3.4.13
Provider Documentation
Apache TinkerPop™ exposes a set of interfaces, protocols, and tests that make it possible for third-parties to build libraries and systems that plug-in to the TinkerPop stack. TinkerPop refers to those third-parties as "providers" and this documentation is designed to help providers understand what is involved in developing code on these lower levels of the TinkerPop API.
This document attempts to address the needs of the different providers that have been identified:
-
Graph System Provider
-
Graph Database Provider
-
Graph Processor Provider
-
-
Graph Driver Provider * Graph Language Provider
-
Graph Plugin Provider
Graph System Provider Requirements
 At the core of TinkerPop 3.x is a Java8 API. The implementation of this
core API and its validation via the
At the core of TinkerPop 3.x is a Java8 API. The implementation of this
core API and its validation via the gremlin-test suite is all that is required of a graph system provider wishing to
provide a TinkerPop-enabled graph engine. Once a graph system has a valid implementation, then all the applications
provided by TinkerPop (e.g. Gremlin Console, Gremlin Server, etc.) and 3rd-party developers (e.g. Gremlin-Scala,
Gremlin-JS, etc.) will integrate properly. Finally, please feel free to use the logo on the left to promote your
TinkerPop implementation.
Graph Structure API
The graph structure API of TinkerPop provides the interfaces necessary to create a TinkerPop enabled system and
exposes the basic components of a property graph to include Graph, Vertex, Edge, VertexProperty and Property.
The structure API can be used directly as follows:
Graph graph = TinkerGraph.open(); //1
Vertex marko = graph.addVertex(T.label, "person", T.id, 1, "name", "marko", "age", 29); //2
Vertex vadas = graph.addVertex(T.label, "person", T.id, 2, "name", "vadas", "age", 27);
Vertex lop = graph.addVertex(T.label, "software", T.id, 3, "name", "lop", "lang", "java");
Vertex josh = graph.addVertex(T.label, "person", T.id, 4, "name", "josh", "age", 32);
Vertex ripple = graph.addVertex(T.label, "software", T.id, 5, "name", "ripple", "lang", "java");
Vertex peter = graph.addVertex(T.label, "person", T.id, 6, "name", "peter", "age", 35);
marko.addEdge("knows", vadas, T.id, 7, "weight", 0.5f); //3
marko.addEdge("knows", josh, T.id, 8, "weight", 1.0f);
marko.addEdge("created", lop, T.id, 9, "weight", 0.4f);
josh.addEdge("created", ripple, T.id, 10, "weight", 1.0f);
josh.addEdge("created", lop, T.id, 11, "weight", 0.4f);
peter.addEdge("created", lop, T.id, 12, "weight", 0.2f);-
Create a new in-memory
TinkerGraphand assign it to the variablegraph. -
Create a vertex along with a set of key/value pairs with
T.labelbeing the vertex label andT.idbeing the vertex id. -
Create an edge along with a set of key/value pairs with the edge label being specified as the first argument.
In the above code all the vertices are created first and then their respective edges. There are two "accessor tokens":
T.id and T.label. When any of these, along with a set of other key value pairs is provided to
Graph.addVertex(Object…) or Vertex.addEdge(String,Vertex,Object…), the respective element is created along
with the provided key/value pair properties appended to it.
Below is a sequence of basic graph mutation operations represented in Java 8.
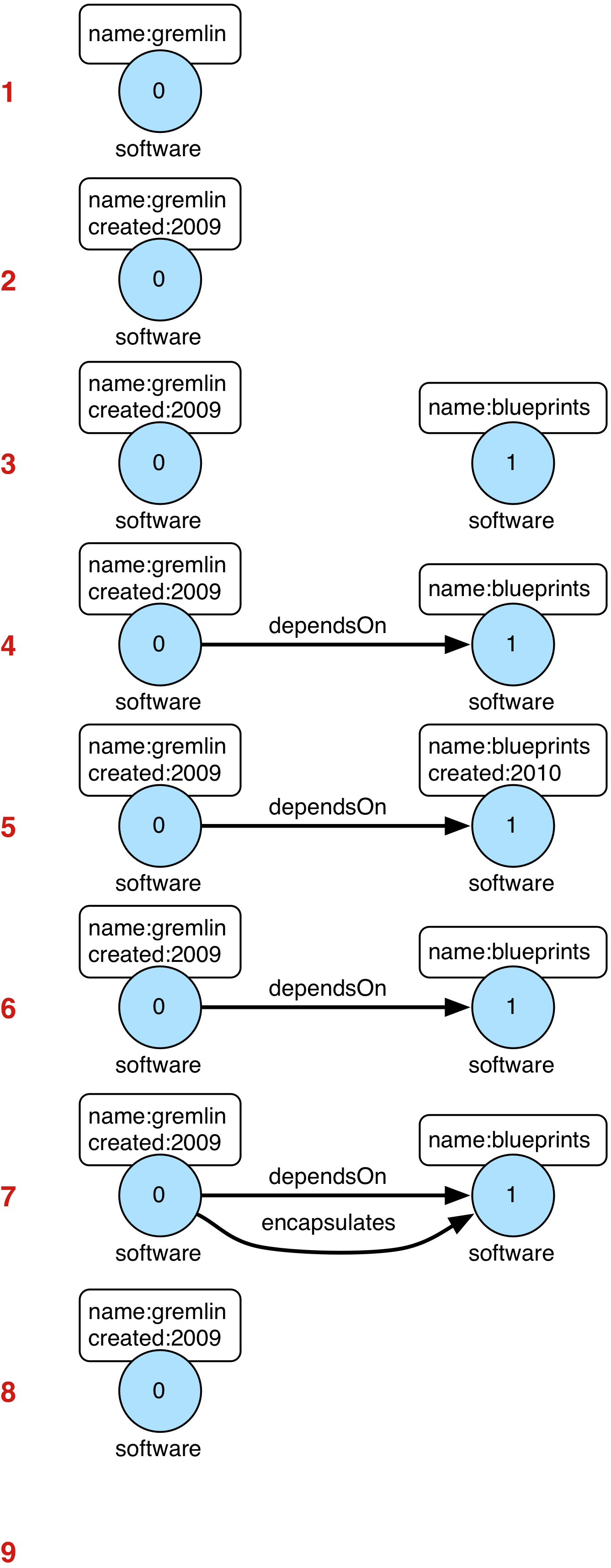
// create a new graph
Graph graph = TinkerGraph.open();
// add a software vertex with a name property
Vertex gremlin = graph.addVertex(T.label, "software",
"name", "gremlin"); //1
// only one vertex should exist
assert(IteratorUtils.count(graph.vertices()) == 1)
// no edges should exist as none have been created
assert(IteratorUtils.count(graph.edges()) == 0)
// add a new property
gremlin.property("created",2009) //2
// add a new software vertex to the graph
Vertex blueprints = graph.addVertex(T.label, "software",
"name", "blueprints"); //3
// connect gremlin to blueprints via a dependsOn-edge
gremlin.addEdge("dependsOn",blueprints); //4
// now there are two vertices and one edge
assert(IteratorUtils.count(graph.vertices()) == 2)
assert(IteratorUtils.count(graph.edges()) == 1)
// add a property to blueprints
blueprints.property("created",2010) //5
// remove that property
blueprints.property("created").remove() //6
// connect gremlin to blueprints via encapsulates
gremlin.addEdge("encapsulates",blueprints) //7
assert(IteratorUtils.count(graph.vertices()) == 2)
assert(IteratorUtils.count(graph.edges()) == 2)
// removing a vertex removes all its incident edges as well
blueprints.remove() //8
gremlin.remove() //9
// the graph is now empty
assert(IteratorUtils.count(graph.vertices()) == 0)
assert(IteratorUtils.count(graph.edges()) == 0)
// tada!The above code samples are just examples of how the structure API can be used to access a graph. Those APIs are then used internally by the process API (i.e. Gremlin) to access any graph that implements those structure API interfaces to execute queries. Typically, the structure API methods are not used directly by end-users.
Implementing Gremlin-Core
The classes that a graph system provider should focus on implementing are itemized below. It is a good idea to study
the TinkerGraph (in-memory OLTP and OLAP
in tinkergraph-gremlin), Neo4jGraph
(OLTP w/ transactions in neo4j-gremlin) and/or
HadoopGraph (OLAP in hadoop-gremlin)
implementations for ideas and patterns.
-
Online Transactional Processing Graph Systems (OLTP)
-
Structure API:
Graph,Element,Vertex,Edge,PropertyandTransaction(if transactions are supported). -
Process API:
TraversalStrategyinstances for optimizing Gremlin traversals to the provider’s graph system (i.e.TinkerGraphStepStrategy).
-
-
Online Analytics Processing Graph Systems (OLAP)
-
Everything required of OLTP is required of OLAP (but not vice versa).
-
GraphComputer API:
GraphComputer,Messenger,Memory.
-
Please consider the following implementation notes:
-
Use
StringHelperto ensuring that thetoString()representation of classes are consistent with other implementations. -
Ensure that your implementation’s
Features(Graph, Vertex, etc.) are correct so that test cases handle particulars accordingly. -
Use the numerous static method helper classes such as
ElementHelper,GraphComputerHelper,VertexProgramHelper, etc. -
There are a number of default methods on the provided interfaces that are semantically correct. However, if they are not efficient for the implementation, override them.
-
Implement the
structure/package interfaces first and then, if desired, interfaces in theprocess/package interfaces. -
ComputerGraphis aWrappersystem that ensure proper semantics during a GraphComputer computation. -
The javadoc is often a good resource in understanding expectations from both the user’s perspective as well as the graph provider’s perspective. Also consider examining the javadoc of TinkerGraph which is often well annotated and the interfaces and classes of the test suite itself.
OLTP Implementations
 The most important interfaces to implement are in the
The most important interfaces to implement are in the structure/
package. These include interfaces like Graph, Vertex, Edge, Property, Transaction, etc. The
StructureStandardSuite will ensure that the semantics of the methods implemented are correct. Moreover, there are
numerous Exceptions classes with static exceptions that should be thrown by the graph system so that all the
exceptions and their messages are consistent amongst all TinkerPop implementations.
The following bullets provide some tips to consider when implementing the structure interfaces:
-
Graph-
Be sure the
Graphimplementation is named asXXXGraph(e.g. TinkerGraph, Neo4jGraph, HadoopGraph, etc.). -
This implementation needs to be
GraphFactorycompatible which means that the implementation should have a staticGraph open(Configuration)method where theConfigurationis an Apache Commons class of that name. Alternatively, theGraphimplementation can have theGraphFactoryClassannotation which specifies a class with that staticGraph open(Configuration)method.
-
-
VertexProperty-
This interface is both a
Propertyand anElementasVertexPropertyis a first-class graph element in that it can have its own properties (i.e. meta-properties). Even if the implementation does not intend to support meta-properties, theVertexPropertyneeds to be implemented as anElement.
-
OLAP Implementations
 Implementing the OLAP interfaces may be a bit more complicated.
Note that before OLAP interfaces are implemented, it is necessary for the OLTP interfaces to be, at minimal,
implemented as specified in OLTP Implementations. A summary of each required interface
implementation is presented below:
Implementing the OLAP interfaces may be a bit more complicated.
Note that before OLAP interfaces are implemented, it is necessary for the OLTP interfaces to be, at minimal,
implemented as specified in OLTP Implementations. A summary of each required interface
implementation is presented below:
-
GraphComputer: A fluent builder for specifying an isolation level, a VertexProgram, and any number of MapReduce jobs to be submitted. -
Memory: A global blackboard for ANDing, ORing, INCRing, and SETing values for specified keys. -
Messenger: The system that collects and distributes messages being propagated by vertices executing the VertexProgram application. -
MapReduce.MapEmitter: The system that collects key/value pairs being emitted by the MapReduce applications map-phase. -
MapReduce.ReduceEmitter: The system that collects key/value pairs being emitted by the MapReduce applications combine- and reduce-phases.
|
Note
|
The VertexProgram and MapReduce interfaces in the process/computer/ package are not required by the graph
system. Instead, these are interfaces to be implemented by application developers writing VertexPrograms and MapReduce jobs.
|
|
Important
|
TinkerPop provides two OLAP implementations: TinkerGraphComputer (TinkerGraph), and SparkGraphComputer (Hadoop). Given the complexity of the OLAP system, it is good to study and copy many of the patterns used in these reference implementations. |
Implementing GraphComputer
 The most complex method in GraphComputer is the
The most complex method in GraphComputer is the submit()-method. The method must do the following:
-
Ensure the GraphComputer has not already been executed.
-
Ensure that at least there is a VertexProgram or 1 MapReduce job.
-
If there is a VertexProgram, validate that it can execute on the GraphComputer given the respectively defined features.
-
Create the Memory to be used for the computation.
-
Execute the VertexProgram.setup() method once and only once.
-
Execute the VertexProgram.execute() method for each vertex.
-
Execute the VertexProgram.terminate() method once and if true, repeat VertexProgram.execute().
-
When VertexProgram.terminate() returns true, move to MapReduce job execution.
-
MapReduce jobs are not required to be executed in any specified order.
-
For each Vertex, execute MapReduce.map(). Then (if defined) execute MapReduce.combine() and MapReduce.reduce().
-
Update Memory with runtime information.
-
Construct a new
ComputerResultcontaining the compute Graph and Memory.
Implementing Memory
 The Memory object is initially defined by
The Memory object is initially defined by VertexProgram.setup().
The memory data is available in the first round of the VertexProgram.execute() method. Each Vertex, when executing
the VertexProgram, can update the Memory in its round. However, the update is not seen by the other vertices until
the next round. At the end of the first round, all the updates are aggregated and the new memory data is available
on the second round. This process repeats until the VertexProgram terminates.
Implementing Messenger
The Messenger object is similar to the Memory object in that a vertex can read and write to the Messenger. However, the data it reads are the messages sent to the vertex in the previous step and the data it writes are the messages that will be readable by the receiving vertices in the subsequent round.
Implementing MapReduce Emitters
![]() The MapReduce framework in TinkerPop is similar to the model
popularized by Hadoop. The primary difference is that all Mappers process the vertices
of the graph, not an arbitrary key/value pair. However, the vertices' edges can not be accessed — only their
properties. This greatly reduces the amount of data needed to be pushed through the MapReduce engine as any edge
information required, can be computed in the VertexProgram.execute() method. Moreover, at this stage, vertices can
not be mutated, only their token and property data read. A Gremlin OLAP system needs to provide implementations for
to particular classes:
The MapReduce framework in TinkerPop is similar to the model
popularized by Hadoop. The primary difference is that all Mappers process the vertices
of the graph, not an arbitrary key/value pair. However, the vertices' edges can not be accessed — only their
properties. This greatly reduces the amount of data needed to be pushed through the MapReduce engine as any edge
information required, can be computed in the VertexProgram.execute() method. Moreover, at this stage, vertices can
not be mutated, only their token and property data read. A Gremlin OLAP system needs to provide implementations for
to particular classes: MapReduce.MapEmitter and MapReduce.ReduceEmitter. TinkerGraph’s implementation is provided
below which demonstrates the simplicity of the algorithm (especially when the data is all within the same JVM).
public class TinkerMapEmitter<K, V> implements MapReduce.MapEmitter<K, V> {
public Map<K, Queue<V>> reduceMap;
public Queue<KeyValue<K, V>> mapQueue;
private final boolean doReduce;
public TinkerMapEmitter(final boolean doReduce) { //1
this.doReduce = doReduce;
if (this.doReduce)
this.reduceMap = new ConcurrentHashMap<>();
else
this.mapQueue = new ConcurrentLinkedQueue<>();
}
@Override
public void emit(K key, V value) {
if (this.doReduce)
this.reduceMap.computeIfAbsent(key, k -> new ConcurrentLinkedQueue<>()).add(value); //2
else
this.mapQueue.add(new KeyValue<>(key, value)); //3
}
protected void complete(final MapReduce<K, V, ?, ?, ?> mapReduce) {
if (!this.doReduce && mapReduce.getMapKeySort().isPresent()) { //4
final Comparator<K> comparator = mapReduce.getMapKeySort().get();
final List<KeyValue<K, V>> list = new ArrayList<>(this.mapQueue);
Collections.sort(list, Comparator.comparing(KeyValue::getKey, comparator));
this.mapQueue.clear();
this.mapQueue.addAll(list);
} else if (mapReduce.getMapKeySort().isPresent()) {
final Comparator<K> comparator = mapReduce.getMapKeySort().get();
final List<Map.Entry<K, Queue<V>>> list = new ArrayList<>();
list.addAll(this.reduceMap.entrySet());
Collections.sort(list, Comparator.comparing(Map.Entry::getKey, comparator));
this.reduceMap = new LinkedHashMap<>();
list.forEach(entry -> this.reduceMap.put(entry.getKey(), entry.getValue()));
}
}
}-
If the MapReduce job has a reduce, then use one data structure (
reduceMap), else use another (mapList). The difference being that a reduction requires a grouping by key and therefore, theMap<K,Queue<V>>definition. If no reduction/grouping is required, then a simpleQueue<KeyValue<K,V>>can be leveraged. -
If reduce is to follow, then increment the Map with a new value for the key.
MapHelperis a TinkerPop class with static methods for adding data to a Map. -
If no reduce is to follow, then simply append a KeyValue to the queue.
-
When the map phase is complete, any map-result sorting required can be executed at this point.
public class TinkerReduceEmitter<OK, OV> implements MapReduce.ReduceEmitter<OK, OV> {
protected Queue<KeyValue<OK, OV>> reduceQueue = new ConcurrentLinkedQueue<>();
@Override
public void emit(final OK key, final OV value) {
this.reduceQueue.add(new KeyValue<>(key, value));
}
protected void complete(final MapReduce<?, ?, OK, OV, ?> mapReduce) {
if (mapReduce.getReduceKeySort().isPresent()) {
final Comparator<OK> comparator = mapReduce.getReduceKeySort().get();
final List<KeyValue<OK, OV>> list = new ArrayList<>(this.reduceQueue);
Collections.sort(list, Comparator.comparing(KeyValue::getKey, comparator));
this.reduceQueue.clear();
this.reduceQueue.addAll(list);
}
}
}The method MapReduce.reduce() is defined as:
public void reduce(final OK key, final Iterator<OV> values, final ReduceEmitter<OK, OV> emitter) { ... }In other words, for the TinkerGraph implementation, iterate through the entrySet of the reduceMap and call the
reduce() method on each entry. The reduce() method can emit key/value pairs which are simply aggregated into a
Queue<KeyValue<OK,OV>> in an analogous fashion to TinkerMapEmitter when no reduce is to follow. These two emitters
are tied together in TinkerGraphComputer.submit().
...
for (final MapReduce mapReduce : mapReducers) {
if (mapReduce.doStage(MapReduce.Stage.MAP)) {
final TinkerMapEmitter<?, ?> mapEmitter = new TinkerMapEmitter<>(mapReduce.doStage(MapReduce.Stage.REDUCE));
final SynchronizedIterator<Vertex> vertices = new SynchronizedIterator<>(this.graph.vertices());
workers.setMapReduce(mapReduce);
workers.mapReduceWorkerStart(MapReduce.Stage.MAP);
workers.executeMapReduce(workerMapReduce -> {
while (true) {
final Vertex vertex = vertices.next();
if (null == vertex) return;
workerMapReduce.map(ComputerGraph.mapReduce(vertex), mapEmitter);
}
});
workers.mapReduceWorkerEnd(MapReduce.Stage.MAP);
// sort results if a map output sort is defined
mapEmitter.complete(mapReduce);
// no need to run combiners as this is single machine
if (mapReduce.doStage(MapReduce.Stage.REDUCE)) {
final TinkerReduceEmitter<?, ?> reduceEmitter = new TinkerReduceEmitter<>();
final SynchronizedIterator<Map.Entry<?, Queue<?>>> keyValues = new SynchronizedIterator((Iterator) mapEmitter.reduceMap.entrySet().iterator());
workers.mapReduceWorkerStart(MapReduce.Stage.REDUCE);
workers.executeMapReduce(workerMapReduce -> {
while (true) {
final Map.Entry<?, Queue<?>> entry = keyValues.next();
if (null == entry) return;
workerMapReduce.reduce(entry.getKey(), entry.getValue().iterator(), reduceEmitter);
}
});
workers.mapReduceWorkerEnd(MapReduce.Stage.REDUCE);
reduceEmitter.complete(mapReduce); // sort results if a reduce output sort is defined
mapReduce.addResultToMemory(this.memory, reduceEmitter.reduceQueue.iterator()); //1
} else {
mapReduce.addResultToMemory(this.memory, mapEmitter.mapQueue.iterator()); //2
}
}
}
...-
Note that the final results of the reducer are provided to the Memory as specified by the application developer’s
MapReduce.addResultToMemory()implementation. -
If there is no reduce stage, the map-stage results are inserted into Memory as specified by the application developer’s
MapReduce.addResultToMemory()implementation.
Hadoop-Gremlin Usage
Hadoop-Gremlin is centered around InputFormats and OutputFormats. If a 3rd-party graph system provider wishes to
leverage Hadoop-Gremlin (and its respective GraphComputer engines), then they need to provide, at minimum, a
Hadoop2 InputFormat<NullWritable,VertexWritable> for their graph system. If the provider wishes to persist computed
results back to their graph system (and not just to HDFS via a FileOutputFormat), then a graph system specific
OutputFormat<NullWritable,VertexWritable> must be developed as well.
Conceptually, HadoopGraph is a wrapper around a Configuration object. There is no "data" in the HadoopGraph as
the InputFormat specifies where and how to get the graph data at OLAP (and OLTP) runtime. Thus, HadoopGraph is a
small object with little overhead. Graph system providers should realize HadoopGraph as the gateway to the OLAP
features offered by Hadoop-Gremlin. For example, a graph system specific Graph.compute(Class<? extends GraphComputer>
graphComputerClass)-method may look as follows:
public <C extends GraphComputer> C compute(final Class<C> graphComputerClass) throws IllegalArgumentException {
try {
if (AbstractHadoopGraphComputer.class.isAssignableFrom(graphComputerClass))
return graphComputerClass.getConstructor(HadoopGraph.class).newInstance(this);
else
throw Graph.Exceptions.graphDoesNotSupportProvidedGraphComputer(graphComputerClass);
} catch (final Exception e) {
throw new IllegalArgumentException(e.getMessage(),e);
}
}Note that the configurations for Hadoop are assumed to be in the Graph.configuration() object. If this is not the
case, then the Configuration provided to HadoopGraph.open() should be dynamically created within the
compute()-method. It is in the provided configuration that HadoopGraph gets the various properties which
determine how to read and write data to and from Hadoop. For instance, gremlin.hadoop.graphReader and
gremlin.hadoop.graphWriter.
GraphFilterAware Interface
Graph filters by OLAP processors to only pull a subgraph of the full graph from the graph data source. For instance, the
example below constructs a GraphFilter that will only pull the "knows"-graph amongst people into the GraphComputer
for processing.
graph.compute().vertices(hasLabel("person")).edges(bothE("knows"))If the provider has a custom InputRDD, they can implement GraphFilterAware and that graph filter will be provided to their
InputRDD at load time. For providers that use an InputFormat, state but the graph filter can be accessed from the configuration
as such:
if (configuration.containsKey(Constants.GREMLIN_HADOOP_GRAPH_FILTER))
this.graphFilter = VertexProgramHelper.deserialize(configuration, Constants.GREMLIN_HADOOP_GRAPH_FILTER);PersistResultGraphAware Interface
A graph system provider’s OutputFormat should implement the PersistResultGraphAware interface which
determines which persistence options are available to the user. For the standard file-based OutputFormats provided
by Hadoop-Gremlin (e.g. GryoOutputFormat, GraphSONOutputFormat,
and ScriptInputOutputFormat) ResultGraph.ORIGINAL is not supported as the original graph
data files are not random access and are, in essence, immutable. Thus, these file-based OutputFormats only support
ResultGraph.NEW which creates a copy of the data specified by the Persist enum.
IO Implementations
If a Graph requires custom serializers for IO to work properly, implement the Graph.io method. A typical example
of where a Graph would require such a custom serializers is if their identifier system uses non-primitive values,
such as OrientDB’s Rid class. From basic serialization of a single Vertex all the way up the stack to Gremlin
Server, the need to know how to handle these complex identifiers is an important requirement.
The first step to implementing custom serializers is to first implement the IoRegistry interface and register the
custom classes and serializers to it. Each Io implementation has different requirements for what it expects from the
IoRegistry:
-
GraphML - No custom serializers expected/allowed.
-
GraphSON - Register a Jackson
SimpleModule. TheSimpleModuleencapsulates specific classes to be serialized, so it does not need to be registered to a specific class in theIoRegistry(usenull). -
Gryo - Expects registration of one of three objects:
-
Register just the custom class with a
nullKryoSerializerimplementation - this class will use default "field-level" Kryo serialization. -
Register the custom class with a specific Kryo `Serializer' implementation.
-
Register the custom class with a
Function<Kryo, Serializer>for those cases where the KryoSerializerrequires theKryoinstance to get constructed.
-
This implementation should provide a zero-arg constructor as the stack may require instantiation via reflection.
Consider extending AbstractIoRegistry for convenience as follows:
public class MyGraphIoRegistry extends AbstractIoRegistry {
public MyGraphIoRegistry() {
register(GraphSONIo.class, null, new MyGraphSimpleModule());
register(GryoIo.class, MyGraphIdClass.class, new MyGraphIdSerializer());
}
}In the Graph.io method, provide the IoRegistry object to the supplied Builder and call the create method to
return that Io instance as follows:
public <I extends Io> I io(final Io.Builder<I> builder) {
return (I) builder.graph(this).registry(myGraphIoRegistry).create();
}}In this way, Graph implementations can pre-configure custom serializers for IO interactions and users will not need
to know about those details. Following this pattern will ensure proper execution of the test suite as well as
simplified usage for end-users.
|
Important
|
Proper implementation of IO is critical to successful Graph operations in Gremlin Server. The Test Suite
does have "serialization" tests that provide some assurance that an implementation is working properly, but those
tests cannot make assertions against any specifics of a custom serializer. It is the responsibility of the
implementer to test the specifics of their custom serializers.
|
|
Tip
|
Consider separating serializer code into its own module, if possible, so that clients that use the Graph
implementation remotely don’t need a full dependency on the entire Graph - just the IO components and related
classes being serialized.
|
There is an important implication to consider when the addition of a custom serializer. Presumably, the custom
serializer was written for the JVM to be deployed with a Graph instance. For example, a graph may expose a
geographical type like a Point or something similar. The library that contains Point assuming users expected to
deserialize back to a Point would need to have the library with Point and the “PointSerializer” class available
to them. In cases where that deployment approach is not desirable, it is possible to coerce a class like Point to
a type that is already in the list of types supported in TinkerPop. For example, Point could be coerced one-way to
Map of keys "x" and "y". Of course, on the client side, users would have to construct a Map for a Point which
isn’t quite as user-friendly.
If doing a type coercion is not desired, then it is important to remember that writing a Point class and related
serializer in Java is not sufficient for full support of Gremlin, as users of non-JVM Gremlin Language Variants (GLV)
will not be able to consume them. Getting full support would mean writing similar classes for each GLV. While
developing those classes is not hard, it also means more code to support.
Supporting Gremlin-Python IO
The serialization system of Gremlin-Python provides ways to add new types by creating serializers and deserializers in
Python and registering them with the RemoteConnection.
class MyType(object):
GRAPHSON_PREFIX = "providerx"
GRAPHSON_BASE_TYPE = "MyType"
GRAPHSON_TYPE = GraphSONUtil.formatType(GRAPHSON_PREFIX, GRAPHSON_BASE_TYPE)
def __init__(self, x, y):
self.x = x
self.y = y
@classmethod
def objectify(cls, value, reader):
return cls(value['x'], value['y'])
@classmethod
def dictify(cls, value, writer):
return GraphSONUtil.typedValue(cls.GRAPHSON_BASE_TYPE,
{'x': value.x, 'y': value.y},
cls.GRAPHSON_PREFIX)
graphson_reader = GraphSONReader({MyType.GRAPHSON_TYPE: MyType})
graphson_writer = GraphSONWriter({MyType: MyType})
connection = DriverRemoteConnection('ws://localhost:8182/gremlin', 'g',
graphson_reader=graphson_reader,
graphson_writer=graphson_writer)Supporting Gremlin.Net IO
The serialization system of Gremlin.Net provides ways to add new types by creating serializers and deserializers in
any .NET language and registering them with the GremlinClient.
internal class MyType
{
public static string GraphsonPrefix = "providerx";
public static string GraphsonBaseType = "MyType";
public static string GraphsonType = GraphSONUtil.FormatTypeName(GraphsonPrefix, GraphsonBaseType);
public MyType(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
}
internal class MyClassWriter : IGraphSONSerializer
{
public Dictionary<string, dynamic> Dictify(dynamic objectData, GraphSONWriter writer)
{
MyType myType = objectData;
var valueDict = new Dictionary<string, object>
{
{"x", myType.X},
{"y", myType.Y}
};
return GraphSONUtil.ToTypedValue(nameof(TestClass), valueDict, MyType.GraphsonPrefix);
}
}
internal class MyTypeReader : IGraphSONDeserializer
{
public dynamic Objectify(JToken graphsonObject, GraphSONReader reader)
{
var x = reader.ToObject(graphsonObject["x"]);
var y = reader.ToObject(graphsonObject["y"]);
return new MyType(x, y);
}
}
var graphsonReader = new GraphSON3Reader(
new Dictionary<string, IGraphSONDeserializer> {{MyType.GraphsonType, new MyTypeReader()}});
var graphsonWriter = new GraphSON3Writer(
new Dictionary<Type, IGraphSONSerializer> {{typeof(MyType), new MyClassWriter()}});
var gremlinClient = new GremlinClient(new GremlinServer("localhost", 8182), graphsonReader, graphsonWriter);RemoteConnection Implementations
A RemoteConnection is an interface that is important for usage on traversal sources configured using the
withRemote() option. A Traversal
that is generated from that source will apply a RemoteStrategy which will inject a RemoteStep to its end. That
step will then send the Bytecode of the Traversal over the RemoteConnection to get the results that it will
iterate.
There is one method to implement on RemoteConnection:
public <E> CompletableFuture<RemoteTraversal<?, E>> submitAsync(final Bytecode bytecode) throws RemoteConnectionException;Note that it returns a RemoteTraversal. This interface should also be implemented and in most cases implementers can
simply extend the AbstractRemoteTraversal.
TinkerPop provides the DriverRemoteConnection as a useful and
example implementation.
DriverRemoteConnection serializes the Traversal as Gremlin bytecode and then submits it for remote processing on
Gremlin Server. Gremlin Server rebinds the Traversal to a configured Graph instance and then iterates the results
back as it would normally do.
Implementing RemoteConnection is not something routinely done for those implementing gremlin-core. It is only
something required if there is a need to exploit remote traversal submission. If a graph provider has a "graph server"
similar to Gremlin Server that can accept bytecode-based requests on its own protocol, then that would be one example
of a reason to implement this interface.
Bulk Import Export
When it comes to doing "bulk" operations, the diverse nature of the available graph databases and their specific capabilities, prevents TinkerPop from doing a good job of generalizing that capability well. TinkerPop thus maintains two positions on the concept of import and export:
-
TinkerPop refers users to the bulk import/export facilities of specific graph providers as they tend to be more efficient and easier to use than the options TinkerPop has tried to generalize in the past.
-
TinkerPop encourages graph providers to expose those capabilities via
g.io()and theIoStepby way of aTraversalStrategy.
That said, for graph providers that don’t have a special bulk loading feature, they can either rely on the default
OLTP (single-threaded) GraphReader and GraphWriter options that are embedded in IoStep or get a basic bulk loader
from TinkerPop using the CloneVertexProgram.
Simply provide a InputFormat and OutputFormat that can be referenced by a HadoopGraph instance as discussed
in the Reference Documentation.
Validating with Gremlin-Test

<dependency>
<groupId>org.apache.tinkerpop</groupId>
<artifactId>gremlin-test</artifactId>
<version>3.4.13</version>
</dependency>The operational semantics of any OLTP or OLAP implementation are validated by gremlin-test. To implement these tests,
provide test case implementations as shown below, where XXX below denotes the name of the graph implementation (e.g.
TinkerGraph, Neo4jGraph, HadoopGraph, etc.).
// Structure API tests
@RunWith(StructureStandardSuite.class)
@GraphProviderClass(provider = XXXGraphProvider.class, graph = XXXGraph.class)
public class XXXStructureStandardTest {}
// Process API tests
@RunWith(ProcessComputerSuite.class)
@GraphProviderClass(provider = XXXGraphProvider.class, graph = XXXGraph.class)
public class XXXProcessComputerTest {}
@RunWith(ProcessStandardSuite.class)
@GraphProviderClass(provider = XXXGraphProvider.class, graph = XXXGraph.class)
public class XXXProcessStandardTest {}The above set of tests represent the minimum test suite set to implement. There are other "integration" and "performance" tests that should be considered optional. Implementing those tests requires the same pattern as shown above.
|
Important
|
It is as important to look at "ignored" tests as it is to look at ones that fail. The gremlin-test
suite utilizes the Feature implementation exposed by the Graph to determine which tests to execute. If a test
utilizes features that are not supported by the graph, it will ignore them. While that may be fine, implementers
should validate that the ignored tests are appropriately bypassed and that there are no mistakes in their feature
definitions. Moreover, implementers should consider filling gaps in their own test suites, especially when
IO-related tests are being ignored.
|
|
Tip
|
If it is expensive to construct a new Graph instance, consider implementing GraphProvider.getStaticFeatures()
which can help by caching a static feature set for instances produced by that GraphProvider and allow the test suite
to avoid that construction cost if the test is ignored.
|
The only test-class that requires any code investment is the GraphProvider implementation class. This class is a
used by the test suite to construct Graph configurations and instances and provides information about the
implementation itself. In most cases, it is best to simply extend AbstractGraphProvider as it provides many
default implementations of the GraphProvider interface.
Finally, specify the test suites that will be supported by the Graph implementation using the @Graph.OptIn
annotation. See the TinkerGraph implementation below as an example:
@Graph.OptIn(Graph.OptIn.SUITE_STRUCTURE_STANDARD)
@Graph.OptIn(Graph.OptIn.SUITE_PROCESS_STANDARD)
@Graph.OptIn(Graph.OptIn.SUITE_PROCESS_COMPUTER)
public class TinkerGraph implements Graph {Only include annotations for the suites the implementation will support. Note that implementing the suite, but not specifying the appropriate annotation will prevent the suite from running (an obvious error message will appear in this case when running the mis-configured suite).
There are times when there may be a specific test in the suite that the implementation cannot support (despite the
features it implements) or should not otherwise be executed. It is possible for implementers to "opt-out" of a test
by using the @Graph.OptOut annotation. This annotation can be applied to either a Graph instance or a
GraphProvider instance (the latter would typically be used for "opting out" for a particular Graph configuration
that was under test). The following is an example of this annotation usage as taken from HadoopGraph:
@Graph.OptIn(Graph.OptIn.SUITE_PROCESS_STANDARD)
@Graph.OptIn(Graph.OptIn.SUITE_PROCESS_COMPUTER)
@Graph.OptOut(
test = "org.apache.tinkerpop.gremlin.process.graph.step.map.MatchTest$Traversals",
method = "g_V_matchXa_hasXname_GarciaX__a_inXwrittenByX_b__a_inXsungByX_bX",
reason = "Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute.")
@Graph.OptOut(
test = "org.apache.tinkerpop.gremlin.process.graph.step.map.MatchTest$Traversals",
method = "g_V_matchXa_inXsungByX_b__a_inXsungByX_c__b_outXwrittenByX_d__c_outXwrittenByX_e__d_hasXname_George_HarisonX__e_hasXname_Bob_MarleyXX",
reason = "Hadoop-Gremlin is OLAP-oriented and for OLTP operations, linear-scan joins are required. This particular tests takes many minutes to execute.")
@Graph.OptOut(
test = "org.apache.tinkerpop.gremlin.process.computer.GraphComputerTest",
method = "shouldNotAllowBadMemoryKeys",
reason = "Hadoop does a hard kill on failure and stops threads which stops test cases. Exception handling semantics are correct though.")
@Graph.OptOut(
test = "org.apache.tinkerpop.gremlin.process.computer.GraphComputerTest",
method = "shouldRequireRegisteringMemoryKeys",
reason = "Hadoop does a hard kill on failure and stops threads which stops test cases. Exception handling semantics are correct though.")
public class HadoopGraph implements Graph {The above examples show how to ignore individual tests. It is also possible to:
-
Ignore an entire test case (i.e. all the methods within the test) by setting the
methodto "*". -
Ignore a "base" test class such that test that extend from those classes will all be ignored.
-
Ignore a
GraphComputertest based on the type ofGraphComputerbeing used. Specify the "computer" attribute on theOptOut(which is an array specification) which should have a value of theGraphComputerimplementation class that should ignore that test. This attribute should be left empty for "standard" execution and by default allGraphComputerimplementations will be included in theOptOutso if there are multiple implementations, explicitly specify the ones that should be excluded.
Also note that some of the tests in the Gremlin Test Suite are parameterized tests and require an additional level of specificity to be properly ignored. To ignore these types of tests, examine the name template of the parameterized tests. It is defined by a Java annotation that looks like this:
@Parameterized.Parameters(name = "expect({0})")The annotation above shows that the name of each parameterized test will be prefixed with "expect" and have
parentheses wrapped around the first parameter (at index 0) value supplied to each test. This information can
only be garnered by studying the test set up itself. Once the pattern is determined and the specific unique name of
the parameterized test is identified, add it to the specific property on the OptOut annotation in addition to
the other arguments.
These annotations help provide users a level of transparency into test suite compliance (via the
describeGraph() utility function). It also
allows implementers to have a lot of flexibility in terms of how they wish to support TinkerPop. For example, maybe
there is a single test case that prevents an implementer from claiming support of a Feature. The implementer could
choose to either not support the Feature or to support it but "opt-out" of the test with a "reason" as to why so
that users understand the limitation.
|
Important
|
Before using OptOut be sure that the reason for using it is sound and it is more of a last resort.
It is possible that a test from the suite doesn’t properly represent the expectations of a feature, is too broad or
narrow for the semantics it is trying to enforce or simply contains a bug. Please consider raising issues in the
developer mailing list with such concerns before assuming OptOut is the only answer.
|
|
Important
|
There are no tests that specifically validate complete compliance with Gremlin Server. Generally speaking,
a Graph that passes the full Test Suite, should be compliant with Gremlin Server. The one area where problems can
occur is in serialization. Always ensure that IO is properly implemented, that custom serializers are tested fully
and ultimately integration test the Graph with an actual Gremlin Server instance.
|
|
Warning
|
Configuring tests to run in parallel might result in errors that are difficult to debug as there is some
shared state in test execution around graph configuration. It is therefore recommended that parallelism be turned
off for the test suite (the Maven SureFire Plugin is configured this way by default). It may also be important to
include this setting, <reuseForks>false</reuseForks>, in the SureFire configuration if tests are failing in an
unexplainable way.
|
|
Warning
|
For graph implementations that require a schema, take note that TinkerPop tests were originally developed without too much concern for these types of graphs. While most tests utilize the standard toy graphs there are instances where tests will utilize their own independent schema that stands alone from all other tests. It may be necessary to create schemas specific to certain tests in those situations. |
|
Tip
|
When running the gremlin-test suite against your implementation, you may need to set build.dir as an
environment variable, depending on your project layout. Some tests require this to find a writable directory for
creating temporary files. The value is typically set to the project build directory. For example using the Maven
SureFire Plugin, this is done via the configuration argLine with -Dbuild.dir=${project.build.directory}.
|
Checking resource leak
The TinkerPop query engine retrieves data by interfacing with the provider using iterators. These iterators (depending on the provider) may hold up resources in the underlying storage layer and hence, it is critical to close them after the query is finished.
TinkerPop provides you with the ability to test for such resource leaks by checking for leaks when you run the
Gremlin-Test suites against your implementation. To enable this leak detection, providers should increment the
StoreIteratorCounter whenever a resource is opened and decrement it when it is closed. A reference implementation
is provided with TinkerGraph as TinkerGraphIterator.java.
Assertions for leak detection are enabled by default when running the test suite. They can be temporarily disabled by way of a system property - simply set `-DtestIteratorLeaks=false".
Accessibility via GremlinPlugin
 The applications distributed with TinkerPop do not distribute with
any graph system implementations besides TinkerGraph. If your implementation is stored in a Maven repository (e.g.
Maven Central Repository), then it is best to provide a
The applications distributed with TinkerPop do not distribute with
any graph system implementations besides TinkerGraph. If your implementation is stored in a Maven repository (e.g.
Maven Central Repository), then it is best to provide a GremlinPlugin implementation so the respective jars can be
downloaded according and when required by the user. Neo4j’s GremlinPlugin is provided below for reference.
package org.apache.tinkerpop.gremlin.neo4j.jsr223;
import org.apache.tinkerpop.gremlin.jsr223.AbstractGremlinPlugin;
import org.apache.tinkerpop.gremlin.jsr223.DefaultImportCustomizer;
import org.apache.tinkerpop.gremlin.jsr223.ImportCustomizer;
import org.apache.tinkerpop.gremlin.neo4j.process.traversal.LabelP;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jEdge;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jElement;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraph;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jGraphVariables;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jHelper;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jProperty;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jVertex;
import org.apache.tinkerpop.gremlin.neo4j.structure.Neo4jVertexProperty;
/**
* @author Stephen Mallette (http://stephen.genoprime.com)
*/
public final class Neo4jGremlinPlugin extends AbstractGremlinPlugin {
private static final String NAME = "tinkerpop.neo4j";
private static final ImportCustomizer imports;
static {
try {
imports = DefaultImportCustomizer.build()
.addClassImports(Neo4jEdge.class,
Neo4jElement.class,
Neo4jGraph.class,
Neo4jGraphVariables.class,
Neo4jHelper.class,
Neo4jProperty.class,
Neo4jVertex.class,
Neo4jVertexProperty.class,
LabelP.class)
.addMethodImports(LabelP.class.getMethod("of", String.class)).create();
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
private static final Neo4jGremlinPlugin instance = new Neo4jGremlinPlugin();
public Neo4jGremlinPlugin() {
super(NAME, imports);
}
public static Neo4jGremlinPlugin instance() {
return instance;
}
@Override
public boolean requireRestart() {
return true;
}
}With the above plugin implementations, users can now download respective binaries for Gremlin Console, Gremlin Server, etc.
gremlin> g = Neo4jGraph.open('/tmp/neo4j')
No such property: Neo4jGraph for class: groovysh_evaluate
Display stack trace? [yN]
gremlin> :install org.apache.tinkerpop neo4j-gremlin 3.4.13
==>loaded: [org.apache.tinkerpop, neo4j-gremlin, …]
gremlin> :plugin use tinkerpop.neo4j
==>tinkerpop.neo4j activated
gremlin> g = Neo4jGraph.open('/tmp/neo4j')
==>neo4jgraph[EmbeddedGraphDatabase [/tmp/neo4j]]In-Depth Implementations
 The graph system implementation details presented thus far are
minimum requirements necessary to yield a valid TinkerPop implementation. However, there are other areas that a
graph system provider can tweak to provide an implementation more optimized for their underlying graph engine. Typical
areas of focus include:
The graph system implementation details presented thus far are
minimum requirements necessary to yield a valid TinkerPop implementation. However, there are other areas that a
graph system provider can tweak to provide an implementation more optimized for their underlying graph engine. Typical
areas of focus include:
-
Traversal Strategies: A TraversalStrategy can be used to alter a traversal prior to its execution. A typical example is converting a pattern of
g.V().has('name','marko')into a global index lookup for all vertices with name "marko". In this way, aO(|V|)lookup becomes anO(log(|V|)). Please reviewTinkerGraphStepStrategyfor ideas. -
Step Implementations: Every step is ultimately referenced by the
GraphTraversalinterface. It is possible to extendGraphTraversalto use a graph system specific step implementation. Note that while it is sometimes possible to develop custom step implementations by extending from a TinkerPop step (typically,AddVertexStepand otherMutatingsteps), it’s important to consider that doing so introduces some greater risk for code breaks on upgrades as opposed to other areas of the code base. As steps are more internal features of TinkerPop, they might be subject to breaking API and behavioral changes that would be less likely to be accepted by more public facing interfaces.
Graph Driver Provider Requirements

One of the roles for Gremlin Server is to provide a bridge from TinkerPop to non-JVM languages (e.g. Go, Python, etc.). Developers can build language bindings (or driver) that provide a way to submit Gremlin scripts to Gremlin Server and get back results. Given the extensible nature of Gremlin Server, it is difficult to provide an authoritative guide to developing a driver. It is however possible to describe the core communication protocol using the standard out-of-the-box configuration which should provide enough information to develop a driver for a specific language.
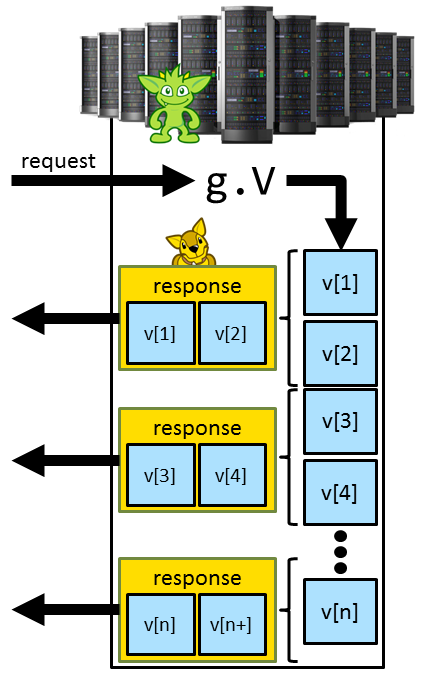
Gremlin Server is distributed with a configuration that utilizes WebSocket with a custom sub-protocol. Under this configuration, Gremlin Server accepts requests containing a Gremlin script, evaluates that script and then streams back the results. The notion of "streaming" is depicted in the diagram to the right.
The diagram shows an incoming request to process the Gremlin script of g.V(). Gremlin Server evaluates that script,
getting an Iterator of vertices as a result, and steps through each Vertex within it. The vertices are batched
together given the resultIterationBatchSize configuration. In this case, that value must be 2 given that each
"response" contains two vertices. Each response is serialized given the requested serializer type (JSON is likely
best for non-JVM languages) and written back to the requesting client immediately. Gremlin Server does not wait for
the entire result to be iterated, before sending back a response. It will send the responses as they are realized.
This approach allows for the processing of large result sets without having to serialize the entire result into memory for the response. It places a bit of a burden on the developer of the driver however, because it becomes necessary to provide a way to reconstruct the entire result on the client side from all of the individual responses that Gremlin Server returns for a single request. Again, this description of Gremlin Server’s "flow" is related to the out-of-the-box configuration. It is quite possible to construct other flows, that might be more amenable to a particular language or style of processing.
To formulate a request to Gremlin Server, a RequestMessage needs to be constructed. The RequestMessage is a
generalized representation of a request that carries a set of "standard" values in addition to optional ones that are
dependent on the operation being performed. A RequestMessage has these fields:
| Key | Description |
|---|---|
requestId |
A UUID representing the unique identification for the request. |
op |
The name of the "operation" to execute based on the available |
processor |
The name of the |
args |
A |
This message can be serialized in any fashion that is supported by Gremlin Server. New serialization methods can
be plugged in by implementing a ServiceLoader enabled MessageSerializer, however Gremlin Server provides for
JSON serialization by default which will be good enough for purposes of most developers building drivers.
A RequestMessage to evaluate a script with variable bindings looks like this in JSON:
{ "requestId":"1d6d02bd-8e56-421d-9438-3bd6d0079ff1",
"op":"eval",
"processor":"",
"args":{"gremlin":"g.V(x).out()",
"bindings":{"x":1},
"language":"gremlin-groovy"}}The above JSON represents the "body" of the request to send to Gremlin Server. When sending this "body" over WebSocket, Gremlin Server can accept a packet frame using a "text" (1) or a "binary" (2) opcode. Using "text" is a bit more limited in that Gremlin Server will always process the body of that request as JSON. Generally speaking "text" is just for testing purposes.
The preferred method for sending requests to Gremlin Server is to use the "binary" opcode. In this case, a "header"
will need be sent in addition to to the "body". The "header" basically consists of a "mime type" so that Gremlin
Server knows how to deserialize the RequestMessage. So, the actual byte array sent to Gremlin Server would be
formatted as follows:
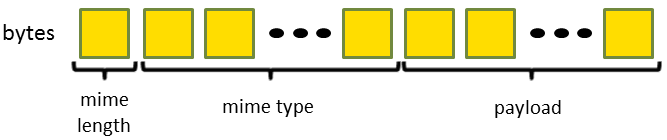
The first byte represents the length of the "mime type" string value that follows. Given the default configuration of
Gremlin Server, this value should be set to application/json. The "payload" represents the JSON message above
encoded as bytes.
|
Note
|
Gremlin Server will only accept masked packets as it pertains to a WebSocket packet header construction. |
When Gremlin Server receives that request, it will decode it given the "mime type", pass it to the requested
OpProcessor which will execute the op defined in the message. In this case, it will evaluate the script
g.V(x).out() using the bindings supplied in the args and stream back the results in a series of
ResponseMessages. A ResponseMessage looks like this:
| Key | Description |
|---|---|
requestId |
The identifier of the |
status |
The |
result |
The |
In this case the ResponseMessage returned to the client would look something like this:
{"result":{"data":[{"id": 2,"label": "person","type": "vertex","properties": [
{"id": 2, "value": "vadas", "label": "name"},
{"id": 3, "value": 27, "label": "age"}]},
], "meta":{}},
"requestId":"1d6d02bd-8e56-421d-9438-3bd6d0079ff1",
"status":{"code":206,"attributes":{},"message":""}}Gremlin Server is capable of streaming results such that additional responses will arrive over the WebSocket connection until
the iteration of the result on the server is complete. Each successful incremental message will have a ResultCode
of 206. Termination of the stream will be marked by a final 200 status code. Note that all messages without a
206 represent terminating conditions for a request. The following table details the various status codes that
Gremlin Server will send:
| Code | Name | Description |
|---|---|---|
200 |
SUCCESS |
The server successfully processed a request to completion - there are no messages remaining in this stream. |
204 |
NO CONTENT |
The server processed the request but there is no result to return (e.g. an |
206 |
PARTIAL CONTENT |
The server successfully returned some content, but there is more in the stream to arrive - wait for a |
401 |
UNAUTHORIZED |
The request attempted to access resources that the requesting user did not have access to. |
407 |
AUTHENTICATE |
A challenge from the server for the client to authenticate its request. |
497 |
CLIENT SERIALIZATION ERROR |
The request message contained an object that was not serializable. |
498 |
MALFORMED REQUEST |
The request message was not properly formatted which means it could not be parsed at all or the "op" code was not recognized such that Gremlin Server could properly route it for processing. Check the message format and retry the request. |
499 |
INVALID REQUEST ARGUMENTS |
The request message was parseable, but the arguments supplied in the message were in conflict or incomplete. Check the message format and retry the request. |
500 |
SERVER ERROR |
A general server error occurred that prevented the request from being processed. |
597 |
SCRIPT EVALUATION ERROR |
The script submitted for processing evaluated in the |
598 |
SERVER TIMEOUT |
The server exceeded one of the timeout settings for the request and could therefore only partially responded or did not respond at all. |
599 |
SERVER SERIALIZATION ERROR |
The server was not capable of serializing an object that was returned from the script supplied on the request. Either transform the object into something Gremlin Server can process within the script or install mapper serialization classes to Gremlin Server. |
|
Note
|
Please refer to the IO Reference Documentation for more
examples of RequestMessage and ResponseMessage instances.
|
OpProcessors Arguments
The following sections define a non-exhaustive list of available operations and arguments for embedded OpProcessors
(i.e. ones packaged with Gremlin Server).
Common
All OpProcessor instances support these arguments.
| Key | Type | Description |
|---|---|---|
batchSize |
Int |
When the result is an iterator this value defines the number of iterations each |
Standard OpProcessor
The "standard" OpProcessor handles requests for the primary function of Gremlin Server - executing Gremlin.
Requests made to this OpProcessor are "sessionless" in the sense that a request must encapsulate the entirety
of a transaction. There is no state maintained between requests. A transaction is started when the script is first
evaluated and is committed when the script completes (or rolled back if an error occurred).
| Key | Description | ||||||
|---|---|---|---|---|---|---|---|
processor |
As this is the default |
||||||
op |
|
authentication operation arguments
| Key | Type | Description |
|---|---|---|
sasl |
String |
Required The response to the server authentication challenge. This value is dependent on the SASL authentication mechanism required by the server and is Base64 encoded. |
saslMechanism |
String |
The SASL mechanism: |
eval operation arguments
| Key | Type | Description |
|---|---|---|
gremlin |
String |
Required The Gremlin script to evaluate. |
bindings |
Map |
A map of key/value pairs to apply as variables in the context of the Gremlin script. |
language |
String |
The flavor of Gremlin used (e.g. |
aliases |
Map |
A map of key/value pairs that allow globally bound |
evaluationTimeout |
Long |
An override for the server setting that determines the maximum time to wait for a script to execute on the server. |
Session OpProcessor
The "session" OpProcessor handles requests for the primary function of Gremlin Server - executing Gremlin. It is
like the "standard" OpProcessor, but instead maintains state between sessions and allows the option to leave all
transaction management up to the calling client. It is important that clients that open sessions, commit or roll
them back, however Gremlin Server will try to clean up such things when a session is killed that has been abandoned.
It is important to consider that a session can only be maintained with a single machine. In the event that multiple
Gremlin Server are deployed, session state is not shared among them.
| Key | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
processor |
This value should be set to |
||||||||
op |
|
|
Note
|
The "close" message is deprecated as of 3.3.11 as servers at this version are required to automatically interrupt
running processes on the close of the connection and release resources such as sessions. Servers wishing to be
compatible with older versions of the driver need only send back a NO_CONTENT for this message. Drivers wishing to
be compatible with servers prior to 3.3.11 may continue to send the message on calls to close() otherwise such code
can be removed.
|
authentication operation arguments
| Key | Type | Description |
|---|---|---|
saslMechanism |
String |
The SASL mechanism: |
sasl |
String |
Required The response to the server authentication challenge. This value is dependent on the SASL authentication mechanism required by the server and is Base64 encoded. |
eval operation arguments
| Key | Type | Description |
|---|---|---|
gremlin |
String |
Required The Gremlin script to evaluate. |
session |
String |
Required The session identifier for the current session - typically this value should be a UUID (the session will be created if it doesn’t exist). |
manageTransaction |
Boolean |
When set to |
bindings |
Map |
A map of key/value pairs to apply as variables in the context of the Gremlin script. |
evaluationTimeout |
Long |
An override for the server setting that determines the maximum time to wait for a script to execute on the server. |
language |
String |
The flavor of Gremlin used (e.g. |
aliases |
Map |
A map of key/value pairs that allow globally bound |
close operation arguments
| Key | Type | Description |
|---|---|---|
session |
String |
Required The session identifier for the session to close. |
force |
Boolean |
Determines if the session should be force closed when the client is closed. Force closing will not
attempt to close open transactions from existing running jobs and leave it to the underlying graph to decided how to
proceed with those orphaned transactions. Setting this to |
Traversal OpProcessor
Both the Standard and Session OpProcessors allow for Gremlin scripts to be submitted to the server. The
TraversalOpProcessor however allows Gremlin Bytecode to be submitted to the server. Supporting this OpProcessor
makes it possible for a Gremlin Language Variant
to submit a Traversal directly to Gremlin Server in the native language of the GLV without having to use a script in
a different language.
Unlike Standard and Session OpProcessors, the Traversal OpProcessor does not simply return the results of the
Traversal. It instead returns Traverser objects which allows the client to take advantage of
bulking. To describe this interaction more
directly, the returned Traverser will represent some value from the Traversal result and the number of times it
is represented in the full stream of results. So, if a Traversal happens to return the same vertex twenty times
it won’t return twenty instances of the same object. It will return one in Traverser with the bulk value set to
twenty. Under this model, the amount of processing and network overhead can be reduced considerably.
To demonstrate consider this example:
gremlin> cluster = Cluster.open()
==>localhost/127.0.0.1:8182
gremlin> client = cluster.connect()
==>org.apache.tinkerpop.gremlin.driver.Client$ClusteredClient@669580e2
gremlin> aliased = client.alias("g")
==>org.apache.tinkerpop.gremlin.driver.Client$AliasClusteredClient@2ace1cd3
gremlin> g = traversal().withEmbedded(org.apache.tinkerpop.gremlin.structure.util.empty.EmptyGraph.instance()) //// (1)
==>graphtraversalsource[emptygraph[empty], standard]
gremlin> rs = aliased.submit(g.V().both().barrier().both().barrier()).all().get() //// (2)
==>result{object=v[1] class=org.apache.tinkerpop.gremlin.process.remote.traversal.DefaultRemoteTraverser}
==>result{object=v[4] class=org.apache.tinkerpop.gremlin.process.remote.traversal.DefaultRemoteTraverser}
==>result{object=v[6] class=org.apache.tinkerpop.gremlin.process.remote.traversal.DefaultRemoteTraverser}
==>result{object=v[5] class=org.apache.tinkerpop.gremlin.process.remote.traversal.DefaultRemoteTraverser}
==>result{object=v[3] class=org.apache.tinkerpop.gremlin.process.remote.traversal.DefaultRemoteTraverser}
==>result{object=v[2] class=org.apache.tinkerpop.gremlin.process.remote.traversal.DefaultRemoteTraverser}
gremlin> aliased.submit(g.V().both().barrier().both().barrier().count()).all().get().get(0).getInt() //// (3)
==>30
gremlin> rs.collect{[value: it.getObject().get(), bulk: it.getObject().bulk()]} //// (4)
==>[value:v[1],bulk:7]
==>[value:v[4],bulk:7]
==>[value:v[6],bulk:3]
==>[value:v[5],bulk:3]
==>[value:v[3],bulk:7]
==>[value:v[2],bulk:3]cluster = Cluster.open()
client = cluster.connect()
aliased = client.alias("g")
g = traversal().withEmbedded(org.apache.tinkerpop.gremlin.structure.util.empty.EmptyGraph.instance()) //// (1)
rs = aliased.submit(g.V().both().barrier().both().barrier()).all().get() //// (2)
aliased.submit(g.V().both().barrier().both().barrier().count()).all().get().get(0).getInt() //// (3)
rs.collect{[value: it.getObject().get(), bulk: it.getObject().bulk()]} //4-
All commands through this step are just designed to demonstrate bulking with Gremlin Server and don’t represent a real-world way that this feature would be used.
-
Submit a
Traversalthat happens to ensure that the server uses bulking. Note that aTraverseris returned and that there are only six results. -
In actuality, however, if this same
Traversalis iterated there are thirty results. Without bulking, the previous request would have sent back thirty traversers. -
Note that the sum of the bulk of each
Traverseris thirty.
The full iteration of a Traversal is thus left to the client. It must interpret the bulk on the Traverser and
unroll it to represent the actual number of times it exists when iterated. The unrolling is typically handled
directly within TinkerPop’s remote traversal implementations.
One of the important aspects of the Traversal OpProcessor is that it enables the user to not only get the results of
the Traversal but also the side-effects that it produces. When the Traversal is submitted with the "bytecode"
operation, the results are iterated back as usual, but any side-effects are retained on the server in a cache keyed by
the identifier of the request that originally submitted the Traversal. The client will want to retain that identifier
if it intends to later get side-effects. The Traversal OpProcessor supplies the "keys" and "gather" operations to get
the keys stored in the side-effect and to get the value of a specific side-effect respectively. Finally, a "close"
operation is available to clear the cache of a specific side-effect.
| Key | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
processor |
This value should be set to |
||||||||||||
op |
|
authentication operation arguments
| Key | Type | Description |
|---|---|---|
sasl |
String |
Required The response to the server authentication challenge. This value is dependent on the SASL authentication mechanism required by the server and is Base64 encoded. |
bytecode operation arguments
| Key | Type | Description |
|---|---|---|
gremlin |
String |
Required The |
aliases |
Map |
Required A map with a single key/value pair that refers to a globally bound |
close operation arguments
| Key | Type | Description |
|---|---|---|
sideEffect |
UUID |
Required The unique identifier for the request that original submitted the traversal (side-effects are keyed by that value) |
gather operation arguments
| Key | Type | Description |
|---|---|---|
sideEffect |
UUID |
Required The unique identifier for the request that original submitted the traversal (side-effects are keyed by that value) |
sideEffectKey |
String |
Required The key for a specific side-effect. |
aliases |
Map |
Required A map with a single key/value pair that refers to a globally bound |
When using "gather" it is important to note the metadata that is returned on the ResponseMessage. It returns both the
"sideEffectKey" that was requested as well as a value keyed as "aggregateTo". The "aggregateTo" field describes how the
streamed side-effect data should be treated on the client. It provides a hint as to whether or not the data should be
rolled back up into a single object or simply left as-is. There are four values for "aggregateTo": bulkset, list,
map, set and none.
keys operation arguments
| Key | Type | Description |
|---|---|---|
sideEffect |
UUID |
Required The unique identifier for the request that original submitted the traversal (side-effects are keyed by that value) |
Authentication
Gremlin Server supports SASL-based
authentication. A SASL implementation provides a series of challenges and responses that a driver must comply with
in order to authenticate. By default, Gremlin Server only supports the "PLAIN" SASL mechanism, which is a cleartext
password system. When authentication is enabled, an incoming request is intercepted before it is evaluated by the
ScriptEngine. The request is saved on the server and a AUTHENTICATE challenge response (status code 407) is
returned to the client.
The client will detect the AUTHENTICATE and respond with an authentication for the op and an arg named sasl
that contains the password. The password should be either, an encoded sequence of UTF-8 bytes, delimited by 0
(US-ASCII NUL), where the form is : <NUL>username<NUL>password, or a Base64 encoded string of the former (which
in this instance would be AHVzZXJuYW1lAHBhc3N3b3Jk). Should Gremlin Server be able to authenticate with the
provided credentials, the server will return the results of the original request as it normally does without
authentication. If it cannot authenticate given the challenge response from the client, it will return UNAUTHORIZED
(status code 401).
|
Note
|
Gremlin Server does not support the "authorization identity" as described in RFC4616. |
Gremlin Plugins
Plugins provide a way to expand the features of a GremlinScriptEngine, which stands at that core of both Gremlin
Console and Gremlin Server. Providers may wish to create plugins for a variety of reasons, but some common examples
include:
-
Initialize the
GremlinScriptEngineapplication with important classes so that the user doesn’t need to type their own imports. -
Place specific objects in the bindings of the
GremlinScriptEnginefor the convenience of the user. -
Bootstrap the
GremlinScriptEnginewith custom functions so that they are ready for usage at startup.
The first step to developing a plugin is to implement the GremlinPlugin interface:
package org.apache.tinkerpop.gremlin.jsr223;
import java.util.Optional;
/**
* A plugin interface that is used by the {@link GremlinScriptEngineManager} to configure special {@link Customizer}
* instances that will alter the features of any {@link GremlinScriptEngine} created by the manager itself.
*
* @author Stephen Mallette (http://stephen.genoprime.com)
*/
public interface GremlinPlugin {
/**
* The name of the module. This name should be unique (use a namespaced approach) as naming clashes will
* prevent proper module operations. Modules developed by TinkerPop will be prefixed with "tinkerpop."
* For example, TinkerPop's implementation of Spark would be named "tinkerpop.spark". If Facebook were
* to do their own implementation the implementation might be called "facebook.spark".
*/
public String getName();
/**
* Some modules may require a restart of the plugin host for the classloader to pick up the features. This is
* typically true of modules that rely on {@code Class.forName()} to dynamically instantiate classes from the
* root classloader (e.g. JDBC drivers that instantiate via @{code DriverManager}).
*/
public default boolean requireRestart() {
return false;
}
/**
* Gets the list of all {@link Customizer} implementations to assign to a new {@link GremlinScriptEngine}. This is
* the same as doing {@code getCustomizers(null)}.
*/
public default Optional<Customizer[]> getCustomizers(){
return getCustomizers(null);
}
/**
* Gets the list of {@link Customizer} implementations to assign to a new {@link GremlinScriptEngine}. The
* implementation should filter the returned {@code Customizers} according to the supplied name of the
* Gremlin-enabled {@code ScriptEngine}. By providing a filter, {@code GremlinModule} developers can have the
* ability to target specific {@code ScriptEngines}.
*
* @param scriptEngineName The name of the {@code ScriptEngine} or null to get all the available {@code Customizers}
*/
public Optional<Customizer[]> getCustomizers(final String scriptEngineName);
}The most simple plugin and the one most commonly implemented will likely be one that just provides a list of classes for import. This type of plugin is the easiest way for implementers of the TinkerPop Structure and Process APIs to make their implementations available to users. The TinkerGraph implementation has just such a plugin:
package org.apache.tinkerpop.gremlin.tinkergraph.jsr223;
import org.apache.tinkerpop.gremlin.jsr223.AbstractGremlinPlugin;
import org.apache.tinkerpop.gremlin.jsr223.DefaultImportCustomizer;
import org.apache.tinkerpop.gremlin.jsr223.ImportCustomizer;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerGraphComputer;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerGraphComputerView;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerMapEmitter;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerMemory;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerMessenger;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerReduceEmitter;
import org.apache.tinkerpop.gremlin.tinkergraph.process.computer.TinkerWorkerPool;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerEdge;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerElement;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerFactory;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerGraph;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerGraphVariables;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerHelper;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerIoRegistryV1d0;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerIoRegistryV2d0;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerIoRegistryV3d0;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerProperty;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerVertex;
import org.apache.tinkerpop.gremlin.tinkergraph.structure.TinkerVertexProperty;
/**
* @author Stephen Mallette (http://stephen.genoprime.com)
*/
public final class TinkerGraphGremlinPlugin extends AbstractGremlinPlugin {
private static final String NAME = "tinkerpop.tinkergraph";
private static final ImportCustomizer imports = DefaultImportCustomizer.build()
.addClassImports(TinkerEdge.class,
TinkerElement.class,
TinkerFactory.class,
TinkerGraph.class,
TinkerGraphVariables.class,
TinkerHelper.class,
TinkerIoRegistryV1d0.class,
TinkerIoRegistryV2d0.class,
TinkerIoRegistryV3d0.class,
TinkerProperty.class,
TinkerVertex.class,
TinkerVertexProperty.class,
TinkerGraphComputer.class,
TinkerGraphComputerView.class,
TinkerMapEmitter.class,
TinkerMemory.class,
TinkerMessenger.class,
TinkerReduceEmitter.class,
TinkerWorkerPool.class).create();
private static final TinkerGraphGremlinPlugin instance = new TinkerGraphGremlinPlugin();
public TinkerGraphGremlinPlugin() {
super(NAME, imports);
}
public static TinkerGraphGremlinPlugin instance() {
return instance;
}
}This plugin extends from the abstract base class of AbstractGremlinPlugin
which provides some default implementations of the GremlinPlugin methods. It simply allows those who extend from it
to be able to just supply the name of the module and a list of Customizer
instances to apply to the GremlinScriptEngine. In this case, the TinkerGraph plugin just needs an
ImportCustomizer
which describes the list of classes to import when the plugin is activated and applied to the GremlinScriptEngine.
The ImportCustomizer is just one of several provided Customizer implementations that can be used in conjunction
with plugin development:
-
BindingsCustomizer - Inject a key/value pair into the global bindings of the
GremlinScriptEngineinstances -
ImportCustomizer - Add imports to a
GremlinScriptEngine -
ScriptCustomizer - Execute a script on a
GremlinScriptEngineat startup
Individual GremlinScriptEngine instances may have their own Customizer instances that can be used only with that
engine - e.g. gremlin-groovy has some that are specific to controlling the Groovy compiler configuration. Developing
a new Customizer implementation is not really possible without changes to TinkerPop, as the framework is not designed
to respond to external ones. The base Customizer implementations listed above should cover most needs.
A GremlinPlugin must support one of two instantiation models so that it can be instantiated from configuration files
for use in various situations - e.g. Gremlin Server. The first option is to use a static initializer given a method
with the following signature:
public static GremlinPlugin instance()The limitation with this approach is that it does not provide a way to supply any configuration to the plugin so it tends to only be useful for fairly simplistic plugins. The more advanced approach is to provide a "builder" given a method with the following signature:
public static Builder build()It doesn’t really matter what kind of class is returned from build so long as it follows a "Builder" pattern, where
methods on that object return an instance of itself, so that builder methods can be chained together prior to calling
a final create method as follows:
public GremlinPlugin create()Please see the ImportGremlinPlugin
for an example of what implementing a Builder might look like in this context.
Note that the plugin provides a unique name for the plugin which follows a namespaced pattern as namespace.plugin-name (e.g. "tinkerpop.hadoop" - "tinkerpop" is the reserved namespace for TinkerPop maintained plugins).
For plugins that will work with Gremlin Console, there is one other step to follow to ensure that the GremlinPlugin
will work there. The console loads GremlinPlugin instances via ServiceLoader
and therefore need a resource file added to the jar file where the plugin exists. Add a file called
org.apache.tinkerpop.gremlin.jsr223.GremlinPlugin to META-INF/services. In the case of the TinkerGraph
plugin above, that file will have this line in it:
org.apache.tinkerpop.gremlin.tinkergraph.jsr223.TinkerGraphGremlinPluginOnce the plugin is packaged, there are two ways to test it out:
-
Copy the jar and its dependencies to the Gremlin Console path and start it. It is preferrable that the plugin is copied to the
/ext/plugin_namedirectory. -
Start Gremlin Console and try the
:installcommand::install com.company my-plugin 1.0.0.
In either case, once one of these two approaches is taken, the jars and their dependencies are available to the
Console. The next step is to "activate" the plugin by doing :plugin use my-plugin, where "my-plugin" refers to the
name of the plugin to activate.
|
Note
|
When :install is used logging dependencies related to SLF4J are filtered out so as
not to introduce multiple logger bindings (which generates warning messages to the logs).
|
A plugin can do much more than just import classes. One can expand the Gremlin language with new functions or steps,
provide useful commands to make repetitive or complex tasks easier to execute, or do helpful integrations with other
systems. The secret to doing so lies in the PluginAcceptor. As mentioned earlier, the PluginAcceptor provides
access to the host of the plugin. It provides several important methods for doing so:
-
addBinding- These two function allow the plugin to inject whatever context it wants to the host. For example, doingaddBinding('x',1)would place a variable ofxwith a value of 1 into the console at the time of the plugin load. -
eval- Evaluates a script in the context of the host at the time of plugin startup. For example, doingeval("sum={x,y→x+y}")would create asumfunction that would be available to the user of the Console after the load of the plugin. -
environment- Provides context from the host environment. For the console, the environment will return aMapcontaining a reference to theIOstream and theGroovyshinstance. These classes represent very low-level access to the underpinnings of the console. Access toGroovyshallows for advanced features such as registering new commands (e.g. like the:pluginor:remotecommands).
Plugins can also tie into the :remote and :submit commands. Recall that a :remote represents a different
context within which Gremlin is executed, when issued with :submit. It is encouraged to use this integration point
when possible, as opposed to registering new commands that can otherwise follow the :remote and :submit pattern.
To expose this integration point as part of a plugin, implement the RemoteAcceptor interface:
|
Tip
|
Be good to the users of plugins and prevent dependency conflicts. Maintaining a conflict free plugin is most easily done by using the Maven Enforcer Plugin. |
|
Tip
|
Consider binding the plugin’s minor version to the TinkerPop minor version so that it’s easy for users to figure out plugin compatibility. Otherwise, clearly document a compatibility matrix for the plugin somewhere that users can find it. |
package org.apache.tinkerpop.gremlin.jsr223.console;
import java.io.Closeable;
import java.util.List;
import java.util.Map;
/**
* The Gremlin Console supports the {@code :remote} and {@code :submit} commands which provide standardized ways
* for plugins to provide "remote connections" to resources and a way to "submit" a command to those resources.
* A "remote connection" does not necessarily have to be a remote server. It simply refers to a resource that is
* external to the console.
* <p/>
* By implementing this interface and returning an instance of it through
* {@link ConsoleCustomizer#getRemoteAcceptor(GremlinShellEnvironment)} a plugin can hook into those commands and
* provide remoting features.
*
* @author Stephen Mallette (http://stephen.genoprime.com)
*/
public interface RemoteAcceptor extends Closeable {
public static final String RESULT = "result";
/**
* Gets called when {@code :remote} is used in conjunction with the "connect" option. It is up to the
* implementation to decide how additional arguments on the line should be treated after "connect".
*
* @return an object to display as output to the user
* @throws RemoteException if there is a problem with connecting
*/
public Object connect(final List<String> args) throws RemoteException;
/**
* Gets called when {@code :remote} is used in conjunction with the {@code config} option. It is up to the
* implementation to decide how additional arguments on the line should be treated after {@code config}.
*
* @return an object to display as output to the user
* @throws RemoteException if there is a problem with configuration
*/
public Object configure(final List<String> args) throws RemoteException;
/**
* Gets called when {@code :submit} is executed. It is up to the implementation to decide how additional
* arguments on the line should be treated after {@code :submit}.
*
* @return an object to display as output to the user
* @throws RemoteException if there is a problem with submission
*/
public Object submit(final List<String> args) throws RemoteException;
/**
* If the {@code RemoteAcceptor} is used in the Gremlin Console, then this method might be called to determine
* if it can be used in a fashion that supports the {@code :remote console} command. By default, this value is
* set to {@code false}.
* <p/>
* A {@code RemoteAcceptor} should only return {@code true} for this method if it expects that all activities it
* supports are executed through the {@code :submit} command. If the users interaction with the remote requires
* working with both local and remote evaluation at the same time, it is likely best to keep this method return
* {@code false}. A good example of this type of plugin would be the Gephi Plugin which uses {@code :remote config}
* to configure a local {@code TraversalSource} to be used and expects calls to {@code :submit} for the same body
* of analysis.
*/
public default boolean allowRemoteConsole() {
return false;
}
}The RemoteAcceptor can be bound to a GremlinPlugin by adding a ConsoleCustomizer implementation to the list of
Customizer instances that are returned from the GremlinPlugin. The ConsoleCustomizer will only be executed when
in use with the Gremlin Console plugin host. Simply instantiate and return a RemoteAcceptor in the
ConsoleCustomizer.getRemoteAcceptor(GremlinShellEnvironment) method. Generally speaking, each call to
getRemoteAcceptor(GremlinShellEnvironment) should produce a new instance of a RemoteAcceptor.