section.
Apache TinkerPop’s Gremlin-Java implements Gremlin within the
Java language and can be used by any Java Virtual Machine. Gremlin-Java is considered the canonical, reference
implementation of Gremlin and serves as the foundation by which all other Gremlin language variants should emulate.
As the Gremlin Traversal Machine that processes Gremlin queries is also written in Java, it can be used in all three
connection methods described in the Connecting Gremlin Section.
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>gremlin-core</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>
<!-- when using Gremlin Server or Remote Gremlin Provider a driver is required -->
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>gremlin-driver</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>
<!--
alternatively the driver is packaged as an uberjar with shaded non-optional dependencies including gremlin-core and
tinkergraph-gremlin which are not shaded.
-->
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>gremlin-driver</artifactId>
<version>4.0.0-SNAPSHOT</version>
<classifier>shaded</classifier>
<!-- The shaded JAR uses the original POM, therefore conflicts may still need resolution -->
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>Connecting
The pattern for connecting is described in Connecting Gremlin and it basically distills down
to creating a GraphTraversalSource. For embedded mode, this involves first creating a
Graph and then spawning the GraphTraversalSource:
Graph graph = ...;
GraphTraversalSource g = traversal().with(graph);Using "g" it is then possible to start writing Gremlin. The "g" allows for the setting of many configuration options which affect traversal execution. The Traversal Section describes some of these options and some are only suitable with embedded style usage. For remote options however there are some added configurations to consider and this section looks to address those.
When connecting to Gremlin Server or Remote Gremlin Providers it
is possible to configure the DriverRemoteConnection manually as shown in earlier examples where the host and port
are provided as follows:
GraphTraversalSource g = traversal().with(DriverRemoteConnection.using("localhost",8182,"g"));It is also possible to create it from a configuration. The most basic way to do so involves the following line of code:
GraphTraversalSource g = traversal().with('conf/remote-graph.properties');The remote-graph.properties file simply provides connection information to the GraphTraversalSource which is used
to configure a RemoteConnection. That file looks like this:
gremlin.remote.remoteConnectionClass=org.apache.tinkerpop.gremlin.driver.remote.DriverRemoteConnection
gremlin.remote.driver.clusterFile=conf/remote-objects.yaml
gremlin.remote.driver.sourceName=gThe RemoteConnection is an interface that provides the transport mechanism for "g" and makes it possible to for
that mechanism to be altered (typically by graph providers who have their own protocols). TinkerPop provides one such
implementation called the DriverRemoteConnection which enables transport over Gremlin Server protocols using the
TinkerPop driver. The driver is configured by the specified gremlin.remote.driver.clusterFile and the local "g" is
bound to the GraphTraversalSource on the remote end with gremlin.remote.driver.sourceName which in this case is
also "g".
There are other ways to configure the traversal using with() as it has other overloads. It can take an
Apache Commons Configuration object which would have keys similar to those shown in the properties file and it
can also take a RemoteConnection instance directly. The latter is interesting in that it means it is possible to
programmatically construct all aspects of the RemoteConnection. For TinkerPop usage, that might mean directly
constructing the DriverRemoteConnection and the driver instance that supplies the transport mechanism. For example,
the command shown above could be re-written using programmatic construction as follows:
Cluster cluster = Cluster.open();
GraphTraversalSource g = traversal().with(DriverRemoteConnection.using(cluster, "g"));Please consider the following example:
gremlin> g = traversal().with('conf/remote-graph.properties')
==>graphtraversalsource[emptygraph[empty], standard]
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,age:29]
==>[id:2,label:person,name:vadas,age:27]
==>[id:3,label:software,name:lop,lang:java]
==>[id:4,label:person,name:josh,age:32]
==>[id:5,label:software,name:ripple,lang:java]
==>[id:6,label:person,name:peter,age:35]
gremlin> g.close()
==>nullg = traversal().with('conf/remote-graph.properties')
g.V().elementMap()
g.close()GraphTraversalSource g = traversal().with("conf/remote-graph.properties");
List<Map> list = g.V().elementMap();
g.close();Note the call to close() above. The call to with() internally instantiates a connection via the driver that
can only be released by "closing" the GraphTraversalSource. It is important to take that step to release network
resources associated with g.
If working with multiple remote TraversalSource instances it is more efficient to construct Cluster and Client
objects and then re-use them.
gremlin> cluster = Cluster.open('conf/remote.yaml')
==>localhost/127.0.0.1:8182
gremlin> client = cluster.connect()
==>org.apache.tinkerpop.gremlin.driver.Client$ClusteredClient@2b0483f2
gremlin> g = traversal().with(DriverRemoteConnection.using(client, "g"))
==>graphtraversalsource[emptygraph[empty], standard]
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,age:29]
==>[id:2,label:person,name:vadas,age:27]
==>[id:3,label:software,name:lop,lang:java]
==>[id:4,label:person,name:josh,age:32]
==>[id:5,label:software,name:ripple,lang:java]
==>[id:6,label:person,name:peter,age:35]
gremlin> g.close()
==>null
gremlin> client.close()
==>null
gremlin> cluster.close()
==>nullcluster = Cluster.open('conf/remote.yaml')
client = cluster.connect()
g = traversal().with(DriverRemoteConnection.using(client, "g"))
g.V().elementMap()
g.close()
client.close()
cluster.close()If the Client instance is supplied externally, as is shown above, then it is not closed implicitly by the close of
"g". Closing "g" will have no effect on "client" or "cluster". When supplying them externally, the Client and
Cluster objects must also be closed explicitly. It’s worth noting that the close of a Cluster will close all
Client instances spawned by the Cluster.
Some connection options can also be set on individual requests made through the Java driver using with() step
on the TraversalSource. For instance to set request timeout to 500 milliseconds:
GraphTraversalSource g = traversal().with(conf);
List<Vertex> vertices = g.with(Tokens.ARGS_EVAL_TIMEOUT, 500L).V().out("knows").toList()The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent and
evaluationTimeout (formerly scriptEvaluationTimeout which is also supported but now deprecated). Use of Tokens
to reference these options is preferred.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following imports provide most of the common functionality required to use Gremlin:
import org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSource;
import org.apache.tinkerpop.gremlin.process.traversal.IO;
import static org.apache.tinkerpop.gremlin.process.traversal.AnonymousTraversalSource.traversal;
import static org.apache.tinkerpop.gremlin.process.traversal.Operator.*;
import static org.apache.tinkerpop.gremlin.process.traversal.Order.*;
import static org.apache.tinkerpop.gremlin.process.traversal.P.*;
import static org.apache.tinkerpop.gremlin.process.traversal.Pop.*;
import static org.apache.tinkerpop.gremlin.process.traversal.SackFunctions.*;
import static org.apache.tinkerpop.gremlin.process.traversal.Scope.*;
import static org.apache.tinkerpop.gremlin.process.traversal.TextP.*;
import static org.apache.tinkerpop.gremlin.structure.Column.*;
import static org.apache.tinkerpop.gremlin.structure.Direction.*;
import static org.apache.tinkerpop.gremlin.structure.T.*;
import static org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__.*;Configuration
The following table describes the various configuration options for the Gremlin Driver:
| Key | Description | Default |
|---|---|---|
auth.type |
Type of Auth to submit on requests that require authentication. Can be: |
"" |
auth.username |
The username to submit on requests that require basic authentication. |
none |
auth.password |
The password to submit on requests that require basic authentication. |
none |
auth.region |
The region setting for sigv4 authentication. |
none |
auth.serviceName |
The service name setting for sigv4 authentication. |
none |
connectionPool.connectionSetupTimeoutMillis |
Duration of time in milliseconds provided for connection setup to complete which includes the SSL handshake. |
15000 |
connectionPool.enableSsl |
Determines if SSL should be enabled or not. If enabled on the server then it must be enabled on the client. |
false |
connectionPool.idleConnectionTimeout |
Duration of time in milliseconds that the driver will allow a channel to not receive read or writes before it automatically closes. |
180000 |
connectionPool.keyStore |
The private key in JKS or PKCS#12 format. |
none |
connectionPool.keyStorePassword |
The password of the |
none |
connectionPool.keyStoreType |
|
none |
connectionPool.maxResponseContentLength |
The maximum length in bytes that a message can be received from the server. |
2147483647 |
connectionPool.maxSize |
The maximum size of a connection pool for a host. |
128 |
connectionPool.maxWaitForConnection |
The amount of time in milliseconds to wait for a new connection before timing out. |
3000 |
connectionPool.maxWaitForClose |
The amount of time in milliseconds to wait for pending messages to be returned from the server before closing the connection. |
3000 |
connectionPool.reconnectInterval |
The amount of time in milliseconds to wait before trying to reconnect to a dead host. |
1000 |
connectionPool.resultIterationBatchSize |
The override value for the size of the result batches to be returned from the server. |
64 |
connectionPool.sslCipherSuites |
The list of JSSE ciphers to support for SSL connections. If specified, only the ciphers that are listed and supported will be enabled. If not specified, the JVM default is used. |
none |
connectionPool.sslEnabledProtocols |
The list of SSL protocols to support for SSL connections. If specified, only the protocols that are listed and supported will be enabled. If not specified, the JVM default is used. |
none |
connectionPool.sslSkipCertValidation |
Configures the |
false |
connectionPool.trustStore |
File location for a SSL Certificate Chain to use when SSL is enabled. If this value is not provided and SSL is enabled, the default |
none |
connectionPool.trustStorePassword |
The password of the |
none |
connectionPool.validationRequest |
A script that is used to test server connectivity. A good script to use is one that evaluates quickly and returns no data. The default simply returns an empty string, but if a graph is required by a particular provider, a good traversal might be |
'' |
bulkResults |
Sets whether the server should attempt to get bulk results or not. |
false |
enableUserAgentOnConnect |
Enables sending a user agent to the server during connection requests. More details can be found in provider docs here. |
true |
hosts |
The list of hosts that the driver will connect to. |
localhost |
nioPoolSize |
Size of the pool for handling request/response operations. |
available processors |
password |
The password to submit on requests that require authentication. |
none |
path |
The URL path to the Gremlin Server. |
/gremlin |
port |
The port of the Gremlin Server to connect to. The same port will be applied for all hosts. |
8192 |
serializer.className |
The fully qualified class name of the |
none |
serializer.config |
A |
none |
username |
The username to submit on requests that require authentication. |
none |
workerPoolSize |
Size of the pool for handling background work. |
available processors * 2 |
Please see the Cluster.Builder javadoc to get more information on these settings.
Transactions
|
Important
|
4.0 Milestone Release - Transactions with Java isn’t currently supported. |
Serialization
Remote systems like Gremlin Server and Remote Gremlin Providers respond to requests made in a particular serialization format and respond by serializing results to some format to be interpreted by the client. For JVM-based languages, there is a single option for serialization: GraphBinary.
|
Important
|
4.0 Milestone Release - There is temporary support for GraphSON in the Java driver which will help with testing, but it is expected that the drivers will only support GraphBinary when 4.0 is fully released. |
It is important that the client and server have the same serializers configured in the same way or else one or the other will experience serialization exceptions and fail to always communicate. Discrepancy in serializer registration between client and server can happen fairly easily as different graph systems may automatically include serializers on the server-side, thus leaving the client to be configured manually. As an example:
IoRegistry registry = ...; // an IoRegistry instance exposed by a specific graph provider
TypeSerializerRegistry typeSerializerRegistry = TypeSerializerRegistry.build().addRegistry(registry).create();
MessageSerializer serializer = new GraphBinaryMessageSerializerV4(typeSerializerRegistry);
Cluster cluster = Cluster.build().
serializer(serializer).
create();
Client client = cluster.connect();
GraphTraversalSource g = traversal().with(DriverRemoteConnection.using(client, "g"));The IoRegistry tells the serializer what classes from the graph provider to auto-register during serialization.
Gremlin Server roughly uses this same approach when it configures its serializers, so using this same model will
ensure compatibility when making requests. Obviously, it is possible to switch to GraphSON or GraphBinary by using
the appropriate MessageSerializer (e.g. GraphSONMessageSerializerV4 or GraphBinaryMessageSerializerV4 respectively)
in the same way and building that into the Cluster object.
GValue Parameterization
A GValue is an encapsulation of a parameter name and value. The GValue class has a series of static methods to
construct GValues of various types from a given parameter name and value. Some of the most common examples are listed
below, see the
Javadocs
for a complete listing.
GValue<String> stringArg = GValue.ofString("name", "value");
GValue<Integer> intArg = GValue.ofInteger("name", 1);
GValue<Map> mapArg = GValue.ofMap("name", Collections.emptyMap());
GValue<?> autoTypedArg = GValue.of("name", "value"); // GValue will attempt to automatically detect correct typeA subset of gremlin steps are able to accept GValues. When constructing a
GraphTraversal with such steps in Java, a GValue may be passed in the traversal to utilize a parameter in place of a
literal.
g.V().has("name", GValue.ofString("name", "marko"));
g.mergeV(GValue.ofMap("vertexPattern", Collections.singletonMap("name", "marko")));The Lambda Solution
Supporting anonymous functions across languages is difficult as most languages do not support lambda introspection and thus, code analysis. In Gremlin-Java and with embedded usage, lambdas can be leveraged directly:
g.V().out("knows").map(t -> t.get().value("name") + " is the friend name") //1
g.V().out("knows").sideEffect(System.out::println) //2
g.V().as("a").out("knows").as("b").select("b").by((Function<Vertex, Integer>) v -> v.<String>value("name").length()) //3-
A Java
Functionis used to map aTraverser<S>to an objectE. -
Gremlin steps that take consumer arguments can be passed Java method references.
-
Gremlin-Java may sometimes require explicit lambda typing when types can not be automatically inferred.
When sending traversals remotely to Gremlin Server or
Remote Gremlin Providers, the static methods of Lambda should be used and should denote a
particular JSR-223 ScriptEngine that is available on the remote end (typically, this is Groovy). Lambda creates a
string-based lambda that is then converted into a lambda/closure/anonymous-function/etc. by the respective lambda
language’s JSR-223 ScriptEngine implementation.
g.V().out("knows").map(Lambda.function("it.get().value('name') + ' is the friend name'"))
g.V().out("knows").sideEffect(Lambda.consumer("println it"))
g.V().as("a").out("knows").as("b").select("b").by(Lambda.<Vertex,Integer>function("it.value('name').length()"))Finally, Gremlin Bytecode that includes lambdas requires that the traversal be processed by the
ScriptEngine. To avoid continued recompilation costs, it supports the encoding of bindings, which allow Gremlin
Server to cache traversals that will be reused over and over again save that some parameterization may change. Thus,
instead of translating, compiling, and then executing each submitted bytecode request, it is possible to simply
execute. To express bindings in Java, use Bindings.
b = Bindings.instance()
g.V(b.of('id',1)).out('created').values('name').map{t -> "name: " + t.get() }
g.V(b.of('id',4)).out('created').values('name').map{t -> "name: " + t.get() }
g.V(b.of('id',4)).out('created').values('name').getBytecode()
g.V(b.of('id',4)).out('created').values('name').getBytecode().getBindings()
cluster.close()Both traversals are abstractly defined as g.V(id).out('created').values('name').map{t → "name: " + t.get() } and
thus, the first submission can be cached for faster evaluation on the next submission.
|
Warning
|
It is generally advised to avoid lambda usage. Please consider A Note On Lambdas for more information. |
Submitting Scripts
 TinkerPop comes equipped with a reference client for Java-based
applications. It is referred to as
TinkerPop comes equipped with a reference client for Java-based
applications. It is referred to as gremlin-driver, which enables applications to send requests to Gremlin Server
and get back results.
Gremlin scripts are sent to the server from a Client instance. A Client is created as follows:
Cluster cluster = Cluster.open(); //1
Client client = cluster.connect(); //2-
Opens a reference to
localhost- note that there are many configuration options available in defining aClusterobject. -
Creates a
Clientgiven the configuration options of theCluster.
Once a Client instance is ready, it is possible to issue some Gremlin Groovy scripts:
ResultSet results = client.submit("[1,2,3,4]"); //1
results.stream().map(i -> i.get(Integer.class) * 2); //2
CompletableFuture<List<Result>> results = client.submit("[1,2,3,4]").all(); //3
CompletableFuture<ResultSet> future = client.submitAsync("[1,2,3,4]"); //4
Map<String,Object> params = new HashMap<>();
params.put("x",4);
client.submit("[1,2,3,x]", params); //5-
Submits a script that simply returns a
Listof integers. This method blocks until the request is written to the server and aResultSetis constructed. -
Even though the
ResultSetis constructed, it does not mean that the server has sent back the results (or even evaluated the script potentially). TheResultSetis just a holder that is awaiting the results from the server. In this case, they are streamed from the server as they arrive. -
Submit a script, get a
ResultSet, then return aCompletableFuturethat will be called when all results have been returned. -
Submit a script asynchronously without waiting for the request to be written to the server.
-
Parameterized request are considered the most efficient way to send Gremlin to the server as they can be cached, which will boost performance and reduce resources required on the server.
Per Request Settings
There are a number of overloads to Client.submit() that accept a RequestOptions object. The RequestOptions
provide a way to include options that are specific to the request made with the call to submit(). A good use-case for
this feature is to set a per-request override to the evaluationTimeout so that it only applies to the current
request.
Cluster cluster = Cluster.open();
Client client = cluster.connect();
RequestOptions options = RequestOptions.build().timeout(500).create();
List<Result> result = client.submit("g.V().repeat(both()).times(100)", options).all().get();The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiar with
bytecode may try g.with(EVALUATION_TIMEOUT, 500) within a script. Gremlin Server will respect timeouts set this way
in scripts as well. With scripts of course, it is possible to send multiple traversals at once in the same script.
In such events, the timeout for the request is interpreted as a sum of all timeouts identified in the script.
RequestOptions options = RequestOptions.build().timeout(500).create();
List<Result> result = client.submit("g.with(EVALUATION_TIMEOUT, 500).addV().iterate();" +
"g.addV().iterate();" +
"g.with(EVALUATION_TIMEOUT, 500).addV();", options).all().get();In the above example, RequestOptions defines a timeout of 500 milliseconds, but the script has three traversals with
two internal settings for the timeout using with(). The request timeout used by the server will therefore be 1000
milliseconds (overriding the 500 which itself was an override for whatever configuration was on the server).
Aliases
Scripts submitted to Gremlin Server automatically have the globally configured Graph and TraversalSource instances
made available to them. Therefore, if Gremlin Server configures two TraversalSource instances called "g1" and "g2"
a script can simply reference them directly as:
client.submit("g1.V()")
client.submit("g2.V()")While this is an acceptable way to submit scripts, it has the downside of forcing the client to encode the server-side
variable name directly into the script being sent. If the server configuration ever changed such that "g1" became
"g100", the client-side code might have to see a significant amount of change. Decoupling the script code from the
server configuration can be managed by the alias method on Client as follows:
Client g1Client = client.alias("g1")
Client g2Client = client.alias("g2")
g1Client.submit("g.V()")
g2Client.submit("g.V()")The above code demonstrates how the alias method can be used such that the script need only contain a reference
to "g" and "g1" and "g2" are automatically rebound into "g" on the server-side.
RequestInterceptor
Gremlin-Java allows for modification of the underlying HTTP request through the use of RequestInteceptors. This is
intended to be an advanced feature which means that you will need to understand how the implementation works in order
to safely utilize it. Gremlin-Java is written in a way that you should be able to interact with a TinkerPop-enabled
server without having to use interceptors. This is intended for cases where the server has special capabilities.
A RequestInterceptor is simply a UnaryOperator. A list of these are maintained and will be run sequentially for
each request. When building a Cluster instance, the methods addInterceptorAfter(), addInterceptorBefore(),
addInterceptor(), and removeInterceptor() can be used to add or remove interceptors. It’s important to remember
that order matters so if one interceptor depends on another’s output then ensure they are added in the correct order.
Note that Auth is also implemented using interceptors, and Auth is always run last after your list of interceptors
has already ran. By default, the PayloadSerializingInterceptor with the name serializer is added to your list of
interceptors. This interceptor is used for serializing the body of the request. The first interceptor is provided with
a org.apache.tinkerpop.gremlin.driver.HttpRequest that contains a RequestMessage in the body. As a reminder
RequestMessage is immutable and only certain keys can be added to them. If you want to customize the body by adding
other fields, you will need to make a different copy of the RequestMessage or completely change the body to contain a
different data type. The very last interceptor should have a org.apache.tinkerpop.gremlin.driver.HttpRequest that
contains a byte[] in the body.
For an example of a simple RequestInterceptor that only modifies the header of the request take a look at
basic authentication.
Domain Specific Languages
Creating a Domain Specific Language (DSL) in Java requires the @GremlinDsl Java annotation in the
gremlin-annotations module. This annotation should be applied to a "DSL interface" that extends
GraphTraversal.Admin:
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>gremlin-annotations</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>@GremlinDsl
public interface SocialTraversalDsl<S, E> extends GraphTraversal.Admin<S, E> {
}|
Important
|
The name of the DSL interface should be suffixed with "TraversalDSL". All characters in the interface name before that become the "name" of the DSL. |
In this interface, define the methods that the DSL will be composed of:
@GremlinDsl
public interface SocialTraversalDsl<S, E> extends GraphTraversal.Admin<S, E> {
public default GraphTraversal<S, Vertex> knows(String personName) {
return out("knows").hasLabel("person").has("name", personName);
}
public default <E2 extends Number> GraphTraversal<S, E2> youngestFriendsAge() {
return out("knows").hasLabel("person").values("age").min();
}
public default GraphTraversal<S, Long> createdAtLeast(int number) {
return outE("created").count().is(P.gte(number));
}
}|
Important
|
Follow the TinkerPop convention of using <S,E> in naming generics as those conventions are taken into
account when generating the anonymous traversal class. The processor attempts to infer the appropriate type parameters
when generating the anonymous traversal class. If it cannot do it correctly, it is possible to avoid the inference by
using the GremlinDsl.AnonymousMethod annotation on the DSL method. It allows explicit specification of the types to
use.
|
The @GremlinDsl annotation is used by the Java Annotation Processor
to generate the boilerplate class structure required to properly use the DSL within the TinkerPop framework. These
classes can be generated and maintained by hand, but it would be time consuming, monotonous and error-prone to do so.
Typically, the Java compilation process is automatically configured to detect annotation processors on the classpath
and will automatically use them when found. If that does not happen, it may be necessary to make configuration changes
to the build to allow for the compilation process to be aware of the following javax.annotation.processing.Processor
implementation:
org.apache.tinkerpop.gremlin.process.traversal.dsl.GremlinDslProcessorThe annotation processor will generate several classes for the DSL:
-
SocialTraversal- ATraversalinterface that extends theSocialTraversalDslproxying methods to its underlying interfaces (such asGraphTraversal) to instead return aSocialTraversal -
DefaultSocialTraversal- A default implementation ofSocialTraversal(typically not used directly by the user) -
SocialTraversalSource- SpawnsDefaultSocialTraversalinstances. -
__- Spawns anonymousDefaultSocialTraversalinstances.
Using the DSL then just involves telling the Graph to use it:
SocialTraversalSource social = traversal(SocialTraversalSource.class).with(graph);
social.V().has("name","marko").knows("josh");The SocialTraversalSource can also be customized with DSL functions. As an additional step, include a class that
extends from GraphTraversalSource and with a name that is suffixed with "TraversalSourceDsl". Include in this class,
any custom methods required by the DSL:
public class SocialTraversalSourceDsl extends GraphTraversalSource {
public SocialTraversalSourceDsl(Graph graph, TraversalStrategies traversalStrategies) {
super(graph, traversalStrategies);
}
public SocialTraversalSourceDsl(Graph graph) {
super(graph);
}
public SocialTraversalSourceDsl(RemoteConnection connection) {
super(connection);
}
public GraphTraversal<Vertex, Vertex> persons(String... names) {
GraphTraversalSource clone = this.clone();
// Manually add a "start" step for the traversal in this case the equivalent of V(). GraphStep is marked
// as a "start" step by passing "true" in the constructor.
clone.getBytecode().addStep(GraphTraversal.Symbols.V);
GraphTraversal<Vertex, Vertex> traversal = new DefaultGraphTraversal<>(clone);
traversal.asAdmin().addStep(new GraphStep<>(traversal.asAdmin(), Vertex.class, true));
traversal = traversal.hasLabel("person");
if (names.length > 0) traversal = traversal.has("name", P.within(names));
return traversal;
}
}Then, back in the SocialTraversal interface, update the GremlinDsl annotation with the traversalSource argument
to point to the fully qualified class name of the SocialTraversalSourceDsl:
@GremlinDsl(traversalSource = "com.company.SocialTraversalSourceDsl")
public interface SocialTraversalDsl<S, E> extends GraphTraversal.Admin<S, E> {
...
}It is then possible to use the persons() method to start traversals:
SocialTraversalSource social = traversal(SocialTraversalSource.class).with(graph);
social.persons("marko").knows("josh");|
Note
|
Using Maven makes developing DSLs with the annotation processor straightforward in that it sets up appropriate paths to the generated code automatically. |
Troubleshooting
Response exceeded X bytes.
This error occurs when the driver attempts to process a response that exceeds the configured maximum response size.
The most direct way to fix this problem is to increase the maxResponseContentLength setting in the driver.
TimeoutException
A TimeoutException is thrown by the driver when the time limit assigned by the maxWaitForConnection is exceeded
when trying to borrow a connection from the connection pool for a particular host. There are generally two scenarios
where this occurs:
-
The server has actually reached its maximum capacity or the driver has just learned that the server is unreachable.
-
The client is throttling requests when the pool is exhausted.
The latter of the two can be addressed from the driver side in the following ways:
-
Increase the
maxWaitForConnectionallowing the client to wait a bit longer for a connection to become available. -
Increase the number of requests allowed per connection by increasing the
maxSimultaneousUsagePerConnectionandmaxInProcessPerConnectionsettings. -
Increase the number of connections available in the connection pool by increasing the
maxConnectionPoolSize.
The exception and logs (assuming they are enabled) should contain information about the state of the connection pool along with its connections which can help shed more light on which of these scenarios caused the problem. Some examples of these messages and their meaning are shown below:
The server is unavailable
Timed-out (500 MILLISECONDS) waiting for connection on Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin}. Potential Cause: Connection refused: no further information
> ConnectionPool (Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin})- no connections in poolClient is likely issuing more requests than the pool size can handle
Timed-out (150 MILLISECONDS) waiting for connection on Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin}. Potential Cause: Number of active requests exceeds pool size. Consider increasing the value for maxConnectionPoolSize.
ConnectionPool (Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin})
Connection Pool Status (size=1 max=1 min=1 toCreate=0 bin=0)
> Connection{channel=5a859d62 isDead=false borrowed=1 pending=1 markedReplaced=false closing=false created=2022-12-19T21:08:21.569613100Z thread=gremlin-driver-conn-scheduler-1}
-- bin --Network traffic is slow and the websocket handshake does not complete in time
Timed-out (250 MILLISECONDS) waiting for connection on Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin}. Potential Cause: WebSocket handshake not completed in stipulated time=[100]ms
ConnectionPool (Host{address=localhost/127.0.0.1:45940, hostUri=ws://localhost:45940/gremlin})
Connection Pool Status (size=1 max=5 min=1 toCreate=0 bin=0)
> Connection{channel=205fc8d2 isDead=false borrowed=1 pending=1 markedReplaced=false closing=false created=2022-12-19T21:10:04.692921600Z thread=gremlin-driver-conn-scheduler-1}
-- bin --Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Java. They can be found in GitHub here.
The remote connection examples in particular are designed to connect to a running Gremlin Server
configured with the conf/gremlin-server.yaml file as included with the standard release packaging.
To do so, download an image of Gremlin Server from Docker Hub, then launch a new container with docker run:
docker pull tinkerpop/gremlin-server
docker run -d -p 8182:8182 tinkerpop/gremlin-serverAll examples can then be run using your IDE of choice.
Gremlin-JavaScript
|
Important
|
4.0 Milestone Release - Gremlin-JavaScript is not available in this milestone, please consider testing with Java or Python. |
 Apache TinkerPop’s Gremlin-JavaScript implements Gremlin within the
JavaScript language. It targets Node.js runtime and can be used on different operating systems on any Node.js 6 or
above. Since the JavaScript naming conventions are very similar to that of Java, it should be very easy to switch
between Gremlin-Java and Gremlin-JavaScript.
Apache TinkerPop’s Gremlin-JavaScript implements Gremlin within the
JavaScript language. It targets Node.js runtime and can be used on different operating systems on any Node.js 6 or
above. Since the JavaScript naming conventions are very similar to that of Java, it should be very easy to switch
between Gremlin-Java and Gremlin-JavaScript.
npm install gremlinConnecting
The pattern for connecting is described in Connecting Gremlin and it basically distills down to
creating a GraphTraversalSource. A GraphTraversalSource is created from the AnonymousTraversalSource.traversal()
method where the "g" provided to the DriverRemoteConnection corresponds to the name of a GraphTraversalSource on
the remote end.
const g = traversal().with(new DriverRemoteConnection('ws://localhost:8182/gremlin'));Gremlin-JavaScript supports plain text SASL authentication, you can set it on the connection options.
const authenticator = new gremlin.driver.auth.PlainTextSaslAuthenticator('myuser', 'mypassword');
const g = traversal().with(new DriverRemoteConnection('ws://localhost:8182/gremlin', { authenticator });Given that I/O operations in Node.js are asynchronous by default, Terminal Steps return a Promise:
-
Traversal.toList(): Returns aPromisewith anArrayas result value. -
Traversal.next(): Returns aPromisewith a{ value, done }tuple as result value, according to the async iterator proposal. -
Traversal.iterate(): Returns aPromisewithout a value.
For example:
g.V().hasLabel('person').values('name').toList()
.then(names => console.log(names));When using async functions it is possible to await the promises:
const names = await g.V().hasLabel('person').values('name').toList();
console.log(names);Some connection options can also be set on individual requests made through the using with() step on the
TraversalSource. For instance to set request timeout to 500 milliseconds:
const vertices = await g.with_('evaluationTimeout', 500).V().out('knows').toList()The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent and
evaluationTimeout (formerly scriptEvaluationTimeout which is also supported but now deprecated).
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following imports provide most of the typical functionality required to use Gremlin:
const gremlin = require('gremlin');
const traversal = gremlin.process.AnonymousTraversalSource.traversal;
const __ = gremlin.process.statics;
const DriverRemoteConnection = gremlin.driver.DriverRemoteConnection;
const column = gremlin.process.column
const direction = gremlin.process.direction
const Direction = {
BOTH: direction.both,
IN: direction.in,
OUT: direction.out,
from_: direction.out,
to: direction.in,
}
const p = gremlin.process.P
const textp = gremlin.process.TextP
const pick = gremlin.process.pick
const pop = gremlin.process.pop
const order = gremlin.process.order
const scope = gremlin.process.scope
const t = gremlin.process.t
const cardinality = gremlin.process.cardinality
const CardinalityValue = gremlin.process.CardinalityValueBy defining these imports it becomes possible to write Gremlin in the more shorthand, canonical style that is demonstrated in most examples found here in the documentation:
const { P: { gt } } = gremlin.process;
const { order: { desc } } = gremlin.process;
g.V().hasLabel('person').has('age',gt(30)).order().by('age',desc).toList()Configuration
The following table describes the various configuration options for the Gremlin-Javascript Driver. They
can be passed in the constructor of a new Client or DriverRemoteConnection :
| Key | Type | Description | Default |
|---|---|---|---|
url |
String |
The resource uri. |
None |
options |
Object |
The connection options. |
{} |
options.ca |
Array |
Trusted certificates. |
undefined |
options.cert |
String/Array/Buffer |
The certificate key. |
undefined |
options.mimeType |
String |
The mime type to use. |
'application/vnd.gremlin-v3.0+json' |
options.pfx |
String/Buffer |
The private key, certificate, and CA certs. |
undefined |
options.reader |
GraphSONReader/GraphBinaryReader |
The reader to use. |
select reader according to mimeType |
options.writer |
GraphSONWriter |
The writer to use. |
select writer according to mimeType |
options.rejectUnauthorized |
Boolean |
Determines whether to verify or not the server certificate. |
undefined |
options.traversalSource |
String |
The traversal source. |
'g' |
options.authenticator |
Authenticator |
The authentication handler to use. |
undefined |
options.processor |
String |
The name of the opProcessor to use, leave it undefined or set 'session' when session mode. |
undefined |
options.session |
String |
The sessionId of Client in session mode. undefined means session-less Client. |
undefined |
options.enableUserAgentOnConnect |
Boolean |
Determines if a user agent will be sent during connection handshake. |
true |
options.headers |
Object |
An associative array containing the additional header key/values for the initial request. |
undefined |
options.pingEnabled |
Boolean |
Setup ping interval. |
true |
options.pingInterval |
Number |
Ping request interval in ms if ping enabled. |
60000 |
options.pongTimeout |
Number |
Timeout of pong response in ms after sending a ping. |
30000 |
Transactions
To get a full understanding of this section, it would be good to start by reading the Transactions section of this documentation, which discusses transactions in the general context of TinkerPop itself. This section builds on that content by demonstrating the transactional syntax for Javascript.
const g = traversal().with(new DriverRemoteConnection('ws://localhost:8182/gremlin'));
const tx = g.tx(); // create a Transaction
// spawn a new GraphTraversalSource binding all traversals established from it to tx
const gtx = tx.begin();
// execute traversals using gtx occur within the scope of the transaction held by tx. the
// tx is closed after calls to commit or rollback and cannot be re-used. simply spawn a
// new Transaction from g.tx() to create a new one as needed. the g context remains
// accessible through all this as a sessionless connection.
Promise.all([
gtx.addV("person").property("name", "jorge").iterate(),
gtx.addV("person").property("name", "josh").iterate()
]).then(() => {
return tx.commit();
}).catch(() => {
return tx.rollback();
});The Lambda Solution
Supporting anonymous functions across languages is difficult as
most languages do not support lambda introspection and thus, code analysis. In Gremlin-Javascript, a Gremlin lambda
should be represented as a zero-arg callable that returns a string representation of the lambda expected for use in the
traversal. The returned lambda should be written as a Gremlin-Groovy string. When the lambda is represented in
Bytecode its language is encoded such that the remote connection host can infer which translator and ultimate
execution engine to use.
g.V().out().
map(() => "it.get().value('name').length()").
sum().
toList().then(total => console.log(total))|
Tip
|
When running into situations where Groovy cannot properly discern a method signature based on the Lambda
instance created, it will help to fully define the closure in the lambda expression - so rather than
() ⇒ "it.get().value('name')", prefer () ⇒ "x → x.get().value('name')".
|
|
Warning
|
As explained throughout the documentation, when possible avoid lambdas. |
Submitting Scripts
It is possible to submit parametrized Gremlin scripts to the server as strings, using the Client class:
const gremlin = require('gremlin');
const client = new gremlin.driver.Client('ws://localhost:8182/gremlin', { traversalSource: 'g' });
const result1 = await client.submit('g.V(vid)', { vid: 1 });
const vertex = result1.first();
const result2 = await client.submit('g.V().hasLabel(label).tail(n)', { label: 'person', n: 3 });
// ResultSet is an iterable
for (const vertex of result2) {
console.log(vertex.id);
}Per Request Settings
The client.submit() functions accept a requestOptions which expects a dictionary. The requestOptions
provide a way to include options that are specific to the request made with the call to submit(). A good use-case for
this feature is to set a per-request override to the evaluationTimeout so that it only applies to the current
request.
const result = await client.submit("g.V().repeat(both()).times(100)", null, { evaluationTimeout: 5000 })The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent, materializeProperties and
evaluationTimeout (formerly scriptEvaluationTimeout which is also supported but now deprecated).
|
Important
|
The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiar
with bytecode may try g.with(EVALUATION_TIMEOUT, 500) within a script. Scripts with multiple traversals and multiple
timeouts will be interpreted as a sum of all timeouts identified in the script for that request.
|
Processing results as they are returned from the Gremlin server
The Gremlin JavaScript driver maintains a WebSocket connection to the Gremlin server and receives messages according to the batchSize parameter on the per request settings or the resultIterationBatchSize value configured for the Gremlin server. When submitting scripts the default behavior is to wait for the entire result set to be returned from a query before allowing any processing on the result set.
The following examples assume that you have 100 vertices in your graph.
const result = await client.submit("g.V()");
console.log(result.toArray()); // 100 - all the vertices in your graphWhen working with larger result sets it may be beneficial for memory management to process each chunk of data as it is returned from the gremlin server. The Gremlin JavaScript driver can return a readable stream instead of waiting for the entire result set to be loaded.
const readable = client.stream("g.V()", {}, { batchSize: 25 });
readable.on('data', (data) => {
console.log(data.toArray()); // 25 vertices
})
readable.on('error', (error) => {
console.log(error); // errors returned from gremlin server
})
readable.on('end', () => {
console.log('query complete'); // when the end event is received then all the results have been processed
})If you are using NodeJS >= 10.0, you can asynchronously iterate readable streams:
const readable = client.stream("g.V()", {}, { batchSize: 25 });
try {
for await (const result of readable) {
console.log('data', result.toArray()); // 25 vertices
}
} catch (err) {
console.log(err);
}Domain Specific Languages
Developing Gremlin DSLs in JavaScript largely requires extension of existing core classes with use of standalone functions for anonymous traversal spawning. The pattern is demonstrated in the following example:
class SocialTraversal extends GraphTraversal {
constructor(graph, traversalStrategies, bytecode) {
super(graph, traversalStrategies, bytecode);
}
aged(age) {
return this.has('person', 'age', age);
}
}
class SocialTraversalSource extends GraphTraversalSource {
constructor(graph, traversalStrategies, bytecode) {
super(graph, traversalStrategies, bytecode, SocialTraversalSource, SocialTraversal);
}
person(name) {
return this.V().has('person', 'name', name);
}
}
function anonymous() {
return new SocialTraversal(null, null, new Bytecode());
}
function aged(age) {
return anonymous().aged(age);
}SocialTraversal extends the core GraphTraversal class and has a three argument constructor which is immediately
proxied to the GraphTraversal constructor. New DSL steps are then added to this class using available steps to
construct the underlying traversal to execute as demonstrated in the aged() step.
The SocialTraversal is spawned from a SocialTraversalSource which is extended from GraphTraversalSource. Steps
added here are meant to be start steps. In the above case, the person() start step find a "person" vertex to begin
the traversal from.
Typically, steps that are made available on a GraphTraversal (i.e. SocialTraversal in this example) should also be
made available as spawns for anonymous traversals. The recommendation is that these steps be exposed in the module
as standalone functions. In the example above, the standalone aged() step creates an anonymous traversal through
an anonymous() utility function. The method for creating these standalone functions can be handled in other ways if
desired.
To use the DSL, simply initialize the g as follows:
const g = traversal(SocialTraversalSource).with(connection);
g.person('marko').aged(29).values('name').toList().
then(names => console.log(names));Differences
In situations where Javascript reserved words and global functions overlap with standard Gremlin steps and tokens, those bits of conflicting Gremlin get an underscore appended as a suffix:
In addition, the enum construct for Cardinality cannot have functions attached to it the way it can be done in Java,
therefore cardinality functions that take a value like list(), set(), and single() are referenced from a
CardinalityValue class rather than Cardinality itself.
Gremlin allows for Map instances to include null keys, but null keys in Javascript have some interesting behavior
as in:
> var a = { null: 'something', 'b': 'else' };
> JSON.stringify(a)
'{"null":"something","b":"else"}'
> JSON.parse(JSON.stringify(a))
{ null: 'something', b: 'else' }
> a[null]
'something'
> a['null']
'something'This behavior needs to be considered when using Gremlin to return such results. A typical situation where this might
happen is with group() or groupCount() as in:
g.V().groupCount().by('age')where "age" is not a valid key for all vertices. In these cases, it will return null for that key and group on that.
It may bet better in Javascript to filter away those vertices to avoid the return of null in the returned Map:
g.V().has('age').groupCount().by('age')
g.V().hasLabel('person').groupCount().by('age')Either of the above two options accomplishes the desired goal as both prevent groupCount() from having to process
the possibility of null.
Limitations
-
The
subgraph()-step is not supported by any variant that is not running on the Java Virtual Machine as there is noGraphinstance to deserialize a result into on the client-side. A workaround is to replace the step withaggregate(local)and then convert those results to something the client can use locally.
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-JavaScript. They
can be found in GitHub here
and are designed to connect to a running Gremlin Server configured with the
conf/gremlin-server.yaml and conf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration file
conf/gremlin-server.yaml. To start a clean server, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, using conf/gremlin-server-modern.yaml.
To start a server with the Modern graph preloaded, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlMake sure to install all necessary packages:
npm installEach example can now be run with the following commands:
node connections.js
node basic-gremlin.js
node modern-traversals.jsGremlin.Net
|
Important
|
4.0 Milestone Release - Gremlin.Net is not available in this milestone, please consider testing with Java or Python. |
![]() Apache TinkerPop’s Gremlin.Net implements Gremlin within the C#
language. It targets .NET Standard and can therefore be used on different operating systems and with different .NET
frameworks, such as .NET Framework and .NET Core. Since the C# syntax is very
similar to that of Java, it should be easy to switch between Gremlin-Java and Gremlin.Net. The only major syntactical
difference is that all method names in Gremlin.Net use PascalCase as opposed to camelCase in Gremlin-Java in order
to comply with .NET conventions.
Apache TinkerPop’s Gremlin.Net implements Gremlin within the C#
language. It targets .NET Standard and can therefore be used on different operating systems and with different .NET
frameworks, such as .NET Framework and .NET Core. Since the C# syntax is very
similar to that of Java, it should be easy to switch between Gremlin-Java and Gremlin.Net. The only major syntactical
difference is that all method names in Gremlin.Net use PascalCase as opposed to camelCase in Gremlin-Java in order
to comply with .NET conventions.
nuget install Gremlin.NetConnecting
The pattern for connecting is described in Connecting Gremlin and it basically distills down to
creating a GraphTraversalSource. A GraphTraversalSource is created from the AnonymousTraversalSource.traversal()
method where the "g" provided to the DriverRemoteConnection corresponds to the name of a GraphTraversalSource on
the remote end.
using var remoteConnection = new DriverRemoteConnection(new GremlinClient(new GremlinServer("localhost", 8182)), "g");
var g = Traversal().With(remoteConnection);Some connection options can also be set on individual requests using the With() step on the TraversalSource.
For instance to set request timeout to 500 milliseconds:
var l = g.With(Tokens.ArgsEvalTimeout, 500).V().Out("knows").Count().ToList();The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent and
evaluationTimeout (formerly scriptEvaluationTimeout which is also supported but now deprecated). These options are
available as constants on the Gremlin.Net.Driver.Tokens class.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following imports provide most of the typical functionality required to use Gremlin:
using static Gremlin.Net.Process.Traversal.AnonymousTraversalSource;
using static Gremlin.Net.Process.Traversal.__;
using static Gremlin.Net.Process.Traversal.P;
using static Gremlin.Net.Process.Traversal.Order;
using static Gremlin.Net.Process.Traversal.Operator;
using static Gremlin.Net.Process.Traversal.Pop;
using static Gremlin.Net.Process.Traversal.Scope;
using static Gremlin.Net.Process.Traversal.TextP;
using static Gremlin.Net.Process.Traversal.Column;
using static Gremlin.Net.Process.Traversal.Direction;
using static Gremlin.Net.Process.Traversal.Cardinality;
using static Gremlin.Net.Process.Traversal.CardinalityValue;
using static Gremlin.Net.Process.Traversal.T;Configuration
The connection properties for the Gremlin.Net driver can be passed to the GremlinServer instance as keyword arguments:
| Key | Description | Default |
|---|---|---|
hostname |
The hostname that the driver will connect to. |
localhost |
port |
The port on which Gremlin Server can be reached. |
8182 |
enableSsl |
Determines if SSL should be enabled or not. If enabled on the server then it must be enabled on the client. |
false |
username |
The username to submit on requests that require authentication. |
none |
password |
The password to submit on requests that require authentication. |
none |
Connection Pool
It is also possible to configure the ConnectionPool of the Gremlin.Net driver.
These configuration options can be set as properties
on the ConnectionPoolSettings instance that can be passed to the GremlinClient:
| Key | Description | Default |
|---|---|---|
PoolSize |
The size of the connection pool. |
4 |
MaxInProcessPerConnection |
The maximum number of in-flight requests that can occur on a connection. |
32 |
ReconnectionAttempts |
The number of attempts to get an open connection from the pool to submit a request. |
4 |
ReconnectionBaseDelay |
The base delay used for the exponential backoff for the reconnection attempts. |
1 s |
EnableUserAgentOnConnect |
Enables sending a user agent to the server during connection requests. More details can be found in provider docs here. |
true |
A NoConnectionAvailableException is thrown if all connections have reached the MaxInProcessPerConnection limit
when a new request comes in.
A ServerUnavailableException is thrown if no connection is available to the server to submit a request after
ReconnectionAttempts retries.
WebSocket Configuration
The WebSocket connections can also be configured, directly as parameters of the GremlinClient constructor. It takes
an optional delegate webSocketConfiguration that will be invoked for each connection. This makes it possible to
configure more advanced options like the KeepAliveInterval or client certificates.
Starting with .NET 6, it is also possible to use compression for WebSockets. This is enabled by default starting with
TinkerPop 3.5.3 (again, only on .NET 6 or higher). Note that compression might make an application susceptible to
attacks like CRIME/BREACH. Compression should therefore be turned off if the application sends sensitive data to the
server as well as data that could potentially be controlled by an untrusted user. Compression can be disabled via the
disableCompression parameter.
Logging
It is possible to enable logging for the Gremlin.Net driver by providing an ILoggerFactory (from the
Microsoft.Extensions.Logging.Abstractions package) to the GremlinClient constructor:
var loggerFactory = LoggerFactory.Create(builder =>
{
builder.AddConsole();
});
var client = new GremlinClient(new GremlinServer("localhost", 8182), loggerFactory: loggerFactory);Serialization
The Gremlin.Net driver uses by default GraphBinary but it is also possible to use another serialization format by passing a message serializer when creating the GremlinClient.
GraphSON 3.0 can be configured like this:
var client = new GremlinClient(new GremlinServer("localhost", 8182), new GraphSON3MessageSerializer());and GraphSON 2.0 like this:
var client = new GremlinClient(new GremlinServer("localhost", 8182), new GraphSON2MessageSerializer());Traversal Strategies
In order to add and remove traversal strategies from a traversal source, Gremlin.Net has an AbstractTraversalStrategy
class along with a collection of subclasses that mirror the standard Gremlin-Java strategies.
g = g.WithStrategies(new SubgraphStrategy(vertices: HasLabel("person"),
edges: Has("weight", Gt(0.5))));
var names = g.V().Values<string>("name").ToList(); // names: [marko, vadas, josh, peter]
g = g.WithoutStrategies(typeof(SubgraphStrategy));
names = g.V().Values<string>("name").ToList(); // names: [marko, vadas, lop, josh, ripple, peter]
var edgeValueMaps = g.V().OutE().ValueMap<object, object>().With(WithOptions.Tokens).ToList();
// edgeValueMaps: [[label:created, id:9, weight:0.4], [label:knows, id:7, weight:0.5], [label:knows, id:8, weight:1.0],
// [label:created, id:10, weight:1.0], [label:created, id:11, weight:0.4], [label:created, id:12, weight:0.2]]
g = g.WithComputer(workers: 2, vertices: Has("name", "marko"));
names = g.V().Values<string>("name").ToList(); // names: [marko]
edgeValueMaps = g.V().OutE().ValueMap<object, object>().With(WithOptions.Tokens).ToList();
// edgeValueMaps: [[label:created, id:9, weight:0.4], [label:knows, id:7, weight:0.5], [label:knows, id:8, weight:1.0]]|
Note
|
Many of the TraversalStrategy classes in Gremlin.Net are proxies to the respective strategy on Apache TinkerPop’s
JVM-based Gremlin traversal machine. As such, their Apply(ITraversal) method does nothing. However, the strategy is
encoded in the Gremlin.Net bytecode and transmitted to the Gremlin traversal machine for re-construction machine-side.
|
Transactions
To get a full understanding of this section, it would be good to start by reading the Transactions section of this documentation, which discusses transactions in the general context of TinkerPop itself. This section builds on that content by demonstrating the transactional syntax for C#.
using var gremlinClient = new GremlinClient(new GremlinServer("localhost", 8182));
var g = Traversal().With(new DriverRemoteConnection(gremlinClient));
var tx = g.Tx(); // create a transaction
// spawn a new GraphTraversalSource binding all traversals established from it to tx
var gtx = tx.Begin();
// execute traversals using gtx occur within the scope of the transaction held by tx. the
// tx is closed after calls to CommitAsync or RollbackAsync and cannot be re-used. simply spawn a
// new Transaction from g.Tx() to create a new one as needed. the g context remains
// accessible through all this as a sessionless connection.
try
{
await gtx.AddV("person").Property("name", "jorge").Promise(t => t.Iterate());
await gtx.AddV("person").Property("name", "josh").Promise(t => t.Iterate());
await tx.CommitAsync();
}
catch (Exception)
{
await tx.RollbackAsync();
}The Lambda Solution
Supporting anonymous functions across languages is difficult as
most languages do not support lambda introspection and thus, code analysis. While Gremlin.Net doesn’t support C# lambdas, it
is still able to represent lambdas in other languages. When the lambda is represented in Bytecode its language is encoded
such that the remote connection host can infer which translator and ultimate execution engine to use.
g.V().Out().Map<int>(Lambda.Groovy("it.get().value('name').length()")).Sum<int>().ToList(); //1
g.V().Out().Map<int>(Lambda.Python("lambda x: len(x.get().value('name'))")).Sum<int>().ToList(); //2-
Lambda.Groovy()can be used to create a Groovy lambda. -
Lambda.Python()can be used to create a Python lambda.
The ILambda interface returned by these two methods inherits interfaces like IFunction and IPredicate that mirror
their Java counterparts which makes it possible to use lambdas with Gremlin.Net for the same steps as in Gremlin-Java.
|
Tip
|
When running into situations where Groovy cannot properly discern a method signature based on the Lambda
instance created, it will help to fully define the closure in the lambda expression - so rather than
Lambda.Groovy("it.get().value('name')), prefer Lambda.Groovy("x → x.get().value('name')).
|
Submitting Scripts
Gremlin scripts are sent to the server from a IGremlinClient instance. A IGremlinClient is created as follows:
var gremlinServer = new GremlinServer("localhost", 8182);
using var gremlinClient = new GremlinClient(gremlinServer);
var response =
await gremlinClient.SubmitWithSingleResultAsync<string>("g.V().has('person','name','marko')");If the remote system has authentication and SSL enabled, then the GremlinServer object can be configured as follows:
var username = "username";
var password = "password";
var gremlinServer = new GremlinServer("localhost", 8182, true, username, password);Per Request Settings
The GremlinClient.Submit() functions accept an option to build a raw RequestMessage. A good use-case for this
feature is to set a per-request override to the evaluationTimeout so that it only applies to the current request.
var gremlinServer = new GremlinServer("localhost", 8182);
using var gremlinClient = new GremlinClient(gremlinServer);
var response =
await gremlinClient.SubmitWithSingleResultAsync<string>(
RequestMessage.Build(Tokens.OpsEval).
AddArgument(Tokens.ArgsGremlin, "g.V().count()").
AddArgument(Tokens.ArgsEvalTimeout, 500).
Create());The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent, materializeProperties and
evaluationTimeout (formerly scriptEvaluationTimeout which is also supported but now deprecated). These options are
available as constants on the Gremlin.Net.Driver.Tokens class.
|
Important
|
The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiar
with bytecode may try g.with(EVALUATION_TIMEOUT, 500) within a script. Scripts with multiple traversals and multiple
timeouts will be interpreted as a sum of all timeouts identified in the script for that request.
|
Domain Specific Languages
Developing a Domain Specific Language (DSL) for .Net is most easily implemented using
Extension Methods
as they don’t require direct extension of classes in the TinkerPop hierarchy. Extension Method classes simply need to
be constructed for the GraphTraversal and the GraphTraversalSource. Unfortunately, anonymous traversals (spawned
from __) can’t use the Extension Method approach as they do not work for static classes and static classes can’t be
extended. The only option is to re-implement the methods of __ as a wrapper in the anonymous traversal for the DSL
or to simply create a static class for the DSL and use the two anonymous traversals creators independently. The
following example uses the latter approach as it saves a lot of boilerplate code with the minor annoyance of having a
second static class to deal with when writing traversals rather than just calling __ for everything.
namespace Dsl
{
public static class SocialTraversalExtensions
{
public static GraphTraversal<Vertex,Vertex> Knows(this GraphTraversal<Vertex,Vertex> t, string personName)
{
return t.Out("knows").HasLabel("person").Has("name", personName);
}
public static GraphTraversal<Vertex, int> YoungestFriendsAge(this GraphTraversal<Vertex,Vertex> t)
{
return t.Out("knows").HasLabel("person").Values<int>("age").Min<int>();
}
public static GraphTraversal<Vertex,long> CreatedAtLeast(this GraphTraversal<Vertex,Vertex> t, long number)
{
return t.OutE("created").Count().Is(P.Gte(number));
}
}
public static class __Social
{
public static GraphTraversal<object,Vertex> Knows(string personName)
{
return __.Out("knows").HasLabel("person").Has("name", personName);
}
public static GraphTraversal<object, int> YoungestFriendsAge()
{
return __.Out("knows").HasLabel("person").Values<int>("age").Min<int>();
}
public static GraphTraversal<object,long> CreatedAtLeast(long number)
{
return __.OutE("created").Count().Is(P.Gte(number));
}
}
public static class SocialTraversalSourceExtensions
{
public static GraphTraversal<Vertex,Vertex> Persons(this GraphTraversalSource g, params string[] personNames)
{
GraphTraversal<Vertex,Vertex> t = g.V().HasLabel("person");
if (personNames.Length > 0)
{
t = t.Has("name", P.Within(personNames));
}
return t;
}
}
}Note the creation of __Social as the Social DSL’s "extension" to the available ways in which to spawn anonymous
traversals. The use of the double underscore prefix in the name is just a convention to consider using and is not a
requirement. To use the DSL, bring it into scope with the using directive:
using Dsl;
using static Dsl.__Social;and then it can be called from the application as follows:
var connection = new DriverRemoteConnection(new GremlinClient(new GremlinServer("localhost", 8182)));
var social = Traversal().With(connection);
social.Persons("marko").Knows("josh");
social.Persons("marko").YoungestFriendsAge();
social.Persons().Filter(CreatedAtLeast(2)).Count();Differences
The biggest difference between Gremlin in .NET and the canonical version in Java is the casing of steps. Canonical
Gremlin utilizes camelCase as is typical in Java for function names, but C# utilizes PascalCase as it is more
typical in that language. Therefore, when viewing a typical Gremlin example written in Gremlin Console, the conversion
to C# usually just requires capitalization of the first letter in the step name, thus the following example in Groovy:
g.V().has('person','name','marko').
out('knows').
elementMap().toList()would become the following in C#:
g.V().Has("Person","name","marko").
Out("knows").
ElementMap().ToList();In addition to the uppercase change, also note the conversion of the single quotes to double quotes as is expected for declaring string values in C# and the addition of the semi-colon at the end of the line. In short, don’t forget to apply the common syntax expectations for C# when trying to convert an example of Gremlin from a different language.
Another common conversion issues lies in having to explicitly define generics, which can make canonical Gremlin appear much more complex in C# where type erasure is not a feature of the language. For example, the following example in Groovy:
g.V().repeat(__.out()).times(2).values('name')must be written as:
g.V().Repeat(__.Out()).Times(2).Values<string>("name");Gremlin allows for Map instances to include null keys, but null keys in C# Dictionary instances are not allowed.
It is therefore necessary to rewrite a traversal such as:
g.V().GroupCount<object>().By("age")where "age" is not a valid key for all vertices in a way that will remove the need for a null to be returned.
Finally, the enum construct for Cardinality cannot have functions attached to it the way it can be done in Java,
therefore cardinality functions that take a value like list(), set(), and single() are referenced from a
CardinalityValue class rather than Cardinality itself.
g.V().Has("age").GroupCount<object>().By("age")
g.V().HasLabel("person").GroupCount<object>().By("age")Either of the above two options accomplishes the desired goal as both prevent groupCount() from having to process
the possibility of null.
Limitations
-
The
subgraph()-step is not supported by any variant that is not running on the Java Virtual Machine as there is noGraphinstance to deserialize a result into on the client-side. A workaround is to replace the step withaggregate(local)and then convert those results to something the client can use locally.
Getting Started
This dotnet template helps getting started with Gremlin.Net. It creates a new C# console project that shows how to connect to a Gremlin Server with Gremlin.Net.
You can install the template with the dotnet CLI tool:
dotnet new -i Gremlin.Net.TemplateAfter the template is installed, a new project based on this template can be installed:
dotnet new gremlinSpecify the output directory for the new project which will then also be used as the name of the created project:
dotnet new gremlin -o MyFirstGremlinProjectApplication Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Dotnet. They
can be found in GitHub here
and are designed to connect to a running Gremlin Server configured with the
conf/gremlin-server.yaml and conf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration file
conf/gremlin-server.yaml. To start a clean server, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, using conf/gremlin-server-modern.yaml.
To start a server with the Modern graph preloaded, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlEach example can now be run with the following command in their respective project directories:
dotnet runGremlin-Python
 Apache TinkerPop’s Gremlin-Python implements Gremlin within
the Python language and can be used on any Python virtual machine including the popular
CPython machine. Python’s syntax has the same constructs as Java including
"dot notation" for function chaining (
Apache TinkerPop’s Gremlin-Python implements Gremlin within
the Python language and can be used on any Python virtual machine including the popular
CPython machine. Python’s syntax has the same constructs as Java including
"dot notation" for function chaining (a.b.c), round bracket function arguments (a(b,c)), and support for global
namespaces (a(b()) vs a(__.b())). As such, anyone familiar with Gremlin-Java will immediately be able to work
with Gremlin-Python. Moreover, there are a few added constructs to Gremlin-Python that make traversals a bit more
succinct.
To install Gremlin-Python, use Python’s pip package manager.
pip install gremlinpythonConnecting
The pattern for connecting is described in Connecting Gremlin and it basically distills down to
creating a GraphTraversalSource. A GraphTraversalSource is created from the anonymous traversal() method where
the "g" provided to the DriverRemoteConnection corresponds to the name of a GraphTraversalSource on the remote end.
g = traversal().with_(DriverRemoteConnection('http://localhost:8182/gremlin','g'))If you need to send additional headers in the HTTP connection, you can pass an optional headers parameter
to the DriverRemoteConnection constructor.
g = traversal().with_(DriverRemoteConnection(
'http://localhost:8182/gremlin', 'g', headers={'Header':'Value'}))Gremlin-Python contains an auth module that allows custom authentication implementation, with plain text and SigV4
authentication provided as reference.
# Plain text authentication
g = traversal().with_(DriverRemoteConnection(
'ws://localhost:8182/gremlin', 'g', auth=basic('stephen', 'password')))
# SigV4 authentication
g = traversal().with_(DriverRemoteConnection(
'ws://localhost:8182/gremlin', 'g', auth=sigv4(service-region, service-name)))If you authenticate to a remote Gremlin Server or Remote Gremlin Provider, this server normally has SSL activated and the HTTP url will start with 'https://'. If Gremlin-Server uses a self-signed certificate for SSL, Gremlin-Python needs access to a local copy of the CA certificate file (in openssl .pem format), to be specified in the SSL_CERT_FILE environment variable.
|
Note
|
If connecting from an inherently single-threaded Python process where blocking while waiting for Gremlin
traversals to complete is acceptable, it might be helpful to set pool_size and max_workers parameters to 1.
See the Configuration section just below. Examples where this could apply are serverless cloud functions or WSGI
worker processes.
|
Some connection options can also be set on individual requests made through the using with() step on the
TraversalSource. For instance to set request timeout to 500 milliseconds:
vertices = g.with_('evaluationTimeout', 500).V().out('knows').to_list()The following options are allowed on a per-request basis in this fashion: batchSize, bulkResults, language, materializeProperties,
userAgent, and evaluationTimeout.
Common Imports
There are a number of classes, functions and tokens that are typically used with Gremlin. The following imports provide most of the typical functionality required to use Gremlin:
from gremlin_python import statics
from gremlin_python.process.anonymous_traversal import traversal
from gremlin_python.process.graph_traversal import __
from gremlin_python.process.strategies import *
from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection
from gremlin_python.process.traversal import T
from gremlin_python.process.traversal import Order
from gremlin_python.process.traversal import Cardinality
from gremlin_python.process.traversal import CardinalityValue
from gremlin_python.process.traversal import Column
from gremlin_python.process.traversal import Direction
from gremlin_python.process.traversal import Operator
from gremlin_python.process.traversal import P
from gremlin_python.process.traversal import TextP
from gremlin_python.process.traversal import Pop
from gremlin_python.process.traversal import Scope
from gremlin_python.process.traversal import Barrier
from gremlin_python.process.traversal import Bindings
from gremlin_python.process.traversal import WithOptionsThese can be used analogously to how they are used in Gremlin-Java.
>>> g.V().has_label('person').has('age',P.gt(30)).order().by('age',Order.desc).to_list()
[v[6], v[4]]Moreover, by importing the statics of Gremlin-Python, the class prefixes can be omitted.
>>> statics.load_statics(globals())With statics loaded its possible to represent the above traversal as below.
>>> g.V().has_label('person').has('age',gt(30)).order().by('age',desc).to_list()
[v[6], v[4]]Statics includes all the __-methods and thus, anonymous traversals like __.out() can be expressed as below.
That is, without the __-prefix.
>>> g.V().repeat(out()).times(2).name.fold().to_list()
[['ripple', 'lop']]There may be situations where certain graphs may want a more exact data type than what Python will allow as a language.
To support these situations gremlin-python has a few special type classes that can be imported from statics. They
include:
from gremlin_python.statics import long # Java long
from gremlin_python.statics import timestamp # Java timestamp
from gremlin_python.statics import SingleByte # Java byte type
from gremlin_python.statics import SingleChar # Java char type
from gremlin_python.statics import GremlinType # Java ClassConfiguration
The following table describes the various configuration options for the Gremlin-Python Driver. They
can be passed to the Client or DriverRemoteConnection instance as keyword arguments:
| Key | Description | Default |
|---|---|---|
headers |
Additional headers that will be added to each request message. |
|
max_workers |
Maximum number of worker threads. |
Number of CPUs * 5 |
request_serializer |
The request serializer implementation. |
|
response_serializer |
The response serializer implementation. |
|
interceptors |
The request interceptors to run after request serialization. |
|
auth |
The authentication scheme to use when submitting requests that require authentication. |
|
pool_size |
The number of connections used by the pool. |
4 |
protocol_factory |
A callable that returns an instance of |
|
transport_factory |
A callable that returns an instance of |
|
enable_user_agent_on_connect |
Enables sending a user agent to the server during connection requests. More details can be found in provider docs here. |
True |
bulk_results |
Enables bulking of results on the server. |
False |
Note that the transport_factory can allow for additional configuration of the AiohttpTransport, which allows
pass through of the named parameters available in
AIOHTTP’s HTTP ClientSession,
and the ability to call the api from an event loop:
import ssl
...
g = traversal().with_(
DriverRemoteConnection('http://localhost:8182/gremlin','g',
transport_factory=lambda: AiohttpTransport(timeout=60,
max_line_size=100*1024*1024,
ssl_options=ssl.create_default_context(Purpose.CLIENT_AUTH))))Traversal Strategies
In order to add and remove traversal strategies from a traversal source, Gremlin-Python has a
TraversalStrategy class along with a collection of subclasses that mirror the standard Gremlin-Java strategies.
>>> g = g.with_strategies(SubgraphStrategy(vertices=has_label('person'),edges=has('weight',gt(0.5))))
>>> g.V().name.to_list()
['marko', 'vadas', 'josh', 'peter']
>>> g.V().out_e().element_map().to_list()
[{<T.id: 1>: 8, <T.label: 4>: 'knows', <Direction.IN: 2>: {<T.id: 1>: 4, <T.label: 4>: 'person'}, <Direction.OUT: 3>: {<T.id: 1>: 1, <T.label: 4>: 'person'}, 'weight': 1.0}]
>>> g = g.without_strategies(SubgraphStrategy)
>>> g.V().name.to_list()
['marko', 'vadas', 'lop', 'josh', 'ripple', 'peter']
>>> g.V().out_e().element_map().to_list()
[{<T.id: 1>: 9, <T.label: 4>: 'created', <Direction.IN: 2>: {<T.id: 1>: 3, <T.label: 4>: 'software'}, <Direction.OUT: 3>: {<T.id: 1>: 1, <T.label: 4>: 'person'}, 'weight': 0.4}, {<T.id: 1>: 7, <T.label: 4>: 'knows', <Direction.IN: 2>: {<T.id: 1>: 2, <T.label: 4>: 'person'}, <Direction.OUT: 3>: {<T.id: 1>: 1, <T.label: 4>: 'person'}, 'weight': 0.5}, {<T.id: 1>: 8, <T.label: 4>: 'knows', <Direction.IN: 2>: {<T.id: 1>: 4, <T.label: 4>: 'person'}, <Direction.OUT: 3>: {<T.id: 1>: 1, <T.label: 4>: 'person'}, 'weight': 1.0}, {<T.id: 1>: 10, <T.label: 4>: 'created', <Direction.IN: 2>: {<T.id: 1>: 5, <T.label: 4>: 'software'}, <Direction.OUT: 3>: {<T.id: 1>: 4, <T.label: 4>: 'person'}, 'weight': 1.0}, {<T.id: 1>: 11, <T.label: 4>: 'created', <Direction.IN: 2>: {<T.id: 1>: 3, <T.label: 4>: 'software'}, <Direction.OUT: 3>: {<T.id: 1>: 4, <T.label: 4>: 'person'}, 'weight': 0.4}, {<T.id: 1>: 12, <T.label: 4>: 'created', <Direction.IN: 2>: {<T.id: 1>: 3, <T.label: 4>: 'software'}, <Direction.OUT: 3>: {<T.id: 1>: 6, <T.label: 4>: 'person'}, 'weight': 0.2}]
>>> g = g.with_computer(workers=2,vertices=has('name','marko'))
>>> g.V().name.to_list()
['marko']
>>> g.V().out_e().value_map().with_(WithOptions.tokens).to_list()
[{<T.id: 1>: 9, <T.label: 4>: 'created', 'weight': 0.4}, {<T.id: 1>: 7, <T.label: 4>: 'knows', 'weight': 0.5}, {<T.id: 1>: 8, <T.label: 4>: 'knows', 'weight': 1.0}]|
Note
|
Many of the TraversalStrategy classes in Gremlin-Python are proxies to the respective strategy on
Apache TinkerPop’s JVM-based Gremlin traversal machine. As such, their apply(Traversal) method does nothing. However,
the strategy is encoded in the Gremlin-Python bytecode and transmitted to the Gremlin traversal machine for
re-construction machine-side.
|
Transactions
|
Important
|
4.0 Milestone Release - Transactions are currently disabled in this Milestone release. |
To get a full understanding of this section, it would be good to start by reading the Transactions section of this documentation, which discusses transactions in the general context of TinkerPop itself. This section builds on that content by demonstrating the transactional syntax for Python.
g = traversal().with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin'))
# Create a Transaction.
tx = g.tx()
# Spawn a new GraphTraversalSource, binding all traversals established from it to tx.
gtx = tx.begin()
try:
# Execute a traversal within the transaction.
gtx.add_v("person").property("name", "Lyndon").iterate(),
# Commit the transaction. The transaction can no longer be used and cannot be re-used.
# A new transaction can be spawned through g.tx().
# The context of g remains sessionless throughout the process.
tx.commit()
except Exception as e:
# Rollback the transaction if an error occurs.
tx.rollback()GValue Parameterization
A GValue is an encapsulation of a parameter name and value. A subset of gremlin steps
are able to accept GValues. When constructing a GraphTraversal with such steps in Python, a GValue may be passed in
the traversal to utilize a parameter in place of a literal.
g.V().has('name', GValue('name', 'marko'))
g.merge_v(GValue('vertexPattern', {'name': 'marko'}))Submitting Scripts
The Client class implementation/interface is based on the Java Driver, with some restrictions. Most notably,
Gremlin-Python does not yet implement the Cluster class. Instead, Client is instantiated directly.
Usage is as follows:
from gremlin_python.driver import client //1
client = client.Client('http://localhost:8182/gremlin', 'g') //2-
Import the Gremlin-Python
clientmodule. -
Opens a reference to
localhost- note that there are various configuration options that can be passed to theClientobject upon instantiation as keyword arguments.
Once a Client instance is ready, it is possible to issue some Gremlin:
result_set = client.submit('[1,2,3,4]') //1
future_results = result_set.all() //2
results = future_results.result() //3
assert results == [1, 2, 3, 4] //4
future_result_set = client.submit_async('[1,2,3,4]') //5
result_set = future_result_set.result() //6
result = result_set.one() //7
assert results == [1, 2, 3, 4] //8
assert result_set.done.done() //9
client.close() //10-
Submit a script that simply returns a
Listof integers. This method blocks until the request is written to the server and aResultSetis constructed. -
Even though the
ResultSetis constructed, it does not mean that the server has sent back the results (or even evaluated the script potentially). TheResultSetis just a holder that is awaiting the results from the server. Theallmethod returns aconcurrent.futures.Futurethat resolves to a list when it is complete. -
Block until the the script is evaluated and results are sent back by the server.
-
Verify the result.
-
Submit the same script to the server but don’t block.
-
Wait until request is written to the server and
ResultSetis constructed. -
Read a single result off the result stream.
-
Again, verify the result.
-
Verify that the all results have been read and stream is closed.
-
Close client and underlying pool connections.
Per Request Settings
The client.submit() functions accept a request_options which expects a dictionary. The request_options
provide a way to include options that are specific to the request made with the call to submit(). A good use-case for
this feature is to set a per-request override to the evaluationTimeout so that it only applies to the current
request.
result_set = client.submit('g.V().repeat(both()).times(100)', request_options={'evaluationTimeout': 5000})The following options are allowed on a per-request basis in this fashion: batchSize, requestId, userAgent, materializeProperties and
evaluationTimeout (formerly scriptEvaluationTimeout which is also supported but now deprecated).
|
Important
|
The preferred method for setting a per-request timeout for scripts is demonstrated above, but those familiar
with bytecode may try g.with(EVALUATION_TIMEOUT, 500) within a script. Scripts with multiple traversals and multiple
timeouts will be interpreted as a sum of all timeouts identified in the script for that request.
|
RequestOptions options = RequestOptions.build().timeout(500).create();
List<Result> result = client.submit("g.with(EVALUATION_TIMEOUT, 500).addV().iterate();" +
"g.addV().iterate();
"g.with(EVALUATION_TIMEOUT, 500).addV();", options).all().get();In the above example, RequestOptions defines a timeout of 500 milliseconds, but the script has three traversals with
two internal settings for the timeout using with(). The request timeout used by the server will therefore be 1000
milliseconds (overriding the 500 which itself was an override for whatever configuration was on the server).
Domain Specific Languages
Writing a Gremlin Domain Specific Language (DSL) in Python simply requires direct extension of several classes:
-
GraphTraversal- which exposes the various steps used in traversal writing -
__- which spawns anonymous traversals from steps -
GraphTraversalSource- which spawnsGraphTraversalinstances
The Social DSL based on the "modern" toy graph might look like this:
class SocialTraversal(GraphTraversal):
def knows(self, person_name):
return self.out('knows').has_label('person').has('name', person_name)
def youngest_friends_age(self):
return self.out('knows').has_label('person').values('age').min()
def created_at_least(self, number):
return self.out_e('created').count().is_(P.gte(number))
class __(AnonymousTraversal):
graph_traversal = SocialTraversal
@classmethod
def knows(cls, *args):
return cls.graph_traversal(None, None, Bytecode()).knows(*args)
@classmethod
def youngest_friends_age(cls, *args):
return cls.graph_traversal(None, None, Bytecode()).youngest_friends_age(*args)
@classmethod
def created_at_least(cls, *args):
return cls.graph_traversal(None, None, Bytecode()).created_at_least(*args)
class SocialTraversalSource(GraphTraversalSource):
def __init__(self, *args, **kwargs):
super(SocialTraversalSource, self).__init__(*args, **kwargs)
self.graph_traversal = SocialTraversal
def persons(self, *args):
traversal = self.get_graph_traversal()
traversal.bytecode.add_step('V')
traversal.bytecode.add_step('hasLabel', 'person')
if len(args) > 0:
traversal.bytecode.add_step('has', 'name', P.within(args))
return traversal|
Note
|
The AnonymousTraversal class above is just an alias for __ as in
from gremlin_python.process.graph_traversal import __ as AnonymousTraversal
|
Using the DSL is straightforward and just requires that the graph instance know the SocialTraversalSource should
be used:
social = traversal(SocialTraversalSource).with_remote(DriverRemoteConnection('ws://localhost:8182/gremlin','g'))
social.persons('marko').knows('josh')
social.persons('marko').youngest_friends_age()
social.persons().filter(__.created_at_least(2)).count()Syntactic Sugar
Python supports meta-programming and operator overloading. There are three uses of these techniques in Gremlin-Python that makes traversals a bit more concise.
>>> g.V().both()[1:3].to_list()
[v[2], v[4]]
>>> g.V().both()[1].to_list()
[v[2]]
>>> g.V().both().name.to_list()
['lop', 'lop', 'lop', 'vadas', 'josh', 'josh', 'josh', 'marko', 'marko', 'marko', 'peter', 'ripple']Differences
In situations where Python reserved words and global functions overlap with standard Gremlin steps and tokens, those bits of conflicting Gremlin get an underscore appended as a suffix:
Steps - all_(), and_(), any_(), as_(), filter_(), from_(), has_key_, id_(), is_(), in_(), max_(), min_(), not_(), or_(), range_(), sum_(), with_()
Tokens - Scope.global_, Direction.from_, Operator.sum_
In addition, the enum construct for Cardinality cannot have functions attached to it the way it can be done in Java,
therefore cardinality functions that take a value like list(), set(), and single() are referenced from a
CardinalityValue class rather than Cardinality itself.
Limitations
-
Traversals that return a
Setmight be coerced to aListin Python. In the case of Python, number equality is different from JVM languages which produces differentSetresults when those types are in use. When this case is detected during deserialization, theSetis coerced to aListso that traversals return consistent results within a collection across different languages. If aSetis needed then convertListresults toSetmanually. -
Gremlin is capable of returning
Dictionaryresults that use non-hashable keys (e.g. Dictionary as a key) and Python does not support that at a language level. Using GraphSON 3.0 or GraphBinary (after 3.5.0) makes it possible to return such results. However, it may not be possible to serialize these maps so they can’t be re-inserted (or round tripped). In all other cases, Gremlin that returns such results will need to be re-written to avoid that sort of key. -
The
floattype in Python is a double precision floating point number which is commonly referred to in other languages as adouble. This means that single precision floating point values will be deserialized into a double, so there will be a precision difference. -
Gremlin supports multiple fixed-width integers such as byte (1-byte), short (2-byte), and long (8-byte). These are deserialized into Python’s variable size
inttype. These numbers can’t be exactly round tripped because the original type information is lost during deserialization. During serialization, these numbers will try to be converted into a 4-byte integer which may throw exceptions if the value is too large or waste space if the value is very small. -
The Gremlin Char type is deserialized as a string and therefore can’t be round tripped as it will it will attempt to be serialized as a string.
-
Date and Duration types in Gremlin are deserialized as
datetime.datetimeanddatetime.timedeltarespectively ingremlin-python. This can lead to errors for large values because they exceed the maximum size allowed fordatetimeandtimedelta. -
In Gremlin, 1 isn’t equal to the boolean true value and 0 isn’t equal to the boolean false value, but they are equal in Python. This means that in
gremlin-pythonif these values are in aSet, you will get a different behavior than what is intended by Gremlin, since it follows Python’s behavior. -
The
subgraph()-step is not supported by any variant that is not running on the Java Virtual Machine as there is noGraphinstance to deserialize a result into on the client-side. A workaround is to replace the step withaggregate(local)and then convert those results to something the client can use locally. -
Use of the aiohttp library in the default transport requires the use of asyncio’s event loop to run the async functions. This can be an issue in situations where the application calling Gremlin-Python is already using an event loop. Certain types of event loops can be patched using nest-asyncio which allows Gremlin-Python to proceed without an error like "Cannot run the event loop while another loop is running". This is the preferred approach to avoiding the issue and can be enabled by passing
call_from_event_loop=Trueto theAiohttpTransportclass.However, in situations where the loop cannot be patched (e.g. uvloop), then the current suggested workaround is to run Gremlin-Python in a separate thread. This is not ideal for asynchronous web servers as the number of concurrent connections will be limited by the number of threads the system can handle. The following snippet shows how Gremlin-Python can be called from asynchronous code using a thread.
def print_vertices(): g = traversal().with(DriverRemoteConnection("ws://localhost:8182/gremlin")) # Do your traversal. async def run_in_thread(): running_loop = asyncio.get_running_loop() with ThreadPoolExecutor() as pool: await running_loop.run_in_executor(pool, print_vertices)
Application Examples
The TinkerPop source code contains some sample applications that demonstrate the basics of Gremlin-Python. They
can be found in GitHub here
and are designed to connect to a running Gremlin Server configured with the
conf/gremlin-server.yaml and conf/gremlin-server-modern.yaml files as included with the standard release packaging.
To run the examples, first download an image of Gremlin Server from Docker Hub:
docker pull tinkerpop/gremlin-serverThe remote connection and basic Gremlin examples can be run on a clean server, which uses the default configuration file
conf/gremlin-server.yaml. To start a clean server, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-serverThe traversal examples should be run on a server configured to start with the Modern toy graph, using conf/gremlin-server-modern.yaml.
To start a server with the Modern graph preloaded, launch a new container with docker run:
docker run -d -p 8182:8182 tinkerpop/gremlin-server conf/gremlin-server-modern.yamlEach example can now be run with the following commands:
python connections.py
python basic_gremlin.py
python modern_traversals.pyImplementations

TinkerPop offers several reference implementations of its interfaces that are not only meant for production usage, but also represent models by which different graph providers can build their systems. More specific documentation on how to build systems at this level of the API can be found in the Provider Documentation. The following sections describe the various reference implementations and their usage.
TinkerGraph-Gremlin
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>tinkergraph-gremlin</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency> TinkerGraph is a single machine, in-memory (with optional
persistence), non-transactional graph engine that provides both OLTP and OLAP functionality. It is deployed with
TinkerPop and serves as the reference implementation for other providers to study in order to understand the
semantics of the various methods of the TinkerPop API. Its status as a reference implementation does not however imply
that it is not suitable for production. TinkerGraph has many practical use cases in production applications and their
development. Some examples of TinkerGraph use cases include:
TinkerGraph is a single machine, in-memory (with optional
persistence), non-transactional graph engine that provides both OLTP and OLAP functionality. It is deployed with
TinkerPop and serves as the reference implementation for other providers to study in order to understand the
semantics of the various methods of the TinkerPop API. Its status as a reference implementation does not however imply
that it is not suitable for production. TinkerGraph has many practical use cases in production applications and their
development. Some examples of TinkerGraph use cases include:
-
Ad-hoc analysis of large immutable graphs that fit in memory.
-
Extract subgraphs, from larger graphs that don’t fit in memory, into TinkerGraph for further analysis or other purposes.
-
Use TinkerGraph as a sandbox to develop and debug complex traversals by simulating data from a larger graph inside a TinkerGraph.
Constructing a simple graph using TinkerGraph in Java is presented below:
Graph graph = TinkerGraph.open();
GraphTraversalSource g = traversal().with(graph);
Vertex marko = g.addV("person").property("name","marko").property("age",29).next();
Vertex lop = g.addV("software").property("name","lop").property("lang","java").next();
g.addE("created").from(marko).to(lop).property("weight",0.6d).iterate();The above Gremlin creates two vertices named "marko" and "lop" and connects them via a created-edge with a weight=0.6 property. The addition of these two vertices and the edge between them could also be done in a single Gremlin statement as follows:
g.addV("person").property("name","marko").property("age",29).as("m").
addV("software").property("name","lop").property("lang","java").as("l").
addE("created").from("m").to("l").property("weight",0.6d).iterate();|
Important
|
Pay attention to the fact that traversals end with next() or iterate(). These methods advance the
objects in the traversal stream and without those methods, the traversal does nothing. Review the
Result Iteration Section
of The Gremlin Console tutorial for more information.
|
Next, the graph can be queried as such.
g.V().has("name","marko").out("created").values("name")The g.V().has("name","marko") part of the query can be executed in two ways.
-
A linear scan of all vertices filtering out those vertices that don’t have the name "marko"
-
A
O(log(|V|))index lookup for all vertices with the name "marko"
Given the initial graph construction in the first code block, no index was defined and thus, a linear scan is executed. However, if the graph was constructed as such, then an index lookup would be used.
Graph g = TinkerGraph.open();
g.createIndex("name",Vertex.class)The execution times for a vertex lookup by property is provided below for both no-index and indexed version of TinkerGraph over the Grateful Dead graph.
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> clock(1000) {g.V().has('name','Garcia').iterate()} //// (1)
==>0.20351376499999999
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> graph.createIndex('name',Vertex.class)
==>null
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> clock(1000){g.V().has('name','Garcia').iterate()} //// (2)
==>0.026619543graph = TinkerGraph.open()
g = traversal().with(graph)
g.io('data/grateful-dead.xml').read().iterate()
clock(1000) {g.V().has('name','Garcia').iterate()} //// (1)
graph = TinkerGraph.open()
g = traversal().with(graph)
graph.createIndex('name',Vertex.class)
g.io('data/grateful-dead.xml').read().iterate()
clock(1000){g.V().has('name','Garcia').iterate()} //2-
Determine the average runtime of 1000 vertex lookups when no
name-index is defined. -
Determine the average runtime of 1000 vertex lookups when a
name-index is defined.
|
Important
|
Each graph system will have different mechanism by which indices and schemas are defined. TinkerPop does not require any conformance in this area. In TinkerGraph, the only definitions are around indices. With other graph systems, property value types, indices, edge labels, etc. may be required to be defined a priori to adding data to the graph. |
|
Note
|
TinkerGraph is distributed with Gremlin Server and is therefore automatically available to it for configuration. |
Data Types
TinkerGraph can store any Java Object for a property value. It is therefore important to take note of the types of
the values that are being used and it is often best to be explicit in terms of exactly what type is being used,
especially in the case of numbers.
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.addV().property('vp2',0.65780294)
==>v[0]
gremlin> g.addV().property('vp2',0.65780294f)
==>v[2]
gremlin> g.addV().property('vp2',0.65780294d)
==>v[4]
gremlin> g.V().has('vp2',0.65780294) //// (1)
==>v[0]
==>v[4]
gremlin> g.V().has('vp2',0.65780294f) //// (2)
==>v[2]
gremlin> g.V().has('vp2',0.65780294d) //// (3)
==>v[0]
==>v[4]graph = TinkerGraph.open()
g = traversal().with(graph)
g.addV().property('vp2',0.65780294)
g.addV().property('vp2',0.65780294f)
g.addV().property('vp2',0.65780294d)
g.V().has('vp2',0.65780294) //// (1)
g.V().has('vp2',0.65780294f) //// (2)
g.V().has('vp2',0.65780294d) //3-
In Gremlin Console,
0.65780294actually evaluates to aBigDecimal, which won’t match the specifically typedfloatproperty value. -
The explicit
floatwill only match thefloatproperty value. -
The explicit
doublewill only match thedoubleandBigDecimalvalues.
Unlike other graphs, the above demonstration shows that TinkerGraph does not do any form of type coercion (except for type coercion related to element identifiers as described in the tinkergraph-configuration).
Configuration
TinkerGraph has several settings that can be provided on creation via Configuration object:
| Property | Description |
|---|---|
gremlin.graph |
|
gremlin.tinkergraph.vertexIdManager |
The |
gremlin.tinkergraph.edgeIdManager |
The |
gremlin.tinkergraph.vertexPropertyIdManager |
The |
gremlin.tinkergraph.defaultVertexPropertyCardinality |
The default |
gremlin.tinkergraph.allowNullPropertyValues |
A boolean value that determines whether or not |
gremlin.tinkergraph.graphLocation |
The path and file name for where TinkerGraph should persist the graph data. If a
value is specified here, the |
gremlin.tinkergraph.graphFormat |
The format to use to serialize the graph which may be one of the following:
|
|
Note
|
To use transactions, configure gremlin.graph as
org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerTransactionGraph.
|
The IdManager settings above refer to how TinkerGraph will control identifiers for vertices, edges and vertex
properties. There are several options for each of these settings: ANY, LONG, INTEGER, UUID, or the fully
qualified class name of an IdManager implementation on the classpath. When not specified, the default values
for all settings is ANY, meaning that the graph will work with any object on the JVM as the identifier and will
generate new identifiers from Long when the identifier is not user supplied. TinkerGraph will also expect the
user to understand the types used for identifiers when querying, meaning that g.V(1) and g.V(1L) could return
two different vertices. LONG, INTEGER and UUID settings will try to coerce identifier values to the expected
type as well as generate new identifiers with that specified type.
|
Tip
|
Setting the IdManager to ANY also allows String type ID values to be used.
|
If the TinkerGraph is configured for persistence with gremlin.tinkergraph.graphLocation and
gremlin.tinkergraph.graphFormat, then the graph will be written to the specified location with the specified
format when Graph.close() is called. In addition, if these settings are present, TinkerGraph will attempt to
load the graph from the specified location.
|
Important
|
If choosing graphson as the gremlin.tinkergraph.graphFormat, be sure to also establish the various
IdManager settings as well to ensure that identifiers are properly coerced to the appropriate types as GraphSON
can lose the identifier’s type during serialization (i.e. it will assume Integer when the default for TinkerGraph
is Long, which could lead to load errors that result in a message like, "Vertex with id already exists").
|
It is important to consider the data being imported to TinkerGraph with respect to defaultVertexPropertyCardinality
setting. For example, if a .gryo file is known to contain multi-property data, be sure to set the default
cardinality to list or else the data will import as single. Consider the following:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io("data/tinkerpop-crew.kryo").read().iterate()
[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than one value: [vp[location->san diego], vp[location->santa cruz], vp[location->brussels], vp[location->santa fe]]. Only last value will be retained.
[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than one value: [vp[location->centreville], vp[location->dulles], vp[location->purcellville]]. Only last value will be retained.
[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than one value: [vp[location->bremen], vp[location->baltimore], vp[location->oakland], vp[location->seattle]]. Only last value will be retained.
[WARN] o.a.t.g.s.u.Attachable$Method - location has SINGLE cardinality but with more than one value: [vp[location->spremberg], vp[location->kaiserslautern], vp[location->aachen]]. Only last value will be retained.
gremlin> g.V().properties()
==>vp[name->marko]
==>vp[location->santa fe]
==>vp[name->stephen]
==>vp[location->purcellville]
==>vp[name->matthias]
==>vp[location->seattle]
==>vp[name->daniel]
==>vp[location->aachen]
==>vp[name->gremlin]
==>vp[name->tinkergraph]
gremlin> conf = new BaseConfiguration()
==>org.apache.commons.configuration2.BaseConfiguration@26c1244c
gremlin> conf.setProperty("gremlin.tinkergraph.defaultVertexPropertyCardinality","list")
==>null
gremlin> graph = TinkerGraph.open(conf)
==>tinkergraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> g.io("data/tinkerpop-crew.kryo").read().iterate()
gremlin> g.V().properties()
==>vp[name->marko]
==>vp[location->san diego]
==>vp[location->santa cruz]
==>vp[location->brussels]
==>vp[location->santa fe]
==>vp[name->stephen]
==>vp[location->centreville]
==>vp[location->dulles]
==>vp[location->purcellville]
==>vp[name->matthias]
==>vp[location->bremen]
==>vp[location->baltimore]
==>vp[location->oakland]
==>vp[location->seattle]
==>vp[name->daniel]
==>vp[location->spremberg]
==>vp[location->kaiserslautern]
==>vp[location->aachen]
==>vp[name->gremlin]
==>vp[name->tinkergraph]graph = TinkerGraph.open()
g = traversal().with(graph)
g.io("data/tinkerpop-crew.kryo").read().iterate()
g.V().properties()
conf = new BaseConfiguration()
conf.setProperty("gremlin.tinkergraph.defaultVertexPropertyCardinality","list")
graph = TinkerGraph.open(conf)
g = traversal().with(graph)
g.io("data/tinkerpop-crew.kryo").read().iterate()
g.V().properties()Transactions
TinkerGraph includes optional transaction support and thread-safety through the TinkerTransactionGraph class.
The default configuration of TinkerGraph remains non-transactional.
|
Note
|
This feature was first made available in TinkerPop 3.7.0. |
Transaction Semantics
TinkerTransactionGraph only has support for ThreadLocal transactions, so embedded graph transactions may not be fully
supported. You can think of the transaction as belonging to a thread, any traversals executed within the same thread
will share the same transaction even if you attempt to start a new transaction.
TinkerTransactionGraph provides the read committed transaction isolation level. This means that it will always try to
guard against dirty reads. While you may notice stricter isolation semantics in some cases, you should not depend on
this behavior as it may change in the future.
TinkerTransactionGraph employs optimistic locking as its locking strategy. This reduces complexity in the design as
there are fewer timeouts that the user needs to manage. However, a consequence of this approach is that a transaction
will throw a TransactionException if two different transactions attempt to lock the same element (see "Best Practices"
below).
Testing Remote Providers
These transaction semantics described above may not fit use cases for some production scenarios that require strict
ACID-like transactions. Therefore, it is recommended that TinkerTransactionGraph be used as a Graph for test
environments where you still require access to a Graph that supports transactions. TinkerTransactionGraph does fully
support TinkerPop’s Transaction interface which still makes it a useful Graph for exploring the
Transaction API.
A common scenario where this sort of testing is helpful is with Remote Graph Providers, where
developing unit tests might be hard against a graph service. Instead, configure TinkerTransactionGraph, either in an
embedded style if using Java or with Gremlin Server for other cases.
// consider this class that returns the results of some Gremlin. by constructing the
// GraphService in a way that takes a GraphTraversalSource it becomes possible to
// execute getPersons() under any graph system.
public class GraphService {
private final GraphTraversalSource g;
public GraphService(GraphTraversalSource g) {
this.g = g;
}
public List<Vertex> getPersons() {
return g.V().hasLabel("person").toList();
}
}
// when writing tests for the GraphService it becomes possible to configure the test
// to run in a variety of scenarios. here we decide that TinkerTransactionGraph is a
// suitable test graph replacement for our actual production graph.
public class GraphServiceTest {
private static final TinkerTransactionGraph graph = TinkerTransactionGraph().open();
private static final GraphTraversalSource g = traversal.with(graph);
private static final GraphService service = new GraphService(g);
@Test
public void shouldGetPersons() {
final List<Vertex> persons = service.getPersons();
assertEquals(6, persons.size());
}
}
// or perhaps, since we're using a remote graph provider, we feel it would be better to
// start Gremlin Server with a TinkerTransactionGraph configured using a docker container,
// embedding it directly in our tests or running it as a separate process like:
//
// bin/gremlin-server.sh conf/gremlin-server-transaction.yaml
//
// and then connect to it with a driver in more of an integration test style. obviously,
// with this approach you could also configure your production graph directly or use custom
// build options to trigger different test configurations for a more dynamic approach
public class GraphServiceTest {
private static final GraphTraversalSource g = traversal.with(
new DriverRemoteConnection('ws://localhost:8182/gremlin'));
private static final GraphService service = new GraphService(g);
@Test
public void shouldGetPersons() {
final List<Vertex> persons = service.getPersons();
assertEquals(6, persons.size());
}
}|
Warning
|
There can be subtle behavioral differences between TinkerGraph and the graph ultimately intended for use. Be aware of the differences when writing tests to ensure that you are testing behaviors of your applications appropriately. |
Best Practices
Errors can occur before a transaction gets committed. Specifically for TinkerTransactionGraph, you may encounter many
TransactionException errors in a highly concurrent environment due its optimistic approach to locking. Users should
follow the try-catch-rollback pattern described in the
transactions section in combination with
exponential backoff based retries to mitigate this issue.
Performance Considerations
While transactions impose minimal impact for mutating workloads, users should expect performance degradation for
read-only work relative to the non-transactional configuration. However, its approach to locking
(write-only, optimistic) and its in-memory nature, TinkerTransactionGraph is likely faster than other Graph
implementations that support transactions.
Examples
Constructing a simple graph using TinkerTransactionGraph in Java is presented below:
Graph graph = TinkerTransactionGraph.open();
g = traversal().with(graph)
GraphTraversalSource gtx = g.tx().begin();
try {
Vertex marko = gtx.addV("person").property("name","marko").property("age",29).next();
Vertex lop = gtx.addV("software").property("name","lop").property("lang","java").next();
gtx.addE("created").from(marko).to(lop).property("weight",0.6d).iterate();
gtx.tx().commit();
} catch (Exception ex) {
gtx.tx().rollback();
}The above Gremlin creates two vertices named "marko" and "lop" and connects them via a created-edge with a weight=0.6
property. In case of any errors rollback() will be called and no changes will be performed.
To use the embedded TinkerTransactionGraph in Gremlin Console:
gremlin> graph = TinkerTransactionGraph.open() //// (1)
==>tinkertransactiongraph[vertices:0 edges:0]
gremlin> g = traversal().with(graph) //// (2)
==>graphtraversalsource[tinkertransactiongraph[vertices:0 edges:0], standard]
gremlin> g.addV('test').property('name','one')
==>v[0]
gremlin> g.tx().commit() //// (3)
==>null
gremlin> g.V().valueMap()
==>[name:[one]]
gremlin> g.addV('test').property('name','two') //// (4)
==>v[2]
gremlin> g.V().valueMap()
==>[name:[one]]
==>[name:[two]]
gremlin> g.tx().rollback() //// (5)
==>null
gremlin> g.V().valueMap()
==>[name:[one]]graph = TinkerTransactionGraph.open() //// (1)
g = traversal().with(graph) //// (2)
g.addV('test').property('name','one')
g.tx().commit() //// (3)
g.V().valueMap()
g.addV('test').property('name','two') //// (4)
g.V().valueMap()
g.tx().rollback() //// (5)
g.V().valueMap()-
Open transactional graph.
-
Spawn a GraphTraversalSource with transactional graph.
-
Commit the add vertex operation
-
Add a second vertex without committing
-
Rollback the change
Neo4j-Gremlin (Deprecated)
|
Warning
|
Deprecated: Neo4j-Gremlin is not compatible with versions of Neo4j beyond 3.4 (Reached End of Life March 31, 2020). For this reason, use of Neo4j-Gremlin is not recommended for production environments. Neo4j-Gremlin is expected to remain compatible with upcoming releases of TinkerPop, however long term support is not guaranteed. Neo4j-Gremlin may be dropped from future versions of TinkerPop if compatibility cannot reasonably be maintained. Alternative TinkerPop enabled graph providers can be found on the TinkerPop site. |
|
Warning
|
Neo4j-Gremlin can work with JDK17, but requires the use of the --add-opens flag to be provided to the JVM
as follows: --add-opens=java.base/sun.nio.ch=ALL-UNNAMED.
|
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>neo4j-gremlin</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>
<!-- neo4j-tinkerpop-api-impl is NOT Apache 2 licensed - more information below -->
<!-- supports Neo4j 3.4.11 -->
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-tinkerpop-api-impl</artifactId>
<version>0.9-3.4.0</version>
</dependency>Neo4j, Inc. are the developers of the OLTP-based Neo4j graph database.
|
Warning
|
Unless under a commercial agreement with Neo4j, Inc., Neo4j is licensed
AGPL. The neo4j-gremlin module is licensed Apache2
because it only references the Apache2-licensed Neo4j API (not its implementation). Note that neither the
Gremlin Console nor Gremlin Server distribute with the Neo4j implementation
binaries. To access the binaries, use the :install command to download binaries from
Maven Central Repository.
|
|
Important
|
When connecting to existing Neo4j databases, ensure that this database is compatible with the version of
Neo4j that TinkerPop currently supports in the neo4j-tinkerpop-api-impl.
|
|
Tip
|
For configuring Grape, the dependency resolver of Groovy, please refer to the Gremlin Applications section. |
gremlin> :install org.apache.tinkerpop neo4j-gremlin 4.0.0-SNAPSHOT
==>Loaded: [org.apache.tinkerpop, neo4j-gremlin, 4.0.0-SNAPSHOT] - restart the console to use [tinkerpop.neo4j]
gremlin> :q
...
gremlin> :plugin use tinkerpop.neo4j
==>tinkerpop.neo4j activated
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[EmbeddedGraphDatabase [/tmp/neo4j]]|
Tip
|
To host Neo4j in Gremlin Server, the dependencies must first be "installed" or otherwise
copied to the Gremlin Server path. The automated method for doing this would be to execute
bin/gremlin-server.sh install org.apache.tinkerpop neo4j-gremlin 4.0.0-SNAPSHOT. Once installed, the Gremlin Server
configuration file must be edited to include the Neo4jGremlinPlugin as shown in conf/gremlin-server-neo4j.yaml.
|
Indices
Neo4j 2.x indices leverage vertex labels to partition the index space. TinkerPop does not provide method interfaces for defining schemas/indices for the underlying graph system. Thus, in order to create indices, it is important to call the Neo4j API directly.
|
Note
|
Neo4jGraphStep will attempt to discern which indices to use when executing a traversal of the form g.V().has().
|
The Gremlin-Console session below demonstrates Neo4j indices. For more information, please refer to the Neo4j documentation:
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[community single [/tmp/neo4j]]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]
gremlin> graph.cypher("CREATE INDEX ON :person(name)")
gremlin> graph.tx().commit() //// (1)
==>null
gremlin> g.addV('person').property('name','marko')
==>v[0]
gremlin> g.addV('dog').property('name','puppy')
==>v[1]
gremlin> g.V().hasLabel('person').has('name','marko').values('name')
==>marko
gremlin> graph.close()
==>null-
Schema mutations must happen in a different transaction than graph mutations
Below demonstrates the runtime benefits of indices and demonstrates how if there is no defined index (only vertex labels), a linear scan of the vertex-label partition is still faster than a linear scan of all vertices.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[community single [/tmp/neo4j]]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> g.tx().commit()
==>null
gremlin> clock(1000) {g.V().hasLabel('artist').has('name','Garcia').iterate()} //// (1)
==>0.35031228
gremlin> graph.cypher("CREATE INDEX ON :artist(name)") //// (2)
gremlin> g.tx().commit()
==>null
gremlin> Thread.sleep(5000) //// (3)
==>null
gremlin> clock(1000) {g.V().hasLabel('artist').has('name','Garcia').iterate()} //// (4)
==>0.061846079
gremlin> clock(1000) {g.V().has('name','Garcia').iterate()} //// (5)
==>0.6680353569999999
gremlin> graph.cypher("DROP INDEX ON :artist(name)") //// (6)
gremlin> g.tx().commit()
==>null
gremlin> graph.close()
==>null-
Find all artists whose name is Garcia which does a linear scan of the artist vertex-label partition.
-
Create an index for all artist vertices on their name property.
-
Neo4j indices are eventually consistent so this stalls to give the index time to populate itself.
-
Find all artists whose name is Garcia which uses the pre-defined schema index.
-
Find all vertices whose name is Garcia which requires a linear scan of all the data in the graph.
-
Drop the created index.
Cypher

NeoTechnology are the creators of the graph pattern-match query language Cypher.
It is possible to leverage Cypher from within Gremlin by using the Neo4jGraph.cypher() graph traversal method.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[community single [/tmp/neo4j]]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]
gremlin> g.io('data/tinkerpop-modern.kryo').read().iterate()
gremlin> graph.cypher('MATCH (a {name:"marko"}) RETURN a')
==>[a:v[0]]
gremlin> graph.cypher('MATCH (a {name:"marko"}) RETURN a').select('a').out('knows').values('name')
==>josh
==>vadas
gremlin> graph.close()
==>nullThus, like match()-step in Gremlin, it is possible to do a declarative pattern match and then move
back into imperative Gremlin.
|
Tip
|
For those developers using Gremlin Server against Neo4j, it is possible to do Cypher queries
by simply placing the Cypher string in graph.cypher(…) before submission to the server.
|
Multi-Label
TinkerPop requires every Element to have a single, immutable string label (i.e. a Vertex, Edge, and
VertexProperty). In Neo4j, a Node (vertex) can have an
arbitrary number of labels while a Relationship
(edge) can have one and only one. Furthermore, in Neo4j, Node labels are mutable while Relationship labels are
not. In order to handle this mismatch, three Neo4jVertex specific methods exist in Neo4j-Gremlin.
public Set<String> labels() // get all the labels of the vertex
public void addLabel(String label) // add a label to the vertex
public void removeLabel(String label) // remove a label from the vertexAn example use case is presented below.
gremlin> graph = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[community single [/tmp/neo4j]]
gremlin> g = traversal().withEmbedded(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]
gremlin> vertex = (Neo4jVertex) g.addV('human::animal').next() //// (1)
==>v[0]
gremlin> vertex.label() //// (2)
==>animal::human
gremlin> vertex.labels() //// (3)
==>animal
==>human
gremlin> vertex.addLabel('organism') //// (4)
==>null
gremlin> vertex.label()
==>animal::human::organism
gremlin> vertex.removeLabel('human') //// (5)
==>null
gremlin> vertex.labels()
==>animal
==>organism
gremlin> vertex.addLabel('organism') //// (6)
==>null
gremlin> vertex.labels()
==>animal
==>organism
gremlin> vertex.removeLabel('human') //// (7)
==>null
gremlin> vertex.label()
==>animal::organism
gremlin> g.V().has(label,'organism') //// (8)
gremlin> g.V().has(label,of('organism')) //// (9)
==>v[0]
gremlin> g.V().has(label,of('organism')).has(label,of('animal'))
==>v[0]
gremlin> g.V().has(label,of('organism').and(of('animal')))
==>v[0]
gremlin> graph.close()
==>null-
Typecasting to a
Neo4jVertexis only required in Java. -
The standard
Vertex.label()method returns all the labels in alphabetical order concatenated using::. -
Neo4jVertex.labels()method returns the individual labels as a set. -
Neo4jVertex.addLabel()method adds a single label. -
Neo4jVertex.removeLabel()method removes a single label. -
Labels are unique and thus duplicate labels don’t exist.
-
If a label that does not exist is removed, nothing happens.
-
P.eq()does a full string match and should only be used if multi-labels are not leveraged. -
LabelP.of()is specific toNeo4jGraphand used for multi-label matching.
|
Important
|
LabelP.of() is only required if multi-labels are leveraged. LabelP.of() is used when
filtering/looking-up vertices by their label(s) as the standard P.eq() does a direct match on the ::-representation
of vertex.label()
|
Configuration
The previous examples showed how to create a Neo4jGraph with the default configuration, but Neo4j has many other
options to initialize it that are native to Neo4j. In order to expose those, Neo4jGraph has an open(Configuration)
method which takes a standard Apache Configuration object. The same can be said of the standard method for creating
Graph instances with GraphFactory. Each configuration key that Neo4j has must simply be prefixed with
gremlin.neo4j.conf. and the suffix configuration key will be passed through to Neo4j.
|
Note
|
Gremlin Server uses GraphFactory to instantiate the Graph instances it manages, so the example below is also
relevant for that purpose as well.
|
For example, a standard configuration file called neo4j.properties that sets the Neo4j
dbms.index_sampling.background_enabled setting might look like:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph
gremlin.neo4j.directory=/tmp/neo4j
gremlin.neo4j.conf.dbms.index_sampling.background_enabled=truewhich can then be used as follows:
gremlin> graph = GraphFactory.open('neo4j.properties')
==>neo4jgraph[community single [/tmp/neo4j]]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[neo4jgraph[community single [/tmp/neo4j]], standard]Having this ability to set standard Neo4j configurations makes it possible to better control the initialization of Neo4j itself and provides the ability to enable certain features that would not otherwise be accessible.
Bolt Configuration
While Neo4jGraph enables Gremlin based queries, users may find it helpful to also be able to connect to that graph
with native Neo4j drivers and other tools from that space. It is possible to enable the
Bolt Protocol as a way to do this:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph
gremlin.neo4j.directory=/tmp/neo4j
gremlin.neo4j.conf.dbms.connector.0.type=BOLT
gremlin.neo4j.conf.dbms.connector.0.enabled=true
gremlin.neo4j.conf.dbms.connector.0.address=localhost:7687This configuration is especially relevant to Gremlin Server where one might want to connect to the same graph instance with both Gremlin and Cypher.
gremlin> :install org.neo4j.driver neo4j-java-driver 1.7.2
==>Loaded: [org.neo4j.driver, neo4j-java-driver, 1.7.2]
... // restart Gremlin Console
gremlin> import org.neo4j.driver.v1.*
==>org.apache.tinkerpop.gremlin.structure.*, org.apache.tinkerpop.gremlin.structure.util.*, ... org.neo4j.driver.v1.*
gremlin> driver = GraphDatabase.driver( "bolt://localhost:7687", AuthTokens.basic("neo4j", "neo4j"))
Oct 28, 2019 3:28:20 PM org.neo4j.driver.internal.logging.JULogger info
INFO: Direct driver instance 1385140107 created for server address localhost:7687
==>org.neo4j.driver.internal.InternalDriver@528f8f8b
gremlin> session = driver.session()
==>org.neo4j.driver.internal.NetworkSession@f3fcd59
gremlin> session.run( "CREATE (a:person {name: {name}, age: {age}})",
......1> Values.parameters("name", "stephen", "age", 29))
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
gremlin> :remote console
==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182] - type ':remote console' to return to local mode
gremlin> g.V().elementMap()
==>{id=0, label=person, name=stephen, age=29}High Availability Configuration
 TinkerPop supports running Neo4j with its fault tolerant master-slave
replication configuration, referred to as its
High Availability (HA) cluster. From the
TinkerPop perspective, configuring for HA is not that different than configuring for embedded mode as shown above. The
main difference is the usage of HA configuration options that enable the cluster. Once connected to a cluster, usage
from the TinkerPop perspective is largely the same.
TinkerPop supports running Neo4j with its fault tolerant master-slave
replication configuration, referred to as its
High Availability (HA) cluster. From the
TinkerPop perspective, configuring for HA is not that different than configuring for embedded mode as shown above. The
main difference is the usage of HA configuration options that enable the cluster. Once connected to a cluster, usage
from the TinkerPop perspective is largely the same.
In configuring for HA the most important thing to realize is that all Neo4j HA settings are simply passed through the
TinkerPop configuration settings given to the GraphFactory.open() or Neo4j.open() methods. For example, to
provide the all-important ha.server_id configuration option through TinkerPop, simply prefix that key with the
TinkerPop Neo4j key of gremlin.neo4j.conf.
The following properties demonstrates one of the three configuration files required to setup a simple three node HA cluster on the same machine instance:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph
gremlin.neo4j.directory=/tmp/neo4j.server1
gremlin.neo4j.conf.ha.server_id=1
gremlin.neo4j.conf.ha.initial_hosts=localhost:5001\,localhost:5002\,localhost:5003
gremlin.neo4j.conf.ha.host.coordination=localhost:5001
gremlin.neo4j.conf.ha.host.data=localhost:6001Assuming the intent is to configure this cluster completely within TinkerPop (perhaps within three separate Gremlin Server instances), the other two configuration files will be quite similar. The second will be:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph
gremlin.neo4j.directory=/tmp/neo4j.server2
gremlin.neo4j.conf.ha.server_id=2
gremlin.neo4j.conf.ha.initial_hosts=localhost:5001\,localhost:5002\,localhost:5003
gremlin.neo4j.conf.ha.host.coordination=localhost:5002
gremlin.neo4j.conf.ha.host.data=localhost:6002and the third will be:
gremlin.graph=org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph
gremlin.neo4j.directory=/tmp/neo4j.server3
gremlin.neo4j.conf.ha.server_id=3
gremlin.neo4j.conf.ha.initial_hosts=localhost:5001\,localhost:5002\,localhost:5003
gremlin.neo4j.conf.ha.host.coordination=localhost:5003
gremlin.neo4j.conf.ha.host.data=localhost:6003|
Important
|
The backslashes in the values provided to gremlin.neo4j.conf.ha.initial_hosts prevent that configuration
setting as being interpreted as a List.
|
Create three separate Gremlin Server configuration files and point each at one of these Neo4j files. Since these Gremlin
Server instances will be running on the same machine, ensure that each Gremlin Server instance has a unique port
setting in that Gremlin Server configuration file. Start each Gremlin Server instance to bring the HA cluster online.
|
Note
|
Neo4jGraph instances will block until all nodes join the cluster.
|
Neither Gremlin Server nor Neo4j will share transactions across the cluster. Be sure to either use Gremlin Server managed transactions or, if using a session without that option, ensure that all requests are being routed to the same server.
This example discussed use of Gremlin Server to demonstrate the HA configuration, but it is also easy to setup with
three Gremlin Console instances. Simply start three Gremlin Console instances and use GraphFactory to read those
configuration files to form the cluster. Furthermore, keep in mind that it is possible to have a Gremlin Console join
a cluster handled by two Gremlin Servers or Neo4j Enterprise. The only limits as to how the configuration can be
utilized are prescribed by Neo4j itself. Please refer to their
documentation for more information on how
this feature works.
Hadoop-Gremlin
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>hadoop-gremlin</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>![]() Hadoop is a distributed
computing framework that is used to process data represented across a multi-machine compute cluster. When the
data in the Hadoop cluster represents a TinkerPop graph, then Hadoop-Gremlin can be used to process the graph
using both TinkerPop’s OLTP and OLAP graph computing models.
Hadoop is a distributed
computing framework that is used to process data represented across a multi-machine compute cluster. When the
data in the Hadoop cluster represents a TinkerPop graph, then Hadoop-Gremlin can be used to process the graph
using both TinkerPop’s OLTP and OLAP graph computing models.
|
Important
|
This section assumes that the user has a Hadoop 3.x cluster functioning. For more information on getting
started with Hadoop, please see the
Single Node Setup
tutorial. Moreover, if using SparkGraphComputer it is advisable that the reader also
familiarize their self with and Spark (Quick Start).
|
Installing Hadoop-Gremlin
If using Gremlin Console, it is important to install the Hadoop-Gremlin plugin. Note that Hadoop-Gremlin requires a Gremlin Console restart after installing.
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin> :install org.apache.tinkerpop hadoop-gremlin 4.0.0-SNAPSHOT
==>loaded: [org.apache.tinkerpop, hadoop-gremlin, 4.0.0-SNAPSHOT] - restart the console to use [tinkerpop.hadoop]
gremlin> :q
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin> :plugin use tinkerpop.hadoop
==>tinkerpop.hadoop activated
gremlin>It is important that the CLASSPATH environmental variable references HADOOP_CONF_DIR and that the configuration
files in HADOOP_CONF_DIR contain references to a live Hadoop cluster. It is easy to verify a proper configuration
from within the Gremlin Console. If hdfs references the local file system, then there is a configuration issue.
gremlin> hdfs
==>storage[org.apache.hadoop.fs.LocalFileSystem@65bb9029] // BAD
gremlin> hdfs
==>storage[DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_1229457199_1, ugi=user (auth:SIMPLE)]]] // GOODThe HADOOP_GREMLIN_LIBS references locations that contain jars that should be uploaded to a respective
distributed cache (YARN or SparkServer).
Note that the locations in HADOOP_GREMLIN_LIBS can be colon-separated (:) and all jars from all locations will
be loaded into the cluster. Locations can be local paths (e.g. /path/to/libs), but may also be prefixed with a file
scheme to reference files or directories in different file systems (e.g. hdfs:///path/to/distributed/libs).
Typically, only the jars of the respective GraphComputer are required to be loaded.
Properties Files
HadoopGraph makes use of properties files which ultimately get turned into Apache configurations and/or
Hadoop configurations.
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
gremlin.hadoop.inputLocation=tinkerpop-modern.kryo
gremlin.hadoop.graphReader=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoInputFormat
gremlin.hadoop.outputLocation=output
gremlin.hadoop.graphWriter=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
gremlin.hadoop.jarsInDistributedCache=true
gremlin.hadoop.defaultGraphComputer=org.apache.tinkerpop.gremlin.spark.process.computer.SparkGraphComputer
####################################
# Spark Configuration #
####################################
spark.master=local[4]
spark.executor.memory=1g
spark.serializer=org.apache.tinkerpop.gremlin.spark.structure.io.gryo.GryoSerializer
gremlin.spark.persistContext=trueA review of the Hadoop-Gremlin specific properties are provided in the table below. For the respective OLAP
engines (SparkGraphComputer refer to their respective documentation for configuration options.
| Property | Description |
|---|---|
gremlin.graph |
The class of the graph to construct using GraphFactory. |
gremlin.hadoop.inputLocation |
The location of the input file(s) for Hadoop-Gremlin to read the graph from. |
gremlin.hadoop.graphReader |
The class that the graph input file(s) are read with (e.g. an |
gremlin.hadoop.outputLocation |
The location to write the computed HadoopGraph to. |
gremlin.hadoop.graphWriter |
The class that the graph output file(s) are written with (e.g. an |
gremlin.hadoop.jarsInDistributedCache |
Whether to upload the Hadoop-Gremlin jars to a distributed cache (necessary if jars are not on the machines' classpaths). |
gremlin.hadoop.defaultGraphComputer |
The default |
Along with the properties above, the numerous Hadoop specific properties can be added as needed to tune and parameterize the executed Hadoop-Gremlin job on the respective Hadoop cluster.
|
Important
|
As the size of the graphs being processed becomes large, it is important to fully understand how the underlying OLAP engine (e.g. Spark, etc.) works and understand the numerous parameterizations offered by these systems. Such knowledge can help alleviate out of memory exceptions, slow load times, slow processing times, garbage collection issues, etc. |
OLTP Hadoop-Gremlin
 It is possible to execute OLTP operations over a
It is possible to execute OLTP operations over a HadoopGraph.
However, realize that the underlying HDFS files are not random access and thus, to retrieve a vertex, a linear scan
is required. OLTP operations are useful for peeking into the graph prior to executing a long running OLAP job — e.g.
g.V().valueMap().limit(10).
|
Warning
|
OLTP operations on HadoopGraph are not efficient. They require linear scans to execute and are unreasonable
for large graphs. In such large graph situations, make use of TraversalVertexProgram
which is the OLAP Gremlin machine.
|
gremlin> hdfs.copyFromLocal('data/tinkerpop-modern.kryo', 'tinkerpop-modern.kryo')
==>null
gremlin> hdfs.ls()
==>rw------- ubuntu ubuntu 8875 .bash_history
==>rw-r--r-- ubuntu ubuntu 220 .bash_logout
==>rw-r--r-- ubuntu ubuntu 4151 .bashrc
==>rwx------ ubuntu ubuntu 4096 (D) .cache
==>rwx------ ubuntu ubuntu 4096 (D) .docker
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .dotnet
==>rw-rw-r-- ubuntu ubuntu 26068 .gremlin_groovy_history
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .groovy
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .java
==>rw------- ubuntu ubuntu 20 .lesshst
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .local
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .m2
==>rwxrwxr-x ubuntu docker 4096 (D) .npm
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .nuget
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .nvm
==>rw-r--r-- ubuntu ubuntu 807 .profile
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .sdkman
==>rwxr-xr-x ubuntu ubuntu 4096 (D) .sparkStaging
==>rwx------ ubuntu ubuntu 4096 (D) .ssh
==>rw-r--r-- ubuntu ubuntu 0 .sudo_as_admin_successful
==>rw------- ubuntu ubuntu 21858 .viminfo
==>rw-rw-r-- ubuntu ubuntu 183 .zshrc
==>rw-rw-r-- ubuntu ubuntu 178473115 3.6.8-docsBuilt.zip
==>rw-rw-r-- ubuntu ubuntu 178468811 3.6.8-finalDocs.zip
==>rw-rw-r-- ubuntu ubuntu 183482646 3.7.3-docsBuilt.zip
==>rw-rw-r-- ubuntu ubuntu 183484617 3.7.3-finalDocs.zip
==>rw-rw-r-- ubuntu ubuntu 183483449 3.7.4-snapshot-docs.zip
==>rwxrwxr-x ubuntu ubuntu 489 cleanGrapes.sh
==>rwxrwxr-x ubuntu ubuntu 75 startHadoop.sh
==>rwxrwxr-x ubuntu ubuntu 4096 (D) tinkerpop
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> g = traversal().with(graph)
==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], standard]
gremlin> g.V().count()
==>6
gremlin> g.V().out().out().values('name')
==>ripple
==>lop
gremlin> g.V().group().by{it.value('name')[1]}.by('name').next()
==>a=[marko, vadas]
==>e=[peter]
==>i=[ripple]
==>o=[lop, josh]hdfs.copyFromLocal('data/tinkerpop-modern.kryo', 'tinkerpop-modern.kryo')
hdfs.ls()
graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
g = traversal().with(graph)
g.V().count()
g.V().out().out().values('name')
g.V().group().by{it.value('name')[1]}.by('name').next()OLAP Hadoop-Gremlin
 Hadoop-Gremlin was designed to execute OLAP operations via
Hadoop-Gremlin was designed to execute OLAP operations via
GraphComputer. The OLTP examples presented previously are reproduced below, but using TraversalVertexProgram
for the execution of the Gremlin traversal.
A Graph in TinkerPop can support any number of GraphComputer implementations. Out of the box, Hadoop-Gremlin
supports the following two implementations.
-
SparkGraphComputer: Leverages Apache Spark to execute TinkerPop OLAP computations.-
The graph may fit within the total RAM of the cluster (supports larger graphs). Message passing is coordinated via Spark map/reduce/join operations on in-memory and disk-cached data (average speed traversals).
-
|
Tip
|
For those wanting to use the SugarPlugin with
their submitted traversal, do :remote config useSugar true as well as :plugin use tinkerpop.sugar at the start of
the Gremlin Console session if it is not already activated.
|
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
plugin activated: tinkerpop.hadoop
gremlin> :install org.apache.tinkerpop spark-gremlin 4.0.0-SNAPSHOT
==>loaded: [org.apache.tinkerpop, spark-gremlin, 4.0.0-SNAPSHOT] - restart the console to use [tinkerpop.spark]
gremlin> :q
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(4)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
plugin activated: tinkerpop.hadoop
gremlin> :plugin use tinkerpop.spark
==>tinkerpop.spark activated|
Warning
|
Hadoop and Spark all depend on many of the same libraries (e.g. ZooKeeper, Snappy, Netty, Guava, etc.). Unfortunately, typically these dependencies are not to the same versions of the respective libraries. As such, it is may be necessary to manually cleanup dependency conflicts among different plugins. |
SparkGraphComputer
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>spark-gremlin</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>![]() Spark is an Apache Software Foundation
project focused on general-purpose OLAP data processing. Spark provides a hybrid in-memory/disk-based distributed
computing model that is similar to Hadoop’s MapReduce model. Spark maintains a fluent function chaining DSL that is
arguably easier for developers to work with than native Hadoop MapReduce. Spark-Gremlin provides an implementation of
the bulk-synchronous parallel, distributed message passing algorithm within Spark and thus, any
Spark is an Apache Software Foundation
project focused on general-purpose OLAP data processing. Spark provides a hybrid in-memory/disk-based distributed
computing model that is similar to Hadoop’s MapReduce model. Spark maintains a fluent function chaining DSL that is
arguably easier for developers to work with than native Hadoop MapReduce. Spark-Gremlin provides an implementation of
the bulk-synchronous parallel, distributed message passing algorithm within Spark and thus, any VertexProgram can be
executed over SparkGraphComputer.
Furthermore the lib/ directory should be distributed across all machines in the SparkServer cluster. For this purpose
TinkerPop provides a helper script, which takes the Spark installation directory and the Spark machines as input:
bin/hadoop/init-tp-spark.sh /usr/local/spark spark@10.0.0.1 spark@10.0.0.2 spark@10.0.0.3Once the lib/ directory is distributed, SparkGraphComputer can be used as follows.
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> g = traversal().with(graph).withComputer(SparkGraphComputer)
==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]
gremlin> g.V().count()
==>6
gremlin> g.V().out().out().values('name')
==>lop
==>ripplegraph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
g = traversal().with(graph).withComputer(SparkGraphComputer)
g.V().count()
g.V().out().out().values('name')|
Note
|
We no longer support lambda executions via :remote on the Gremlin Console starting in TinkerPop 4.
|
The SparkGraphComputer algorithm leverages Spark’s caching abilities to reduce the amount of data shuffled across
the wire on each iteration of the VertexProgram. When the graph is loaded as a Spark RDD
(Resilient Distributed Dataset) it is immediately cached as graphRDD. The graphRDD is a distributed adjacency
list which encodes the vertex, its properties, and all its incident edges. On the first iteration, each vertex
(in parallel) is passed through VertexProgram.execute(). This yields an output of the vertex’s mutated state
(i.e. updated compute keys — propertyX) and its outgoing messages. This viewOutgoingRDD is then reduced to
viewIncomingRDD where the outgoing messages are sent to their respective vertices. If a MessageCombiner exists
for the vertex program, then messages are aggregated locally and globally to ultimately yield one incoming message
for the vertex. This reduce sequence is the "message pass." If the vertex program does not terminate on this
iteration, then the viewIncomingRDD is joined with the cached graphRDD and the process continues. When there
are no more iterations, there is a final join and the resultant RDD is stripped of its edges and messages. This
mapReduceRDD is cached and is processed by each MapReduce job in the
GraphComputer computation.

| Property | Description |
|---|---|
gremlin.hadoop.graphReader |
A class for reading a graph-based RDD (e.g. an |
gremlin.hadoop.graphWriter |
A class for writing a graph-based RDD (e.g. an |
gremlin.spark.graphStorageLevel |
What |
gremlin.spark.persistContext |
Whether to create a new |
gremlin.spark.persistStorageLevel |
What |
InputRDD and OutputRDD
If the provider/user does not want to use Hadoop InputFormats, it is possible to leverage Spark’s RDD
constructs directly. An InputRDD provides a read method that takes a SparkContext and returns a graphRDD. Likewise,
and OutputRDD is used for writing a graphRDD.
If the graph system provider uses an InputRDD, the RDD should maintain an associated org.apache.spark.Partitioner. By doing so,
SparkGraphComputer will not partition the loaded graph across the cluster as it has already been partitioned by the graph system provider.
This can save a significant amount of time and space resources. If the InputRDD does not have a registered partitioner,
SparkGraphComputer will partition the graph using a org.apache.spark.HashPartitioner with the number of partitions
being either the number of existing partitions in the input (i.e. input splits) or the user specified number of GraphComputer.workers().
Storage Levels
The SparkGraphComputer uses MEMORY_ONLY to cache the input graph and the output graph by default. Users should be aware of the impact of
different storage levels, since the default settings can quickly lead to memory issues on larger graphs. An overview of Spark’s persistence
settings is provided in Spark’s programming guide.
Using a Persisted Context
It is possible to persist the graph RDD between jobs within the SparkContext (e.g. SparkServer) by leveraging PersistedOutputRDD.
Note that gremlin.spark.persistContext should be set to true or else the persisted RDD will be destroyed when the SparkContext closes.
The persisted RDD is named by the gremlin.hadoop.outputLocation configuration. Similarly, PersistedInputRDD is used with respective
gremlin.hadoop.inputLocation to retrieve the persisted RDD from the SparkContext.
When using a persistent SparkContext the configuration used by the original Spark Configuration will be inherited by all threaded
references to that Spark Context. The exception to this rule are those properties which have a specific thread local effect.
-
spark.jobGroup.id
-
spark.job.description
-
spark.job.interruptOnCancel
-
spark.scheduler.pool
Finally, there is a spark object that can be used to manage persisted RDDs (see Interacting with Spark).
Using CloneVertexProgram
The CloneVertexProgram copies a whole graph from any graph InputFormat to any graph
OutputFormat. TinkerPop provides formats such as GraphSONOutputFormat, GryoOutputFormat or ScriptOutputFormat.
The example below takes a Hadoop graph as the input (in GryoInputFormat) and exports it as a GraphSON file
(GraphSONOutputFormat).
gremlin> hdfs.copyFromLocal('data/tinkerpop-modern.kryo', 'tinkerpop-modern.kryo')
==>null
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> graph.configuration().setProperty('gremlin.hadoop.graphWriter', 'org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONOutputFormat')
==>null
gremlin> graph.compute(SparkGraphComputer).program(CloneVertexProgram.build().create()).submit().get()
==>result[hadoopgraph[graphsoninputformat->graphsonoutputformat],memory[size:0]]
gremlin> hdfs.ls('output')
==>rwxr-xr-x ubuntu ubuntu 4096 (D) ~g
gremlin> hdfs.head('output/~g')
==>{"id":{"@type":"g:Int32","@value":1},"label":"person","outE":{"created":[{"id":{"@type":"g:Int32","@value":9},"inV":{"@type":"g:Int32","@value":3},"properties":{"weight":{"@type":"g:Double","@value":0.4}}}],"knows":[{"id":{"@type":"g:Int32","@value":7},"inV":{"@type":"g:Int32","@value":2},"properties":{"weight":{"@type":"g:Double","@value":0.5}}},{"id":{"@type":"g:Int32","@value":8},"inV":{"@type":"g:Int32","@value":4},"properties":{"weight":{"@type":"g:Double","@value":1.0}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":0},"value":"marko"}],"age":[{"id":{"@type":"g:Int64","@value":1},"value":{"@type":"g:Int32","@value":29}}]}}
==>{"id":{"@type":"g:Int32","@value":2},"label":"person","inE":{"knows":[{"id":{"@type":"g:Int32","@value":7},"outV":{"@type":"g:Int32","@value":1},"properties":{"weight":{"@type":"g:Double","@value":0.5}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":2},"value":"vadas"}],"age":[{"id":{"@type":"g:Int64","@value":3},"value":{"@type":"g:Int32","@value":27}}]}}
==>{"id":{"@type":"g:Int32","@value":3},"label":"software","inE":{"created":[{"id":{"@type":"g:Int32","@value":9},"outV":{"@type":"g:Int32","@value":1},"properties":{"weight":{"@type":"g:Double","@value":0.4}}},{"id":{"@type":"g:Int32","@value":11},"outV":{"@type":"g:Int32","@value":4},"properties":{"weight":{"@type":"g:Double","@value":0.4}}},{"id":{"@type":"g:Int32","@value":12},"outV":{"@type":"g:Int32","@value":6},"properties":{"weight":{"@type":"g:Double","@value":0.2}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":4},"value":"lop"}],"lang":[{"id":{"@type":"g:Int64","@value":5},"value":"java"}]}}
==>{"id":{"@type":"g:Int32","@value":4},"label":"person","inE":{"knows":[{"id":{"@type":"g:Int32","@value":8},"outV":{"@type":"g:Int32","@value":1},"properties":{"weight":{"@type":"g:Double","@value":1.0}}}]},"outE":{"created":[{"id":{"@type":"g:Int32","@value":10},"inV":{"@type":"g:Int32","@value":5},"properties":{"weight":{"@type":"g:Double","@value":1.0}}},{"id":{"@type":"g:Int32","@value":11},"inV":{"@type":"g:Int32","@value":3},"properties":{"weight":{"@type":"g:Double","@value":0.4}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":6},"value":"josh"}],"age":[{"id":{"@type":"g:Int64","@value":7},"value":{"@type":"g:Int32","@value":32}}]}}
==>{"id":{"@type":"g:Int32","@value":5},"label":"software","inE":{"created":[{"id":{"@type":"g:Int32","@value":10},"outV":{"@type":"g:Int32","@value":4},"properties":{"weight":{"@type":"g:Double","@value":1.0}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":8},"value":"ripple"}],"lang":[{"id":{"@type":"g:Int64","@value":9},"value":"java"}]}}
==>{"id":{"@type":"g:Int32","@value":6},"label":"person","outE":{"created":[{"id":{"@type":"g:Int32","@value":12},"inV":{"@type":"g:Int32","@value":3},"properties":{"weight":{"@type":"g:Double","@value":0.2}}}]},"properties":{"name":[{"id":{"@type":"g:Int64","@value":10},"value":"peter"}],"age":[{"id":{"@type":"g:Int64","@value":11},"value":{"@type":"g:Int32","@value":35}}]}}hdfs.copyFromLocal('data/tinkerpop-modern.kryo', 'tinkerpop-modern.kryo')
graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
graph.configuration().setProperty('gremlin.hadoop.graphWriter', 'org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONOutputFormat')
graph.compute(SparkGraphComputer).program(CloneVertexProgram.build().create()).submit().get()
hdfs.ls('output')
hdfs.head('output/~g')Input/Output Formats
 Hadoop-Gremlin provides various I/O formats — i.e. Hadoop
Hadoop-Gremlin provides various I/O formats — i.e. Hadoop
InputFormat and OutputFormat. All of the formats make use of an adjacency list
representation of the graph where each "row" represents a single vertex, its properties, and its incoming and
outgoing edges.
Gryo I/O Format
-
InputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoInputFormat -
OutputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
Gryo is a binary graph format that leverages Kryo to make a compact, binary representation of a vertex. It is recommended that users leverage Gryo given its space/time savings over text-based representations.
|
Note
|
The GryoInputFormat is splittable.
|
GraphSON I/O Format
-
InputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONInputFormat -
OutputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONOutputFormat
GraphSON is a JSON based graph format. GraphSON is a space-expensive graph format in that it is a text-based markup language. However, it is convenient for many developers to work with as its structure is simple (easy to create and parse).
The data below represents an adjacency list representation of the classic TinkerGraph toy graph in GraphSON format.
{"id":1,"label":"person","outE":{"created":[{"id":9,"inV":3,"properties":{"weight":0.4}}],"knows":[{"id":7,"inV":2,"properties":{"weight":0.5}},{"id":8,"inV":4,"properties":{"weight":1.0}}]},"properties":{"name":[{"id":0,"value":"marko"}],"age":[{"id":1,"value":29}]}}
{"id":2,"label":"person","inE":{"knows":[{"id":7,"outV":1,"properties":{"weight":0.5}}]},"properties":{"name":[{"id":2,"value":"vadas"}],"age":[{"id":3,"value":27}]}}
{"id":3,"label":"software","inE":{"created":[{"id":9,"outV":1,"properties":{"weight":0.4}},{"id":11,"outV":4,"properties":{"weight":0.4}},{"id":12,"outV":6,"properties":{"weight":0.2}}]},"properties":{"name":[{"id":4,"value":"lop"}],"lang":[{"id":5,"value":"java"}]}}
{"id":4,"label":"person","inE":{"knows":[{"id":8,"outV":1,"properties":{"weight":1.0}}]},"outE":{"created":[{"id":10,"inV":5,"properties":{"weight":1.0}},{"id":11,"inV":3,"properties":{"weight":0.4}}]},"properties":{"name":[{"id":6,"value":"josh"}],"age":[{"id":7,"value":32}]}}
{"id":5,"label":"software","inE":{"created":[{"id":10,"outV":4,"properties":{"weight":1.0}}]},"properties":{"name":[{"id":8,"value":"ripple"}],"lang":[{"id":9,"value":"java"}]}}
{"id":6,"label":"person","outE":{"created":[{"id":12,"inV":3,"properties":{"weight":0.2}}]},"properties":{"name":[{"id":10,"value":"peter"}],"age":[{"id":11,"value":35}]}}Script I/O Format
-
InputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.script.ScriptInputFormat -
OutputFormat:
org.apache.tinkerpop.gremlin.hadoop.structure.io.script.ScriptOutputFormat
ScriptInputFormat and ScriptOutputFormat take an arbitrary script and use that script to either read or write
Vertex objects, respectively. This can be considered the most general InputFormat/OutputFormat possible in that
Hadoop-Gremlin uses the user provided script for all reading/writing.
ScriptInputFormat
The data below represents an adjacency list representation of the classic TinkerGraph toy graph. First line reads,
"vertex 1, labeled person having 2 property values (marko and 29) has 3 outgoing edges; the first edge is
labeled knows, connects the current vertex 1 with vertex 2 and has a property value 0.4, and so on."
1:person:marko:29 knows:2:0.5,knows:4:1.0,created:3:0.4
2:person:vadas:27
3:project:lop:java
4:person:josh:32 created:3:0.4,created:5:1.0
5:project:ripple:java
6:person:peter:35 created:3:0.2There is no corresponding InputFormat that can parse this particular file (or some adjacency list variant of it).
As such, ScriptInputFormat can be used. With ScriptInputFormat a script is stored in HDFS and leveraged by each
mapper in the Hadoop job. The script must have the following method defined:
def parse(String line) { ... }In order to create vertices and edges, the parse() method gets access to a global variable named graph, which holds
the local StarGraph for the current line/vertex.
An appropriate parse() for the above adjacency list file is:
def parse(line) {
def parts = line.split(/ /)
def (id, label, name, x) = parts[0].split(/:/).toList()
def v1 = graph.addVertex(T.id, id, T.label, label)
if (name != null) v1.property('name', name) // first value is always the name
if (x != null) {
// second value depends on the vertex label; it's either
// the age of a person or the language of a project
if (label.equals('project')) v1.property('lang', x)
else v1.property('age', Integer.valueOf(x))
}
if (parts.length == 2) {
parts[1].split(/,/).grep { !it.isEmpty() }.each {
def (eLabel, refId, weight) = it.split(/:/).toList()
def v2 = graph.addVertex(T.id, refId)
v1.addOutEdge(eLabel, v2, 'weight', Double.valueOf(weight))
}
}
return v1
}The resultant Vertex denotes whether the line parsed yielded a valid Vertex. As such, if the line is not valid
(e.g. a comment line, a skip line, etc.), then simply return null.
ScriptOutputFormat Support
The principle above can also be used to convert a vertex to an arbitrary String representation that is ultimately
streamed back to a file in HDFS. This is the role of ScriptOutputFormat. ScriptOutputFormat requires that the
provided script maintains a method with the following signature:
def stringify(Vertex vertex) { ... }An appropriate stringify() to produce output in the same format that was shown in the ScriptInputFormat sample is:
def stringify(vertex) {
def v = vertex.values('name', 'age', 'lang').inject(vertex.id(), vertex.label()).join(':')
def outE = vertex.outE().map {
def e = it.get()
e.values('weight').inject(e.label(), e.inV().next().id()).join(':')
}.join(',')
return [v, outE].join('\t')
}Storage Systems
Hadoop-Gremlin provides two implementations of the Storage API:
-
FileSystemStorage: Access HDFS and local file system data. -
SparkContextStorage: Access Spark persisted RDD data.
Interacting with HDFS
The distributed file system of Hadoop is called HDFS.
The results of any OLAP operation are stored in HDFS accessible via hdfs. For local file system access, there is fs.
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();
==>result[hadoopgraph[gryoinputformat->gryooutputformat],memory[size:1]]
gremlin> hdfs.ls()
==>rw------- ubuntu ubuntu 8875 .bash_history
==>rw-r--r-- ubuntu ubuntu 220 .bash_logout
==>rw-r--r-- ubuntu ubuntu 4151 .bashrc
==>rwx------ ubuntu ubuntu 4096 (D) .cache
==>rwx------ ubuntu ubuntu 4096 (D) .docker
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .dotnet
==>rw-rw-r-- ubuntu ubuntu 26786 .gremlin_groovy_history
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .groovy
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .java
==>rw------- ubuntu ubuntu 20 .lesshst
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .local
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .m2
==>rwxrwxr-x ubuntu docker 4096 (D) .npm
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .nuget
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .nvm
==>rw-r--r-- ubuntu ubuntu 807 .profile
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .sdkman
==>rwxr-xr-x ubuntu ubuntu 4096 (D) .sparkStaging
==>rwx------ ubuntu ubuntu 4096 (D) .ssh
==>rw-r--r-- ubuntu ubuntu 0 .sudo_as_admin_successful
==>rw------- ubuntu ubuntu 21858 .viminfo
==>rw-rw-r-- ubuntu ubuntu 183 .zshrc
==>rw-rw-r-- ubuntu ubuntu 178473115 3.6.8-docsBuilt.zip
==>rw-rw-r-- ubuntu ubuntu 178468811 3.6.8-finalDocs.zip
==>rw-rw-r-- ubuntu ubuntu 183482646 3.7.3-docsBuilt.zip
==>rw-rw-r-- ubuntu ubuntu 183484617 3.7.3-finalDocs.zip
==>rw-rw-r-- ubuntu ubuntu 183483449 3.7.4-snapshot-docs.zip
==>rwxrwxr-x ubuntu ubuntu 489 cleanGrapes.sh
==>rwxrwxr-x ubuntu ubuntu 75 startHadoop.sh
==>rwxrwxr-x ubuntu ubuntu 4096 (D) tinkerpop
gremlin> hdfs.ls('output')
==>rwxr-xr-x ubuntu ubuntu 4096 (D) clusterCount
==>rwxr-xr-x ubuntu ubuntu 4096 (D) ~g
gremlin> hdfs.head('output', GryoInputFormat)
==>v[4]
==>v[1]
==>v[6]
==>v[3]
==>v[5]
==>v[2]
gremlin> hdfs.head('output', 'clusterCount', SequenceFileInputFormat)
==>2
gremlin> hdfs.rm('output')
==>true
gremlin> hdfs.ls()
==>rw------- ubuntu ubuntu 8875 .bash_history
==>rw-r--r-- ubuntu ubuntu 220 .bash_logout
==>rw-r--r-- ubuntu ubuntu 4151 .bashrc
==>rwx------ ubuntu ubuntu 4096 (D) .cache
==>rwx------ ubuntu ubuntu 4096 (D) .docker
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .dotnet
==>rw-rw-r-- ubuntu ubuntu 26784 .gremlin_groovy_history
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .groovy
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .java
==>rw------- ubuntu ubuntu 20 .lesshst
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .local
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .m2
==>rwxrwxr-x ubuntu docker 4096 (D) .npm
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .nuget
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .nvm
==>rw-r--r-- ubuntu ubuntu 807 .profile
==>rwxrwxr-x ubuntu ubuntu 4096 (D) .sdkman
==>rwxr-xr-x ubuntu ubuntu 4096 (D) .sparkStaging
==>rwx------ ubuntu ubuntu 4096 (D) .ssh
==>rw-r--r-- ubuntu ubuntu 0 .sudo_as_admin_successful
==>rw------- ubuntu ubuntu 21858 .viminfo
==>rw-rw-r-- ubuntu ubuntu 183 .zshrc
==>rw-rw-r-- ubuntu ubuntu 178473115 3.6.8-docsBuilt.zip
==>rw-rw-r-- ubuntu ubuntu 178468811 3.6.8-finalDocs.zip
==>rw-rw-r-- ubuntu ubuntu 183482646 3.7.3-docsBuilt.zip
==>rw-rw-r-- ubuntu ubuntu 183484617 3.7.3-finalDocs.zip
==>rw-rw-r-- ubuntu ubuntu 183483449 3.7.4-snapshot-docs.zip
==>rwxrwxr-x ubuntu ubuntu 489 cleanGrapes.sh
==>rwxrwxr-x ubuntu ubuntu 75 startHadoop.sh
==>rwxrwxr-x ubuntu ubuntu 4096 (D) tinkerpopgraph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();
hdfs.ls()
hdfs.ls('output')
hdfs.head('output', GryoInputFormat)
hdfs.head('output', 'clusterCount', SequenceFileInputFormat)
hdfs.rm('output')
hdfs.ls()Interacting with Spark
If a Spark context is persisted, then Spark RDDs will remain the Spark cache and accessible over subsequent jobs.
RDDs are retrieved and saved to the SparkContext via PersistedInputRDD and PersistedOutputRDD respectively.
Persisted RDDs can be accessed using spark.
gremlin> Spark.create('local[4]')
==>org.apache.spark.SparkContext@6c96346b
gremlin> graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> graph.configuration().setProperty('gremlin.hadoop.graphWriter', PersistedOutputRDD.class.getCanonicalName())
==>null
gremlin> graph.configuration().setProperty('gremlin.spark.persistContext',true)
==>null
gremlin> graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();
==>result[hadoopgraph[persistedinputrdd->persistedoutputrdd],memory[size:1]]
gremlin> spark.ls()
gremlin> spark.ls('output')
==>output/clusterCount [Memory Deserialized 1x Replicated]
==>output/~g [Memory Deserialized 1x Replicated]
gremlin> spark.head('output', PersistedInputRDD)
==>v[4]
==>v[1]
==>v[6]
==>v[3]
==>v[5]
==>v[2]
gremlin> spark.head('output', 'clusterCount', PersistedInputRDD)
==>2
gremlin> spark.rm('output')
==>true
gremlin> spark.ls()Spark.create('local[4]')
graph = GraphFactory.open('conf/hadoop/hadoop-gryo.properties')
graph.configuration().setProperty('gremlin.hadoop.graphWriter', PersistedOutputRDD.class.getCanonicalName())
graph.configuration().setProperty('gremlin.spark.persistContext',true)
graph.compute(SparkGraphComputer).program(PeerPressureVertexProgram.build().create(graph)).mapReduce(ClusterCountMapReduce.build().memoryKey('clusterCount').create()).submit().get();
spark.ls()
spark.ls('output')
spark.head('output', PersistedInputRDD)
spark.head('output', 'clusterCount', PersistedInputRDD)
spark.rm('output')
spark.ls()Gremlin Compilers
SPARQL-Gremlin
The SPARQL-Gremlin compiler, transforms SPARQL queries into Gremlin traversals. It uses the Apache Jena SPARQL processor ARQ, which provides access to a syntax tree of a SPARQL query.
The goal of this work is to bridge the query interoperability gap between the two famous, yet fairly disconnected, graph communities: Semantic Web (which relies on the RDF data model) and Graph database (which relies on property graph data model).
|
Note
|
The foundational research work on SPARQL-Gremlin compiler (aka Gremlinator) can be found in the Gremlinator paper. This paper presents the graph query language semantics of SPARQL and Gremlin, and a formal mapping between SPARQL pattern matching graph patterns and Gremlin traversals. |
<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>sparql-gremlin</artifactId>
<version>4.0.0-SNAPSHOT</version>
</dependency>The SPARQL-Gremlin compiler converts SPARQL queries into Gremlin so that they can be executed across any TinkerPop-enabled graph system. To use this compiler in the Gremlin Console, first install and activate the "tinkerpop.sparql" plugin:
gremlin> :install org.apache.tinkerpop sparql-gremlin 4.0.0-SNAPSHOT
==>Loaded: [org.apache.tinkerpop, sparql-gremlin, 4.0.0-SNAPSHOT]
gremlin> :plugin use tinkerpop.sparql
==>tinkerpop.sparql activatedInstalling this plugin will download appropriate dependencies and import certain classes to the console so that they may be used as follows:
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = traversal(SparqlTraversalSource).with(graph) //// (1)
==>sparqltraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.sparql("""SELECT ?name ?age
WHERE { ?person v:name ?name . ?person v:age ?age }
ORDER BY ASC(?age)""") //// (2)
==>[name:vadas,age:27]
==>[name:marko,age:29]
==>[name:josh,age:32]
==>[name:peter,age:35]graph = TinkerFactory.createModern()
g = traversal(SparqlTraversalSource).with(graph) //// (1)
g.sparql("""SELECT ?name ?age
WHERE { ?person v:name ?name . ?person v:age ?age }
ORDER BY ASC(?age)""") //2-
Define
gas aTraversalSourcethat uses theSparqlTraversalSource- by default, thetraversal()method usually returns aGraphTraversalSourcewhich includes the standard Gremlin starts steps likeV()orE(). In this case, theSparqlTraversalSourceenables starts steps that are specific to SPARQL only - in this case thesparql()start step. -
Execute a SPARQL query against the TinkerGraph instance. The
SparqlTraversalSourceuses a TraversalStrategy to transparently converts that SPARQL query into a standard Gremlin traversal and then when finally iterated, executes that against the TinkerGraph.
Prefixes
The SPARQL-Gremlin compiler supports the following prefixes to traverse the graph:
| Prefix | Purpose |
|---|---|
|
access to vertex id, label or property value |
|
out-edge traversal |
|
property traversal |
Note that element IDs and labels are treated like normal properties, hence they can be accessed using the same pattern:
gremlin> g.sparql("""SELECT ?name ?id ?label
WHERE {
?element v:name ?name .
?element v:id ?id .
?element v:label ?label .}""")
==>[name:marko,id:1,label:person]
==>[name:vadas,id:2,label:person]
==>[name:lop,id:3,label:software]
==>[name:josh,id:4,label:person]
==>[name:ripple,id:5,label:software]
==>[name:peter,id:6,label:person]g.sparql("""SELECT ?name ?id ?label
WHERE {
?element v:name ?name .
?element v:id ?id .
?element v:label ?label .}""")Supported Queries
The SPARQL-Gremlin compiler currently supports translation of the SPARQL 1.0 specification, especially SELECT
queries, though there is an on-going effort to cover the entire SPARQL 1.1 query feature spectrum. The supported
SPARQL query types are:
-
Union
-
Optional
-
Order-By
-
Group-By
-
STAR-shaped or neighbourhood queries
-
Query modifiers, such as:
-
Filter with restrictions
-
Count
-
LIMIT
-
OFFSET
-
Limitations
The current implementation of SPARQL-Gremlin compiler (i.e. SPARQL-Gremlin) does not support the following cases:
-
SPARQL queries with variables in the predicate position are not currently covered, with an exception of the following case:
g.sparql("""SELECT * WHERE { ?x ?y ?z . }""")-
A SPARQL Union query with un-balanced patterns, i.e. a gremlin union traversal can only be generated if the input SPARQL query has the same number of patterns on both the side of the union operator. For instance, the following SPARQL query cannot be mapped, since a union is executed between different number of graph patterns (two patterns
union1 pattern).
g.sparql("""SELECT *
WHERE {
{?person e:created ?software .
?person v:name "josh" .}
UNION
{?software v:lang "java" .} }""")-
A non-Group key variable cannot be projected in a SPARQL query. This is a SPARQL language limitation rather than that of Gremlin/TinkerPop. Apache Jena throws the exception "Non-group key variable in SELECT" if this occurs. For instance, in a SPARQL query with GROUP-BY clause, only the variable on which the grouping is declared, can be projected. The following query is valid:
g.sparql("""SELECT ?age
WHERE {
?person v:label "person" .
?person v:age ?age .
?person v:name ?name .} GROUP BY (?age)""")Whereas, the following SPARQL query will be invalid:
g.sparql("""SELECT ?person
WHERE {
?person v:label "person" .
?person v:age ?age .
?person v:name ?name .} GROUP BY (?age)""")-
In a SPARQL query with an ORDER-BY clause, the ordering occurs with respect to the first projected variable in the query. It is possible to choose any number of variable to be projected, however, the first variable in the selection will be the ordering decider. For instance, in the query:
g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:age ?age .
?person v:name ?name . } ORDER BY (?age)""")the result set will be ordered according to the ?name variable (in ascending order by default) despite having passed
?age in the order by. Whereas, for the following query:
g.sparql("""SELECT ?age ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person v:name ?name . } ORDER BY (?age)""")the result set will be ordered according to the ?age (as it is the first projected variable). Finally, for the
select all case (SELECT *):
g.sparql("""SELECT *
WHERE { ?person v:label "person" . ?person v:age ?age . ?person v:name ?name . } ORDER BY (?age)""")the the variable encountered first will be the ordering decider, i.e. since we have ?person encountered first,
the result set will be ordered according to the ?person variable (which are vertex id).
-
In the current implementation,
OPTIONALclause doesn’t work under nesting withUNIONclause (i.e. multiple optional clauses with in a union clause) andORDER-Byclause (i.e. declaring ordering over triple patterns within optional clauses). Everything else with SPARQLOPTIONALworks just fine.
Examples
The following section presents examples of SPARQL queries that are currently covered by the SPARQL-Gremlin compiler.
Select All
Select all vertices in the graph.
gremlin> g.sparql("""SELECT * WHERE { }""")
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]g.sparql("""SELECT * WHERE { }""")Match Constant Values
Select all vertices with the label person.
gremlin> g.sparql("""SELECT * WHERE { ?person v:label "person" .}""")
==>v[1]
==>v[2]
==>v[4]
==>v[6]g.sparql("""SELECT * WHERE { ?person v:label "person" .}""")Select Specific Elements
Select the values of the properties name and age for each person vertex.
gremlin> g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:name ?name .
?person v:age ?age . }""")
==>[name:marko,age:29]
==>[name:vadas,age:27]
==>[name:josh,age:32]
==>[name:peter,age:35]g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:name ?name .
?person v:age ?age . }""")Pattern Matching
Select only those persons who created a project.
gremlin> g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:name ?name .
?person v:age ?age .
?person e:created ?project . }""")
==>[name:marko,age:29]
==>[name:josh,age:32]
==>[name:josh,age:32]
==>[name:peter,age:35]g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:name ?name .
?person v:age ?age .
?person e:created ?project . }""")Filtering
Select only those persons who are older than 30.
gremlin> g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:name ?name .
?person v:age ?age .
FILTER (?age > 30) }""")
==>[name:josh,age:32]
==>[name:peter,age:35]g.sparql("""SELECT ?name ?age
WHERE {
?person v:label "person" .
?person v:name ?name .
?person v:age ?age .
FILTER (?age > 30) }""")Deduplication
Select the distinct names of the created projects.
gremlin> g.sparql("""SELECT DISTINCT ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person e:created ?project .
?project v:name ?name .
FILTER (?age > 30)}""")
==>ripple
==>lopg.sparql("""SELECT DISTINCT ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person e:created ?project .
?project v:name ?name .
FILTER (?age > 30)}""")Multiple Filters
Select the distinct names of all Java projects.
gremlin> g.sparql("""SELECT DISTINCT ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person e:created ?project .
?project v:name ?name .
?project v:lang ?lang .
FILTER (?age > 30 && ?lang = "java") }""")
==>ripple
==>lopg.sparql("""SELECT DISTINCT ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person e:created ?project .
?project v:name ?name .
?project v:lang ?lang .
FILTER (?age > 30 && ?lang = "java") }""")Union
Select all persons who have developed a software in java using union.
gremlin> g.sparql("""SELECT *
WHERE {
{?person e:created ?software .}
UNION
{?software v:lang "java" .} }""")
==>[software:v[3],person:v[1]]
==>[software:v[3]]
==>[software:v[5],person:v[4]]
==>[software:v[3],person:v[4]]
==>[software:v[5]]
==>[software:v[3],person:v[6]]g.sparql("""SELECT *
WHERE {
{?person e:created ?software .}
UNION
{?software v:lang "java" .} }""")Optional
Return the names of the persons who have created a software in java and optionally python.
g.sparql("""SELECT ?person
WHERE {
?person v:label "person" .
?person e:created ?software .
?software v:lang "java" .
OPTIONAL {?software v:lang "python" . }}""")Order By
Select all vertices with the label person and order them by their age.
gremlin> g.sparql("""SELECT ?age ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person v:name ?name .
} ORDER BY (?age)""")
==>[age:27,name:vadas]
==>[age:29,name:marko]
==>[age:32,name:josh]
==>[age:35,name:peter]g.sparql("""SELECT ?age ?name
WHERE {
?person v:label "person" .
?person v:age ?age .
?person v:name ?name .
} ORDER BY (?age)""")Group By
Select all vertices with the label person and group them by their age.
gremlin> g.sparql("""SELECT ?age
WHERE {
?person v:label "person" .
?person v:age ?age .
} GROUP BY (?age)""")
==>[32:[32],35:[35],27:[27],29:[29]]g.sparql("""SELECT ?age
WHERE {
?person v:label "person" .
?person v:age ?age .
} GROUP BY (?age)""")Mixed/complex/aggregation-based queries
Count the number of projects which have been created by persons under the age of 30 and group them by age. Return only the top two.
g.sparql("""SELECT (COUNT(?project) as ?p)
WHERE {
?person v:label "person" .
?person v:age ?age . FILTER (?age < 30)
?person e:created ?project .
} GROUP BY (?age) LIMIT 2""")Meta-Property Access
Accessing the Meta-Property of a graph element. Meta-Property can be perceived as the reified statements in an RDF graph.
gremlin> g = traversal(SparqlTraversalSource).with(graph)
==>sparqltraversalsource[tinkergraph[vertices:6 edges:14], standard]
gremlin> g.sparql("""SELECT ?name ?startTime
WHERE {
?person v:name "daniel" .
?person p:location ?location .
?location v:value ?name .
?location v:startTime ?startTime }""")
==>[name:spremberg,startTime:1982]
==>[name:kaiserslautern,startTime:2005]
==>[name:aachen,startTime:2009]g = traversal(SparqlTraversalSource).with(graph)
g.sparql("""SELECT ?name ?startTime
WHERE {
?person v:name "daniel" .
?person p:location ?location .
?location v:value ?name .
?location v:startTime ?startTime }""")STAR-shaped queries
STAR-shaped queries are the queries that form/follow a star-shaped execution plan. These in terms of graph traversals
can be perceived as path queries or neighborhood queries. For instance, getting all the information about a specific
person or software.
gremlin> g.sparql("""SELECT ?age ?software ?lang ?name
WHERE {
?person v:name "josh" .
?person v:age ?age .
?person e:created ?software .
?software v:lang ?lang .
?software v:name ?name . }""")g.sparql("""SELECT ?age ?software ?lang ?name
WHERE {
?person v:name "josh" .
?person v:age ?age .
?person e:created ?software .
?software v:lang ?lang .
?software v:name ?name . }""")With Gremlin
The sparql()-step takes a SPARQL query and returns a result. That result can be further processed by standard Gremlin
steps as shown below:
gremlin> g = traversal(SparqlTraversalSource).with(graph)
==>sparqltraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }")
==>[name:marko,age:29]
==>[name:vadas,age:27]
==>[name:josh,age:32]
==>[name:peter,age:35]
gremlin> g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }").select("name")
==>marko
==>vadas
==>josh
==>peter
gremlin> g.sparql("SELECT * WHERE { }").out("knows").values("name")
==>vadas
==>josh
gremlin> g.withSack(1.0f).sparql("SELECT * WHERE { }").
repeat(outE().sack(mult).by("weight").inV()).
times(2).
sack()
==>1.0
==>0.4g = traversal(SparqlTraversalSource).with(graph)
g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }")
g.sparql("SELECT ?name ?age WHERE { ?person v:name ?name . ?person v:age ?age }").select("name")
g.sparql("SELECT * WHERE { }").out("knows").values("name")
g.withSack(1.0f).sparql("SELECT * WHERE { }").
repeat(outE().sack(mult).by("weight").inV()).
times(2).
sack()Mixing SPARQL with Gremlin steps introduces some interesting possibilities for complex traversals.
Conclusion
The world that we know, you and me, is but a subset of the world
that Gremlin has weaved within The TinkerPop. Gremlin has constructed a fully connected graph and only the subset that
makes logical sense to our traversing thoughts is the fragment we have come to know and have come to see one another
within. But there are many more out there, within other webs of logics unfathomed. From any thought, every other
thought, we come to realize that which is — The TinkerPop.
Acknowledgements
![]() YourKit supports the TinkerPop open source project with its full-featured
Java Profiler. YourKit, LLC is the creator of innovative and intelligent tools for profiling Java and .NET
applications. YourKit’s leading software products: YourKit Java Profiler
and YourKit .NET Profiler
YourKit supports the TinkerPop open source project with its full-featured
Java Profiler. YourKit, LLC is the creator of innovative and intelligent tools for profiling Java and .NET
applications. YourKit’s leading software products: YourKit Java Profiler
and YourKit .NET Profiler
 Ketrina Yim — Designing
Gremlin and his friends for TinkerPop was one of my first major projects as a freelancer, and it’s delightful to
see them on the Web and all over the documentation! Drawing and tweaking the characters over time is like watching
them grow up. They’ve gone from sketches on paper to full-color logos, and from logos to living characters that
cheerfully greet visitors to the TinkerPop website. And it’s been a great time all throughout!
Ketrina Yim — Designing
Gremlin and his friends for TinkerPop was one of my first major projects as a freelancer, and it’s delightful to
see them on the Web and all over the documentation! Drawing and tweaking the characters over time is like watching
them grow up. They’ve gone from sketches on paper to full-color logos, and from logos to living characters that
cheerfully greet visitors to the TinkerPop website. And it’s been a great time all throughout!
…in the beginning.