3.4.2
Recipes
 All programming languages tend to have
patterns of usage for commonly occurring problems. Gremlin
is not different in that respect. There are many commonly occurring traversal themes that have general applicability
to any graph. Gremlin Recipes present these common traversal patterns and methods of usage that will
provide some basic building blocks for virtually any graph in any domain.
All programming languages tend to have
patterns of usage for commonly occurring problems. Gremlin
is not different in that respect. There are many commonly occurring traversal themes that have general applicability
to any graph. Gremlin Recipes present these common traversal patterns and methods of usage that will
provide some basic building blocks for virtually any graph in any domain.
Recipes assume general familiarity with Gremlin and the Apache TinkerPop™ stack. Be sure to have read the Getting Started tutorial and the The Gremlin Console tutorial.
Traversal Recipes
Between Vertices
It is quite common to have a situation where there are two particular vertices of a graph and a need to execute some traversal on the paths found between them. Consider the following examples using the modern toy graph:
gremlin> g.V(1).bothE() //1\
==>e[9][1-created->3]
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).bothE().where(otherV().hasId(2)) //2\
==>e[7][1-knows->2]
gremlin> v1 = g.V(1).next();[]
gremlin> v2 = g.V(2).next();[]
gremlin> g.V(v1).bothE().where(otherV().is(v2)) //3\
==>e[7][1-knows->2]
gremlin> g.V(v1).outE().where(inV().is(v2)) //4\
==>e[7][1-knows->2]
gremlin> g.V(1).outE().where(inV().has(id, within(2,3))) //5\
==>e[9][1-created->3]
==>e[7][1-knows->2]
gremlin> g.V(1).out().where(__.in().hasId(6)) //6\
==>v[3]g.V(1).bothE() //1\
g.V(1).bothE().where(otherV().hasId(2)) //2\
v1 = g.V(1).next();[]
v2 = g.V(2).next();[]
g.V(v1).bothE().where(otherV().is(v2)) //3\
g.V(v1).outE().where(inV().is(v2)) //4\
g.V(1).outE().where(inV().has(id, within(2,3))) //5\
g.V(1).out().where(__.in().hasId(6)) //6-
There are three edges from the vertex with the identifier of "1".
-
Filter those three edges using the
where()-step using the identifier of the vertex returned byotherV()to ensure it matches on the vertex of concern, which is the one with an identifier of "2". -
Note that the same traversal will work if there are actual
Vertexinstances rather than just vertex identifiers. -
The vertex with identifier "1" has all outgoing edges, so it would also be acceptable to use the directional steps of
outE()andinV()since the schema allows it. -
There is also no problem with filtering the terminating side of the traversal on multiple vertices, in this case, vertices with identifiers "2" and "3".
-
There’s no reason why the same pattern of exclusion used for edges with
where()can’t work for a vertex between two vertices.
The basic pattern of using where()-step to find the "other" known vertex can be applied in far more complex
scenarios. For one such example, consider the following traversal that finds all the paths between a group of defined
vertices:
gremlin> ids = [2,4,6].toArray()
==>2
==>4
==>6
gremlin> g.V(ids).as("a").
repeat(bothE().otherV().simplePath()).times(5).emit(hasId(within(ids))).as("b").
filter(select(last,"a","b").by(id).where("a", lt("b"))).
path().by().by(label)
==>[v[2],knows,v[1],knows,v[4]]
==>[v[2],knows,v[1],created,v[3],created,v[4]]
==>[v[2],knows,v[1],created,v[3],created,v[6]]
==>[v[2],knows,v[1],knows,v[4],created,v[3],created,v[6]]
==>[v[4],created,v[3],created,v[6]]
==>[v[4],knows,v[1],created,v[3],created,v[6]]ids = [2,4,6].toArray()
g.V(ids).as("a").
repeat(bothE().otherV().simplePath()).times(5).emit(hasId(within(ids))).as("b").
filter(select(last,"a","b").by(id).where("a", lt("b"))).
path().by().by(label)For another example, consider the following schema:

Assume that the goal is to find information about a known job and a known person. Specifically, the idea would be to extract the known job, the company that created the job, the date it was created by the company and whether or not the known person completed an application.
gremlin> g.addV("person").property("name", "bob").as("bob").
addV("person").property("name", "stephen").as("stephen").
addV("company").property("name", "Blueprints, Inc").as("blueprints").
addV("company").property("name", "Rexster, LLC").as("rexster").
addV("job").property("name", "job1").as("blueprintsJob1").
addV("job").property("name", "job2").as("blueprintsJob2").
addV("job").property("name", "job3").as("blueprintsJob3").
addV("job").property("name", "job4").as("rexsterJob1").
addV("application").property("name", "application1").as("appBob1").
addV("application").property("name", "application2").as("appBob2").
addV("application").property("name", "application3").as("appStephen1").
addV("application").property("name", "application4").as("appStephen2").
addE("completes").from("bob").to("appBob1").
addE("completes").from("bob").to("appBob2").
addE("completes").from("stephen").to("appStephen1").
addE("completes").from("stephen").to("appStephen2").
addE("appliesTo").from("appBob1").to("blueprintsJob1").
addE("appliesTo").from("appBob2").to("blueprintsJob2").
addE("appliesTo").from("appStephen1").to("rexsterJob1").
addE("appliesTo").from("appStephen2").to("blueprintsJob3").
addE("created").from("blueprints").to("blueprintsJob1").property("creationDate", "12/20/2015").
addE("created").from("blueprints").to("blueprintsJob2").property("creationDate", "12/15/2015").
addE("created").from("blueprints").to("blueprintsJob3").property("creationDate", "12/16/2015").
addE("created").from("rexster").to("rexsterJob1").property("creationDate", "12/18/2015").iterate()
gremlin> vBlueprintsJob1 = g.V().has("job", "name", "job1").next()
==>v[8]
gremlin> vRexsterJob1 = g.V().has("job", "name", "job4").next()
==>v[14]
gremlin> vStephen = g.V().has("person", "name", "stephen").next()
==>v[2]
gremlin> vBob = g.V().has("person", "name", "bob").next()
==>v[0]
gremlin> g.V(vRexsterJob1).as('job').
inE('created').as('created').
outV().as('company').
select('job').
coalesce(__.in('appliesTo').where(__.in('completes').is(vStephen)),
constant(false)).as('application').
select('job', 'company', 'created', 'application').
by().by().by('creationDate').by()
==>[job:v[14],company:v[6],created:12/18/2015,application:v[20]]
gremlin> g.V(vRexsterJob1, vBlueprintsJob1).as('job').
inE('created').as('created').
outV().as('company').
select('job').
coalesce(__.in('appliesTo').where(__.in('completes').is(vBob)),
constant(false)).as('application').
select('job', 'company', 'created', 'application').
by().by().by('creationDate').by()
==>[job:v[14],company:v[6],created:12/18/2015,application:false]
==>[job:v[8],company:v[4],created:12/20/2015,application:v[16]]g.addV("person").property("name", "bob").as("bob").
addV("person").property("name", "stephen").as("stephen").
addV("company").property("name", "Blueprints, Inc").as("blueprints").
addV("company").property("name", "Rexster, LLC").as("rexster").
addV("job").property("name", "job1").as("blueprintsJob1").
addV("job").property("name", "job2").as("blueprintsJob2").
addV("job").property("name", "job3").as("blueprintsJob3").
addV("job").property("name", "job4").as("rexsterJob1").
addV("application").property("name", "application1").as("appBob1").
addV("application").property("name", "application2").as("appBob2").
addV("application").property("name", "application3").as("appStephen1").
addV("application").property("name", "application4").as("appStephen2").
addE("completes").from("bob").to("appBob1").
addE("completes").from("bob").to("appBob2").
addE("completes").from("stephen").to("appStephen1").
addE("completes").from("stephen").to("appStephen2").
addE("appliesTo").from("appBob1").to("blueprintsJob1").
addE("appliesTo").from("appBob2").to("blueprintsJob2").
addE("appliesTo").from("appStephen1").to("rexsterJob1").
addE("appliesTo").from("appStephen2").to("blueprintsJob3").
addE("created").from("blueprints").to("blueprintsJob1").property("creationDate", "12/20/2015").
addE("created").from("blueprints").to("blueprintsJob2").property("creationDate", "12/15/2015").
addE("created").from("blueprints").to("blueprintsJob3").property("creationDate", "12/16/2015").
addE("created").from("rexster").to("rexsterJob1").property("creationDate", "12/18/2015").iterate()
vBlueprintsJob1 = g.V().has("job", "name", "job1").next()
vRexsterJob1 = g.V().has("job", "name", "job4").next()
vStephen = g.V().has("person", "name", "stephen").next()
vBob = g.V().has("person", "name", "bob").next()
g.V(vRexsterJob1).as('job').
inE('created').as('created').
outV().as('company').
select('job').
coalesce(__.in('appliesTo').where(__.in('completes').is(vStephen)),
constant(false)).as('application').
select('job', 'company', 'created', 'application').
by().by().by('creationDate').by()
g.V(vRexsterJob1, vBlueprintsJob1).as('job').
inE('created').as('created').
outV().as('company').
select('job').
coalesce(__.in('appliesTo').where(__.in('completes').is(vBob)),
constant(false)).as('application').
select('job', 'company', 'created', 'application').
by().by().by('creationDate').by()While the traversals above are more complex, the pattern for finding "things" between two vertices is largely the same.
Note the use of the where()-step to terminate the traversers for a specific user. It is embedded in a coalesce()
step to handle situations where the specified user did not complete an application for the specified job and will
return false in those cases.
Centrality
There are many measures of centrality which are meant to help identify the most important vertices in a graph. As these measures are common in graph theory, this section attempts to demonstrate how some of these different indicators can be calculated using Gremlin.
Degree Centrality
Degree centrality is a measure of the number of edges associated to each vertex. The following examples use the modern toy graph:
gremlin> g.V().group().by().by(bothE().count()) //1\
==>[v[1]:3,v[2]:1,v[3]:3,v[4]:3,v[5]:1,v[6]:1]
gremlin> g.V().group().by().by(inE().count()) //2\
==>[v[1]:0,v[2]:1,v[3]:3,v[4]:1,v[5]:1,v[6]:0]
gremlin> g.V().group().by().by(outE().count()) //3\
==>[v[1]:3,v[2]:0,v[3]:0,v[4]:2,v[5]:0,v[6]:1]
gremlin> g.V().project("v","degree").by().by(bothE().count()) //4\
==>[v:v[1],degree:3]
==>[v:v[2],degree:1]
==>[v:v[3],degree:3]
==>[v:v[4],degree:3]
==>[v:v[5],degree:1]
==>[v:v[6],degree:1]
gremlin> g.V().project("v","degree").by().by(bothE().count()). //5\
order().by(select("degree"), desc).
limit(4)
==>[v:v[1],degree:3]
==>[v:v[3],degree:3]
==>[v:v[4],degree:3]
==>[v:v[2],degree:1]g.V().group().by().by(bothE().count()) //1\
g.V().group().by().by(inE().count()) //2\
g.V().group().by().by(outE().count()) //3\
g.V().project("v","degree").by().by(bothE().count()) //4\
g.V().project("v","degree").by().by(bothE().count()). //5\
order().by(select("degree"), desc).
limit(4)-
Calculation of degree centrality which counts all incident edges on each vertex to include those that are both incoming and outgoing.
-
Calculation of in-degree centrality which only counts incoming edges to a vertex.
-
Calculation of out-degree centrality which only counts outgoing edges from a vertex.
-
The previous examples all produce a single
Mapas their output. While that is a desirable output, producing a stream ofMapobjects can allow some greater flexibility. -
For example, use of a stream enables use of an ordered limit that can be executed in a distributed fashion in OLAP traversals.
|
Note
|
The group step takes up to two separate
by modulators. The first by() tells group()
what the key in the resulting Map will be (i.e. the value to group on). In the above examples, the by() is empty
and as a result, the grouping will be on the incoming Vertex object itself. The second by() is the value to be
stored in the Map for each key.
|
Betweeness Centrality
Betweeness centrality is a measure of the number of times a vertex is found between the shortest path of each vertex pair in a graph. Consider the following graph for demonstration purposes:
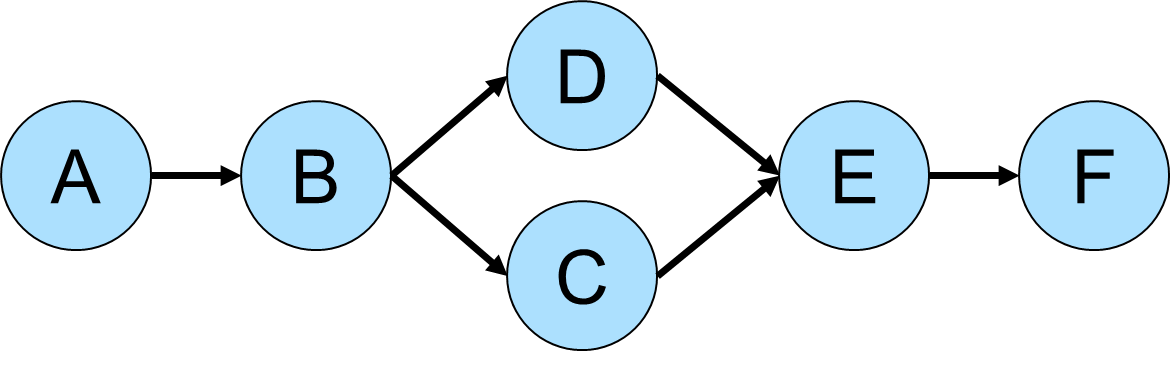
gremlin> g.addV().property(id,'A').as('a').
addV().property(id,'B').as('b').
addV().property(id,'C').as('c').
addV().property(id,'D').as('d').
addV().property(id,'E').as('e').
addV().property(id,'F').as('f').
addE('next').from('a').to('b').
addE('next').from('b').to('c').
addE('next').from('b').to('d').
addE('next').from('c').to('e').
addE('next').from('d').to('e').
addE('next').from('e').to('f').iterate()
gremlin> g.V().as("v"). //1\
repeat(both().simplePath().as("v")).emit(). //2\
filter(project("x","y","z").by(select(first, "v")). //3\
by(select(last, "v")).
by(select(all, "v").count(local)).as("triple").
coalesce(select("x","y").as("a"). //4\
select("triples").unfold().as("t").
select("x","y").where(eq("a")).
select("t"),
store("triples")). //5\
select("z").as("length").
select("triple").select("z").where(eq("length"))). //6\
select(all, "v").unfold(). //7\
groupCount().next() //8\
==>v[A]=14
==>v[B]=28
==>v[C]=20
==>v[D]=20
==>v[E]=28
==>v[F]=14g.addV().property(id,'A').as('a').
addV().property(id,'B').as('b').
addV().property(id,'C').as('c').
addV().property(id,'D').as('d').
addV().property(id,'E').as('e').
addV().property(id,'F').as('f').
addE('next').from('a').to('b').
addE('next').from('b').to('c').
addE('next').from('b').to('d').
addE('next').from('c').to('e').
addE('next').from('d').to('e').
addE('next').from('e').to('f').iterate()
g.V().as("v"). //1\
repeat(both().simplePath().as("v")).emit(). //2\
filter(project("x","y","z").by(select(first, "v")). //3\
by(select(last, "v")).
by(select(all, "v").count(local)).as("triple").
coalesce(select("x","y").as("a"). //4\
select("triples").unfold().as("t").
select("x","y").where(eq("a")).
select("t"),
store("triples")). //5\
select("z").as("length").
select("triple").select("z").where(eq("length"))). //6\
select(all, "v").unfold(). //7\
groupCount().next() //8-
Starting from each vertex in the graph…
-
…traverse on both - incoming and outgoing - edges, avoiding cyclic paths.
-
Create a triple consisting of the first vertex, the last vertex and the length of the path between them.
-
Determine whether a path between those two vertices was already found.
-
If this is the first path between the two vertices, store the triple in an internal collection named "triples".
-
Keep only those paths between a pair of vertices that have the same length as the first path that was found between them.
-
Select all shortest paths and unfold them.
-
Count the number of occurrences of each vertex, which is ultimately its betweeness score.
|
Warning
|
Since the betweeness centrality algorithm requires the shortest path between any pair of vertices in the graph, its practical applications are very limited. It’s recommended to use this algorithm only on small subgraphs (graphs like the Grateful Dead graph with only 808 vertices and 8049 edges already require a massive amount of compute resources to determine the shortest paths between all vertex pairs). |
Closeness Centrality
Closeness centrality is a measure of the distance of one vertex to all other reachable vertices in the graph. The following examples use the modern toy graph:
gremlin> g = TinkerFactory.createModern().traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
gremlin> g.withSack(1f).V().as("v"). //1\
repeat(both().simplePath().as("v")).emit(). //2\
filter(project("x","y","z").by(select(first, "v")). //3\
by(select(last, "v")).
by(select(all, "v").count(local)).as("triple").
coalesce(select("x","y").as("a"). //4\
select("triples").unfold().as("t").
select("x","y").where(eq("a")).
select("t"),
store("triples")). //5\
select("z").as("length").
select("triple").select("z").where(eq("length"))). //6\
group().by(select(first, "v")). //7\
by(select(all, "v").count(local).sack(div).sack().sum()).next()
==>v[1]=2.1666666666666665
==>v[2]=1.6666666666666665
==>v[3]=2.1666666666666665
==>v[4]=2.1666666666666665
==>v[5]=1.6666666666666665
==>v[6]=1.6666666666666665g = TinkerFactory.createModern().traversal()
g.withSack(1f).V().as("v"). //1\
repeat(both().simplePath().as("v")).emit(). //2\
filter(project("x","y","z").by(select(first, "v")). //3\
by(select(last, "v")).
by(select(all, "v").count(local)).as("triple").
coalesce(select("x","y").as("a"). //4\
select("triples").unfold().as("t").
select("x","y").where(eq("a")).
select("t"),
store("triples")). //5\
select("z").as("length").
select("triple").select("z").where(eq("length"))). //6\
group().by(select(first, "v")). //7\
by(select(all, "v").count(local).sack(div).sack().sum()).next()-
Defines a Gremlin sack with a value of one.
-
Traverses on both - incoming and outgoing - edges, avoiding cyclic paths.
-
Create a triple consisting of the first vertex, the last vertex and the length of the path between them.
-
Determine whether a path between those two vertices was already found.
-
If this is the first path between the two vertices, store the triple in an internal collection named "triples".
-
Keep only those paths between a pair of vertices that have the same length as the first path that was found between them.
-
For each vertex divide 1 by the product of the lengths of all shortest paths that start with this particular vertex.
|
Warning
|
Since the closeness centrality algorithm requires the shortest path between any pair of vertices in the graph, its practical applications are very limited. It’s recommended to use this algorithm only on small subgraphs (graphs like the Grateful Dead graph with only 808 vertices and 8049 edges already require a massive amount of compute resources to determine the shortest paths between all vertex pairs). |
Eigenvector Centrality
A calculation of eigenvector centrality uses the relative importance of adjacent vertices to help determine their centrality. In other words, unlike degree centrality the vertex with the greatest number of incident edges does not necessarily give it the highest rank. Consider the following example using the Grateful Dead graph:
gremlin> g.io('data/grateful-dead.xml').read().iterate()
gremlin> g.V().repeat(groupCount('m').by('name').out()).times(5).cap('m'). //1\
order(local).by(values, desc).limit(local, 10).next() //2\
==>PLAYING IN THE BAND=8758598
==>ME AND MY UNCLE=8214246
==>JACK STRAW=8173882
==>EL PASO=7666994
==>TRUCKING=7643494
==>PROMISED LAND=7339027
==>CHINA CAT SUNFLOWER=7322213
==>CUMBERLAND BLUES=6730838
==>RAMBLE ON ROSE=6676667
==>LOOKS LIKE RAIN=6674121
gremlin> g.V().repeat(groupCount('m').by('name').out().timeLimit(100)).times(5).cap('m'). //3\
order(local).by(values, desc).limit(local, 10).next()
==>PLAYING IN THE BAND=8758598
==>ME AND MY UNCLE=8214246
==>JACK STRAW=8173882
==>EL PASO=7666994
==>TRUCKING=7643494
==>PROMISED LAND=7339027
==>CHINA CAT SUNFLOWER=7322213
==>CUMBERLAND BLUES=6730838
==>RAMBLE ON ROSE=6676667
==>LOOKS LIKE RAIN=6674121g.io('data/grateful-dead.xml').read().iterate()
g.V().repeat(groupCount('m').by('name').out()).times(5).cap('m'). //1\
order(local).by(values, desc).limit(local, 10).next() //2\
g.V().repeat(groupCount('m').by('name').out().timeLimit(100)).times(5).cap('m'). //3\
order(local).by(values, desc).limit(local, 10).next()-
The traversal iterates through each vertex in the graph and for each one repeatedly group counts each vertex that passes through using the vertex as the key. The
Mapof this group count is stored in a variable named "m". Theout()traversal is repeated thirty times or until the paths are exhausted. Five iterations should provide enough time to converge on a solution. Callingcap('m')at the end simply extracts theMapside-effect stored in "m". -
The entries in the
Mapare then iterated and sorted with the top ten most central vertices presented as output. -
The previous examples can be expanded on a little bit by including a time limit. The
timeLimit()prevents the traversal from taking longer than one hundred milliseconds to execute (the previous example takes considerably longer than that). While the answer provided with thetimeLimit()is not the absolute ranking, it does provide a relative ranking that closely matches the absolute one. The use oftimeLimit()in certain algorithms (e.g. recommendations) can shorten the time required to get a reasonable and usable result.
PageRank Centrality
While not technically a recipe, it’s worth noting here in the "Centrality Section" that
PageRank centrality can be calculated with Gremlin with the
pageRank()-step which is designed to work with
GraphComputer (OLAP) based traversals.
gremlin> g = graph.traversal().withComputer()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], graphcomputer]
gremlin> g.V().pageRank().by('pageRank').values('pageRank')
==>0.30472009079122503
==>0.1459854015271911
==>0.1459854015271911
==>0.11375510357865544
==>0.11375510357865544
==>0.1757988989970824g = graph.traversal().withComputer()
g.V().pageRank().by('pageRank').values('pageRank')Collections

Lists and maps form the basis for much of the processing in Gremlin traversals. They are core to how side-effects
are typically held and how results are generally produced. Being able to pick them apart and reformat them is sometimes
required. This need to shape the data within a traversal may arise both at the
terminal step of the traversal (technically
just prior to the terminal step) or in the middle of a traversal. Considering the former, a transformation just prior
to iteration will get the result into the form required by the application which would remove the need for additional
application level manipulation. Moreover, a transformation at this stage may reduce the size of the payload being
returned which could be useful in remote applications. Examining the latter, there may be times where a List or Map
requires some mid-traversal transformation so as to continue with the general logic of the traversal itself. For
example, a traversal at some point might produce a Map of List objects where the lists contain vertices, where each
List might need to be sorted by some criteria and then the top item for each extracted to become the basis for the
continued traversal. Executing transformations for either of these types of situations can be made possible with the
patterns described in this section.
The appearance of a List as a traverser in Gremlin usually arises as a result of a fold() operation, but may also
appear by way of some side-effect steps like store():
gremlin> g.V().fold()
==>[v[1],v[2],v[3],v[4],v[5],v[6]]
gremlin> g.V().store('a').cap('a')
==>[v[1],v[2],v[3],v[4],v[5],v[6]]g.V().fold()
g.V().store('a').cap('a')It is worth noting that while a Path is not technically a List it does present like one and can be manipulated in
similar fashion to lists:
gremlin> g.V().out().out().path()
==>[v[1],v[4],v[5]]
==>[v[1],v[4],v[3]]g.V().out().out().path()These examples are obviously trivial and there are other ways that a traverser might end up in a List form, but, at
this moment, the point here is to focus less on how to get a List and more on how to manipulate one within the
Gremlin language. The examples going forward will also be similarly contrived insofar as producing a usable List to
manipulate. Bear in mind that it may be quite possible to get the same end results of these examples using more direct
means than what is demonstrated.
It may seem simple, but the most obvious choice to modifying what is in a list is to simply unfold() the List:
gremlin> g.V().fold().unfold().values('name')
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peter
gremlin> g.V().store('a').cap('a').unfold().values('name')
==>marko
==>vadas
==>lop
==>josh
==>ripple
==>peterg.V().fold().unfold().values('name')
g.V().store('a').cap('a').unfold().values('name')The above examples show that unfold() works quite well when you don’t want to preserve the List structure of the
traverser as it just flattens List traversers to the traversal stream. The above examples only have one List as a
result, but consider what happens when there is more than one:
gremlin> g.V().union(fold(),fold())
==>[v[1],v[2],v[3],v[4],v[5],v[6]]
==>[v[1],v[2],v[3],v[4],v[5],v[6]]
gremlin> g.V().union(fold(),fold()).unfold().values('name')
==>marko
==>marko
==>vadas
==>vadas
==>lop
==>lop
==>josh
==>josh
==>ripple
==>ripple
==>peter
==>peterg.V().union(fold(),fold())
g.V().union(fold(),fold()).unfold().values('name')The two separate List traversers are flattened to a single traversal stream and all the results are mixed together.
While this approach may be acceptable, there are many cases where it might not be so. To preserve the individual
structure of the List traversers "locally" unfold() the lists to transform them:
gremlin> g.V().
union(fold(),fold()).
local(unfold().values('name').fold())
==>[marko,vadas,lop,josh,ripple,peter]
==>[marko,vadas,lop,josh,ripple,peter]g.V().
union(fold(),fold()).
local(unfold().values('name').fold())The call to local() executes its anonymous sub-traversal over each individual List iterator and as the
sub-traversal ends with a fold()-step, the results are reduced back into a List to preserve the original structure,
thus maintaining two traverser results.
This pattern for unfolding and folding List traversers ends up having other applications:
gremlin> g.V().union(limit(3).fold(),tail(3).fold()) //1\
==>[v[1],v[2],v[3]]
==>[v[4],v[5],v[6]]
gremlin> g.V().union(limit(3).fold(),tail(3).fold()).
local(unfold(). //2\
order().
by(bothE().count(),desc).
limit(1).
fold())
==>[v[1]]
==>[v[4]]
gremlin> g.V().union(limit(3).fold(),tail(3).fold()). //3\
local(unfold().
has('age',gte(29)).
values('age').
mean())
==>29.0
==>33.5g.V().union(limit(3).fold(),tail(3).fold()) //1\
g.V().union(limit(3).fold(),tail(3).fold()).
local(unfold(). //2\
order().
by(bothE().count(),desc).
limit(1).
fold())
g.V().union(limit(3).fold(),tail(3).fold()). //3\
local(unfold().
has('age',gte(29)).
values('age').
mean())-
The output consists of two
Listtraversers. -
For each
Listof vertices, order them by their number of edges, and choose the first one which will be the one with the highest degree (i.e. number of edges). By ending withfold()theListtraverser structure is preserved thus returning twoListobjects. Consider this a method for choosing a "max" or a highly ranked vertex. In this case the rank was determined by the number of edges, but it could have just as easily been determined by a vertex property, edge property, a calculated value, etc. - one simply needs to alter theby()-step modulator toorder(). -
For each
Listof vertices, filter thatListto only include vertices that have an "age" property with a value greater than or equal to "29" and then average the results of each list. More generally, consider how this approach performs some kind of reducing calculation on eachListtraverser. In this case, an average was calculated, but it might also have been asum(),count()or similar operation that reduced the list to a single calculated value.
So far, this section has focused on what to do with a List traverser once there is one present and there have been
fairly contrived examples for how to produce one in the first place. The use of fold() has been used most frequently
at this point to achieve list creation and that step should be recalled whenever there is a need to reduce some
traversal stream to an actual List. Of course, it may become necessary to more manually construct a List,
especially in cases where the expected output of the traversal is composed of one or more ordered results in the
form of a List. For example, consider the following three traversals:
gremlin> g.V().has('name','marko').values('age') //1\
==>29
gremlin> g.V().has('name','marko'). //2\
repeat(out()).
until(has('lang','java')).
path().
by('name')
==>[marko,lop]
==>[marko,josh,ripple]
==>[marko,josh,lop]
gremlin> g.V().has('name','marko'). //3\
repeat(outE().inV()).
until(has('lang','java')).
path().
local(unfold().
has('weight').
values('weight').
mean())
==>0.4
==>1.0
==>0.7g.V().has('name','marko').values('age') //1\
g.V().has('name','marko'). //2\
repeat(out()).
until(has('lang','java')).
path().
by('name')
g.V().has('name','marko'). //3\
repeat(outE().inV()).
until(has('lang','java')).
path().
local(unfold().
has('weight').
values('weight').
mean())-
Get the age of "marko"
-
get the "name" values of the vertices in the collected paths that traverse out from "marko" to any vertex with the "lang" of "java".
-
Get the average of the "weight" values of edges in the collected paths that traverse out from "marko" to any vertex with the "lang" of "java". Note the use of the earlier defined pattern that used
local()in conjunction withunfold(). In this case it filters out vertices from thePathas they are not relevant as the concern is only with the "weight" property on the edges.
For purposes of this example, the three traversals above happen to represent three pieces of data that are required by
an application. It is plain to note that all of the above traversals hold a similar pattern that starts with
"getting 'marko'" and, in the case of the latter two, traversing on outgoing edges away from him and collecting data
from that path. Ideally, all three of these traversals should execute as one to prevent having to submit three separate
traversals, thus incurring additional query execution costs for what amounts to be largely the same underlying data but
with different transformations applied. The goal here would be to return the results of this data as a List with
three results (i.e. triple) that could then be submitted once by the application. The following example demonstrates
the use of store() to aid in construction of this List:
gremlin> g.V().has('name','marko').as('v'). //1\
store('a'). //2\
by('age').
repeat(outE().as('e').inV().as('v')). //3\
until(has('lang','java')).
aggregate('b'). //4\
by(select(all,'v').unfold().values('name').fold()).
aggregate('c'). //5\
by(select(all,'e').unfold().values('weight').mean()).
fold(). //6\
store('a'). //7\
by(cap('b')).
store('a'). //8\
by(cap('c')).
cap('a')
==>[29,[[marko,lop],[marko,josh,ripple],[marko,josh,lop]],[0.4,1.0,0.7]]g.V().has('name','marko').as('v'). //1\
store('a'). //2\
by('age').
repeat(outE().as('e').inV().as('v')). //3\
until(has('lang','java')).
aggregate('b'). //4\
by(select(all,'v').unfold().values('name').fold()).
aggregate('c'). //5\
by(select(all,'e').unfold().values('weight').mean()).
fold(). //6\
store('a'). //7\
by(cap('b')).
store('a'). //8\
by(cap('c')).
cap('a')-
Get the "marko" vertex and label that step as "v".
-
Store the first "age" of "marko" as the first item in the
Listcalled "a", which will ultimately be the result. -
Execute the traversal away from "marko" and continue to traverse on outgoing edges until the vertex has the value of "java" for the "lang" property. Note the labels of "e" and "v". Note that "e" will contain a
Listof all of the edges that have been traversed and "v" will contain aListof all the vertices that have been traversed. -
The incoming traverser to
aggregate('b')are vertices that terminate therepeat()(i.e. those with the "lang" of "java"). Note however that theby()modulator overrides that traverser completely by starting a fresh stream of the list of vertices in "v". Those vertices are unfolded to retrieve the name property from each and then are reduced withfold()back into a list to be stored in the side-effected named "b". -
A similar use of
aggregate()as the previous step, though this one turns "e" into a stream of edges to calculate themean()to store in aListcalled "c". Note thataggregate()was used here instead ofstore(), as the former is an eager collection of the elements in the stream (store()is lazy) and will force the traversal to be iterated up to that point before moving forward. Without that eager collection, "v" and "e" would not contain the complete information required for the production of "b" and "c". -
Adding
fold()-step here is a bit of a trick. To see the trick, copy and paste all lines of Gremlin up to but not including thisfold()-step and run them against the "modern" graph. The output is three vertices and if theprofile()-step was added one would also see that the traversal contained three traversers. These three traversers with a vertex in each one were produced from therepeat()-step (i.e. those vertices that had the "lang" of "java" when traversing away from "marko"). Theaggregate()-steps are side-effects and just allow the traversers to pass through them unchanged. Thefold()obviously converts those three traversers to a singleListto make one traverser with aListinside. That means that the remaining steps following thefold()will only be executed one time each instead of three, which, as will be shown, is critical to the proper result. -
The single traverser with the
Listof three vertices in it passes tostore(). Theby()modulator presents an override telling Gremlin to ignore theListof three vertices and simply grab the "b" side effect created earlier and stick that into "a" as part of the result. TheListwith three vertices passes out unchanged asstore()is a side-effect step. -
Again, the single traverser with the
Listof three vertices passes tostore()and again, theby()modulator presents an override to include "c" into the result.
All of the above code and explanation show that store() can be used to construct List objects as side-effects
which can then be used as a result. Note that aggregate() can be used to similar effect, should it make sense that
lazy List creation is not acceptable with respect to the nature of the traversal. An interesting sub-pattern that
emerges here is that the by()-step can modulate its step to completely override the current traverser and ignore its
contents for purpose of that step. This ability to override a traverser acts as a powerful and flexible tool as it
means that each traverser can effectively become a completely different object as determined by a sub-traversal.
Another interesting method for List creation was demonstrated a bit earlier but not examined in detail - the use of
union(). It was shown earlier in the following context where it helped create a List of two lists of three
vertices each:
gremlin> g.V().union(limit(3).fold(),tail(3).fold())
==>[v[1],v[2],v[3]]
==>[v[4],v[5],v[6]]g.V().union(limit(3).fold(),tail(3).fold())By folding the results of union(), it becomes possible to essentially construct lists with arbitrary traversal
results.
gremlin> g.V().
local(union(identity(), //1\
bothE().count()).
fold())
==>[v[1],3]
==>[v[2],1]
==>[v[3],3]
==>[v[4],3]
==>[v[5],1]
==>[v[6],1]
gremlin> g.V().
store('x').
by(union(select('x').count(local), //2\
identity(),
bothE().count()).
fold()).
cap('x')
==>[[0,v[1],3],[1,v[2],1],[2,v[3],3],[3,v[4],3],[4,v[5],1],[5,v[6],1]]g.V().
local(union(identity(), //1\
bothE().count()).
fold())
g.V().
store('x').
by(union(select('x').count(local), //2\
identity(),
bothE().count()).
fold()).
cap('x')-
For each vertex, create a "pair" (i.e. a
Listof two objects) of the vertex itself and its edge count. -
For each vertex, create a "triple" (i.e. a `List`of three objects) of the index of the vertex (starting at zero), the vertex itself and its edge count.
The pattern here is to use union() in conjunction with fold(). As explained earlier, the fold() operation reduces
the stream from union() to a single List that is then fed forward to the next step in the traversal.
Now that List patterns have been explained, there can now be some attention on Map. One of the most common ways
to end up with a Map is with valueMap():
gremlin> g.V().has('name','marko').valueMap('name','age')
==>[name:[marko],age:[29]]g.V().has('name','marko').valueMap('name','age')The problem is that unless the graph is making use of multi-properties, there is little need to have the value of each
property stored as a List. One way to unwrap this value from the list is to avoid having it there in the first place
by avoiding use of valueMap():
gremlin> g.V().has('name','marko').
local(properties('name','age').
group().by(key()).by(value()))
==>[name:marko,age:29]g.V().has('name','marko').
local(properties('name','age').
group().by(key()).by(value()))Interestingly, it’s worth looking at how to process the output of valueMap() to attain this output as the approach is
generally applicable to processing any Map instances with any sorts of values:
gremlin> g.V().has('name','marko').
valueMap('name','age').
unfold().
group().
by(keys).
by(select(values).unfold())
==>[name:marko,age:29]g.V().has('name','marko').
valueMap('name','age').
unfold().
group().
by(keys).
by(select(values).unfold())The code above, basically deconstructs then reconstructs the Map. The key to the pattern is to first unfold() the
Map into its key and value entries. Then for each key and value produce a new Map using group() where the key
for that map is the key of the entry (those are obviously unique as you picked them out of the valueMap()) and the
value is simply the unfold() of the list of values in each entry. Recall that the select(values).unfold() only
returns one value (i.e. the first) not only because there is only one, but also because by() will only call next()
on that sub-traversal (it does not iterate the entire thing).
Generally speaking, a Map constructed as part of group() or project() will already be in the form required as
the by() modulators would be written in such a fashion as to produce that final output. It would be unnecessary to
deconstruct/reconstruct it. Be certain that there isn’t a way to re-write the group() or project() to get the
desired output before taking this approach.
In the following case, project() is used to create a Map that does not meet this requirement as it contains some
unavoidable extraneous keys in the output Map:
gremlin> g.V().
project('name','age','lang').
by('name').
by(coalesce(values('age'),constant('n/a'))).
by(coalesce(values('lang'),constant('n/a')))
==>[name:marko,age:29,lang:n/a]
==>[name:vadas,age:27,lang:n/a]
==>[name:lop,age:n/a,lang:java]
==>[name:josh,age:32,lang:n/a]
==>[name:ripple,age:n/a,lang:java]
==>[name:peter,age:35,lang:n/a]g.V().
project('name','age','lang').
by('name').
by(coalesce(values('age'),constant('n/a'))).
by(coalesce(values('lang'),constant('n/a')))The use of coalesce() works around the problem where "age" and "lang" are not necessarily property keys present on
every single vertex in the traversal stream. When the "age" or "lang" are not present, the constant of "n/a" is
supplied. While this may be an acceptable output, it is possible to shape the Map to be "nicer":
gremlin> g.V().
project('name','age','lang').
by('name').
by(coalesce(values('age'),constant('n/a'))).
by(coalesce(values('lang'),constant('n/a'))).
local(unfold().
filter(select(values).is(P.neq('n/a'))).
group().
by(keys).
by(values))
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
==>[name:[lop],lang:[java]]
==>[name:[josh],age:[32]]
==>[name:[ripple],lang:[java]]
==>[name:[peter],age:[35]]g.V().
project('name','age','lang').
by('name').
by(coalesce(values('age'),constant('n/a'))).
by(coalesce(values('lang'),constant('n/a'))).
local(unfold().
filter(select(values).is(P.neq('n/a'))).
group().
by(keys).
by(values))The additional steps above unfold() the Map to key-value entries and filter the values for "n/a" and remove them
prior to reconstructing the Map with the method shown earlier. To go a step further, apply the pattern presented
earlier to flatten List values within a Map:
gremlin> g.V().
project('name','age','lang').
by('name').
by(coalesce(values('age'),constant('n/a'))).
by(coalesce(values('lang'),constant('n/a'))).
local(unfold().
filter(select(values).is(P.neq('n/a'))).
group().
by(keys).
by(select(values).unfold()))
==>[name:marko,age:29]
==>[name:vadas,age:27]
==>[name:lop,lang:java]
==>[name:josh,age:32]
==>[name:ripple,lang:java]
==>[name:peter,age:35]g.V().
project('name','age','lang').
by('name').
by(coalesce(values('age'),constant('n/a'))).
by(coalesce(values('lang'),constant('n/a'))).
local(unfold().
filter(select(values).is(P.neq('n/a'))).
group().
by(keys).
by(select(values).unfold()))As there may be a desire to remove entries from a Map, there may also be the need to add keys to a Map. The pattern
here involves the use of a union() that returns the Map instances which can be flattened to entries and then
reconstructed as a new Map that has been merged together:
gremlin> g.V().
has('name','marko').
union(project('degree'). //1\
by(bothE().count()),
valueMap().with(WithOptions.tokens)).
unfold(). //2\
group().
by(keys).
by(select(values).unfold())
==>[id:1,degree:3,name:marko,label:person,age:29]g.V().
has('name','marko').
union(project('degree'). //1\
by(bothE().count()),
valueMap().with(WithOptions.tokens)).
unfold(). //2\
group().
by(keys).
by(select(values).unfold())-
The
valueMap().with(WithOptions.tokens)of aVertexcan be extended with the "degree" of theVertexby performing aunion()of the two traversals that produce that output (both produceMapobjects). -
The
unfold()-step is used to decompose theMapobjects into key/value entries that are then constructed back into a single newMapgiven the patterns shown earlier. TheMapobjects of both traversals in theunion()are essentially merged together.
When using this pattern, it is important to recognize that if there are non-unique keys produced by the traversals
supplied to union(), they will overwrite one another given the final by() modulator above. If changed to
by(select(values).unfold().fold()) they will merge to produce a List of values. Of course, that change will bring
a List back for all the values of the new Map. With some added logic the Map values can be flattened out of
List instances when necessary:
gremlin> g.V().
has('name','marko').
union(valueMap().with(WithOptions.tokens),
project('age').
by(constant(100))).
unfold().
group().
by(keys).
by(select(values).
unfold().
fold().
choose(count(local).is(eq(1)), unfold()))
==>[id:1,name:marko,label:person,age:[29,100]]g.V().
has('name','marko').
union(valueMap().with(WithOptions.tokens),
project('age').
by(constant(100))).
unfold().
group().
by(keys).
by(select(values).
unfold().
fold().
choose(count(local).is(eq(1)), unfold()))Connected Components
Gremlin can be used to find connected components in a graph. In a directed graph like in TinkerPop, components can be weakly or strongly connected. This recipe is restricted to finding weakly connected components, in which the direction of edges is not taken into account.
Depending on the size of the graph, three solution regimes can be discriminated:
-
Small graphs that fit in the memory of a single machine
-
Medium-sized graphs backed by storage for which an OLTP linear scan is still feasible. This regime is left to third party TinkerPop implementations, since TinkerPop itself has no storage-backed reference implementations. The idea is that component membership is stored in the graph, rather than in memory.
-
Large graphs requiring an approach with
HadoopGraphandSparkGraphComputerto yield results in a reasonable time.
These regimes are discussed separately using the following graph with three weakly connected components:
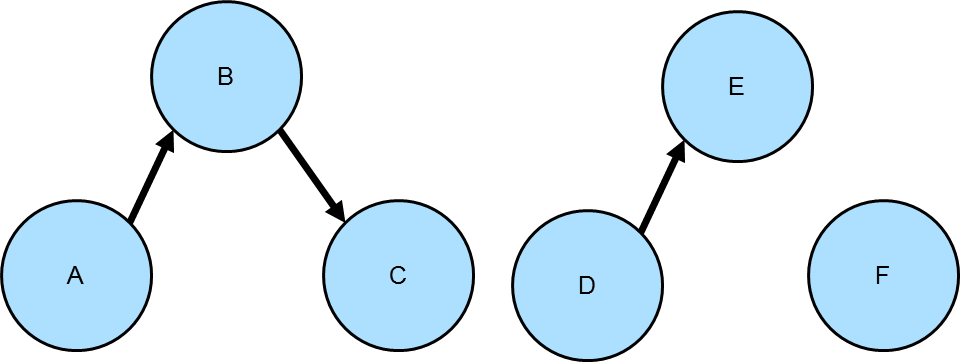
gremlin> g.addV().property(id, "A").as("a").
addV().property(id, "B").as("b").
addV().property(id, "C").as("c").
addV().property(id, "D").as("d").
addV().property(id, "E").as("e").
addV().property(id, "F").
addE("link").from("a").to("b").
addE("link").from("b").to("c").
addE("link").from("d").to("e").iterate()g.addV().property(id, "A").as("a").
addV().property(id, "B").as("b").
addV().property(id, "C").as("c").
addV().property(id, "D").as("d").
addV().property(id, "E").as("e").
addV().property(id, "F").
addE("link").from("a").to("b").
addE("link").from("b").to("c").
addE("link").from("d").to("e").iterate()Small graph traversals
Connected components in a small graph can be determined with either an OLTP traversal or the OLAP
connectedComponent()-step. The connectedComponent()-step is available as of TinkerPop 3.4.0 and is
described in more detail in the
Reference Documentation.
The traversal looks like:
gremlin> g.withComputer().V().connectedComponent().
group().by(ConnectedComponent.component).
select(values).unfold()
==>[v[D],v[E]]
==>[v[A],v[C],v[B]]
==>[v[F]]g.withComputer().V().connectedComponent().
group().by(ConnectedComponent.component).
select(values).unfold()|
Note
|
The component option passed to by() is statically imported from ConnectedComponent and refers to the
default property key within which the result of the algorithm is stored.
|
A straightforward way to detect the various subgraphs with an OLTP traversal is to do this:
gremlin> g.V().emit(cyclicPath().or().not(both())). //1\
repeat(__.where(without('a')).store('a').both()).until(cyclicPath()). //2\
group().by(path().unfold().limit(1)). //3\
by(path().unfold().dedup().fold()). //4\
select(values).unfold() //5\
==>[v[A],v[B],v[C]]
==>[v[D],v[E]]
==>[v[F]]g.V().emit(cyclicPath().or().not(both())). //1\
repeat(__.where(without('a')).store('a').both()).until(cyclicPath()). //2\
group().by(path().unfold().limit(1)). //3\
by(path().unfold().dedup().fold()). //4\
select(values).unfold() //5-
The initial emit() step allows for output of isolated vertices, in addition to the discovery of components as described in (2).
-
The entire component to which the first returned vertex belongs, is visited. To allow for components of any structure, a repeat loop is applied that only stops for a particular branch of the component when it detects a cyclic path. Collection
'a'is used to keep track of visited vertices, for both subtraversals within a component and new traversals resulting from theg.V()linear scan. -
While
'a'nicely keeps track of vertices already visited, the actual components need to be extracted from the path information. Thepath().unfold().limit(1)closure provides the starting vertex of surviving traversers, which can be used to group the components. -
This clause collects the unique vertices from all paths with the same starting vertex, thus from the same weak component.
-
The values of the groupby map contain the lists of vertices making up the requested components.
Small graph scalability
The scalability of the OLTP traversal and the connectedComponent()-step for in-memory graphs is shown in the figures
below.
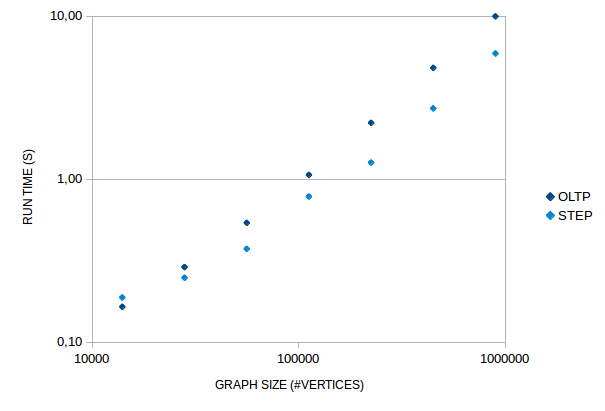
In general, the connectedComponent()-step is almost a factor two faster than the OLTP traversal. Only, for very
small graphs the overhead of running the ConnectedComponentVertexProgram is larger than that of the OLTP traversal.
The vertex program works by having interconnected vertices exchange id’s and store the lowest id until no vertex
receives a lower id. This algorithm is commonly applied in
bulk synchronous parallel systems, e.g. in
Apache Spark GraphX. Overhead for the vertex program arises because it has to run
as many cycles as the largest length of the shortest paths between any two vertices in a component of the graph. In
every cycle each vertex has to be checked for being
"halted". Overhead of the OLTP traversal consists of each traverser having to carry complete path information. For
pure depth-first-search or breadth-first-search implementations, connected-component algotithms should scale
as O(V+E). For the traversals in the figure above this is almost the case.
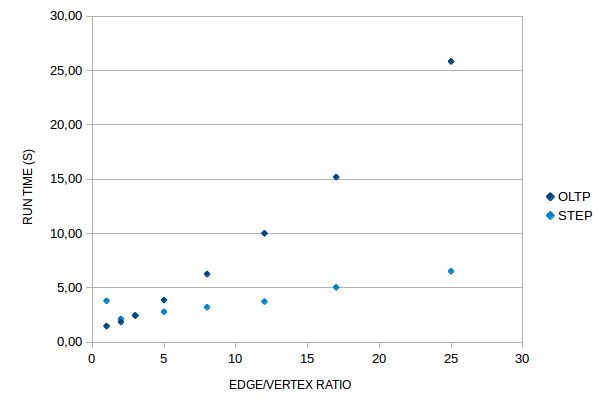
The random graphs used for the scalability tests can be modulated with the edge/vertex ratio. For small ratios the
components generated are more lint-like and harder to process by the connectedComponent()-step. For high ratios
the components are more mesh-like and the ConnectedComponentVertexProgram needs few cycles to process the graph. These
characteristics show clearly from the graph. Indeed, for a given number of vertices, the run time of the
connectedComponent()-step does not depend on the number of edges, but rather on the maximum shortest path length in
the graph.
Large graphs
Large graphs in TinkerPop require distributed processing by SparkGraphComputer to get results in a reasonable time (OLAP
approach). This means that the graph must be available as HadoopGraph (third party TinkerPop implementations often
allow to make a graph available as an HadoopGraph by providing an Hadoop InputFormat). Running the
connectedComponent()-step on
an HadoopGraph works the same as for a small graph, provided that SparkGraphComputer is specified as the graph computer,
either with the gremlin.hadoop.defaultGraphComputer property or as part of the withComputer()-step.
Scalability of the the connectedComponent()-step with SparkGraphComputer is high, but note that:
-
The graph should fit in the memory of the Spark cluster to allow the VertexProgram to run its cycles without spilling intermediate results to disk and loosing most of the gains from the distributed processing.
-
As discussed for small graphs, the BSP algorithm does not play well with graphs having a large shortest path between any pair of vertices. Overcoming this limitation is still a subject of academic research.
Cycle Detection
A cycle occurs in a graph where a path loops back on itself to the originating vertex. For example, in the graph
depicted below Gremlin could be use to detect the cycle among vertices A-B-C.
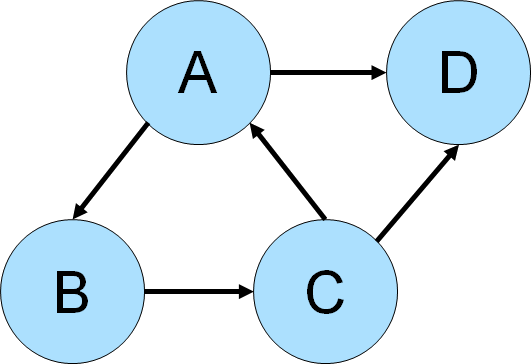
gremlin> g.addV().property(id,'a').as('a').
addV().property(id,'b').as('b').
addV().property(id,'c').as('c').
addV().property(id,'d').as('d').
addE('knows').from('a').to('b').
addE('knows').from('b').to('c').
addE('knows').from('c').to('a').
addE('knows').from('a').to('d').
addE('knows').from('c').to('d').iterate()
gremlin> g.V().as('a').repeat(out().simplePath()).times(2).
where(out().as('a')).path() //1\
==>[v[a],v[b],v[c]]
==>[v[b],v[c],v[a]]
==>[v[c],v[a],v[b]]
gremlin> g.V().as('a').repeat(out().simplePath()).times(2).
where(out().as('a')).path().
dedup().by(unfold().order().by(id).dedup().fold()) //2\
==>[v[a],v[b],v[c]]g.addV().property(id,'a').as('a').
addV().property(id,'b').as('b').
addV().property(id,'c').as('c').
addV().property(id,'d').as('d').
addE('knows').from('a').to('b').
addE('knows').from('b').to('c').
addE('knows').from('c').to('a').
addE('knows').from('a').to('d').
addE('knows').from('c').to('d').iterate()
g.V().as('a').repeat(out().simplePath()).times(2).
where(out().as('a')).path() //1\
g.V().as('a').repeat(out().simplePath()).times(2).
where(out().as('a')).path().
dedup().by(unfold().order().by(id).dedup().fold()) //2-
Gremlin starts its traversal from a vertex labeled "a" and traverses
out()from each vertex filtering on thesimplePath, which removes paths with repeated objects. The steps goingout()are repeated twice as in this case the length of the cycle is known to be three and there is no need to exceed that. The traversal filters with awhere()to see only return paths that end with where it started at "a". -
The previous query returned the
A-B-Ccycle, but it returned three paths which were all technically the same cycle. It returned three, because there was one for each vertex that started the cycle (i.e. one forA, one forBand one forC). This next line introduce deduplication to only return unique cycles.
The above case assumed that the need was to only detect cycles over a path length of three. It also respected the directionality of the edges by only considering outgoing ones.
Also note that the traversal above won’t detect self-loops (vertices directly connected to
themselves). To do so, you would need to .emit() a Traverser before the repeat()-loop.
gremlin> g.addV().property(id,'a').as('a').
addV().property(id,'b').as('b').
addV().property(id,'c').as('c').
addV().property(id,'d').as('d').
addE('knows').from('a').to('b').
addE('knows').from('b').to('c').
addE('knows').from('c').to('a').
addE('knows').from('a').to('d').
addE('knows').from('c').to('d').
addE('self').from('a').to('a').iterate()
gremlin> g.V().as('a').
emit().
repeat(outE().inV().simplePath()).
times(2).
outE().inV().where(eq('a')).
path().
by(id).
by(label)
==>[a,self,a]
==>[a,knows,b,knows,c,knows,a]
==>[b,knows,c,knows,a,knows,b]
==>[c,knows,a,knows,b,knows,c]g.addV().property(id,'a').as('a').
addV().property(id,'b').as('b').
addV().property(id,'c').as('c').
addV().property(id,'d').as('d').
addE('knows').from('a').to('b').
addE('knows').from('b').to('c').
addE('knows').from('c').to('a').
addE('knows').from('a').to('d').
addE('knows').from('c').to('d').
addE('self').from('a').to('a').iterate()
g.V().as('a').
emit().
repeat(outE().inV().simplePath()).
times(2).
outE().inV().where(eq('a')).
path().
by(id).
by(label)What would need to change to detect cycles of arbitrary length over both incoming and outgoing edges, in the modern graph?
gremlin> g.V().as('a').repeat(both().simplePath()).emit(loops().is(gt(1))).
both().where(eq('a')).path().
dedup().by(unfold().order().by(id).dedup().fold())
==>[v[1],v[3],v[4],v[1]]g.V().as('a').repeat(both().simplePath()).emit(loops().is(gt(1))).
both().where(eq('a')).path().
dedup().by(unfold().order().by(id).dedup().fold())An interesting type of cycle is known as the Eulerian circuit which is a path taken in a graph where each edge is visited once and the path starts and ends with the same vertex. Consider the following graph, representative of an imaginary but geographically similar Königsberg that happens to have an eighth bridge (the diagram depicts edge direction but direction won’t be considered in the traversal):
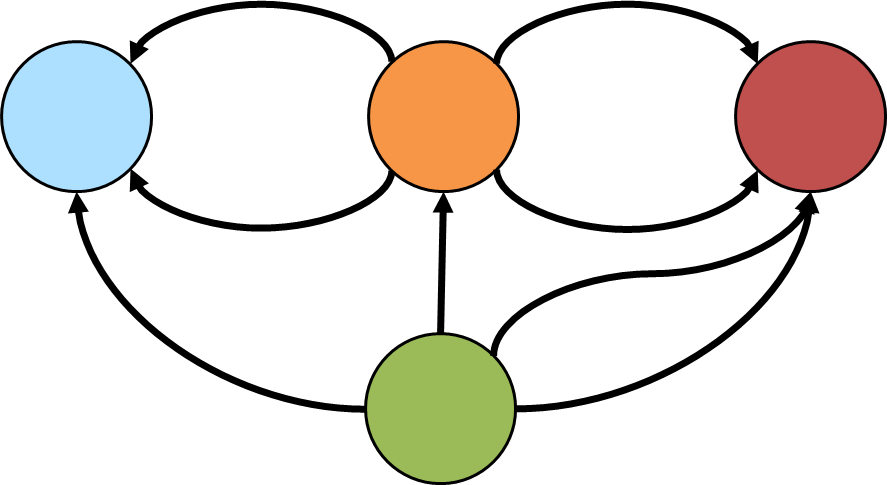
Gremlin can detect if such a cycle exists with:
gremlin> g.addV().property(id, 'blue').as('b').
addV().property(id, 'orange').as('o').
addV().property(id, 'red').as('r').
addV().property(id, 'green').as('g').
addE('bridge').from('g').to('b').
addE('bridge').from('g').to('o').
addE('bridge').from('g').to('r').
addE('bridge').from('g').to('r').
addE('bridge').from('o').to('b').
addE('bridge').from('o').to('b').
addE('bridge').from('o').to('r').
addE('bridge').from('o').to('r').iterate()
gremlin> g.V().sideEffect(outE("bridge").aggregate("bridges")).barrier(). //1\
repeat(bothE(). //2\
or(__.not(select('e')),
__.not(filter(__.as('x').select(all, 'e').unfold(). //3\
where(eq('x'))))).as('e').
otherV()).
until(select(all, 'e').count(local).as("c"). //4\
select("bridges").count(local).where(eq("c"))).hasNext()
==>trueg.addV().property(id, 'blue').as('b').
addV().property(id, 'orange').as('o').
addV().property(id, 'red').as('r').
addV().property(id, 'green').as('g').
addE('bridge').from('g').to('b').
addE('bridge').from('g').to('o').
addE('bridge').from('g').to('r').
addE('bridge').from('g').to('r').
addE('bridge').from('o').to('b').
addE('bridge').from('o').to('b').
addE('bridge').from('o').to('r').
addE('bridge').from('o').to('r').iterate()
g.V().sideEffect(outE("bridge").aggregate("bridges")).barrier(). //1\
repeat(bothE(). //2\
or(__.not(select('e')),
__.not(filter(__.as('x').select(all, 'e').unfold(). //3\
where(eq('x'))))).as('e').
otherV()).
until(select(all, 'e').count(local).as("c"). //4\
select("bridges").count(local).where(eq("c"))).hasNext()-
Gather all the edges in a "bridges" side effect.
-
As mentioned earlier with the diagram, directionality is ignored as the traversal uses
bothEand, later,otherV. -
In continually traversing over both incoming and outgoing edges, this path is only worth continuing if the edges traversed thus far are only traversed once. That set of edges is maintained in "e".
-
The traversal should repeat until the number of edges traversed in "e" is equal to the total number gathered in the first step above, which would mean that the complete circuit has been made.
Unlike Königsberg, with just seven bridges, a Eulerian circuit exists in the case with an eighth bridge. The first detected circuit can be displayed with:
gremlin> g.V().sideEffect(outE("bridge").aggregate("bridges")).barrier().
repeat(bothE().or(__.not(select('e')),
__.not(filter(__.as('x').select(all, 'e').unfold().
where(eq('x'))))).as('e').otherV()).
until(select(all, 'e').count(local).as("c").
select("bridges").count(local).where(eq("c"))).limit(1).
path().by(id).by(constant(" -> ")).
map {String.join("", it.get().objects())}
==>orange -> blue -> green -> orange -> red -> green -> red -> orange -> blueg.V().sideEffect(outE("bridge").aggregate("bridges")).barrier().
repeat(bothE().or(__.not(select('e')),
__.not(filter(__.as('x').select(all, 'e').unfold().
where(eq('x'))))).as('e').otherV()).
until(select(all, 'e').count(local).as("c").
select("bridges").count(local).where(eq("c"))).limit(1).
path().by(id).by(constant(" -> ")).
map {String.join("", it.get().objects())}Duplicate Edge Detection
Whether part of a graph maintenance process or for some other analysis need, it is sometimes necessary to detect if there is more than one edge between two vertices. The following examples will assume that an edge with the same label and direction will be considered "duplicate".
The "modern" graph does not have any duplicate edges that fit that definition, so the following example adds one that is duplicative of the "created" edge between vertex "1" and "3".
gremlin> g.V(1).as("a").V(3).addE("created").from("a").iterate()
gremlin> g.V(1).outE("created")
==>e[9][1-created->3]
==>e[13][1-created->3]g.V(1).as("a").V(3).addE("created").from("a").iterate()
g.V(1).outE("created")One way to find the duplicate edges would be to do something like this:
gremlin> g.V().outE().
project("a","b"). //1\
by().by(inV().path().by().by(label)).
group(). //2\
by(select("b")).
by(select("a").fold()).
unfold(). //3\
select(values). //4\
where(count(local).is(gt(1)))
==>[e[9][1-created->3],e[13][1-created->3]]g.V().outE().
project("a","b"). //1\
by().by(inV().path().by().by(label)).
group(). //2\
by(select("b")).
by(select("a").fold()).
unfold(). //3\
select(values). //4\
where(count(local).is(gt(1)))-
The "a" and "b" from the
projectcontain the edge and the path respectively. The path consists of a the outgoing vertex, an edge, and the incoming vertex. The use ofby().by(label))converts the edge to its label (recall thatbyare applied in round-robin fashion), so the path will look something like:[v[1],created,v[3]]. -
Group by the path from "b" and construct a list of edges from "a". Any value in this
Mapthat has a list of edges greater than one means that there is more than one edge for that edge label between those two vertices (i.e. theMapkey). -
Unroll the key-value pairs in the
Mapof paths-edges. -
Only the values from the
Mapare needed and as mentioned earlier, those lists with more than one edge would contain duplicate.
This method find the duplicates, but does require more memory than other approaches. A slightly more complex approach that uses less memory might look like this:
gremlin> g.V().as("ov").
outE().as("e").
inV().as("iv").
inE(). //1\
where(neq("e")). //2\
where(eq("e")).by(label).
where(outV().as("ov")).
group().
by(select("ov","e","iv").by().by(label)). //3\
unfold(). //4\
select(values).
where(count(local).is(gt(1)))
==>[e[13][1-created->3],e[9][1-created->3]]g.V().as("ov").
outE().as("e").
inV().as("iv").
inE(). //1\
where(neq("e")). //2\
where(eq("e")).by(label).
where(outV().as("ov")).
group().
by(select("ov","e","iv").by().by(label)). //3\
unfold(). //4\
select(values).
where(count(local).is(gt(1)))-
To this point in the traversal, the outgoing edges of a vertex are being iterated with the current edge labeled as "e". For "e", Gremlin traverses to the incoming vertex and back on in edges of that vertex.
-
Those incoming edges are filtered with the following
wheresteps. The first ensures that it does not traverse back over "e" (i.e. the current edge). The second determines if the edge label is equivalent (i.e. the test for the working definition of "duplicate"). The third determines if the outgoing vertex matches the one that started the path labeled as "ov". -
This line is quite similar to the output achieved in the previous example at step 2. A
Mapis produced that uses the outgoing vertex, the edge label, and the incoming vertex as the key, with the list of edges for that path as the value. -
The rest of the traversal is the same as the previous one.
Note that the above traversal could also be written using match step:
gremlin> g.V().match(
__.as("ov").outE().as("e"),
__.as("e").inV().as("iv"),
__.as("iv").inE().as("ie"),
__.as("ie").outV().as("ov")).
where("ie",neq("e")).
where("ie",eq("e")).by(label).
select("ie").
group().
by(select("ov","e","iv").by().by(label)).
unfold().select(values).
where(count(local).is(gt(1)))
==>[e[13][1-created->3],e[9][1-created->3]]g.V().match(
__.as("ov").outE().as("e"),
__.as("e").inV().as("iv"),
__.as("iv").inE().as("ie"),
__.as("ie").outV().as("ov")).
where("ie",neq("e")).
where("ie",eq("e")).by(label).
select("ie").
group().
by(select("ov","e","iv").by().by(label)).
unfold().select(values).
where(count(local).is(gt(1)))A third way to approach this problem would be to force a depth-first search. The previous examples invoke traversal strategies that force a breadth first search as a performance optimization.
gremlin> g.withoutStrategies(LazyBarrierStrategy, PathRetractionStrategy).V().as("ov"). //1\
outE().as("e1").
inV().as("iv").
inE().
where(neq("e1")).
where(outV().as("ov")).as("e2"). //2\
where("e1", eq("e2")).by(label) //3\
==>e[13][1-created->3]
==>e[9][1-created->3]g.withoutStrategies(LazyBarrierStrategy, PathRetractionStrategy).V().as("ov"). //1\
outE().as("e1").
inV().as("iv").
inE().
where(neq("e1")).
where(outV().as("ov")).as("e2"). //2\
where("e1", eq("e2")).by(label) //3-
Remove strategies that will optimize for breadth first searches and thus allow Gremlin to go depth first.
-
To this point, the traversal is very much like the previous one. Review step 2 in the previous example to see the parallels here.
-
The final
wheresimply looks for edges that match on label, which would then meet the working definition of "duplicate".
The basic pattern at play here is to compare the path of the outgoing vertex, its outgoing edge label and the incoming vertex. This model can obviously be contracted or expanded as needed to fit different definitions of "duplicate". For example, a "duplicate" definition could extended to the label and properties of the edge. For purposes of demonstration, an additional edge is added to the "modern" graph:
gremlin> g.V(1).as("a").V(3).addE("created").property("weight",0.4d).from("a").iterate()
gremlin> g.V(1).as("a").V(3).addE("created").property("weight",0.5d).from("a").iterate()
gremlin> g.V(1).outE("created").valueMap().with(WithOptions.tokens)
==>[id:9,label:created,weight:0.4]
==>[id:13,label:created,weight:0.4]
==>[id:14,label:created,weight:0.5]g.V(1).as("a").V(3).addE("created").property("weight",0.4d).from("a").iterate()
g.V(1).as("a").V(3).addE("created").property("weight",0.5d).from("a").iterate()
g.V(1).outE("created").valueMap().with(WithOptions.tokens)To identify the duplicate with this revised definition, the previous traversal can be modified to:
gremlin> g.withoutStrategies(LazyBarrierStrategy, PathRetractionStrategy).V().as("ov").
outE().as("e1").
inV().as("iv").
inE().
where(neq("e1")).
where(outV().as("ov")).as("e2").
where("e1", eq("e2")).by(label).
where("e1", eq("e2")).by("weight").valueMap().with(WithOptions.tokens)
==>[id:13,label:created,weight:0.4]
==>[id:9,label:created,weight:0.4]g.withoutStrategies(LazyBarrierStrategy, PathRetractionStrategy).V().as("ov").
outE().as("e1").
inV().as("iv").
inE().
where(neq("e1")).
where(outV().as("ov")).as("e2").
where("e1", eq("e2")).by(label).
where("e1", eq("e2")).by("weight").valueMap().with(WithOptions.tokens)Duplicate Vertex Detection
The pattern for finding duplicate vertices is quite similar to the pattern defined in the Duplicate Edge section. The idea is to extract the relevant features of the vertex into a comparable list that can then be used to group for duplicates.
Consider the following example with some duplicate vertices added to the "modern" graph:
gremlin> g.addV('person').property('name', 'vadas').property('age', 27)
==>v[13]
gremlin> g.addV('person').property('name', 'vadas').property('age', 22) // not a duplicate because "age" value
==>v[16]
gremlin> g.addV('person').property('name', 'marko').property('age', 29)
==>v[19]
gremlin> g.V().hasLabel("person").
group().
by(values("name", "age").fold()).
unfold()
==>[marko, 29]=[v[1], v[19]]
==>[vadas, 27]=[v[2], v[13]]
==>[peter, 35]=[v[6]]
==>[vadas, 22]=[v[16]]
==>[josh, 32]=[v[4]]g.addV('person').property('name', 'vadas').property('age', 27)
g.addV('person').property('name', 'vadas').property('age', 22) // not a duplicate because "age" value
g.addV('person').property('name', 'marko').property('age', 29)
g.V().hasLabel("person").
group().
by(values("name", "age").fold()).
unfold()In the above case, the "name" and "age" properties are the relevant features for identifying duplication. The key in
the Map provided by the group is the list of features for comparison and the value is the list of vertices that
match the feature. To extract just those vertices that contain duplicates an additional filter can be added:
gremlin> g.V().hasLabel("person").
group().
by(values("name", "age").fold()).
unfold().
filter(select(values).count(local).is(gt(1)))
==>[marko, 29]=[v[1], v[19]]
==>[vadas, 27]=[v[2], v[13]]g.V().hasLabel("person").
group().
by(values("name", "age").fold()).
unfold().
filter(select(values).count(local).is(gt(1)))That filter, extracts the values of the Map and counts the vertices within each list. If that list contains more than
one vertex then it is a duplicate.
Moving an Edge

Aside from their properties, edges are immutable structures where the label and the related in and out vertices cannot be modified. To "move" an edge from one vertex to another, it requires that the edge be dropped and a new edge be created with the same properties and label. It is possible to simulate this "move" in a single traversal as follows:
gremlin> g.V().has('name','marko').
outE().inV().
path().by('name').by(valueMap().with(WithOptions.tokens))
==>[marko,[id:9,label:created,weight:0.4],lop]
==>[marko,[id:7,label:knows,weight:0.5],vadas]
==>[marko,[id:8,label:knows,weight:1.0],josh]g.V().has('name','marko').
outE().inV().
path().by('name').by(valueMap().with(WithOptions.tokens))The "marko" vertex contains a "knows" edge to the "vadas" vertex. The following code shows how to "move" that edge to the "peter" vertex in a single traversal:
gremlin> g.V().has('name','marko').as('a').
outE('knows').as('e1').filter(inV().has('name','vadas')). //1\
V().has('name','peter').
addE('knows').from('a').as('e2'). //2\
sideEffect(select('e1').properties().
unfold().as('p').
select('e2').
property(select('p').key(), select('p').value())). //3\
select('e1').drop() //4\
gremlin> g.V().has('name','marko').
outE().inV().
path().by('name').by(valueMap().with(WithOptions.tokens))
==>[marko,[id:9,label:created,weight:0.4],lop]
==>[marko,[id:8,label:knows,weight:1.0],josh]
==>[marko,[id:13,label:knows,weight:0.5],peter]g.V().has('name','marko').as('a').
outE('knows').as('e1').filter(inV().has('name','vadas')). //1\
V().has('name','peter').
addE('knows').from('a').as('e2'). //2\
sideEffect(select('e1').properties().
unfold().as('p').
select('e2').
property(select('p').key(), select('p').value())). //3\
select('e1').drop() //4\
g.V().has('name','marko').
outE().inV().
path().by('name').by(valueMap().with(WithOptions.tokens))-
Find the edge to "move" and label that as "e1". It will be necessary to reference this later to get the edge properties to transfer to the new "moved" edge.
-
Add the "moved" edge and label it as "e2".
-
Use a
sideEffect()to transfer the properties from "e1" to "e2". -
Use
drop()to get rid of the old edge at "e1" now that the new "e2" edge is in place.
Element Existence
Checking for whether or not a graph element is present in the graph is simple:
gremlin> g.V().has('person','name','marko').hasNext()
==>true
gremlin> g.V().has('person','name','stephen').hasNext()
==>falseg.V().has('person','name','marko').hasNext()
g.V().has('person','name','stephen').hasNext()Knowing that an element exists or not is usually a common point of decision in determining the appropriate path of code to take. In the example above, the check is for vertex existence and a typical reason to check for existence is to determine whether or not to add a new vertex or to return the one that exists (i.e. "get or create" pattern). This entire operation can occur in a single traversal.
gremlin> g.V().has('person','name','marko').
fold().
coalesce(unfold(),
addV('person').
property('name','marko').
property('age',29))
==>v[1]
gremlin> g.V().has('person','name','stephen').
fold().
coalesce(unfold(),
addV('person').
property('name','stephen').
property('age',34))
==>v[13]g.V().has('person','name','marko').
fold().
coalesce(unfold(),
addV('person').
property('name','marko').
property('age',29))
g.V().has('person','name','stephen').
fold().
coalesce(unfold(),
addV('person').
property('name','stephen').
property('age',34))This use of coalesce() shown above is the basis for this pattern. Note that at the end of has()-step there is
either a vertex or not. By using fold(), "existence" or "not existence" is reduced to a List with the vertex or
a List with no values. With a List as the traverser flowing into coalesce() the first child traversal to return
something will execute. If the List has a vertex then it will unfold() and return the existing one. If it is empty,
then the vertex does not exist and it is added and returned.
This "get or create" logic can be expanded to be "upsert" like functionality as follows:
gremlin> g.V().has('person','name','marko').
fold().
coalesce(unfold(),
addV('person').property('name','marko')).
property('age',29)
==>v[1]
gremlin> g.V().has('person','name','stephen').
fold().
coalesce(unfold(),
addV('person').property('name','stephen')).
property('age',34)
==>v[13]g.V().has('person','name','marko').
fold().
coalesce(unfold(),
addV('person').property('name','marko')).
property('age',29)
g.V().has('person','name','stephen').
fold().
coalesce(unfold(),
addV('person').property('name','stephen')).
property('age',34)By moving the property()-step that set the "age" value outside of coalesce(), the property is then set for both
newly created vertices and for existing ones.
|
Warning
|
Always consider the specific nature of the graph implementation in use when considering these patterns. Some graph databases may not treat these traversals as true "upsert" operations and may do a "read before write" in their execution. |
It is possible to do similar sorts of operations with edges using the same pattern:
gremlin> g.V().has('person','name','vadas').as('v').
V().has('software','name','ripple').
coalesce(__.inE('created').where(outV().as('v')),
addE('created').from('v').property('weight',0.5))
==>e[13][2-created->5]g.V().has('person','name','vadas').as('v').
V().has('software','name','ripple').
coalesce(__.inE('created').where(outV().as('v')),
addE('created').from('v').property('weight',0.5))In this case, the adjacent vertices of the edge are retrieved first and within the coalesce(), the existence of
the edge is checked with where() using a matching pattern on the "v" label and returned if found. If the edge is not
found between these two vertices, then it is created as part of the second traversal given to coalesce().
If-Then Based Grouping
Consider the following traversal over the "modern" toy graph:
gremlin> g.V().hasLabel('person').groupCount().by('age')
==>[32:1,35:1,27:1,29:1]g.V().hasLabel('person').groupCount().by('age')The result is an age distribution that simply shows that every "person" in the graph is of a different age. In some cases, this result is exactly what is needed, but sometimes a grouping may need to be transformed to provide a different picture of the result. For example, perhaps a grouping on the value "age" would be better represented by a domain concept such as "young", "old" and "very old".
gremlin> g.V().hasLabel("person").groupCount().by(values("age").choose(
is(lt(28)),constant("young"),
choose(is(lt(30)),
constant("old"),
constant("very old"))))
==>[young:1,old:1,very old:2]g.V().hasLabel("person").groupCount().by(values("age").choose(
is(lt(28)),constant("young"),
choose(is(lt(30)),
constant("old"),
constant("very old"))))Note that the by modulator has been altered from simply taking a string key of "age" to take a Traversal. That
inner Traversal utilizes choose which is like an if-then-else clause. The choose is nested and would look
like the following in Java:
if (age < 28) {
return "young";
} else {
if (age < 30) {
return "old";
} else {
return "very old";
}
}The use of choose is a good intuitive choice for this Traversal as it is a natural mapping to if-then-else, but
there is another option to consider with coalesce:
gremlin> g.V().hasLabel("person").
groupCount().by(values("age").
coalesce(is(lt(28)).constant("young"),
is(lt(30)).constant("old"),
constant("very old")))
==>[young:1,old:1,very old:2]g.V().hasLabel("person").
groupCount().by(values("age").
coalesce(is(lt(28)).constant("young"),
is(lt(30)).constant("old"),
constant("very old")))The answer is the same, but this traversal removes the nested choose, which makes it easier to read.
Pagination
 In most database applications, it is oftentimes desirable to return
discrete blocks of data for a query rather than all of the data that the total results would contain. This approach to
returning data is referred to as "pagination" and typically involves a situation where the client executing the query
can specify the start position and end position (or the amount of data to return in lieu of the end position)
representing the block of data to return. In this way, one could return the first ten records of one hundred, then the
second ten records and so on, until potentially all one hundred were returned.
In most database applications, it is oftentimes desirable to return
discrete blocks of data for a query rather than all of the data that the total results would contain. This approach to
returning data is referred to as "pagination" and typically involves a situation where the client executing the query
can specify the start position and end position (or the amount of data to return in lieu of the end position)
representing the block of data to return. In this way, one could return the first ten records of one hundred, then the
second ten records and so on, until potentially all one hundred were returned.
In Gremlin, a basic approach to paging would look something like the following:
gremlin> g.V().hasLabel('person').fold() //1\
==>[v[1],v[2],v[4],v[6]]
gremlin> g.V().hasLabel('person').
fold().as('persons','count').
select('persons','count').
by(range(local, 0, 2)).
by(count(local)) //2\
==>[persons:[v[1],v[2]],count:4]
gremlin> g.V().hasLabel('person').
fold().as('persons','count').
select('persons','count').
by(range(local, 2, 4)).
by(count(local)) //3\
==>[persons:[v[4],v[6]],count:4]g.V().hasLabel('person').fold() //1\
g.V().hasLabel('person').
fold().as('persons','count').
select('persons','count').
by(range(local, 0, 2)).
by(count(local)) //2\
g.V().hasLabel('person').
fold().as('persons','count').
select('persons','count').
by(range(local, 2, 4)).
by(count(local)) //3-
Gets all the "person" vertices.
-
Gets the first two "person" vertices and includes the total number of vertices so that the client knows how many it has to page through.
-
Gets the final two "person" vertices.
From a functional perspective, the above example shows a fairly standard paging model. Unfortunately, there is a
problem. To get the total number of vertices, the traversal must first fold() them, which iterates out
the traversal bringing them all into memory. If the number of "person" vertices is large, that step could lead to a
long running traversal and perhaps one that would simply run out of memory prior to completion. There is no shortcut
to getting a total count without doing a full iteration of the traversal. If the requirement for a total count is
removed then the traversals become more simple:
gremlin> g.V().hasLabel('person').range(0,2)
==>v[1]
==>v[2]
gremlin> g.V().hasLabel('person').range(2,4)
==>v[4]
==>v[6]g.V().hasLabel('person').range(0,2)
g.V().hasLabel('person').range(2,4)|
Note
|
The first traversal above could also be written as g.V().hasLabel('person').limit(2).
|
In this case, there is no way to know the total count so the only way to know if the end of the results have been
reached is to count the results from each paged result to see if there’s less than the number expected or simply zero
results. In that case, further requests for additional pages would be unnecessary. Of course, this approach is not
free of problems either. Most graph databases will not optimize the range()-step, meaning that the second traversal
will repeat the iteration of the first two vertices to get to the second set of two vertices. In other words, for the
second traversal, the graph will still read four vertices even though there was only a request for two.
The only way to completely avoid that problem is to re-use the same traversal instance:
gremlin> t = g.V().hasLabel('person');[]
gremlin> t.next(2)
==>v[1]
==>v[2]
gremlin> t.next(2)
==>v[4]
==>v[6]t = g.V().hasLabel('person');[]
t.next(2)
t.next(2)A further consideration relates to the order in which results are returned. TinkerPop does not guarantee that the order of the items returned on the same traversal will be the same order each time the traversal is iterated. TinkerPop only guarantees that it does not re-shuffle the order provided by the underlying graph database. This guarantee has two implications:
-
Iteration order is dependent on the underlying graph database. Some graphs may guarantee ordering and some may not and still some others may guarantee ordering but only under certain conditions. Consult the documentation of the graph database for more information on this.
-
Use
order()-step to make iteration order explicit if guarantees are required.
Recommendation
 One of the more common use cases for a graph database is the
development of recommendation systems and a simple approach to
doing that is through collaborative filtering.
Collaborative filtering assumes that if a person shares one set of opinions with a different person, they are likely to
have similar taste with respect to other issues. With that basis in mind, it is then possible to make predictions for a
specific person as to what their opinions might be.
One of the more common use cases for a graph database is the
development of recommendation systems and a simple approach to
doing that is through collaborative filtering.
Collaborative filtering assumes that if a person shares one set of opinions with a different person, they are likely to
have similar taste with respect to other issues. With that basis in mind, it is then possible to make predictions for a
specific person as to what their opinions might be.
As a simple example, consider a graph that contains "person" and "product" vertices connected by "bought" edges. The following script generates some data for the graph using that basic schema:
gremlin> g.addV("person").property("name","alice").
addV("person").property("name","bob").
addV("person").property("name","jon").
addV("person").property("name","jack").
addV("person").property("name","jill")iterate()
gremlin> (1..10).each {
g.addV("product").property("name","product #${it}").iterate()
}; []
gremlin> (3..7).each {
g.V().has("person","name","alice").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
gremlin> (1..5).each {
g.V().has("person","name","bob").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
gremlin> (6..10).each {
g.V().has("person","name","jon").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
gremlin> 1.step(10, 2) {
g.V().has("person","name","jack").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
gremlin> 2.step(10, 2) {
g.V().has("person","name","jill").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []g.addV("person").property("name","alice").
addV("person").property("name","bob").
addV("person").property("name","jon").
addV("person").property("name","jack").
addV("person").property("name","jill")iterate()
(1..10).each {
g.addV("product").property("name","product #${it}").iterate()
}; []
(3..7).each {
g.V().has("person","name","alice").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
(1..5).each {
g.V().has("person","name","bob").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
(6..10).each {
g.V().has("person","name","jon").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
1.step(10, 2) {
g.V().has("person","name","jack").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []
2.step(10, 2) {
g.V().has("person","name","jill").as("p").
V().has("product","name","product #${it}").addE("bought").from("p").iterate()
}; []The first step to making a recommendation to "alice" using collaborative filtering is to understand what she bought:
gremlin> g.V().has('name','alice').out('bought').values('name')
==>product #5
==>product #6
==>product #7
==>product #3
==>product #4g.V().has('name','alice').out('bought').values('name')The following diagram depicts one of the edges traversed in the above example between "alice" and "product #5". Obviously, the other products "alice" bought would have similar relations, but this diagram and those to follow will focus on the neighborhood around that product.
The next step is to determine who else purchased those products:
gremlin> g.V().has('name','alice').out('bought').in('bought').dedup().values('name')
==>alice
==>bob
==>jack
==>jill
==>jong.V().has('name','alice').out('bought').in('bought').dedup().values('name')It is worth noting that "alice" is in the results above. She should really be excluded from the list as the interest is in what individuals other than herself purchased:
gremlin> g.V().has('name','alice').as('her').
out('bought').
in('bought').where(neq('her')).
dedup().values('name')
==>bob
==>jack
==>jill
==>jong.V().has('name','alice').as('her').
out('bought').
in('bought').where(neq('her')).
dedup().values('name')The following diagram shows "alice" and those others who purchased "product #5".
The knowledge of the people who bought the same things as "alice" can then be used to find the set of products that they bought:
gremlin> g.V().has('name','alice').as('her').
out('bought').
in('bought').where(neq('her')).
out('bought').
dedup().values('name')
==>product #1
==>product #2
==>product #3
==>product #4
==>product #5
==>product #7
==>product #9
==>product #6
==>product #8
==>product #10g.V().has('name','alice').as('her').
out('bought').
in('bought').where(neq('her')).
out('bought').
dedup().values('name')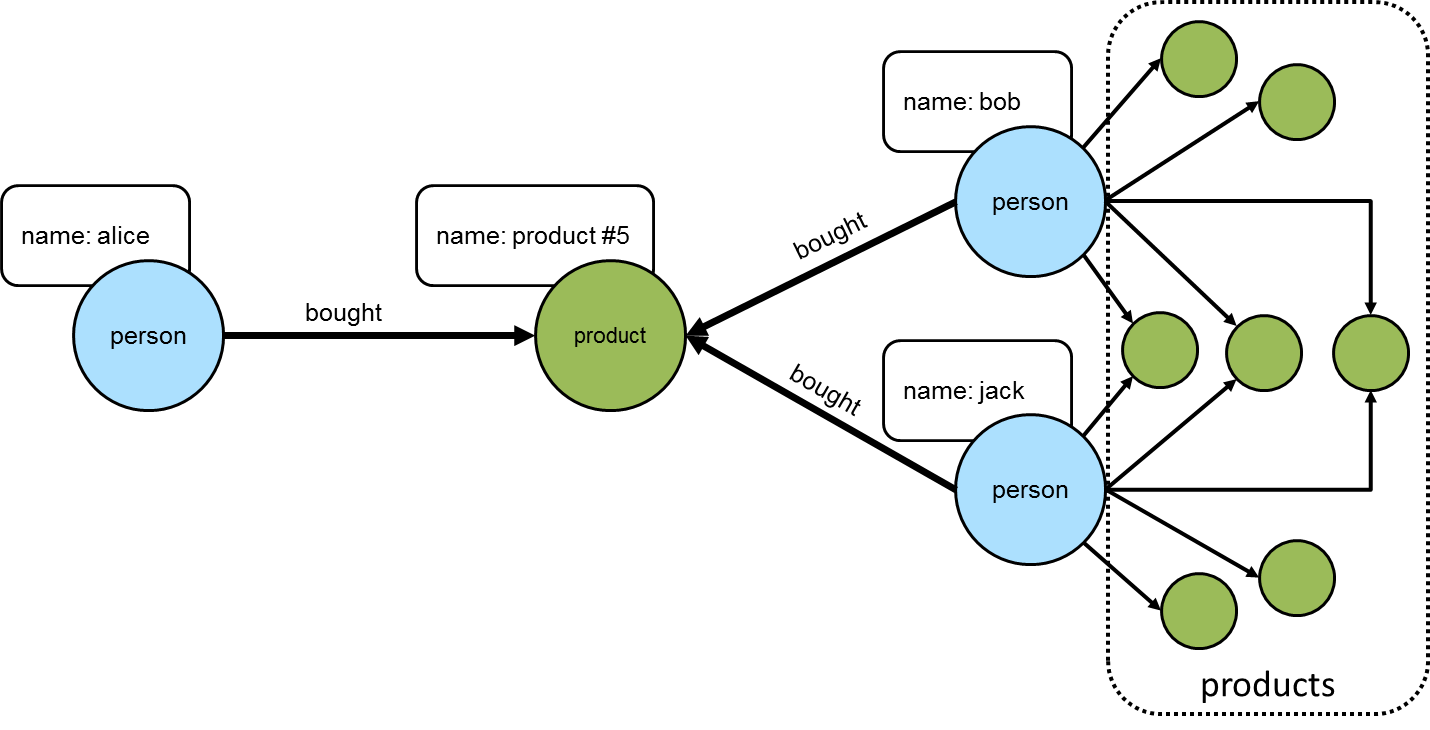
This set of products could be the basis for recommendation, but it is important to remember that "alice" may have already purchased some of these products and it would be better to not pester her with recommendations for products that she already owns. Those products she already purchased can be excluded as follows:
gremlin> g.V().has('name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).
dedup().values('name')
==>product #1
==>product #2
==>product #9
==>product #8
==>product #10g.V().has('name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).
dedup().values('name')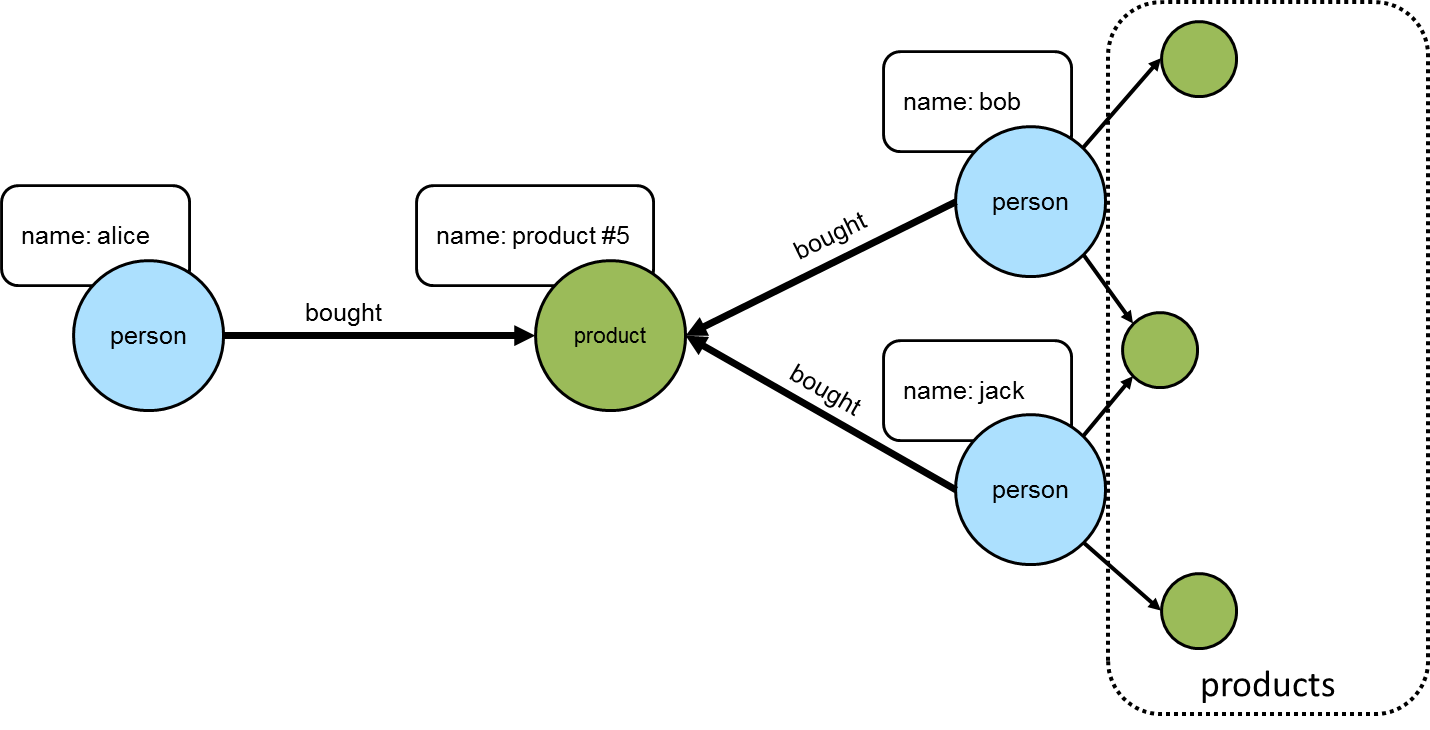
The final step would be to group the remaining products (instead of dedup() which was mostly done for demonstration
purposes) to form a ranking:
gremlin> g.V().has('person','name','alice').as('her'). //1\
out('bought').aggregate('self'). //2\
in('bought').where(neq('her')). //3\
out('bought').where(without('self')). //4\
groupCount().
order(local).
by(values, desc) //5\
==>[v[10]:6,v[26]:5,v[12]:5,v[24]:4,v[28]:2]g.V().has('person','name','alice').as('her'). //1\
out('bought').aggregate('self'). //2\
in('bought').where(neq('her')). //3\
out('bought').where(without('self')). //4\
groupCount().
order(local).
by(values, desc) //5-
Find "alice" who is the person for whom the product recommendation is being made.
-
Traverse to the products that "alice" bought and gather them for later use in the traversal.
-
Traverse to the "person" vertices who bought the products that "alice" bought and exclude "alice" herself from that list.
-
Given those people who bought similar products to "alice", find the products that they bought and exclude those that she already bought.
-
Group the products and count the number of times they were purchased by others to come up with a ranking of products to recommend to "alice".
The previous example was already described as "basic" and obviously could take into account whatever data is available to further improve the quality of the recommendation (e.g. product ratings, times of purchase, etc.). One option to improve the quality of what is recommended (without expanding the previous dataset) might be to choose the person vertices that make up the recommendation to "alice" who have the largest common set of purchases.
Looking back to the previous code example, consider its more strip down representation that shows those individuals who have at least one product in common:
gremlin> g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup()
==>v[2]
==>v[6]
==>v[8]
==>v[4]g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup()Next, do some grouping to find count how many products they have in common:
gremlin> g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count())
==>[v[2]:3,v[4]:2,v[6]:3,v[8]:2]g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count())The above output shows that the best that can be expected is three common products. The traversal needs to be aware of that maximum:
gremlin> g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).
select(values).
order(local).
by(desc).limit(local, 1)
==>3g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).
select(values).
order(local).
by(desc).limit(local, 1)With the maximum value available, it can be used to chose those "person" vertices that have the three products in common:
gremlin> g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).as("g").
select(values).
order(local).
by(desc).limit(local, 1).as("m").
select("g").unfold().
where(select(values).as("m")).select(keys)
==>v[2]
==>v[6]g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).as("g").
select(values).
order(local).
by(desc).limit(local, 1).as("m").
select("g").unfold().
where(select(values).as("m")).select(keys)Now that there is a list of "person" vertices to base the recommendation on, traverse to the products that they purchased:
gremlin> g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).as("g").
select(values).
order(local).
by(desc).limit(local, 1).as("m").
select("g").unfold().
where(select(values).as("m")).select(keys).
out("bought").where(without("self"))
==>v[10]
==>v[12]
==>v[26]
==>v[10]g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).as("g").
select(values).
order(local).
by(desc).limit(local, 1).as("m").
select("g").unfold().
where(select(values).as("m")).select(keys).
out("bought").where(without("self"))The above output shows that one product is held in common making it the top recommendation:
gremlin> g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).as("g").
select(values).
order(local).
by(desc).limit(local, 1).as("m").
select("g").unfold().
where(select(values).as("m")).select(keys).
out("bought").where(without("self")).
groupCount().
order(local).
by(values, desc).
by(select(keys).values("name")).
unfold().select(keys).values("name")
==>product #1
==>product #2
==>product #9g.V().has("person","name","alice").as("alice").
out("bought").aggregate("self").
in("bought").where(neq("alice")).dedup().
group().
by().by(out("bought").
where(within("self")).count()).as("g").
select(values).
order(local).
by(desc).limit(local, 1).as("m").
select("g").unfold().
where(select(values).as("m")).select(keys).
out("bought").where(without("self")).
groupCount().
order(local).
by(values, desc).
by(select(keys).values("name")).
unfold().select(keys).values("name")In considering the practical applications of this recipe, it is worth revisiting the earlier "basic" version of the recommendation algorithm:
gremlin> g.V().has('person','name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).
groupCount().
order(local).
by(values, desc)
==>[v[10]:6,v[26]:5,v[12]:5,v[24]:4,v[28]:2]g.V().has('person','name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).
groupCount().
order(local).
by(values, desc)The above traversal performs a full ranking of items based on all the connected data. That could be a time consuming operation depending on the number of paths being traversed. As it turns out, recommendations don’t need to have perfect knowledge of all data to provide a "pretty good" approximation of a recommendation. It can therefore make sense to place additional limits on the traversal to have it better return more quickly at the expense of examining less data.
Gremlin provides a number of steps that can help with these limits like: coin(), sample(), and timeLimit(). For example, to have the traversal sample the data for no longer than one second, the previous "basic" recommendation could be changed to:
gremlin> g.V().has('person','name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).timeLimit(1000).
groupCount().
order(local).
by(values, desc)
==>[v[10]:6,v[26]:5,v[12]:5,v[24]:4,v[28]:2]g.V().has('person','name','alice').as('her').
out('bought').aggregate('self').
in('bought').where(neq('her')).
out('bought').where(without('self')).timeLimit(1000).
groupCount().
order(local).
by(values, desc)In using sampling methods, it is important to consider that the natural ordering of edges in the graph may not produce an ideal sample for the recommendation. For example, if the edges end up being returned oldest first, then the recommendation will be based on the oldest data, which would not be ideal. As with any traversal, it is important to understand the nature of the graph being traversed and the behavior of the underlying graph database to properly achieve the desired outcome.
Shortest Path
When working with a graph, it is often necessary to identify the shortest path between two identified vertices. The following is a simple example that identifies the shortest path between vertex "1" and vertex "5" while traversing over out edges:
gremlin> g.addV().property(id, 1).as('1').
addV().property(id, 2).as('2').
addV().property(id, 3).as('3').
addV().property(id, 4).as('4').
addV().property(id, 5).as('5').
addE('knows').from('1').to('2').
addE('knows').from('2').to('4').
addE('knows').from('4').to('5').
addE('knows').from('2').to('3').
addE('knows').from('3').to('4').iterate()
gremlin> g.V(1).repeat(out().simplePath()).until(hasId(5)).path().limit(1) //1\
==>[v[1],v[2],v[4],v[5]]
gremlin> g.V(1).repeat(out().simplePath()).until(hasId(5)).path().count(local) //2\
==>4
==>5
gremlin> g.V(1).repeat(out().simplePath()).until(hasId(5)).path().
group().by(count(local)).next() //3\
==>4=[path[v[1], v[2], v[4], v[5]]]
==>5=[path[v[1], v[2], v[3], v[4], v[5]]]g.addV().property(id, 1).as('1').
addV().property(id, 2).as('2').
addV().property(id, 3).as('3').
addV().property(id, 4).as('4').
addV().property(id, 5).as('5').
addE('knows').from('1').to('2').
addE('knows').from('2').to('4').
addE('knows').from('4').to('5').
addE('knows').from('2').to('3').
addE('knows').from('3').to('4').iterate()
g.V(1).repeat(out().simplePath()).until(hasId(5)).path().limit(1) //1\
g.V(1).repeat(out().simplePath()).until(hasId(5)).path().count(local) //2\
g.V(1).repeat(out().simplePath()).until(hasId(5)).path().
group().by(count(local)).next() //3-
The traversal starts at vertex with the identifier of "1" and repeatedly traverses on out edges "until" it finds a vertex with an identifier of "5". The inclusion of
simplePathwithin therepeatis present to filter out repeated paths. The traversal terminates withlimitin this case as the first path returned will be the shortest one. Of course, it is possible for there to be more than one path in the graph of the same length (i.e. two or more paths of length three), but this example is not considering that. -
It might be interesting to know the path lengths for all paths between vertex "1" and "5".
-
Alternatively, one might wish to do a path length distribution over all the paths.
The following code block demonstrates how the shortest path from v[1] to v[5] can be queried in OLAP, using the shortestPath() step.
gremlin> g = g.withComputer()
==>graphtraversalsource[tinkergraph[vertices:5 edges:5], graphcomputer]
gremlin> g.V(1).shortestPath().
with(ShortestPath.edges, Direction.OUT).
with(ShortestPath.target, hasId(5))
==>[v[1],v[2],v[4],v[5]]g = g.withComputer()
g.V(1).shortestPath().
with(ShortestPath.edges, Direction.OUT).
with(ShortestPath.target, hasId(5))The previous example defines the length of the path by the number of vertices in the path, but the "path" might also be measured by data within the graph itself. The following example use the same graph structure as the previous example, but includes a "weight" on the edges, that will be used to help determine the "cost" of a particular path:
gremlin> g.addV().property(id, 1).as('1').
addV().property(id, 2).as('2').
addV().property(id, 3).as('3').
addV().property(id, 4).as('4').
addV().property(id, 5).as('5').
addE('knows').from('1').to('2').property('weight', 1.25).
addE('knows').from('2').to('4').property('weight', 1.5).
addE('knows').from('4').to('5').property('weight', 0.25).
addE('knows').from('2').to('3').property('weight', 0.25).
addE('knows').from('3').to('4').property('weight', 0.25).iterate()
gremlin> g.V(1).repeat(out().simplePath()).until(hasId(5)).path().
group().by(count(local)).next() //1\
==>4=[path[v[1], v[2], v[4], v[5]]]
==>5=[path[v[1], v[2], v[3], v[4], v[5]]]
gremlin> g.V(1).repeat(outE().inV().simplePath()).until(hasId(5)).
path().by(coalesce(values('weight'),
constant(0.0))).
map(unfold().sum()) //2\
==>3.00
==>2.00
gremlin> g.V(1).repeat(outE().inV().simplePath()).until(hasId(5)).
path().by(constant(0.0)).by('weight').map(unfold().sum()) //3\
==>3.00
==>2.00
gremlin> g.V(1).repeat(outE().inV().simplePath()).until(hasId(5)).
path().as('p').
map(unfold().coalesce(values('weight'),
constant(0.0)).sum()).as('cost').
select('cost','p') //4\
==>[cost:3.00,p:[v[1],e[0][1-knows->2],v[2],e[1][2-knows->4],v[4],e[2][4-knows->5],v[5]]]
==>[cost:2.00,p:[v[1],e[0][1-knows->2],v[2],e[3][2-knows->3],v[3],e[4][3-knows->4],v[4],e[2][4-knows->5],v[5]]]g.addV().property(id, 1).as('1').
addV().property(id, 2).as('2').
addV().property(id, 3).as('3').
addV().property(id, 4).as('4').
addV().property(id, 5).as('5').
addE('knows').from('1').to('2').property('weight', 1.25).
addE('knows').from('2').to('4').property('weight', 1.5).
addE('knows').from('4').to('5').property('weight', 0.25).
addE('knows').from('2').to('3').property('weight', 0.25).
addE('knows').from('3').to('4').property('weight', 0.25).iterate()
g.V(1).repeat(out().simplePath()).until(hasId(5)).path().
group().by(count(local)).next() //1\
g.V(1).repeat(outE().inV().simplePath()).until(hasId(5)).
path().by(coalesce(values('weight'),
constant(0.0))).
map(unfold().sum()) //2\
g.V(1).repeat(outE().inV().simplePath()).until(hasId(5)).
path().by(constant(0.0)).by('weight').map(unfold().sum()) //3\
g.V(1).repeat(outE().inV().simplePath()).until(hasId(5)).
path().as('p').
map(unfold().coalesce(values('weight'),
constant(0.0)).sum()).as('cost').
select('cost','p') //4-
Note that the shortest path as determined by the structure of the graph is the same.
-
Calculate the "cost" of the path as determined by the weight on the edges. As the "weight" data is on the edges between the vertices, it is necessary to change the contents of the
repeatstep to useoutE().inV()so that the edge is included in the path. The path is then post-processed with abymodulator that extracts the "weight" value. The traversal usescoalesceas there is a mixture of vertices and edges in the path and the traversal is only interested in edge elements that can return a "weight" property. The final part of the traversal executes a map function over each path, unfolding it and summing the weights. -
The same traversal as the one above it, but avoids the use of
coalescewith the use of twobymodulators. Thebymodulator is applied in a round-robin fashion, so the firstbywill always apply to a vertex (as it is the first item in every path) and the secondbywill always apply to an edge (as it always follows the vertex in the path). -
The output of the previous examples of the "cost" wasn’t terribly useful as it didn’t include which path had the calculated cost. With some slight modifications given the use of
selectit becomes possible to include the path in the output. Note that the path with the lowest "cost" actually has a longer path length as determined by the graph structure.
The next code block demonstrates how the shortestPath() step can be used in OLAP to determine the shortest weighted path.
gremlin> g = g.withComputer()
==>graphtraversalsource[tinkergraph[vertices:5 edges:5], graphcomputer]
gremlin> g.V(1).shortestPath().
with(ShortestPath.edges, Direction.OUT).
with(ShortestPath.distance, 'weight').
with(ShortestPath.target, hasId(5))
==>[v[1],v[2],v[3],v[4],v[5]]g = g.withComputer()
g.V(1).shortestPath().
with(ShortestPath.edges, Direction.OUT).
with(ShortestPath.distance, 'weight').
with(ShortestPath.target, hasId(5))The following query illustrates how select(<traversal>) can be used to find all shortest weighted undirected paths
in the modern toy graph.
gremlin> g.withSack(0.0).V().as("from"). //1\
repeat(bothE().
sack(sum).
by("weight").
otherV(). //2\
where(neq("from")).as("to"). //3\
group("m"). //4\
by(select("from","to")).
by(sack().min()).
filter(project("s","x"). //5\
by(sack()).
by(select("m").select(select("from","to"))).
where("s", eq("x"))).
group("p"). //6\
by(select("from", "to")).
by(map(union(path().by("name").by("weight"),
sack()).fold())).
barrier()).
cap("p").unfold().
order(). //7\
by(select(keys).select("from").id()).
by(select(keys).select("to").id()).
barrier().
dedup(). //8\
by(select(keys).select(values).order(local).by(id))
==>{from=v[1], to=v[2]}=[path[marko, 0.5, vadas], 0.5]
==>{from=v[1], to=v[3]}=[path[marko, 0.4, lop], 0.4]
==>{from=v[1], to=v[4]}=[path[marko, 0.4, lop, 0.4, josh], 0.8]
==>{from=v[1], to=v[5]}=[path[marko, 0.4, lop, 0.4, josh, 1.0, ripple], 1.8]
==>{from=v[1], to=v[6]}=[path[marko, 0.4, lop, 0.2, peter], 0.6]
==>{from=v[2], to=v[3]}=[path[vadas, 0.5, marko, 0.4, lop], 0.9]
==>{from=v[2], to=v[4]}=[path[vadas, 0.5, marko, 0.4, lop, 0.4, josh], 1.3]
==>{from=v[2], to=v[5]}=[path[vadas, 0.5, marko, 0.4, lop, 0.4, josh, 1.0, ripple], 2.3]
==>{from=v[2], to=v[6]}=[path[vadas, 0.5, marko, 0.4, lop, 0.2, peter], 1.1]
==>{from=v[3], to=v[4]}=[path[lop, 0.4, josh], 0.4]
==>{from=v[3], to=v[5]}=[path[lop, 0.4, josh, 1.0, ripple], 1.4]
==>{from=v[3], to=v[6]}=[path[lop, 0.2, peter], 0.2]
==>{from=v[4], to=v[5]}=[path[josh, 1.0, ripple], 1.0]
==>{from=v[4], to=v[6]}=[path[josh, 0.4, lop, 0.2, peter], 0.6]
==>{from=v[5], to=v[6]}=[path[ripple, 1.0, josh, 0.4, lop, 0.2, peter], 1.6]g.withSack(0.0).V().as("from"). //1\
repeat(bothE().
sack(sum).
by("weight").
otherV(). //2\
where(neq("from")).as("to"). //3\
group("m"). //4\
by(select("from","to")).
by(sack().min()).
filter(project("s","x"). //5\
by(sack()).
by(select("m").select(select("from","to"))).
where("s", eq("x"))).
group("p"). //6\
by(select("from", "to")).
by(map(union(path().by("name").by("weight"),
sack()).fold())).
barrier()).
cap("p").unfold().
order(). //7\
by(select(keys).select("from").id()).
by(select(keys).select("to").id()).
barrier().
dedup(). //8\
by(select(keys).select(values).order(local).by(id))-
Start the traversal from all vertices with an initial sack value of 0.
-
Traverse into all directions and sum up the edge weight values.
-
Filter out the initial start vertex.
-
For the current start and end vertex, update the minimum sack value (weighted length of the path).
-
Compare the current weighted path length to the current minimum weighted path length between the 2 vertices. Eliminate traversers that found a path that is longer than the current shortest path.
-
Update the path and weighted path length for the current start and end vertex pair.
-
Order the output by the start vertex id and then the end vertex id (for better readability).
-
Deduplicate vertex pairs (the shortest path from
v[1]tov[6]is the same as the path fromv[6]tov[1]).
Again, this can be translated into an OLAP query using the shortestPath() step.
gremlin> result = g.withComputer().V().
shortestPath().
with(ShortestPath.distance, 'weight').
with(ShortestPath.includeEdges, true).
filter(count(local).is(gt(1))).
group().
by(project('from','to').
by(limit(local, 1)).
by(tail(local, 1))).
unfold().
order().
by(select(keys).select('from').id()).
by(select(keys).select('to').id()).toList()
==>{from=v[1], to=v[2]}=[path[v[1], e[7][1-knows->2], v[2]]]
==>{from=v[1], to=v[3]}=[path[v[1], e[9][1-created->3], v[3]]]
==>{from=v[1], to=v[4]}=[path[v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4]]]
==>{from=v[1], to=v[5]}=[path[v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4], e[10][4-created->5], v[5]]]
==>{from=v[1], to=v[6]}=[path[v[1], e[9][1-created->3], v[3], e[12][6-created->3], v[6]]]
==>{from=v[2], to=v[1]}=[path[v[2], e[7][1-knows->2], v[1]]]
==>{from=v[2], to=v[3]}=[path[v[2], e[7][1-knows->2], v[1], e[9][1-created->3], v[3]]]
==>{from=v[2], to=v[4]}=[path[v[2], e[7][1-knows->2], v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4]]]
==>{from=v[2], to=v[5]}=[path[v[2], e[7][1-knows->2], v[1], e[9][1-created->3], v[3], e[11][4-created->3], v[4], e[10][4-created->5], v[5]]]
==>{from=v[2], to=v[6]}=[path[v[2], e[7][1-knows->2], v[1], e[9][1-created->3], v[3], e[12][6-created->3], v[6]]]
==>{from=v[3], to=v[1]}=[path[v[3], e[9][1-created->3], v[1]]]
==>{from=v[3], to=v[2]}=[path[v[3], e[9][1-created->3], v[1], e[7][1-knows->2], v[2]]]
==>{from=v[3], to=v[4]}=[path[v[3], e[11][4-created->3], v[4]]]
==>{from=v[3], to=v[5]}=[path[v[3], e[11][4-created->3], v[4], e[10][4-created->5], v[5]]]
==>{from=v[3], to=v[6]}=[path[v[3], e[12][6-created->3], v[6]]]
==>{from=v[4], to=v[1]}=[path[v[4], e[11][4-created->3], v[3], e[9][1-created->3], v[1]]]
==>{from=v[4], to=v[2]}=[path[v[4], e[11][4-created->3], v[3], e[9][1-created->3], v[1], e[7][1-knows->2], v[2]]]
==>{from=v[4], to=v[3]}=[path[v[4], e[11][4-created->3], v[3]]]
==>{from=v[4], to=v[5]}=[path[v[4], e[10][4-created->5], v[5]]]
==>{from=v[4], to=v[6]}=[path[v[4], e[11][4-created->3], v[3], e[12][6-created->3], v[6]]]
==>{from=v[5], to=v[1]}=[path[v[5], e[10][4-created->5], v[4], e[11][4-created->3], v[3], e[9][1-created->3], v[1]]]
==>{from=v[5], to=v[2]}=[path[v[5], e[10][4-created->5], v[4], e[11][4-created->3], v[3], e[9][1-created->3], v[1], e[7][1-knows->2], v[2]]]
==>{from=v[5], to=v[3]}=[path[v[5], e[10][4-created->5], v[4], e[11][4-created->3], v[3]]]
==>{from=v[5], to=v[4]}=[path[v[5], e[10][4-created->5], v[4]]]
==>{from=v[5], to=v[6]}=[path[v[5], e[10][4-created->5], v[4], e[11][4-created->3], v[3], e[12][6-created->3], v[6]]]
==>{from=v[6], to=v[1]}=[path[v[6], e[12][6-created->3], v[3], e[9][1-created->3], v[1]]]
==>{from=v[6], to=v[2]}=[path[v[6], e[12][6-created->3], v[3], e[9][1-created->3], v[1], e[7][1-knows->2], v[2]]]
==>{from=v[6], to=v[3]}=[path[v[6], e[12][6-created->3], v[3]]]
==>{from=v[6], to=v[4]}=[path[v[6], e[12][6-created->3], v[3], e[11][4-created->3], v[4]]]
==>{from=v[6], to=v[5]}=[path[v[6], e[12][6-created->3], v[3], e[11][4-created->3], v[4], e[10][4-created->5], v[5]]]result = g.withComputer().V().
shortestPath().
with(ShortestPath.distance, 'weight').
with(ShortestPath.includeEdges, true).
filter(count(local).is(gt(1))).
group().
by(project('from','to').
by(limit(local, 1)).
by(tail(local, 1))).
unfold().
order().
by(select(keys).select('from').id()).
by(select(keys).select('to').id()).toList()The obvious difference in the result is the absence of property values in the OLAP result. Since OLAP traversers are not
allowed to leave the local star graph, it’s not possible to have the exact same result in an OLAP query. However, the determined
shortest paths can be passed back into the OLTP GraphTraversalSource, which can then be used to query the values.
gremlin> g.withSideEffect('v', []). //1\
inject(result.toArray()).as('kv').select(values).
unfold().
map(unfold().as('v_or_e').
coalesce(V().where(eq('v_or_e')).store('v'),
select('v').tail(local, 1).bothE().where(eq('v_or_e'))).
values('name','weight').
fold()).
group().
by(select('kv').select(keys)).unfold().
order().
by(select(keys).select('from').id()).
by(select(keys).select('to').id()).toList()
==>{from=v[1], to=v[2]}=[[marko, 0.5, vadas]]
==>{from=v[1], to=v[3]}=[[marko, 0.4, lop]]
==>{from=v[1], to=v[4]}=[[marko, 0.4, lop, 0.4, josh]]
==>{from=v[1], to=v[5]}=[[marko, 0.4, lop, 0.4, josh, 1.0, ripple]]
==>{from=v[1], to=v[6]}=[[marko, 0.4, lop, 0.2, peter]]
==>{from=v[2], to=v[1]}=[[vadas, 0.5, marko]]
==>{from=v[2], to=v[3]}=[[vadas, 0.5, marko, 0.4, lop]]
==>{from=v[2], to=v[4]}=[[vadas, 0.5, marko, 0.4, lop, 0.4, josh]]
==>{from=v[2], to=v[5]}=[[vadas, 0.5, marko, 0.4, lop, 0.4, josh, 1.0, ripple]]
==>{from=v[2], to=v[6]}=[[vadas, 0.5, marko, 0.4, lop, 0.2, peter]]
==>{from=v[3], to=v[1]}=[[lop, 0.4, marko]]
==>{from=v[3], to=v[2]}=[[lop, 0.4, marko, 0.5, vadas]]
==>{from=v[3], to=v[4]}=[[lop, 0.4, josh]]
==>{from=v[3], to=v[5]}=[[lop, 0.4, josh, 1.0, ripple]]
==>{from=v[3], to=v[6]}=[[lop, 0.2, peter]]
==>{from=v[4], to=v[1]}=[[josh, 0.4, lop, 0.4, marko]]
==>{from=v[4], to=v[2]}=[[josh, 0.4, lop, 0.4, marko, 0.5, vadas]]
==>{from=v[4], to=v[3]}=[[josh, 0.4, lop]]
==>{from=v[4], to=v[5]}=[[josh, 1.0, ripple]]
==>{from=v[4], to=v[6]}=[[josh, 0.4, lop, 0.2, peter]]
==>{from=v[5], to=v[1]}=[[ripple, 1.0, josh, 0.4, lop, 0.4, marko]]
==>{from=v[5], to=v[2]}=[[ripple, 1.0, josh, 0.4, lop, 0.4, marko, 0.5, vadas]]
==>{from=v[5], to=v[3]}=[[ripple, 1.0, josh, 0.4, lop]]
==>{from=v[5], to=v[4]}=[[ripple, 1.0, josh]]
==>{from=v[5], to=v[6]}=[[ripple, 1.0, josh, 0.4, lop, 0.2, peter]]
==>{from=v[6], to=v[1]}=[[peter, 0.2, lop, 0.4, marko]]
==>{from=v[6], to=v[2]}=[[peter, 0.2, lop, 0.4, marko, 0.5, vadas]]
==>{from=v[6], to=v[3]}=[[peter, 0.2, lop]]
==>{from=v[6], to=v[4]}=[[peter, 0.2, lop, 0.4, josh]]
==>{from=v[6], to=v[5]}=[[peter, 0.2, lop, 0.4, josh, 1.0, ripple]]g.withSideEffect('v', []). //1\
inject(result.toArray()).as('kv').select(values).
unfold().
map(unfold().as('v_or_e').
coalesce(V().where(eq('v_or_e')).store('v'),
select('v').tail(local, 1).bothE().where(eq('v_or_e'))).
values('name','weight').
fold()).
group().
by(select('kv').select(keys)).unfold().
order().
by(select(keys).select('from').id()).
by(select(keys).select('to').id()).toList()-
The side-effect
vis used to keep track of the last processed vertex, hence it needs to be an order-preserving list. Without this explicit definitionvwould become aBulkSetwhich doesn’t preserve the insert order.
Traversal Induced Values
The parameters of a Traversal can be known ahead of time as constants or might otherwise be passed in as dynamic
arguments.
gremlin> g.V().has('name','marko').out('knows').has('age', gt(29)).values('name')
==>joshg.V().has('name','marko').out('knows').has('age', gt(29)).values('name')In plain language, the above Gremlin asks, "What are the names of the people who Marko knows who are over the age of 29?". In this case, "29" is known as a constant to the traversal. Of course, if the question is changed slightly to instead ask, "What are the names of the people who Marko knows who are older than he is?", the hardcoding of "29" will no longer suffice. There are multiple ways Gremlin would allow this second question to be answered. The first is obvious to any programmer - use a variable:
gremlin> marko = g.V().has('name','marko').next()
==>v[1]
gremlin> g.V(marko).out('knows').has('age', gt(marko.value('age'))).values('name')
==>joshmarko = g.V().has('name','marko').next()
g.V(marko).out('knows').has('age', gt(marko.value('age'))).values('name')The downside to this approach is that it takes two separate traversals to answer the question. Ideally, there should
be a single traversal, that can query "marko" once, determine his age and then use that for the value supplied to
filter the people he knows. In this way the value for the age in the has()-filter is induced from the Traversal
itself.
gremlin> g.V().has('name','marko').as('marko'). //1\
out('knows').as('friend'). //2\
where('friend', gt('marko')).by('age'). //3\
values('name') //4\
==>joshg.V().has('name','marko').as('marko'). //1\
out('knows').as('friend'). //2\
where('friend', gt('marko')).by('age'). //3\
values('name') //4-
Find the "marko"
Vertexand label it as "marko". -
Traverse out on the "knows" edges to the adjacent
Vertexand label it as "friend". -
Continue to traverser only if Marko’s current friend is older than him.
-
Get the name of Marko’s older friend.
As another example of how traversal induced values can be used, consider a scenario where there was a graph that contained people, their friendship relationships, and the movies that they liked.
gremlin> g.addV("user").property("name", "alice").as("u1").
addV("user").property("name", "jen").as("u2").
addV("user").property("name", "dave").as("u3").
addV("movie").property("name", "the wild bunch").as("m1").
addV("movie").property("name", "young guns").as("m2").
addV("movie").property("name", "unforgiven").as("m3").
addE("friend").from("u1").to("u2").
addE("friend").from("u1").to("u3").
addE("like").from("u2").to("m1").
addE("like").from("u2").to("m2").
addE("like").from("u3").to("m2").
addE("like").from("u3").to("m3").iterate()g.addV("user").property("name", "alice").as("u1").
addV("user").property("name", "jen").as("u2").
addV("user").property("name", "dave").as("u3").
addV("movie").property("name", "the wild bunch").as("m1").
addV("movie").property("name", "young guns").as("m2").
addV("movie").property("name", "unforgiven").as("m3").
addE("friend").from("u1").to("u2").
addE("friend").from("u1").to("u3").
addE("like").from("u2").to("m1").
addE("like").from("u2").to("m2").
addE("like").from("u3").to("m2").
addE("like").from("u3").to("m3").iterate()Getting a list of all the movies that Alice’s friends like could be done like this:
gremlin> g.V().has('name','alice').out("friend").out("like").values("name")
==>the wild bunch
==>young guns
==>young guns
==>unforgiveng.V().has('name','alice').out("friend").out("like").values("name")but what if there was a need to get a list of movies that all her Alice’s friends liked. In this case, that would mean filtering out "the wild bunch" and "unforgiven".
gremlin> g.V().has("name","alice").
out("friend").aggregate("friends"). //1\
out("like").dedup(). //2\
filter(__.in("like").where(within("friends")).count().as("a"). //3\
select("friends").count(local).where(eq("a"))). //4\
values("name")
==>young gunsg.V().has("name","alice").
out("friend").aggregate("friends"). //1\
out("like").dedup(). //2\
filter(__.in("like").where(within("friends")).count().as("a"). //3\
select("friends").count(local).where(eq("a"))). //4\
values("name")-
Gather Alice’s list of friends to a list called "friends".
-
Traverse to the unique list of movies that Alice’s friends like.
-
Remove movies that weren’t liked by all friends. This starts by taking each movie and traversing back in on the "like" edges to friends who liked the movie (note the use of
where(within("friends"))to limit those likes to only Alice’s friends as aggregated in step one) and count them up into "a". -
Count the aggregated friends and see if the number matches what was stored in "a" which would mean that all friends like the movie.
Traversal induced values are not just for filtering. They can also be used when writing the values of the properties
of one Vertex to another:
gremlin> g.V().has('name', 'marko').as('marko').
out('created').property('creator', select('marko').by('name'))
==>v[3]
gremlin> g.V().has('name', 'marko').out('created').valueMap()
==>[creator:[marko],name:[lop],lang:[java]]g.V().has('name', 'marko').as('marko').
out('created').property('creator', select('marko').by('name'))
g.V().has('name', 'marko').out('created').valueMap()In a more complex example of how this might work, consider a situation where the goal is to propagate a value stored on a particular vertex through one of more additional connected vertices using some value on the connecting edges to determine the value to assign. For example, the following graph depicts three "tank" vertices where the edges represent the direction a particular "tank" should drain and the "factor" by which it should do it:
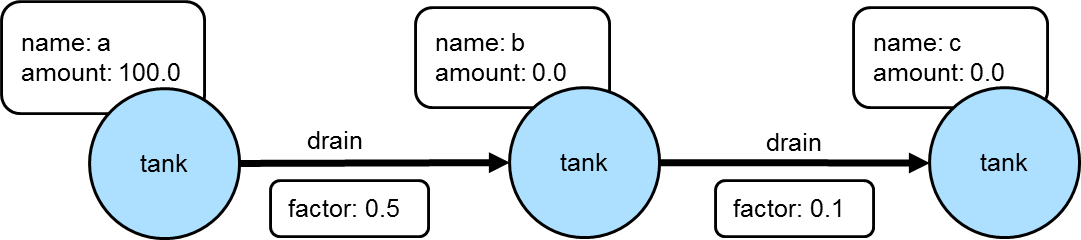
If the traversal started at tank "a", then the value of "amount" on that tank would be used to calculate what the value of tank "b" was by multiplying it by the value of the "factor" property on the edge between vertices "a" and "b". In this case the amount of tank "b" would then be 50. Following this pattern, when going from tank "b" to tank "c", the value of the "amount" of tank "c" would be 5.
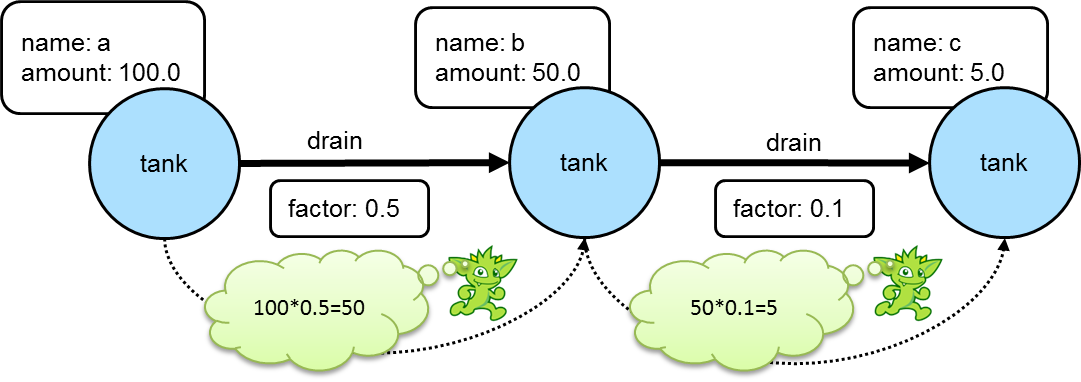
Using Gremlin sack(), this kind of operation could be specified as a single traversal:
gremlin> g.addV('tank').property('name', 'a').property('amount', 100.0).as('a').
addV('tank').property('name', 'b').property('amount', 0.0).as('b').
addV('tank').property('name', 'c').property('amount', 0.0).as('c').
addE('drain').property('factor', 0.5).from('a').to('b').
addE('drain').property('factor', 0.1).from('b').to('c').iterate()
gremlin> a = g.V().has('name','a').next()
==>v[0]
gremlin> g.withSack(a.value('amount')).
V(a).repeat(outE('drain').sack(mult).by('factor').
inV().property('amount', sack())).
until(__.outE('drain').count().is(0)).iterate()
gremlin> g.V().valueMap()
==>[amount:[100.0],name:[a]]
==>[amount:[50.00],name:[b]]
==>[amount:[5.000],name:[c]]g.addV('tank').property('name', 'a').property('amount', 100.0).as('a').
addV('tank').property('name', 'b').property('amount', 0.0).as('b').
addV('tank').property('name', 'c').property('amount', 0.0).as('c').
addE('drain').property('factor', 0.5).from('a').to('b').
addE('drain').property('factor', 0.1).from('b').to('c').iterate()
a = g.V().has('name','a').next()
g.withSack(a.value('amount')).
V(a).repeat(outE('drain').sack(mult).by('factor').
inV().property('amount', sack())).
until(__.outE('drain').count().is(0)).iterate()
g.V().valueMap()The "sack value" gets initialized to the value of tank "a". The traversal iteratively traverses out on the "drain"
edges and uses mult to multiply the sack value by the value of "factor". The sack value at that point is then
written to the "amount" of the current vertex.
As shown in the previous example, sack() is a useful way to "carry" and manipulate a value that can be later used
elsewhere in the traversal. Here is another example of its usage where it is utilized to increment all the "age" values
in the modern toy graph by 10:
gremlin> g.withSack(0).V().has("age").
sack(assign).by("age").sack(sum).by(constant(10)).
property("age", sack()).valueMap()
==>[name:[marko],age:[39]]
==>[name:[vadas],age:[37]]
==>[name:[josh],age:[42]]
==>[name:[peter],age:[45]]g.withSack(0).V().has("age").
sack(assign).by("age").sack(sum).by(constant(10)).
property("age", sack()).valueMap()In the above case, the sack is initialized to zero and as each vertex is iterated, the "age" is assigned to the sack
with sack(assign).by('age'). That value in the sack is then incremented by the value constant(10) and assigned to
the "age" property of the same vertex.
This value the sack is incremented by need not be a constant. It could also be derived from the traversal itself. Using the same example, the "weight" property on the incident edges will be used as the value to add to the sack:
gremlin> g.withSack(0).V().has("age").
sack(assign).by("age").sack(sum).by(bothE().values("weight").sum()).
property("age", sack()).valueMap()
==>[name:[marko],age:[30.9]]
==>[name:[vadas],age:[27.5]]
==>[name:[josh],age:[34.4]]
==>[name:[peter],age:[35.2]]g.withSack(0).V().has("age").
sack(assign).by("age").sack(sum).by(bothE().values("weight").sum()).
property("age", sack()).valueMap()Tree

Lowest Common Ancestor
 Given a tree, the lowest common ancestor
is the deepest vertex that is common to two or more other vertices. The diagram to the right depicts the common
ancestor tree for vertices A and D in the various green shades. The C vertex, the vertex with the darkest green
shading, is the lowest common ancestor.
Given a tree, the lowest common ancestor
is the deepest vertex that is common to two or more other vertices. The diagram to the right depicts the common
ancestor tree for vertices A and D in the various green shades. The C vertex, the vertex with the darkest green
shading, is the lowest common ancestor.
The following code simply sets up the graph depicted above using "hasParent" for the edge label:
gremlin> g.addV().property(id, 'A').as('a').
addV().property(id, 'B').as('b').
addV().property(id, 'C').as('c').
addV().property(id, 'D').as('d').
addV().property(id, 'E').as('e').
addV().property(id, 'F').as('f').
addV().property(id, 'G').as('g').
addE('hasParent').from('a').to('b').
addE('hasParent').from('b').to('c').
addE('hasParent').from('d').to('c').
addE('hasParent').from('c').to('e').
addE('hasParent').from('e').to('f').
addE('hasParent').from('g').to('f').iterate()g.addV().property(id, 'A').as('a').
addV().property(id, 'B').as('b').
addV().property(id, 'C').as('c').
addV().property(id, 'D').as('d').
addV().property(id, 'E').as('e').
addV().property(id, 'F').as('f').
addV().property(id, 'G').as('g').
addE('hasParent').from('a').to('b').
addE('hasParent').from('b').to('c').
addE('hasParent').from('d').to('c').
addE('hasParent').from('c').to('e').
addE('hasParent').from('e').to('f').
addE('hasParent').from('g').to('f').iterate()Given that graph, the following traversal will get the lowest common ancestor for two vertices, A and D:
gremlin> g.V('A').
repeat(out('hasParent')).emit().as('x').
repeat(__.in('hasParent')).emit(hasId('D')).
select('x').limit(1)
==>v[C]g.V('A').
repeat(out('hasParent')).emit().as('x').
repeat(__.in('hasParent')).emit(hasId('D')).
select('x').limit(1)The above traversal is reasonably straightforward to follow in that it simply traverses up the tree from the A vertex and then traverses down from each ancestor until it finds the "D" vertex. The first path that uncovers that match is the lowest common ancestor.
The complexity of finding the lowest common ancestor increases when trying to find the ancestors of three or more vertices.
gremlin> input = ['A','B','D']
==>A
==>B
==>D
gremlin> g.V(input.head()).
repeat(out('hasParent')).emit().as('x'). //1\
V().has(id, within(input.tail())). //2\
repeat(out('hasParent')).emit(where(eq('x'))). //3\
group().
by(select('x')).
by(path().count(local).fold()). //4\
unfold().filter(select(values).count(local).is(input.tail().size())). //5\
order().by(select(values).
unfold().sum()). //6\
select(keys).limit(1) //7\
==>v[C]input = ['A','B','D']
g.V(input.head()).
repeat(out('hasParent')).emit().as('x'). //1\
V().has(id, within(input.tail())). //2\
repeat(out('hasParent')).emit(where(eq('x'))). //3\
group().
by(select('x')).
by(path().count(local).fold()). //4\
unfold().filter(select(values).count(local).is(input.tail().size())). //5\
order().by(select(values).
unfold().sum()). //6\
select(keys).limit(1) //7-
The start of the traversal is not so different than the previous one and starts with vertex A.
-
Use a mid-traversal
V()to find the child vertices B and D. -
Traverse up the tree for B and D and find common ancestors that were labeled with "x".
-
Group on the common ancestors where the value of the grouping is the length of the path.
-
The result of the previous step is a
Mapwith a vertex (i.e. common ancestor) for the key and a list of path lengths. Unroll theMapand ensure that the number of path lengths are equivalent to the number of children that were given to the mid-traversalV(). -
Order the results based on the sum of the path lengths.
-
Since the results were placed in ascending order, the first result must be the lowest common ancestor.
As the above traversal utilizes a mid-traversal V(), it cannot be used for OLAP. In OLAP, the pattern changes a bit:
gremlin> g.withComputer().
V().has(id, within(input)).
aggregate('input').hasId(input.head()). //1\
repeat(out('hasParent')).emit().as('x').
select('input').unfold().has(id, within(input.tail())).
repeat(out('hasParent')).emit(where(eq('x'))).
group().
by(select('x')).
by(path().count(local).fold()).
unfold().filter(select(values).count(local).is(input.tail().size())).
order().
by(select(values).unfold().sum()).
select(keys).limit(1)
==>v[C]g.withComputer().
V().has(id, within(input)).
aggregate('input').hasId(input.head()). //1\
repeat(out('hasParent')).emit().as('x').
select('input').unfold().has(id, within(input.tail())).
repeat(out('hasParent')).emit(where(eq('x'))).
group().
by(select('x')).
by(path().count(local).fold()).
unfold().filter(select(values).count(local).is(input.tail().size())).
order().
by(select(values).unfold().sum()).
select(keys).limit(1)-
The main difference for OLAP is the use of
aggregate()over the mid-traversalV().
Maximum Depth
Finding the maximum depth of a tree starting from a specified root vertex can be determined as follows:
gremlin> g.addV().property('name', 'A').as('a').
addV().property('name', 'B').as('b').
addV().property('name', 'C').as('c').
addV().property('name', 'D').as('d').
addV().property('name', 'E').as('e').
addV().property('name', 'F').as('f').
addV().property('name', 'G').as('g').
addE('hasParent').from('a').to('b').
addE('hasParent').from('b').to('c').
addE('hasParent').from('d').to('c').
addE('hasParent').from('c').to('e').
addE('hasParent').from('e').to('f').
addE('hasParent').from('g').to('f').iterate()
gremlin> g.V().has('name','F').repeat(__.in()).emit().path().count(local).max()
==>5
gremlin> g.V().has('name','C').repeat(__.in()).emit().path().count(local).max()
==>3g.addV().property('name', 'A').as('a').
addV().property('name', 'B').as('b').
addV().property('name', 'C').as('c').
addV().property('name', 'D').as('d').
addV().property('name', 'E').as('e').
addV().property('name', 'F').as('f').
addV().property('name', 'G').as('g').
addE('hasParent').from('a').to('b').
addE('hasParent').from('b').to('c').
addE('hasParent').from('d').to('c').
addE('hasParent').from('c').to('e').
addE('hasParent').from('e').to('f').
addE('hasParent').from('g').to('f').iterate()
g.V().has('name','F').repeat(__.in()).emit().path().count(local).max()
g.V().has('name','C').repeat(__.in()).emit().path().count(local).max() The traversals shown above are fairly straightforward. The traversal
beings at a particular starting vertex, traverse in on the "hasParent" edges emitting all vertices as it goes. It
calculates the path length and then selects the longest one. While this approach is quite direct, there is room for
improvement:
The traversals shown above are fairly straightforward. The traversal
beings at a particular starting vertex, traverse in on the "hasParent" edges emitting all vertices as it goes. It
calculates the path length and then selects the longest one. While this approach is quite direct, there is room for
improvement:
gremlin> g.V().has('name','F').
repeat(__.in()).emit(__.not(inE())).tail(1).
path().count(local)
==>5
gremlin> g.V().has('name','C').
repeat(__.in()).emit(__.not(inE())).tail(1).
path().count(local)
==>3g.V().has('name','F').
repeat(__.in()).emit(__.not(inE())).tail(1).
path().count(local)
g.V().has('name','C').
repeat(__.in()).emit(__.not(inE())).tail(1).
path().count(local)There are two optimizations at play. First, there is no need to emit all the vertices, only the "leaf" vertices (i.e. those without incoming edges). Second, all results save the last one can be ignored to that point (i.e. the last one is the one at the deepest point in the tree). In this way, the path and path length only need to be calculated for a single result.
The previous approaches to calculating the maximum depth use path calculations to achieve the answer. Path calculations
can be expensive and if possible avoided if they are not needed. Another way to express a traversal that calculates
the maximum depth is to use the sack()-step:
gremlin> g.withSack(1).V().has('name','F').
repeat(__.in().sack(sum).by(constant(1))).emit().
sack().max()
==>5
gremlin> g.withSack(1).V().has('name','C').
repeat(__.in().sack(sum).by(constant(1))).emit().
sack().max()
==>3g.withSack(1).V().has('name','F').
repeat(__.in().sack(sum).by(constant(1))).emit().
sack().max()
g.withSack(1).V().has('name','C').
repeat(__.in().sack(sum).by(constant(1))).emit().
sack().max()Time-based Indexing
Trees can be used for modeling time-oriented data in a graph. Modeling time where there are "year", "month" and "day" vertices (or lower granularity as needed) allows the structure of the graph to inherently index data tied to them.
|
Note
|
This model is discussed further in this Neo4j blog post. Also, there can be other versions of this model that utilize different edge/vertex labeling and property naming strategies. The schema depicted here is designed for simplicity. |
The Gremlin script below creates the graph depicted in the graph above:
gremlin> g.addV('year').property('name', '2016').as('y2016').
addV('month').property('name', 'may').as('m05').
addV('month').property('name', 'june').as('m06').
addV('day').property('name', '30').as('d30').
addV('day').property('name', '31').as('d31').
addV('day').property('name', '01').as('d01').
addV('event').property('name', 'A').as('eA').
addV('event').property('name', 'B').as('eB').
addV('event').property('name', 'C').as('eC').
addV('event').property('name', 'D').as('eD').
addV('event').property('name', 'E').as('eE').
addE('may').from('y2016').to('m05').
addE('june').from('y2016').to('m06').
addE('day30').from('m05').to('d30').
addE('day31').from('m05').to('d31').
addE('day01').from('m06').to('d01').
addE('has').from('d30').to('eA').
addE('has').from('d30').to('eB').
addE('has').from('d31').to('eC').
addE('has').from('d31').to('eD').
addE('has').from('d01').to('eE').
addE('next').from('d30').to('d31').
addE('next').from('d31').to('d01').
addE('next').from('m05').to('m06').iterate()g.addV('year').property('name', '2016').as('y2016').
addV('month').property('name', 'may').as('m05').
addV('month').property('name', 'june').as('m06').
addV('day').property('name', '30').as('d30').
addV('day').property('name', '31').as('d31').
addV('day').property('name', '01').as('d01').
addV('event').property('name', 'A').as('eA').
addV('event').property('name', 'B').as('eB').
addV('event').property('name', 'C').as('eC').
addV('event').property('name', 'D').as('eD').
addV('event').property('name', 'E').as('eE').
addE('may').from('y2016').to('m05').
addE('june').from('y2016').to('m06').
addE('day30').from('m05').to('d30').
addE('day31').from('m05').to('d31').
addE('day01').from('m06').to('d01').
addE('has').from('d30').to('eA').
addE('has').from('d30').to('eB').
addE('has').from('d31').to('eC').
addE('has').from('d31').to('eD').
addE('has').from('d01').to('eE').
addE('next').from('d30').to('d31').
addE('next').from('d31').to('d01').
addE('next').from('m05').to('m06').iterate()|
Important
|
The code example above does not create any indices. Proper index creation, which is specific to the graph implementation used, will be critical to the performance of traversals over this structure. |
gremlin> g.V().has('name','2016').out().out().out('has').values() //1\
==>E
==>C
==>D
==>A
==>B
gremlin> g.V().has('name','2016').out('may').out().out('has').values() //2\
==>C
==>D
==>A
==>B
gremlin> g.V().has('name','2016').out('may').out('day31').out('has').values() //3\
==>C
==>D
gremlin> g.V().has('name','2016').out('may').out('day31').as('start').
V().has('name','2016').out('june').out('day01').as('end').
emit().repeat(__.in('next')).until(where(eq('start'))).
out('has').
order().by('name').values('name') //4\
==>C
==>D
==>Eg.V().has('name','2016').out().out().out('has').values() //1\
g.V().has('name','2016').out('may').out().out('has').values() //2\
g.V().has('name','2016').out('may').out('day31').out('has').values() //3\
g.V().has('name','2016').out('may').out('day31').as('start').
V().has('name','2016').out('june').out('day01').as('end').
emit().repeat(__.in('next')).until(where(eq('start'))).
out('has').
order().by('name').values('name') //4-
Find all the events in 2016.
-
Find all the events in May of 2016.
-
Find all the events on May 31, 2016.
-
Find all the events between May 31, 2016 and June 1, 2016.
OLAP traversals with Spark on YARN
TinkerPop’s combination of SparkGraphComputer
and HadoopGraph allows for running
distributed, analytical graph queries (OLAP) on a computer cluster. The
reference documentation covers the cases
where Spark runs locally or where the cluster is managed by a Spark server. However, many users can only run OLAP jobs
via the Hadoop 2.x Resource Manager (YARN), which requires SparkGraphComputer to be
configured differently. This recipe describes this configuration.
Approach
Most configuration problems of TinkerPop with Spark on YARN stem from three reasons:
-
SparkGraphComputercreates its ownSparkContextso it does not get any configs from the usualspark-submitcommand. -
The TinkerPop Spark plugin did not include Spark on YARN runtime dependencies until version 3.2.7/3.3.1.
-
Resolving reason 2 by adding the cluster’s Spark jars to the classpath may create all kinds of version conflicts with the TinkerPop dependencies.
The current recipe follows a minimalist approach in which no dependencies are added to the dependencies included in the TinkerPop binary distribution. The Hadoop cluster’s Spark installation is completely ignored. This approach minimizes the chance of dependency version conflicts.
Prerequisites
This recipe is suitable for both a real external and a local pseudo Hadoop cluster. While the recipe is maintained for the vanilla Hadoop pseudo-cluster, it has been reported to work on real clusters with Hadoop distributions from various vendors.
If you want to try the recipe on a local Hadoop pseudo-cluster, the easiest way to install
it is to look at the install script at https://github.com/apache/tinkerpop/blob/3.4.2/docker/hadoop/install.sh
and the start hadoop section of https://github.com/apache/tinkerpop/blob/3.4.2/docker/scripts/build.sh.
This recipe assumes that you installed the Gremlin Console with the
Spark plugin (the
Hadoop plugin is optional). Your Hadoop cluster
may have been configured to use file compression, e.g. LZO compression. If so, you need to copy the relevant
jar (e.g. hadoop-lzo-*.jar) to Gremlin Console’s ext/spark-gremlin/lib folder.
For starting the Gremlin Console in the right environment, create a shell script (e.g. bin/spark-yarn.sh) with the
contents below. Of course, actual values for GREMLIN_HOME, HADOOP_HOME and HADOOP_CONF_DIR need to be adapted to
your particular environment.
#!/bin/bash
# Variables to be adapted to the actual environment
GREMLIN_HOME=/home/yourdir/lib/apache-tinkerpop-gremlin-console-3.4.2-standalone
export HADOOP_HOME=/usr/local/lib/hadoop-2.7.2
export HADOOP_CONF_DIR=/usr/local/lib/hadoop-2.7.2/etc/hadoop
# Have TinkerPop find the hadoop cluster configs and hadoop native libraries
export CLASSPATH=$HADOOP_CONF_DIR
export JAVA_OPTIONS="-Djava.library.path=$HADOOP_HOME/lib/native:$HADOOP_HOME/lib/native/Linux-amd64-64"
# Start gremlin-console without getting the HADOOP_GREMLIN_LIBS warning
cd $GREMLIN_HOME
[ ! -e empty ] && mkdir empty
export HADOOP_GREMLIN_LIBS=$GREMLIN_HOME/empty
bin/gremlin.shRunning the job
You can now run a gremlin OLAP query with Spark on YARN:
$ hdfs dfs -put data/tinkerpop-modern.kryo .
$ . bin/spark-yarn.shgremlin> hadoop = System.getenv('HADOOP_HOME')
gremlin> hadoopConfDir = System.getenv('HADOOP_CONF_DIR')
gremlin> archive = 'spark-gremlin.zip'
==>spark-gremlin.zip
gremlin> archivePath = "/tmp/$archive"
==>/tmp/spark-gremlin.zip
gremlin> ['bash', '-c', "rm -f $archivePath; cd ext/spark-gremlin/lib && zip $archivePath *.jar"].execute().waitFor()
==>0
gremlin> conf = new PropertiesConfiguration('conf/hadoop/hadoop-gryo.properties')
==>org.apache.commons.configuration.PropertiesConfiguration@3e377967
gremlin> conf.setProperty('spark.master', 'yarn')
gremlin> conf.setProperty('spark.submit.deployMode', 'client')
gremlin> conf.setProperty('spark.yarn.archive', "$archivePath")
gremlin> conf.setProperty('spark.yarn.appMasterEnv.CLASSPATH', "./__spark_libs__/*:$hadoopConfDir")
gremlin> conf.setProperty('spark.executor.extraClassPath', "./__spark_libs__/*:$hadoopConfDir")
gremlin> conf.setProperty('spark.driver.extraLibraryPath', "$hadoop/lib/native:$hadoop/lib/native/Linux-amd64-64")
gremlin> conf.setProperty('spark.executor.extraLibraryPath', "$hadoop/lib/native:$hadoop/lib/native/Linux-amd64-64")
gremlin> conf.setProperty('gremlin.spark.persistContext', 'true')
gremlin> hdfs.copyFromLocal('data/tinkerpop-modern.kryo', 'tinkerpop-modern.kryo')
gremlin> graph = GraphFactory.open(conf)
==>hadoopgraph[gryoinputformat->gryooutputformat]
gremlin> g = graph.traversal().withComputer(SparkGraphComputer)
==>graphtraversalsource[hadoopgraph[gryoinputformat->gryooutputformat], sparkgraphcomputer]
gremlin> g.V().group().by(values('name')).by(both().count())
==>[ripple:1,peter:1,vadas:1,josh:3,lop:3,marko:3]hadoop = System.getenv('HADOOP_HOME')
hadoopConfDir = System.getenv('HADOOP_CONF_DIR')
archive = 'spark-gremlin.zip'
archivePath = "/tmp/$archive"
['bash', '-c', "rm -f $archivePath; cd ext/spark-gremlin/lib && zip $archivePath *.jar"].execute().waitFor()
conf = new PropertiesConfiguration('conf/hadoop/hadoop-gryo.properties')
conf.setProperty('spark.master', 'yarn')
conf.setProperty('spark.submit.deployMode', 'client')
conf.setProperty('spark.yarn.archive', "$archivePath")
conf.setProperty('spark.yarn.appMasterEnv.CLASSPATH', "./__spark_libs__/*:$hadoopConfDir")
conf.setProperty('spark.executor.extraClassPath', "./__spark_libs__/*:$hadoopConfDir")
conf.setProperty('spark.driver.extraLibraryPath', "$hadoop/lib/native:$hadoop/lib/native/Linux-amd64-64")
conf.setProperty('spark.executor.extraLibraryPath', "$hadoop/lib/native:$hadoop/lib/native/Linux-amd64-64")
conf.setProperty('gremlin.spark.persistContext', 'true')
hdfs.copyFromLocal('data/tinkerpop-modern.kryo', 'tinkerpop-modern.kryo')
graph = GraphFactory.open(conf)
g = graph.traversal().withComputer(SparkGraphComputer)
g.V().group().by(values('name')).by(both().count())If you run into exceptions, you will have to dig into the logs. You can do this from the command line with
yarn application -list -appStates ALL to find the applicationId, while the logs are available with
yarn logs -applicationId application_1498627870374_0008. Alternatively, you can inspect the logs via
the YARN Resource Manager UI (e.g. http://rm.your.domain:8088/cluster), provided that YARN was configured with the
yarn.log-aggregation-enable property set to true. See the Spark documentation for
additional hints.
Explanation
This recipe does not require running the bin/hadoop/init-tp-spark.sh script described in the
reference documentation and thus is also
valid for cluster users without access permissions to do so.
Rather, it exploits the spark.yarn.archive property, which points to an archive with jars on the local file
system and is loaded into the various YARN containers. As a result the spark-gremlin.zip archive becomes available
as the directory named __spark_libs__ in the YARN containers. The spark.executor.extraClassPath and
spark.yarn.appMasterEnv.CLASSPATH properties point to the jars inside this directory.
This is why they contain the ./__spark_lib__/* item. Just because a Spark executor got the archive with
jars loaded into its container, does not mean it knows how to access them.
Also the HADOOP_GREMLIN_LIBS mechanism is not used because it can not work for Spark on YARN as implemented (jars
added to the SparkContext are not available to the YARN application master).
The gremlin.spark.persistContext property is explained in the reference documentation of
SparkGraphComputer: it helps in getting
follow-up OLAP queries answered faster, because you skip the overhead for getting resources from YARN.
Additional configuration options
This recipe does most of the graph configuration in the Gremlin Console so that environment variables can be used and
the chance of configuration mistakes is minimal. Once you have your setup working, it is probably easier to make a copy
of the conf/hadoop/hadoop-gryo.properties file and put the property values specific to your environment there. This is
also the right moment to take a look at the spark-defaults.xml file of your cluster, in particular the settings for
the Spark History Service, which allows you to access logs of
finished applications via the YARN resource manager UI.
This recipe uses the Gremlin Console, but things should not be very different for your own JVM-based application,
as long as you do not use the spark-submit or spark-shell commands. You will also want to check the additional
runtime dependencies listed in the Gremlin-Plugin-Dependencies section of the manifest file in the spark-gremlin
jar.
You may not like the idea that the Hadoop and Spark jars from the TinkerPop distribution differ from the versions in
your cluster. If so, just build TinkerPop from source with the corresponding dependencies changed in the various pom.xml
files (e.g. spark-core_2.11-2.2.0-some-vendor.jar instead of spark-core_2.11-2.2.0.jar). Of course, TinkerPop will
only build for exactly matching or slightly differing artifact versions.
Anti-Patterns

Long Traversals
It can be tempting to generate long traversals, e.g. to create a set of vertices and edges based on information that resides within an application. For example, let’s consider two lists - one that contains information about persons and another that contains information about the relationship between these persons. To illustrate the problem we will create two list with a few random map entries.
gremlin> :set max-iteration 10
gremlin> rnd = new Random(123) ; x = []
gremlin> persons = (1..100).collect {["id": it, "name": "person ${it}", "age": rnd.nextInt(40) + 20]}
==>[id:1,name:person 1,age:42]
==>[id:2,name:person 2,age:30]
==>[id:3,name:person 3,age:36]
==>[id:4,name:person 4,age:49]
==>[id:5,name:person 5,age:55]
==>[id:6,name:person 6,age:37]
==>[id:7,name:person 7,age:54]
==>[id:8,name:person 8,age:57]
==>[id:9,name:person 9,age:45]
==>[id:10,name:person 10,age:33]
...
gremlin> relations = (1..500).collect {[rnd.nextInt(persons.size()), rnd.nextInt(persons.size())]}.
unique().grep {it[0] != it[1] && !x.contains(it.reverse())}.collect {
x << it
minAge = Math.min(persons[it[0]].age, persons[it[1]].age)
knowsSince = new Date().year + 1900 - rnd.nextInt(minAge)
["from": persons[it[0]].id, "to": persons[it[1]].id, "since": knowsSince]
}
==>[from:21,to:11,since:2015]
==>[from:59,to:61,since:2013]
==>[from:1,to:37,since:2011]
==>[from:83,to:45,since:2007]
==>[from:21,to:51,since:2015]
==>[from:27,to:5,since:2012]
==>[from:77,to:89,since:2016]
==>[from:16,to:44,since:2011]
==>[from:95,to:53,since:1972]
==>[from:20,to:22,since:2017]
...
gremlin> [ "Number of persons": persons.size()
, "Number of unique relationships": relations.size() ]
==>Number of persons=100
==>Number of unique relationships=478:set max-iteration 10
rnd = new Random(123) ; x = []
persons = (1..100).collect {["id": it, "name": "person ${it}", "age": rnd.nextInt(40) + 20]}
relations = (1..500).collect {[rnd.nextInt(persons.size()), rnd.nextInt(persons.size())]}.
unique().grep {it[0] != it[1] && !x.contains(it.reverse())}.collect {
x << it
minAge = Math.min(persons[it[0]].age, persons[it[1]].age)
knowsSince = new Date().year + 1900 - rnd.nextInt(minAge)
["from": persons[it[0]].id, "to": persons[it[1]].id, "since": knowsSince]
}
[ "Number of persons": persons.size()
, "Number of unique relationships": relations.size() ]Now, to create the person vertices and the knows edges between them it may look like a good idea to generate a
single graph-mutating traversal, just like this:
gremlin> t = g
==>graphtraversalsource[tinkergraph[vertices:0 edges:0], standard]
gremlin> for (person in persons) {
t = t.addV("person").
property(id, person.id).
property("name", person.name).
property("age", person.age).as("p${person.id}")
} ; []
gremlin> for (relation in relations) {
t = t.addE("knows").property("since", relation.since).
from("p${relation.from}").
to("p${relation.to}")
} ; []
gremlin> traversalAsString = org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyTranslator.of("g").translate(t.bytecode) ; []
gremlin> [ "Traversal String Length": traversalAsString.length()
, "Traversal Preview": traversalAsString.replaceFirst(/^(.{104}).*(.{64})$/, '$1 ... $2') ]
==>Traversal String Length=41086
==>Traversal Preview=g.addV("person").property(T.id,(int) 1).property("name",person 1).property("age",(int) 42).as("p1").addV ... addE("knows").property("since",(int) 2005).from("p47").to("p48")t = g
for (person in persons) {
t = t.addV("person").
property(id, person.id).
property("name", person.name).
property("age", person.age).as("p${person.id}")
} ; []
for (relation in relations) {
t = t.addE("knows").property("since", relation.since).
from("p${relation.from}").
to("p${relation.to}")
} ; []
traversalAsString = org.apache.tinkerpop.gremlin.groovy.jsr223.GroovyTranslator.of("g").translate(t.bytecode) ; []
[ "Traversal String Length": traversalAsString.length()
, "Traversal Preview": traversalAsString.replaceFirst(/^(.{104}).*(.{64})$/, '$1 ... $2') ]However, this kind of traversal does not scale and it’s prone to produce a StackOverflowError. This error can hardly be prevented
as it’s a limit imposed by the JVM. The stack size can be increased using the -Xss JVM option, but that’s not how the problem that’s
discussed here, should be solved. The proper way to accomplish the same thing as in the traversal above is to inject the lists into
the traversal and process them from there.
gremlin> g.withSideEffect("relations", relations).
inject(persons).sideEffect(
unfold().
addV("person").
property(id, select("id")).
property("name", select("name")).
property("age", select("age")).
group("m").
by(id).
by(unfold())).
select("relations").unfold().as("r").
addE("knows").
from(select("m").select(select("r").select("from"))).
to(select("m").select(select("r").select("to"))).
property("since", select("since")).iterate()
gremlin> g
==>graphtraversalsource[tinkergraph[vertices:100 edges:478], standard]g.withSideEffect("relations", relations).
inject(persons).sideEffect(
unfold().
addV("person").
property(id, select("id")).
property("name", select("name")).
property("age", select("age")).
group("m").
by(id).
by(unfold())).
select("relations").unfold().as("r").
addE("knows").
from(select("m").select(select("r").select("from"))).
to(select("m").select(select("r").select("to"))).
property("since", select("since")).iterate()
gObviously, these traversals are more complicated, but the number of steps is known and thus it’s the best way to prevent an
unexpected StackOverflowError. Furthermore, shorter traversals reduce the (de)serialization costs when such a traversal is send
over the wire to a Gremlin Server.
|
Note
|
Although the example was based on a graph-mutating traversal, the same rules apply for read-only and mixed traversals. |
Unspecified Keys and Labels
Some Gremlin steps have optional arguments that represent keys (e.g. valueMap()) or labels (e.g. out()). In the prototyping
phase of a projects it’s often convenient to use these steps without any arguments. However, in production code this is bad idea
and keys and labels should always be specified. Not only does it make the traversal easier to read for others, but it also ensures
that the application will not break if the schema changes at one point and the queries return completely different results.
The following code block shows a few examples that are good for prototyping or graph discovery.
gremlin> g.V().has("person","name","marko").out()
==>v[3]
==>v[2]
==>v[4]
gremlin> g.V().has("person","name","marko").out("created").valueMap()
==>[name:[lop],lang:[java]]
gremlin> g.V().has("software","name","ripple").inE().has("weight", gte(0.5)).outV().properties()
==>vp[name->josh]
==>vp[age->32]g.V().has("person","name","marko").out()
g.V().has("person","name","marko").out("created").valueMap()
g.V().has("software","name","ripple").inE().has("weight", gte(0.5)).outV().properties()The next code block shows the same queries, but with specified keys and labels.
gremlin> g.V().has("person","name","marko").out("created","knows")
==>v[3]
==>v[2]
==>v[4]
gremlin> g.V().has("person","name","marko").out("created").valueMap("name","lang")
==>[name:[lop],lang:[java]]
gremlin> g.V().has("software","name","ripple").inE("created").has("weight", gte(0.5)).outV().
properties("name","age")
==>vp[name->josh]
==>vp[age->32]g.V().has("person","name","marko").out("created","knows")
g.V().has("person","name","marko").out("created").valueMap("name","lang")
g.V().has("software","name","ripple").inE("created").has("weight", gte(0.5)).outV().
properties("name","age")Unnecessary Steps
There are quite a few steps and patterns that can be combined into a much shorter form. TinkerPop is trying to optimize queries, by
rewriting such patterns automatically using traversal optimization strategies. These strategies, however, do have a few preconditions
and under certain circumstance they will not attempt to rewrite a traversal. For example, if the traversal has path computations
enabled (e.g. by using certain steps, such as path(), simplePath(), otherV(), etc.), then the assumption is that all steps are
required in order to produce the desired path.
An often seen anti-pattern is the one that explicitly traverses to an edge and then to a vertex without using any filters.
gremlin> g.V().hasLabel("person").outE("created").inV().dedup() //1\
==>v[3]
==>v[5]
gremlin> g.V().hasLabel("software").inE("created").outV().count() //2\
==>4g.V().hasLabel("person").outE("created").inV().dedup() //1\
g.V().hasLabel("software").inE("created").outV().count() //2-
The
creatededge is never really needed as the traversal only asks for all things that were created by all persons in the graph. These "things" are only represented by the adjacent vertices, not the edges. -
This traversals counts the persons in the graph who created software. The interesting thing about this query is that it actually doesn’t need to traverse all the way to the
personvertices to count them. In this case it’s sufficient to count the edges between thesoftwareandpersonvertices. The performance of this query pretty much depends on the particular provider implementation, but counting incident edges is usually much faster than counting adjacent vertices.
The next code block shows the two aforementioned queries properly rewritten.
gremlin> g.V().hasLabel("person").out("created").dedup()
==>v[3]
==>v[5]
gremlin> g.V().hasLabel("software").inE("created").count()
==>4g.V().hasLabel("person").out("created").dedup()
g.V().hasLabel("software").inE("created").count()Another anti-pattern that is commonly seen is the chaining of where()-steps using predicates. Consider the following traversal:
gremlin> g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a')).by(id).where(gt('b')).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name')
==>[a:lop,b:marko,c:vadas]
==>[a:josh,b:marko,c:vadas]
==>[a:peter,b:lop,c:josh]g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a')).by(id).where(gt('b')).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name')Ignoring the anti-patterns that were discussed before, there’s not much wrong with the traversal, but note the two chained where()-steps
(where(lt('a')).by(id).where(gt('b'))).by(id)). Both steps compare the id of the current vertex with the id of a previous vertex. These
two conditions can be combined on the predicate level.
gremlin> g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a').and(gt('b'))).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name')
==>[a:lop,b:marko,c:vadas]
==>[a:josh,b:marko,c:vadas]
==>[a:peter,b:lop,c:josh]g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a').and(gt('b'))).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name')The profile() output of both queries should make clear why this is better than using two where()-steps.
gremlin> g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a')).by(id).where(gt('b')).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name').
profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[])@[a] 6 6 0.141 2.19
VertexStep(BOTH,vertex) 12 12 0.712 11.02
WherePredicateStep(lt(a),[id])@[b] 6 6 0.456 7.07
NoOpBarrierStep(2500) 6 6 0.110 1.71
VertexStep(BOTH,vertex) 18 18 0.173 2.69
NotStep([VertexStep(BOTH,vertex), ProfileStep, ... 15 15 3.680 56.98
VertexStep(BOTH,vertex) 40 40 0.426
WherePredicateStep(eq(a)) 2.959
WherePredicateStep(lt(a),[id]) 6 6 0.530 8.22
NoOpBarrierStep(2500) 6 6 0.114 1.77
WherePredicateStep(gt(b),[id])@[c] 3 3 0.189 2.94
NoOpBarrierStep(2500) 3 3 0.069 1.08
SelectStep(last,[a, b, c],[value(name)]) 3 3 0.158 2.45
NoOpBarrierStep(2500) 3 3 0.120 1.87
>TOTAL - - 6.459 -
gremlin> g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a').and(gt('b'))).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name').
profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[])@[a] 6 6 0.191 2.92
VertexStep(BOTH,vertex) 12 12 0.429 6.54
WherePredicateStep(lt(a),[id])@[b] 6 6 0.482 7.35
NoOpBarrierStep(2500) 6 6 0.277 4.23
VertexStep(BOTH,vertex) 18 18 0.331 5.04
NotStep([VertexStep(BOTH,vertex), ProfileStep, ... 15 15 2.691 40.98
VertexStep(BOTH,vertex) 40 40 0.714
WherePredicateStep(eq(a)) 1.236
WherePredicateStep(and(lt(a), gt(b)),[id])@[c] 3 3 1.267 19.30
NoOpBarrierStep(2500) 3 3 0.179 2.73
SelectStep(last,[a, b, c],[value(name)]) 3 3 0.447 6.81
NoOpBarrierStep(2500) 3 3 0.269 4.11
>TOTAL - - 6.568 -g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a')).by(id).where(gt('b')).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name').
profile()
g.V().as('a').
both().where(lt('a')).by(id).as('b').
both().where(lt('a').and(gt('b'))).by(id).as('c').
not(both().where(eq('a'))).
select('a','b','c').
by('name').
profile()Unspecified Label in Global Vertex lookup
The severity of the anti-pattern described in this section heavily depends on the provider implementation. Throughout the TinkerPop documentation the code samples often use traversals that start like this:
gremlin> g.V().has('name','marko')
==>v[1]g.V().has('name','marko')This is totally fine for TinkerGraph as it uses a very simplified indexing schema, e.g. every vertex that has a certain property is stored in the same index. However, providers may prefer to use separate indexes for different vertex labels. This becomes more important as graphs grow much larger over time (which is not what TinkerGraph is meant to do). Hence, any traversal that’s going to be used in production code should also specify the vertex label to prevent the query engine from searching every index for the provided property value.
The easy fix for the initially mentioned query follows in the code block below.
gremlin> g.V().hasLabel('person').has('name','marko') //1\
==>v[1]
gremlin> g.V().has('person','name','marko') //2\
==>v[1]g.V().hasLabel('person').has('name','marko') //1\
g.V().has('person','name','marko') //2-
With the specified label the traversal still returns the same result, but it’s much safer to use across different providers.
-
Same as statement 1, but a much shorter form to improve readability.
Steps Instead of Tokens
When child traversals contain a single step, there’s a good chance that the step can be replaced with a token. These tokens are translated into optimized traversals that execute much faster then their step traversal pendants. A few examples of single step child traversals are shown in the following code block.
gremlin> g.V().groupCount().by(label())
==>[software:2,person:4]
gremlin> g.V().group().by(label()).by(id().fold())
==>[software:[3,5],person:[1,2,4,6]]
gremlin> g.V().project("id","label").
by(id()).
by(label())
==>[id:1,label:person]
==>[id:2,label:person]
==>[id:3,label:software]
==>[id:4,label:person]
==>[id:5,label:software]
==>[id:6,label:person]
gremlin> g.V().choose(label()).
option("person", project("person").by(values("name"))).
option("software", project("product").by(values("name")))
==>[person:marko]
==>[person:vadas]
==>[product:lop]
==>[person:josh]
==>[product:ripple]
==>[person:peter]g.V().groupCount().by(label())
g.V().group().by(label()).by(id().fold())
g.V().project("id","label").
by(id()).
by(label())
g.V().choose(label()).
option("person", project("person").by(values("name"))).
option("software", project("product").by(values("name")))With tokens used instead of steps the traversals become a little shorter and more readable.
gremlin> g.V().groupCount().by(label)
==>[software:2,person:4]
gremlin> g.V().group().by(label).by(id) //1\
==>[software:[3,5],person:[1,2,4,6]]
gremlin> g.V().project("id","label").
by(id).
by(label)
==>[id:1,label:person]
==>[id:2,label:person]
==>[id:3,label:software]
==>[id:4,label:person]
==>[id:5,label:software]
==>[id:6,label:person]
gremlin> g.V().choose(label).
option("person", project("person").by("name")).
option("software", project("product").by("name")) //2\
==>[person:marko]
==>[person:vadas]
==>[product:lop]
==>[person:josh]
==>[product:ripple]
==>[person:peter]g.V().groupCount().by(label)
g.V().group().by(label).by(id) //1\
g.V().project("id","label").
by(id).
by(label)
g.V().choose(label).
option("person", project("person").by("name")).
option("software", project("product").by("name")) //2-
Note, that tokens use a
fold()reducer by default. -
by("name")doesn’t use a token, but falls into the same category as the String"name"is translated into an optimized traversal.
But this is not all about readability; as initially mentioned, the use of tokens also improves the overall query performance as shown in
the profile() output below.
gremlin> g.V().groupCount().by(label()).profile() // not using token
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.183 39.80
GroupCountStep([LabelStep, ProfileStep]) 1 1 0.277 60.20
LabelStep 6 6 0.105
>TOTAL - - 0.461 -
gremlin> g.V().groupCount().by(label).profile() // using a token
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.084 37.13
GroupCountStep(label) 1 1 0.142 62.87
>TOTAL - - 0.227 -
gremlin> g.V().group().by(label()).by(id().fold()).profile() // not using tokens
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.130 10.92
GroupStep([LabelStep, ProfileStep],[IdStep, Pro... 1 1 1.063 89.08
LabelStep 6 6 0.026
IdStep 6 6 0.128
FoldStep 2 2 0.190
>TOTAL - - 1.194 -
gremlin> g.V().group().by(label).by(id).profile() // using tokens
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.084 17.73
GroupStep(label,[TraversalMapStep(id), ProfileS... 1 1 0.392 82.27
TraversalMapStep(id) 6 6 0.151
FoldStep 2 2 0.084
>TOTAL - - 0.477 -
gremlin> g.V().project("id","label").
by(id()).
by(label()).profile() // not using tokens
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.067 9.64
ProjectStep([id, label],[[IdStep, ProfileStep],... 6 6 0.629 90.36
IdStep 6 6 0.018
LabelStep 6 6 0.400
>TOTAL - - 0.696 -
gremlin> g.V().project("id","label").
by(id).
by(label).profile() // using tokens
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.125 50.49
ProjectStep([id, label],[id, label]) 6 6 0.123 49.51
>TOTAL - - 0.248 -
gremlin> g.V().choose(label()).
option("person", project("person").by(values("name"))).
option("software", project("product").by(values("name"))).
profile() // not using tokens
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.062 5.09
ChooseStep([LabelStep, ProfileStep],{software=[... 6 6 1.173 94.91
LabelStep 6 6 0.066
ProjectStep([product],[[PropertiesStep([name]... 2 2 0.013
PropertiesStep([name],value) 2 2 0.025
EndStep 2 2 0.078
ProjectStep([person],[[PropertiesStep([name],... 4 4 0.018
PropertiesStep([name],value) 4 4 0.090
EndStep 4 4 0.141
>TOTAL - - 1.236 -
gremlin> g.V().choose(label).
option("person", project("person").by("name")).
option("software", project("product").by("name")).
profile() // using tokens
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.078 10.13
ChooseStep([LambdaMapStep(label), ProfileStep],... 6 6 0.695 89.87
LambdaMapStep(label) 6 6 0.027
ProjectStep([product],[value(name)]) 2 2 0.011
EndStep 2 2 0.046
ProjectStep([person],[value(name)]) 4 4 0.027
EndStep 4 4 0.178
>TOTAL - - 0.774 -g.V().groupCount().by(label()).profile() // not using token
g.V().groupCount().by(label).profile() // using a token
g.V().group().by(label()).by(id().fold()).profile() // not using tokens
g.V().group().by(label).by(id).profile() // using tokens
g.V().project("id","label").
by(id()).
by(label()).profile() // not using tokens
g.V().project("id","label").
by(id).
by(label).profile() // using tokens
g.V().choose(label()).
option("person", project("person").by(values("name"))).
option("software", project("product").by(values("name"))).
profile() // not using tokens
g.V().choose(label).
option("person", project("person").by("name")).
option("software", project("product").by("name")).
profile() // using tokens|
Note
|
Pay attention to all metrics. The time difference does not always look significant, sometimes it might even be worse in the optimized query, but that’s usually because TinkerGraph keeps everything in memory and thus even bad queries can sometimes perform surprisingly well. The more important metrics, however, are the number of traversers that are used and the overall number of generated steps. |
Implementation Recipes
Style Guide
Gremlin is a data flow language where each new step concatenation alters the stream accordingly. This aspect of the language allows users to easily "build-up" a traversal (literally) step-by-step until the expected results are returned. For instance:
gremlin> g.V(1)
==>v[1]
gremlin> g.V(1).out('knows')
==>v[2]
==>v[4]
gremlin> g.V(1).out('knows').out('created')
==>v[5]
==>v[3]
gremlin> g.V(1).out('knows').out('created').groupCount()
==>[v[3]:1,v[5]:1]
gremlin> g.V(1).out('knows').out('created').groupCount().by('name')
==>[ripple:1,lop:1]g.V(1)
g.V(1).out('knows')
g.V(1).out('knows').out('created')
g.V(1).out('knows').out('created').groupCount()
g.V(1).out('knows').out('created').groupCount().by('name')A drawback of building up a traversal is that users tend to create long, single line traversal that are hard to read. For simple traversals, a single line is fine. For complex traversals, there are few formatting patterns that should be followed which will yield cleaner, easier to understand traversals. For instance, the last traversal above would be written:
gremlin> g.V(1).out('knows').out('created').
groupCount().by('name')
==>[ripple:1,lop:1]g.V(1).out('knows').out('created').
groupCount().by('name')Lets look at a complex traversal and analyze each line according to the recommended formatting rule is subscribes to.
gremlin> g.V().out('knows').out('created'). //1\
group().by('lang').by(). //2\
select('java').unfold(). //3\
in('created').hasLabel('person'). //4\
order(). //5\
by(inE().count(),desc). //6\
by('age',asc).
dedup().limit(10).values('name') //7\
==>josh
==>marko
==>peterg.V().out('knows').out('created'). //1\
group().by('lang').by(). //2\
select('java').unfold(). //3\
in('created').hasLabel('person'). //4\
order(). //5\
by(inE().count(),desc). //6\
by('age',asc).
dedup().limit(10).values('name') //7-
A sequence of
ins().outs().filters().etc()on a single line until it gets too long. -
When a barrier (reducer, aggregator, etc.) is used, put it on a new line.
-
When a next line component is an "add on" to the previous line component, 2 space indent. The
select()-step in this context is "almost like" aby()-modulator as its projecting data out of thegroup(). Theunfold()-step is a data formatting necessity that should not be made too prominent. -
Back to a series of
ins().outs().filters().etc()on a single line. -
order()is a barrier step and thus, should be on a new line. -
If there is only one
by()-modulator (or a series of short ones), keep it on one line, else eachby()is a new line. -
Back to a series
ins().outs().filters().etc().
Style Guide Rules
A generalization of the specifics above are presented below.
-
Always use 2 space indent.
-
No newline should ever have the same indent as the line starting with the traversal source
g. -
Barrier steps should form line breaks unless they are simple (e.g.
sum()). -
Complex
by()-modulators form indented "paragraphs." -
Standard filters, maps, flatMaps remain on the same line until they get too long.
Given the diversity of traversals and the complexities introduced by lambdas (for example), these rules will not always lead to optimal representations. However, by in large, the style rules above will help make 90% of traversals look great.
Traversal Component Reuse
Good software development practices require reuse to keep software maintainable. In Gremlin, there are often bits of
traversal logic that could be represented as components that might be tested independently and utilized
as part of other traversals. One approach to doing this would be to extract such logic into an anonymous traversal
and provide it to a parent traversal through flatMap()-step.
Using the modern toy graph as an example, assume that there are number of traversals that are interested in filtering on edges where the "weight" property is greater than "0.5". A query like that might look like this:
gremlin> g.V(1).outE("knows").has('weight', P.gt(0.5d)).inV().both()
==>v[5]
==>v[3]
==>v[1]g.V(1).outE("knows").has('weight', P.gt(0.5d)).inV().both()Repeatedly requiring that filter on "weight" could lead to a lot of duplicate code, which becomes difficult to maintain. It would be nice to extract that logic so as to centralize it for reuse in all places where needed. An anonymous traversal allows that to happen and can be created as follows.
gremlin> weightFilter = outE("knows").has('weight', P.gt(0.5d)).inV();[]
gremlin> g.V(1).flatMap(weightFilter).both()
==>v[5]
==>v[3]
==>v[1]weightFilter = outE("knows").has('weight', P.gt(0.5d)).inV();[]
g.V(1).flatMap(weightFilter).both()The weightFilter is an anonymous traversal and it is created by way __ class. The __ is omitted above from
initalization of weightFilter because it is statically imported to the Gremlin Console. The weightFilter gets
passed to the "full" traversal by way for flatMap()-step and the results are the same. Of course, there is a problem.
If there is an attempt to use that weightFilter a second time, the traversal with thrown an exception because both
the weightFilter and parent traversal have been "compiled" which prevents their re-use. A simple fix to this would
be to clone the weightFilter.
gremlin> weightFilter = outE("knows").has('weight', P.gt(0.5d)).inV();[]
gremlin> g.V(1).flatMap(weightFilter.clone()).both()
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(1).flatMap(weightFilter.clone()).bothE().otherV()
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(1).flatMap(weightFilter.clone()).groupCount()
==>[v[4]:1]weightFilter = outE("knows").has('weight', P.gt(0.5d)).inV();[]
g.V(1).flatMap(weightFilter.clone()).both()
g.V(1).flatMap(weightFilter.clone()).bothE().otherV()
g.V(1).flatMap(weightFilter.clone()).groupCount()Now the weightFilter can be reused over and over again. Remembering to clone() might lead to yet another maintenance
issue in that failing to recall that step would likely result in a bug. One option might be to wrap the weightFilter
creation in a function that returns the clone. Another approach might be to parameterize that function to construct
a new anonymous traversal each time with the idea being that this might gain even more flexibility in parameterizing
the anonymous traversal itself.
gremlin> weightFilter = { w -> outE("knows").has('weight', P.gt(w)).inV() }
==>groovysh_evaluate$_run_closure1@7a1a3468
gremlin> g.V(1).flatMap(weightFilter(0.5d)).both()
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(1).flatMap(weightFilter(0.5d)).bothE().otherV()
==>v[5]
==>v[3]
==>v[1]
gremlin> g.V(1).flatMap(weightFilter(0.5d)).groupCount()
==>[v[4]:1]weightFilter = { w -> outE("knows").has('weight', P.gt(w)).inV() }
g.V(1).flatMap(weightFilter(0.5d)).both()
g.V(1).flatMap(weightFilter(0.5d)).bothE().otherV()
g.V(1).flatMap(weightFilter(0.5d)).groupCount()How to Contribute a Recipe
Recipes are generated under the same system as all TinkerPop documentation and is stored directly in the source code repository. TinkerPop documentation is all asciidoc based and can be generated locally with either shell script/Maven or Docker build commands. Once changes are complete, submit a pull request for review by TinkerPop committers.
|
Note
|
Please review existing recipes and attempt to conform to their writing and visual style. It may also be a good idea to discuss ideas for a recipe on the developer mailing list prior to starting work on it, as the community might provide insight on the approach and idea that would be helpful. It is preferable that a JIRA issue be opened that describes the nature of the recipe so that the eventual pull request can be bound to that issue. |
|
Important
|
Please read TinkerPop’s policy on contributing prior to submitting a recipe. |
To contribute a recipe, first clone the repository:
git clone https://github.com/apache/tinkerpop.gitThe recipes can be found in this directory:
ls docs/src/recipesEach recipe exists within a separate .asciidoc file. The file name should match the name of the recipe. Recipe names
should be short, but descriptive (as they need to fit in the left-hand table of contents when generated). The
index.asciidoc is the parent document that "includes" the content of each individual recipe file. A recipe file is
included in the index.asciidoc with an entry like this: include::my-recipe.asciidoc[]
Documentation should be generated locally for review prior to submitting a pull request. TinkerPop documentation is
"live" in that it is bound to a specific version when generated. Furthermore, code examples (those that are
gremlin-groovy based) are executed at document generation time with the results written directly into the output.
The following command will generate the documentation with:
bin/process-docs.shThe generated documentation can be found at target/docs/htmlsingle/recipes. This process can be long on the first
run of the documentation as it is generating all of the documentation locally (e.g. reference documentation,
tutorials, etc). To generate just the recipes, follow this process:
bin/process-docs.sh -f docs/src/recipesThe bin/process-docs.sh approach requires that Hadoop is installed. To avoid that prerequisite, try using Docker:
docker/build.sh -dThe downside to using Docker is that the process will take longer as each run will require the entire documentation set to be generated.
The final step to submitting a recipe is to issue a pull request through GitHub. It is helpful to prefix the name of the pull request with the JIRA issue number, so that TinkerPop’s automation between GitHub and JIRA are linked. As mentioned earlier in this section, the recipe will go under review by TinkerPop committers prior to merging. This process may take several days to complete. We look forward to receiving your submissions!
Appendix
Many of the recipes are based on questions and answers provided on the gremlin-users mailing list or on StackOverflow. This section contains those traversals from those sources that do not easily fit any particular pattern (i.e. a recipe), but are nonetheless interesting and thus remain good tools for learning Gremlin.
For each person in a "follows" graph, determine the number of followers and list their names.
gremlin> g.addV().property('name','marko').as('marko').
addV().property('name','josh').as('josh').
addV().property('name','daniel').as('daniel').
addV().property('name','matthias').as('matthias').
addE('follows').from('josh').to('marko').
addE('follows').from('matthias').to('josh').
addE('follows').from('daniel').to('josh').
addE('follows').from('daniel').to('marko').iterate()
gremlin> g.V().as('p').
map(__.in('follows').values('name').fold()).
project('person','followers','numFollowers').
by(select('p').by('name')).
by().
by(count(local))
==>[person:marko,followers:[josh,daniel],numFollowers:2]
==>[person:josh,followers:[matthias,daniel],numFollowers:2]
==>[person:daniel,followers:[],numFollowers:0]
==>[person:matthias,followers:[],numFollowers:0]g.addV().property('name','marko').as('marko').
addV().property('name','josh').as('josh').
addV().property('name','daniel').as('daniel').
addV().property('name','matthias').as('matthias').
addE('follows').from('josh').to('marko').
addE('follows').from('matthias').to('josh').
addE('follows').from('daniel').to('josh').
addE('follows').from('daniel').to('marko').iterate()
g.V().as('p').
map(__.in('follows').values('name').fold()).
project('person','followers','numFollowers').
by(select('p').by('name')).
by().
by(count(local))It might also be alternatively written as:
gremlin> g.V().group().
by('name').
by(project('numFollowers','followers').
by(__.in('follows').count()).
by(__.in('follows').values('name').fold())).next()
==>daniel={numFollowers=0, followers=[]}
==>matthias={numFollowers=0, followers=[]}
==>josh={numFollowers=2, followers=[matthias, daniel]}
==>marko={numFollowers=2, followers=[josh, daniel]}g.V().group().
by('name').
by(project('numFollowers','followers').
by(__.in('follows').count()).
by(__.in('follows').values('name').fold())).next()or even:
gremlin> g.V().group().
by('name').
by(__.in('follows').values('name').fold().
project('numFollowers','followers').
by(count(local)).
by()).next()
==>daniel={numFollowers=0, followers=[]}
==>matthias={numFollowers=0, followers=[]}
==>josh={numFollowers=2, followers=[matthias, daniel]}
==>marko={numFollowers=2, followers=[josh, daniel]}g.V().group().
by('name').
by(__.in('follows').values('name').fold().
project('numFollowers','followers').
by(count(local)).
by()).next()In the "modern" graph, show each person, the software they worked on and the co-worker count for the software and the names of those co-workers.
gremlin> g.V().hasLabel("person").as("p").
out("created").as("s").
map(__.in("created").
where(neq("p")).values("name").fold()).
group().by(select("p").by("name")).
by(group().by(select("s").by("name")).
by(project("numCoworkers","coworkers").
by(count(local)).by())).next()
==>peter={lop={numCoworkers=2, coworkers=[marko, josh]}}
==>josh={ripple={numCoworkers=0, coworkers=[]}, lop={numCoworkers=2, coworkers=[marko, peter]}}
==>marko={lop={numCoworkers=2, coworkers=[josh, peter]}}g.V().hasLabel("person").as("p").
out("created").as("s").
map(__.in("created").
where(neq("p")).values("name").fold()).
group().by(select("p").by("name")).
by(group().by(select("s").by("name")).
by(project("numCoworkers","coworkers").
by(count(local)).by())).next()Assuming a graph of students, classes and times, detect students who have a conflicting schedule.
gremlin> g.addV("student").property("name", "Pete").as("s1").
addV("student").property("name", "Joe").as("s2").
addV("class").property("name", "Java's GC").as("c1").
addV("class").property("name", "FP Principles").as("c2").
addV("class").property("name", "Memory Management in C").as("c3").
addV("class").property("name", "Memory Management in C++").as("c4").
addV("timeslot").property("date", "11/25/2016").property("fromTime", "10:00").property("toTime", "11:00").as("t1").
addV("timeslot").property("date", "11/25/2016").property("fromTime", "11:00").property("toTime", "12:00").as("t2").
addE("attends").from("s1").to("c1").
addE("attends").from("s1").to("c2").
addE("attends").from("s1").to("c3").
addE("attends").from("s1").to("c4").
addE("attends").from("s2").to("c2").
addE("attends").from("s2").to("c3").
addE("allocated").from("c1").to("t1").
addE("allocated").from("c1").to("t2").
addE("allocated").from("c2").to("t1").
addE("allocated").from("c3").to("t2").
addE("allocated").from("c4").to("t2").iterate()
gremlin> g.V().hasLabel("student").as("s").
out("attends").as("c").
out("allocated").as("t").
select("s").
out("attends").
where(neq("c")).
out("allocated").
where(eq("t")).
group().
by(select("s").by("name")).
by(group().by(select("t").by(valueMap("fromTime","toTime"))).
by(select("c").dedup().values("name").fold())).next()
==>Pete={{fromTime=[10:00], toTime=[11:00]}=[Java's GC, FP Principles], {fromTime=[11:00], toTime=[12:00]}=[Memory Management in C, Memory Management in C++, Java's GC]}g.addV("student").property("name", "Pete").as("s1").
addV("student").property("name", "Joe").as("s2").
addV("class").property("name", "Java's GC").as("c1").
addV("class").property("name", "FP Principles").as("c2").
addV("class").property("name", "Memory Management in C").as("c3").
addV("class").property("name", "Memory Management in C++").as("c4").
addV("timeslot").property("date", "11/25/2016").property("fromTime", "10:00").property("toTime", "11:00").as("t1").
addV("timeslot").property("date", "11/25/2016").property("fromTime", "11:00").property("toTime", "12:00").as("t2").
addE("attends").from("s1").to("c1").
addE("attends").from("s1").to("c2").
addE("attends").from("s1").to("c3").
addE("attends").from("s1").to("c4").
addE("attends").from("s2").to("c2").
addE("attends").from("s2").to("c3").
addE("allocated").from("c1").to("t1").
addE("allocated").from("c1").to("t2").
addE("allocated").from("c2").to("t1").
addE("allocated").from("c3").to("t2").
addE("allocated").from("c4").to("t2").iterate()
g.V().hasLabel("student").as("s").
out("attends").as("c").
out("allocated").as("t").
select("s").
out("attends").
where(neq("c")).
out("allocated").
where(eq("t")).
group().
by(select("s").by("name")).
by(group().by(select("t").by(valueMap("fromTime","toTime"))).
by(select("c").dedup().values("name").fold())).next()In the "modern" graph, with a duplicate edge added, find the vertex pairs that have more than one edge between them.
gremlin> g.V(1).as("a").V(3).addE("created").property("weight",0.4d).from("a").iterate()
gremlin> g.V(1).outE("created")
==>e[9][1-created->3]
==>e[13][1-created->3]
gremlin> g.V().as("a").
out().as("b").
groupCount().
by(select("a","b")).
unfold().
filter(select(values).is(gt(1))).
select(keys)
==>[a:v[1],b:v[3]]g.V(1).as("a").V(3).addE("created").property("weight",0.4d).from("a").iterate()
g.V(1).outE("created")
g.V().as("a").
out().as("b").
groupCount().
by(select("a","b")).
unfold().
filter(select(values).is(gt(1))).
select(keys)The following example assumes that the edges point in the OUT direction. Assuming undirected edges:
gremlin> g.V().where(without("x")).as("a").
outE().as("e").inV().as("b").
filter(bothE().where(neq("e")).otherV().where(eq("a"))).store("x").
select("a","b").dedup()g.V().where(without("x")).as("a").
outE().as("e").inV().as("b").
filter(bothE().where(neq("e")).otherV().where(eq("a"))).store("x").
select("a","b").dedup()In the "crew" graph, find vertices that match on a complete set of multi-properties.
gremlin> places = ["centreville","dulles"];[] // will not match as "purcellville" is missing
gremlin> g.V().not(has("location", without(places))).
where(values("location").is(within(places)).count().is(places.size())).
valueMap()
gremlin> places = ["centreville","dulles","purcellville"];[]
gremlin> g.V().not(has("location", without(places))).
where(values("location").is(within(places)).count().is(places.size())).
valueMap()
==>[name:[stephen],location:[centreville,dulles,purcellville]]places = ["centreville","dulles"];[] // will not match as "purcellville" is missing
g.V().not(has("location", without(places))).
where(values("location").is(within(places)).count().is(places.size())).
valueMap()
places = ["centreville","dulles","purcellville"];[]
g.V().not(has("location", without(places))).
where(values("location").is(within(places)).count().is(places.size())).
valueMap()Methods for performing some basic mathematical operations in the "modern" graph.
gremlin> g.V().values("age").sum() // sum all ages
==>123
gremlin> g.V().values("age").fold(1, mult) // multiply all ages
==>876960
gremlin> g.withSack(0).V().values("age").sack(sum).sack(sum).by(constant(-1)).sack() // subtract 1
==>28
==>26
==>31
==>34
gremlin> g.withSack(0).V().values("age").sack(sum).sack(sum).sack() // multiply by 2 (simple)
==>58
==>54
==>64
==>70
gremlin> g.withSack(0).V().values("age").sack(sum).sack(mult).by(constant(2)).sack() // multiply by 2 (generally useful for multiplications by n)
==>58
==>54
==>64
==>70g.V().values("age").sum() // sum all ages
g.V().values("age").fold(1, mult) // multiply all ages
g.withSack(0).V().values("age").sack(sum).sack(sum).by(constant(-1)).sack() // subtract 1
g.withSack(0).V().values("age").sack(sum).sack(sum).sack() // multiply by 2 (simple)
g.withSack(0).V().values("age").sack(sum).sack(mult).by(constant(2)).sack() // multiply by 2 (generally useful for multiplications by n)Method for doing a sum with division.
gremlin> g.addV().property(id, "a").as("a").
addV().property(id, "b").as("b").
addE("link").from("a").to("b").
addE("link").from("b").to("a").
addE("link").from("b").to("a").iterate()
gremlin> g.withSack(0d).
V("a").as("a").
V("b").as("b").
project("ab", "ba").
by(inE("link").where(outV().as("a")).count()).
by(outE("link").where(inV().as("a")).count()).
sack(sum).by(select("ab")).
sack(div).by(select("ba")).
project("a", "b", "#(a,b)", "#(b,a)", "#(a,b) / #(b,a)").
by(select("a")).
by(select("b")).
by(select("ab")).
by(select("ba")).
by(sack())
==>[a:v[a],b:v[b],#(a,b):1,#(b,a):2,#(a,b) / #(b,a):0.5]g.addV().property(id, "a").as("a").
addV().property(id, "b").as("b").
addE("link").from("a").to("b").
addE("link").from("b").to("a").
addE("link").from("b").to("a").iterate()
g.withSack(0d).
V("a").as("a").
V("b").as("b").
project("ab", "ba").
by(inE("link").where(outV().as("a")).count()).
by(outE("link").where(inV().as("a")).count()).
sack(sum).by(select("ab")).
sack(div).by(select("ba")).
project("a", "b", "#(a,b)", "#(b,a)", "#(a,b) / #(b,a)").
by(select("a")).
by(select("b")).
by(select("ab")).
by(select("ba")).
by(sack())Dropping a vertex, as well as the vertices related to that dropped vertex that are connected by a "knows" edge in the "modern" graph
gremlin> g.V().has('name','marko').outE()
==>e[9][1-created->3]
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V().has('name','marko').sideEffect(out('knows').drop()).drop()
gremlin> g.V().has('name','marko')
gremlin> g.V(2,4,3)
==>v[3]g.V().has('name','marko').outE()
g.V().has('name','marko').sideEffect(out('knows').drop()).drop()
g.V().has('name','marko')
g.V(2,4,3)For the specified graph, find all neighbor vertices connected to "A" as filtered by datetime, those neighbor vertices that don’t have datetime vertices, and those neighbor vertices that have the label "dimon".
gremlin> g.addV().property("name", "A").as("a").
addV().property("name", "B").as("b").
addV().property("name", "C").as("c").
addV().property("name", "D").as("d").
addV().property("name", "E").as("e").
addV("dimon").property("name", "F").as("f").
addV().property("name", "G").as("g").property("date", 20160818).
addV().property("name", "H").as("h").property("date", 20160817).
addE("rel").from("a").to("b").
addE("rel").from("a").to("c").
addE("rel").from("a").to("d").
addE("rel").from("a").to("e").
addE("rel").from("c").to("f").
addE("occured_at").from("d").to("g").
addE("occured_at").from("e").to("h").iterate()
gremlin> // D and E have a valid datetime
==>true
gremlin> g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", gte(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
==>[name:[B]]
==>[name:[F]]
==>[name:[D]]
==>[name:[E]]
gremlin> // only E has a valid date
==>true
gremlin> g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", lte(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
==>[name:[B]]
==>[name:[F]]
==>[name:[E]]
gremlin> // only D has a valid date
==>true
gremlin> g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", gt(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
==>[name:[B]]
==>[name:[F]]
==>[name:[D]]
gremlin> // neither D nor E have a valid date
==>true
gremlin> g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", lt(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
==>[name:[B]]
==>[name:[F]]g.addV().property("name", "A").as("a").
addV().property("name", "B").as("b").
addV().property("name", "C").as("c").
addV().property("name", "D").as("d").
addV().property("name", "E").as("e").
addV("dimon").property("name", "F").as("f").
addV().property("name", "G").as("g").property("date", 20160818).
addV().property("name", "H").as("h").property("date", 20160817).
addE("rel").from("a").to("b").
addE("rel").from("a").to("c").
addE("rel").from("a").to("d").
addE("rel").from("a").to("e").
addE("rel").from("c").to("f").
addE("occured_at").from("d").to("g").
addE("occured_at").from("e").to("h").iterate()
// D and E have a valid datetime
g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", gte(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
// only E has a valid date
g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", lte(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
// only D has a valid date
g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", gt(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()
// neither D nor E have a valid date
g.V().has("name", "A").out("rel").
union(where(out("occured_at").has("date", lt(20160817))),
__.not(outE("occured_at")).coalesce(out().hasLabel("dimon"), identity())).
valueMap()Use element labels in a select.
gremlin> g.V(1).as("a").
both().
map(group().by(label).by(unfold())).as("b").
select("a","b").
map(union(project("a").by(select("a")), select("b")).
unfold().
group().
by(select(keys)).
by(select(values)))
==>[a:v[1],software:v[3]]
==>[a:v[1],person:v[2]]
==>[a:v[1],person:v[4]]
gremlin> g.V().as("a").
both().
map(group().by(label).by(unfold())).as("b").
select("a","b").
group().
by(select("a")).
by(select("b").
group().
by(select(keys)).
by(select(values).fold())).
unfold().
map(union(select(keys).project("a").by(), select(values)).
unfold().
group().
by(select(keys).unfold()).
by(select(values).unfold().unfold().fold()))
==>[a:[v[1]],software:[v[3]],person:[v[2],v[4]]]
==>[a:[v[2]],person:[v[1]]]
==>[a:[v[3]],person:[v[1],v[4],v[6]]]
==>[a:[v[4]],software:[v[5],v[3]],person:[v[1]]]
==>[a:[v[5]],person:[v[4]]]
==>[a:[v[6]],software:[v[3]]]g.V(1).as("a").
both().
map(group().by(label).by(unfold())).as("b").
select("a","b").
map(union(project("a").by(select("a")), select("b")).
unfold().
group().
by(select(keys)).
by(select(values)))
g.V().as("a").
both().
map(group().by(label).by(unfold())).as("b").
select("a","b").
group().
by(select("a")).
by(select("b").
group().
by(select(keys)).
by(select(values).fold())).
unfold().
map(union(select(keys).project("a").by(), select(values)).
unfold().
group().
by(select(keys).unfold()).
by(select(values).unfold().unfold().fold()))Sum edge weight with a coefficient.
gremlin> g.addV('person').property('name','alice').as('alice').
addV('person').property('name','bobby').as('bobby').
addV('person').property('name','cindy').as('cindy').
addV('person').property('name','david').as('david').
addV('person').property('name','eliza').as('eliza').
addE('rates').from('alice').to('bobby').property('tag','ruby').property('value',9).
addE('rates').from('bobby').to('cindy').property('tag','ruby').property('value',8).
addE('rates').from('cindy').to('david').property('tag','ruby').property('value',7).
addE('rates').from('david').to('eliza').property('tag','ruby').property('value',6).
addE('rates').from('alice').to('eliza').property('tag','java').property('value',9).iterate()
gremlin> g.withSack(1.0).V().has("name","alice").
repeat(outE("rates").has("tag","ruby").
project("a","b","c").
by(inV()).
by(sack()).
by("value").as("x").
select("a").
sack(mult).by(constant(0.5))).
times(3).emit().
select(all, "x").
project("name","score").
by(tail(local, 1).select("a").values("name")).
by(unfold().
sack(assign).by(select("b")).
sack(mult).by(select("c")).
sack().sum())
==>[name:bobby,score:9.0]
==>[name:cindy,score:13.00]
==>[name:david,score:14.750]g.addV('person').property('name','alice').as('alice').
addV('person').property('name','bobby').as('bobby').
addV('person').property('name','cindy').as('cindy').
addV('person').property('name','david').as('david').
addV('person').property('name','eliza').as('eliza').
addE('rates').from('alice').to('bobby').property('tag','ruby').property('value',9).
addE('rates').from('bobby').to('cindy').property('tag','ruby').property('value',8).
addE('rates').from('cindy').to('david').property('tag','ruby').property('value',7).
addE('rates').from('david').to('eliza').property('tag','ruby').property('value',6).
addE('rates').from('alice').to('eliza').property('tag','java').property('value',9).iterate()
g.withSack(1.0).V().has("name","alice").
repeat(outE("rates").has("tag","ruby").
project("a","b","c").
by(inV()).
by(sack()).
by("value").as("x").
select("a").
sack(mult).by(constant(0.5))).
times(3).emit().
select(all, "x").
project("name","score").
by(tail(local, 1).select("a").values("name")).
by(unfold().
sack(assign).by(select("b")).
sack(mult).by(select("c")).
sack().sum())