Getting Started
Apache TinkerPop is an open source Graph Computing Framework. Within itself, TinkerPop represents a large collection of capabilities and technologies and, in its wider ecosystem, an additionally extended world of third-party contributed graph libraries and systems. TinkerPop’s ecosystem can appear complex to newcomers of all experience, especially when glancing at the reference documentation for the first time.
So, where do you get started with TinkerPop? How do you dive in quickly and get productive? Well - Gremlin, the most recognizable citizen of The TinkerPop, is here to help with this thirty minute tutorial. That’s right - in just thirty short minutes, you too can be fit to start building graph applications with TinkerPop. Welcome to The TinkerPop Workout - by Gremlin!

The First Five Minutes
It is quite possible to learn a lot in just five minutes with TinkerPop, but before doing so, a proper introduction of your trainer is in order. Meet Gremlin!

Gremlin helps you navigate the vertices and edges of a graph. He is essentially your query language to graph databases, as SQL is the query language to relational databases. To tell Gremlin how he should "traverse" the graph (i.e. what you want your query to do) you need a way to provide him commands in the language he understands - and, of course, that language is called "Gremlin". For this task, you need one of TinkerPop’s most important tools: The Gremlin Console.
|
Note
|
Are you unsure of what a vertex or edge is? That topic is covered in the next section, but please allow the tutorial to get you oriented with the Gremlin Console first, so that you have an understanding of the tool that will help you with your learning experience. |
Download the console, unpackage it and start it:
$ unzip apache-tinkerpop-gremlin-console-3.1.6-bin.zip
$ cd apache-tinkerpop-gremlin-console-3.1.6
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin>|
Tip
|
Windows users may use the included bin/gremlin.bat file to start the Gremlin Console.
|
The Gremlin Console is a REPL environment, which provides a nice way to learn Gremlin as you get immediate feedback for the code that you enter. This eliminates the more complex need to "create a project" to try things out. The console is not just for "getting started" however. You will find yourself using it for a variety of TinkerPop-related activities, such as loading data, administering graphs, working out complex traversals, etc.
To get Gremlin to traverse a graph, you need a Graph instance, which holds the
structure and data of the
graph. TinkerPop is a graph abstraction layer over different graph databases and different graph processors, so there
are many Graph instances you can choose from to instantiate in the console. The best Graph instance to start with
however is TinkerGraph. TinkerGraph
is a fast, in-memory graph database with a small handful of configuration options, making it a good choice for beginners.
|
Tip
|
TinkerGraph is not just a toy for beginners. It is useful in analyzing subgraphs taken from a large graph, working with a small static graph that doesn’t change much, writing unit tests and other use cases where the graph can fit in memory. |
|
Tip
|
Resist the temptation to "get started" with more complex databases like Titan or to delve into how to get Gremlin Server working properly. Focusing on the basics, presented in this guide, builds a good foundation for all the other things TinkerPop offers. |
To make your process even easier, start with one of TinkerPop’s "toy" graphs. These are "small" graphs designed to provide a quick start into querying. It is good to get familiar with them, as almost all TinkerPop documentation is based on them and when you need help and have to come to the mailing list, a failing example put in the context of the toy graphs can usually get you a fast answer to your problem.
For your first graph, use the "Modern" graph which looks like this:
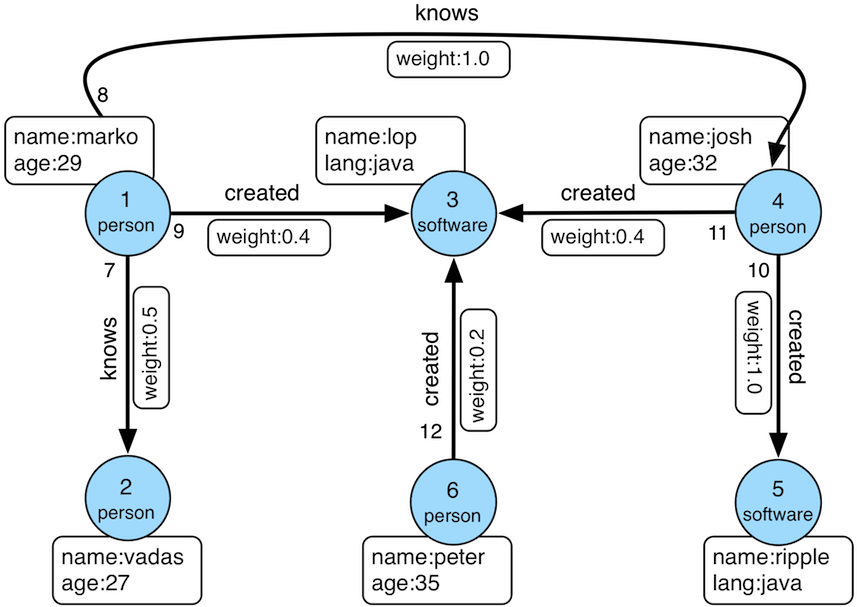
It can be instantiated in the console this way:
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]The first command creates a Graph instance named graph, which thus provides a reference to the data you want
Gremlin to traverse. Unfortunately, just having graph doesn’t provide Gremlin enough context to do his job. You
also need something called a TraversalSource, which is generated by the second command. The TraversalSource
provides additional information to Gremlin (such as the traversal strategies
to apply and the traversal engine to use) which
provides him guidance on how to execute his trip around the Graph.
With your TraversalSource g available it is now possible to ask Gremlin to traverse the Graph:
gremlin> g.V() //(1)
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V(1) //(2)
==>v[1]
gremlin> g.V(1).values('name') //(3)
==>marko
gremlin> g.V(1).outE('knows') //(4)
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).outE('knows').inV().values('name') //(5)
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name') //(6)
==>vadas
==>josh
gremlin> g.V(1).out('knows').has('age', gt(30)).values('name') //(7)
==>josh-
Get all the vertices in the
Graph. -
Get a vertex with the unique identifier of "1".
-
Get the value of the
nameproperty on vertex with the unique identifier of "1". -
Get the edges with the label "knows" for the vertex with the unique identifier of "1".
-
Get the names of the people that the vertex with the unique identifier of "1" "knows".
-
Note that when one uses
outE().inV()as shown in the previous command, this can be shortened to justout()(similar toinE().inV()andinfor incoming edges). -
Get the names of the people vertex "1" knows who are over the age of 30.
|
Important
|
A Traversal is essentially an Iterator so if you have code like x = g.V(), the x does not contain
the results of the g.V() query. Rather, that statement assigns an Iterator value to x. To get your results,
you would then need to iterate through x. This understanding is important because in the context of the console
typing g.V() instantly returns a value. The console does some magic for you by noticing that g.V() returns
an Iterator and then automatically iterates the results. In short, when writing Gremlin outside of the console
always remember that you must iterate your Traversal manually in some way for it to do anything.
|
In this first five minutes with Gremlin, you’ve gotten the Gremlin Console installed, instantiated a Graph and
TraversalSource, wrote some traversals and hopefully learned something about TinkerPop in general. You’ve only
scratched the surface of what there is to know, but those accomplishments will help enable your understanding of the
detailed sections to come.
The Next Fifteen Minutes
In the first five minutes of The TinkerPop Workout - by Gremlin, you learned some basics for traversing graphs. Of course, there wasn’t much discussion about what a graph is. A graph is a collection of vertices (i.e. nodes, dots) and edges (i.e. relationships, lines), where a vertex is an entity which represents some domain object (e.g. a person, a place, etc.) and an edge represents the relationship between two vertices.

The diagram above shows a graph with two vertices, one with a unique identifier of "1" and another with a unique identifier of "3". There is an edge connecting the two with a unique identifier of "9". It is important to consider that the edge has a direction which goes out from vertex "1" and in to vertex "3'.
|
Important
|
Most TinkerPop implementations do not allow for identifier assignment. They will rather assign their own identifiers and ignore assigned identifiers that you attempt to assign to them. |
A graph with elements that just have identifiers does not make for much of a database. To give some meaning to this basic structure, vertices and edges can each be given labels to categorize them.

You can now see that a vertex "1" is a "person" and vertex "3" is a "software" vertex. They are joined by a "created" edge which allows you to see that a "person created software". The "label" and the "id" are reserved attributes of vertices and edges, but you can add your own arbitrary properties as well:

This model is referred to as a property graph and it provides a flexible and intuitive way in which to model your data.
Creating a Graph
As intuitive as it is to you, it is perhaps more intuitive to Gremlin himself, as vertices, edges and properties make up the very elements of his existence. It is indeed helpful to think of our friend, Gremlin, moving about a graph when developing traversals, as picturing his position as the traverser helps orient where you need him to go next. Let’s use the two vertex, one edge graph we’ve been discussing above as an example. First, you need to create this graph:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> v1 = graph.addVertex(id, 1, label, "person", "name", "marko", "age", 29)
==>v[1]
gremlin> v2 = graph.addVertex(id, 3, label, "software", "name", "lop", "lang", "java")
==>v[3]
gremlin> v1.addEdge("created", v2, id, 9, "weight", 0.4)
==>e[9][1-created->3]There are a number of important things to consider in the above code. First, recall that id and label are
"reserved" for special usage in TinkerPop and are members of the enum, T. Those "keys" supplied to the creation
method are statically imported
to the console, which allows you to access them without having to specify their owning enum. Think of it as a
shorthand form that enables a more fluid code style. You would normally refer to them as T.id and T.label. Without
that static importing you would instead have to write:
gremlin> graph = TinkerGraph.open()
==>tinkergraph[vertices:0 edges:0]
gremlin> v1 = graph.addVertex(T.id, 1, T.label, "person", "name", "marko", "age", 29)
==>v[1]
gremlin> v2 = graph.addVertex(T.id, 3, T.label, "software", "name", "lop", "lang", "java")
==>v[3]
gremlin> v1.addEdge("created", v2, id, 9, "weight", 0.4)
==>e[9][1-created->3]|
Note
|
The fully qualified name for T is org.apache.tinkerpop.gremlin.structure.T. Another important static import
that is often seen in Gremlin comes from org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.__, which allows
for the creation of anonymous traversals.
|
Second, don’t forget that you are working with TinkerGraph which allows for identifier assignment. That is not the case with most graph databases.
Finally, the label for an Edge is required and is thus part of the method signature of addEdge(). It is the first
parameter supplied, followed by the Vertex to which v1 should be connected. Therefore, this usage of addEdge is
creating an edge that goes out of v1 and into v2 with a label of "created".
Graph Traversal - Staying Simple
Now that Gremlin knows where the graph data is, you can ask him to get you some data from it by doing a traversal, which you can think of as executing some process over the structure of the graph. We can form our question in English and then translate it to Gremlin. For this initial example, let’s ask Gremlin: "What software has Marko created?"
To answer this question, we would want Gremlin to:
-
Find "marko" in the graph
-
Walk along the "created" edges to "software" vertices
-
Select the "name" property of the "software" vertices
The English-based steps above largely translate to Gremlin’s position in the graph and to the steps we need to take
to ask him to answer our question. By stringing these steps together, we form a Traversal or the sequence of programmatic
steps Gremlin needs to perform
in order to get you an answer.
Let’s start with finding "marko". This operation is a filtering step as it searches the full set of vertices to match those that have the "name" property value of "marko". This can be done with the has() step as follows:
gremlin> g.V().has('name','marko')
==>v[1]|
Note
|
The variable g is the TraversalSource, which was introduced in the "The First Five Minutes". The
TraversalSource is created with graph.traversal() and is the object used to spawn new traversals.
|
We can picture this traversal in our little graph with Gremlin sitting on vertex "1".

When Gremlin is on a vertex or an edge, he has access to all the properties that are available to that element.
|
Important
|
The above query iterates all the vertices in the graph to get its answer. That’s fine for our little example, but for multi-million or billion edge graphs that is a big problem. To solve this problem, you should look to use indices. TinkerPop does not provide an abstraction for index management. You should consult the documentation of the graph you have chosen and utilize its native API to create indices which will then speed up these types of lookups. Your traversals will remain unchanged however, as the indices will be used transparently at execution time. |
Now that Gremlin has found "marko", he can now consider the next step in the traversal where we ask him to "walk" along "created" edges to "software" vertices. As described earlier, edges have direction, so we have to tell Gremlin what direction to follow. In this case, we want him to traverse on outgoing edges from the "marko" vertex. For this, we use the outE step.
gremlin> g.V().has('name','marko').outE('created')
==>e[9][1-created->3]At this point, you can picture Gremlin moving from the "marko" vertex to the "created" edge.

To get to the vertex on the other end of the edge, you need to tell Gremlin to move from the edge to the incoming
vertex with inV().
gremlin> g.V().has('name','marko').outE('created').inV()
==>v[3]You can now picture Gremlin on the "software" vertex as follows:

As you are not asking Gremlin to do anything with the properties of the "created" edge, you can simplify the statement above with:
gremlin> g.V().has('name','marko').out('created')
==>v[3]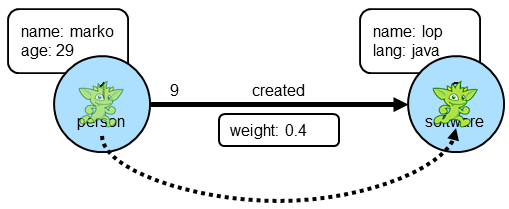
Finally, now that Gremlin has reached the "software that Marko created", he has access to the properties of the "software" vertex and you can therefore ask Gremlin to extract the value of the "name" property as follows:
gremlin> g.V().has('name','marko').out('created').values('name')
==>lopYou should now be able to see the connection Gremlin has to the structure of the graph and how Gremlin maneuvers from vertices to edges and so on. Your ability to string together steps to ask Gremlin to do more complex things, depends on your understanding of these basic concepts.
Graph Traversal - Increasing Complexity
Armed with the knowledge from the previous section, let’s ask Gremlin to perform some more difficult traversal tasks.
There’s not much more that can be done with the "baby" graph we had, so let’s return to the "modern" toy graph from
the "five minutes section". Recall that you can create this Graph and establish a TraversalSource with:
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]Earlier we’d used the has() step to tell Gremlin how to find the "marko" vertex. Let’s look at some other ways to
use has(). What if we wanted Gremlin to find the "age" values of both "vadas" and "marko"? In this case we could
use the within comparator with has() as follows:
gremlin> g.V().has('name',within('vadas','marko')).values('age')
==>29
==>27It is worth noting that within is statically imported from P to the Gremlin Console (much like T is, as described
earlier).
|
Note
|
The fully qualified name for P is org.apache.tinkerpop.gremlin.process.traversal.P.
|
If we wanted to ask Gremlin the average age of "vadas" and "marko" we could use the mean() step as follows:
gremlin> g.V().has('name',within('vadas','marko')).values('age').mean()
==>28.0Another method of filtering is seen in the use of the where step. We know how to find the "software" that "marko" created:
gremlin> g.V().has('name','marko').out('created')
==>v[3] Let’s extend on that query to try to learn who "marko"
collaborates with when it comes to the software he created. In other words, let’s try to answer the question of: "Who
are the people that marko develops software with?" To do that, we should first picture Gremlin where we left him in
the previous query. He was standing on the "software" vertex. To find out who "created" that "software", we need to
have Gremlin traverse back in along the "created" edges to find the "person" vertices tied to it.
Let’s extend on that query to try to learn who "marko"
collaborates with when it comes to the software he created. In other words, let’s try to answer the question of: "Who
are the people that marko develops software with?" To do that, we should first picture Gremlin where we left him in
the previous query. He was standing on the "software" vertex. To find out who "created" that "software", we need to
have Gremlin traverse back in along the "created" edges to find the "person" vertices tied to it.
gremlin> g.V().has('name','marko').out('created').in('created').values('name')
==>marko
==>josh
==>peterSo that’s nice, we can see that "peter", "josh" and "marko" are both responsible for creating "lop". Of course, we already know about the involvement of "marko" and it seems strange to say that "marko" collaborates with himself, so excluding "marko" from the results seems logical. The following traversal handles that exclusion:
gremlin> g.V().has('name','marko').as('exclude').out('created').in('created').where(neq('exclude')).values('name')
==>josh
==>peterWe made two additions to the traversal to make it exclude "marko" from the results. First, we added the
as() step. The as() step is not really a "step",
but a "step modulator" - something that adds features to a step or the traversal. Here, the as('exclude') labels
the has() step with the name "exclude" and all values that pass through that step are held in that label for later
use. In this case, the "marko" vertex is the only vertex to pass through that point, so it is held in "exclude".
The other addition that was made was the where() step which is a filter step like has(). The where() is
positioned after the in() step that has "person" vertices, which means that the where() filter is occurring
on the list of "marko" collaborators. The where() specifies that the "person" vertices passing through it should
not equal (i.e. neq()) the contents of the "exclude" label. As it just contains the "marko" vertex, the where()
filters out the "marko" that we get when we traverse back in on the "created" edges.
You will find many uses of as(). Here it is in combination with select:
gremlin> g.V().as('a').out().as('b').out().as('c').select('a','b','c')
==>[a:v[1], b:v[4], c:v[5]]
==>[a:v[1], b:v[4], c:v[3]]In the above example, we tell Gremlin to iterate through all vertices and traverse out twice from each. Gremlin
will label each vertex in that path with "a", "b" and "c", respectively. We can then use select to extract the
contents of that label.
Another common but important step is the group() step and its related step modulator called by(). If we wanted to ask Gremlin to group all the vertices in the graph by their vertex label we could do:
gremlin> g.V().group().by(label)
==>[software:[v[3], v[5]], person:[v[1], v[2], v[4], v[6]]]The use of by() here provides the mechanism by which to do the grouping. In this case, we’ve asked Gremlin to
use the label (which, again, is an automatic static import from T in the console). We can’t really tell much
about our distribution though because we just have vertex unique identifiers as output. To make that nicer we
could ask Gremlin to get us the value of the "name" property from those vertices, by supplying another by()
modulator to group() to transform the values.
gremlin> g.V().group().by(label).by('name')
==>[software:[lop, ripple], person:[marko, vadas, josh, peter]]In this section, you have learned a bit more about what property graphs are and how Gremlin interacts with them. You also learned how to envision Gremlin moving about a graph and how to use some of the more complex, but commonly utilized traversal steps. You are now ready to think about TinkerPop in terms of its wider applicability to graph computing.
The Final Ten Minutes
In these final ten minutes of The TinkerPop Workout - by Gremlin we’ll look at TinkerPop from a higher level and introduce different features of the stack in order to orient you with what it offers. In this way, you can identify areas of interest and dig into the details from there.
Why TinkerPop?
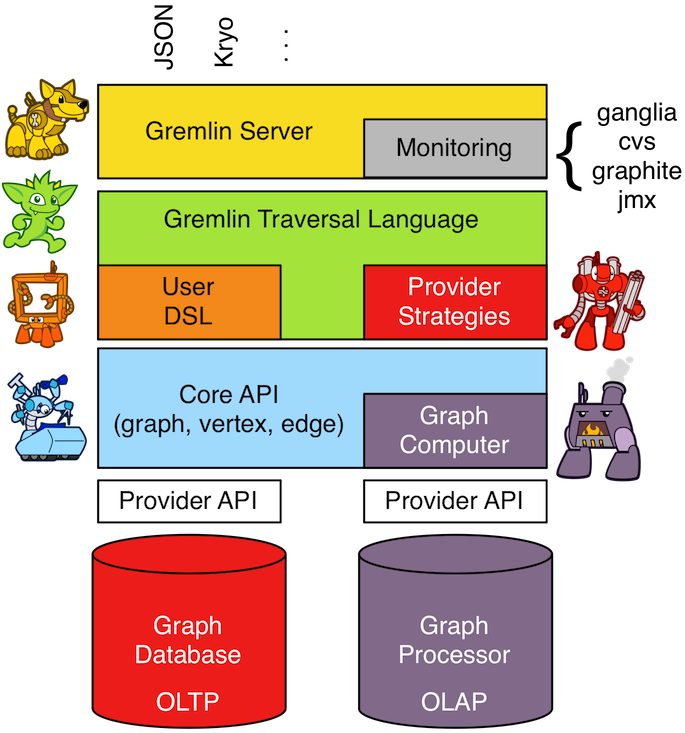 The goal of TinkerPop, as a Graph Computing Framework, is to make it
easy for developers to create graph applications by providing APIs and tools that simplify their endeavors. One of
the fundamental aspects to what TinkerPop offers in this area lies in the fact that TinkerPop is an abstraction layer
over different graph databases and different graph processors. As an abstraction layer, TinkerPop provides a way to
avoid vendor lock-in to a specific database or processor. This capability provides immense value to developers who
are thus afforded options in their architecture and development because:
The goal of TinkerPop, as a Graph Computing Framework, is to make it
easy for developers to create graph applications by providing APIs and tools that simplify their endeavors. One of
the fundamental aspects to what TinkerPop offers in this area lies in the fact that TinkerPop is an abstraction layer
over different graph databases and different graph processors. As an abstraction layer, TinkerPop provides a way to
avoid vendor lock-in to a specific database or processor. This capability provides immense value to developers who
are thus afforded options in their architecture and development because:
-
They can try different implementations using the same code to decide which is best for their environment.
-
They can grow into a particular implementation if they so desire - start with a graph that is designed to scale within a single machine and then later switch to a graph that is designed to scale horizontally.
-
They can feel more confident in graph technology choices, as advances in the state of different provider implementations are behind TinkerPop APIs, which open the possibility to switch providers with limited impact.
TinkerPop has always had the vision of being an abstraction over different graph databases. That much
is not new and dates back to TinkerPop 1.x. It is in TinkerPop 3.x however that we see the introduction of the notion
that TinkerPop is also an abstraction over different graph processors like Spark and
Giraph. The scope of this tutorial does not permit it to delve into
"graph processors", but the short story is that the same Gremlin statement we wrote in the examples above can be
executed to run in distributed fashion over Spark or Hadoop. The changes required to the code to do this are not
in the traversal itself, but in the definition of the TraversalSource. You can again see why we encourage, graph
operations to be executed through that class as opposed to just using Graph. You can read more about these
features in this section on hadoop-gremlin.
|
Tip
|
To maintain an abstraction over Graph creation use GraphFactory.open() to construct new instances. See
the documentation for individual Graph implementations to learn about the configuration options to provide.
|
Loading Data
 There are many strategies for getting data into your graph. As you are
just getting started, let’s look at the more simple methods aimed at "smaller" graphs. A "small" graph, in this
context, is one that has less than ten million edges. The most direct way to load this data is to write a Groovy script
that can be executed in the Gremlin Console, a tool that you should be well familiar with at this point. For our
example, let’s use the Wikipedia Vote Network data set which
contains 7,115 vertices and 103,689 edges.
There are many strategies for getting data into your graph. As you are
just getting started, let’s look at the more simple methods aimed at "smaller" graphs. A "small" graph, in this
context, is one that has less than ten million edges. The most direct way to load this data is to write a Groovy script
that can be executed in the Gremlin Console, a tool that you should be well familiar with at this point. For our
example, let’s use the Wikipedia Vote Network data set which
contains 7,115 vertices and 103,689 edges.
$ curl -L -O http://snap.stanford.edu/data/wiki-Vote.txt.gz
$ gunzip wiki-Vote.txt.gzThe data is contained in a tab-delimited structure where vertices are Wikipedia users and edges from one user to
another implies a "vote" relationship. Here is the script to parse the file and generate the Graph instance using
TinkerGraph:
graph = TinkerGraph.open()
graph.createIndex('userId', Vertex.class) (1)
g = graph.traversal()
getOrCreate = { id ->
g.V().has('userId', id).tryNext().orElseGet{ g.addV('userId', id).next() }
}
new File('wiki-Vote.txt').eachLine {
if (!it.startsWith("#")){
(fromVertex, toVertex) = it.split('\t').collect(getOrCreate) (2)
fromVertex.addEdge('votesFor', toVertex)
}
}-
To ensure fast lookups of vertices, we need an index. The
createIndex()method is a method native to TinkerGraph. Please consult your graph databases documentation for their index creation approaches. -
We are iterating each line of the
wiki-Vote.txtfile and this line splits the line on the delimiter, then uses some neat Groovy syntax to apply thegetOrCreate()function to each of the twouserIdfields encountered in the line and stores those vertices in thefromVertexandtoVertexvariables respectively.
|
Note
|
While this is a tab-delimited structure, this same pattern can be applied to any data source you require and Groovy tends to have nice libraries that can help making working with data quite enjoyable. |
|
Warning
|
Take care if using a Graph implementation that supports
transactions. As TinkerGraph does not, there is
no need to commit(). If your Graph does support transactions, intermediate commits during load will need to be
applied.
|
To load larger data sets you should read about the BulkLoaderVertexProgram (BLVP), which provides a generalized method for loading graphs of virtually any size.
Gremlin Server
 Gremlin Server
provides a way to remotely execute Gremlin scripts against one or more
Gremlin Server
provides a way to remotely execute Gremlin scripts against one or more Graph instances hosted within it. It does
this by exposing different endpoints, such as REST
and websockets, which allow a request
containing a Gremlin script to be processed with results returned.
$ curl -L -O https://www.apache.org/dist/tinkerpop/3.1.6/apache-tinkerpop-gremlin-server-3.1.6-bin.zip
$ unzip apache-tinkerpop-gremlin-server-3.1.6-bin.zip
$ cd apache-tinkerpop-gremlin-server-3.1.6
$ bin/gremlin-server.sh conf/gremlin-server-modern.yaml
[INFO] GremlinServer -
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
[INFO] GremlinServer - Configuring Gremlin Server from conf/gremlin-server-rest-modern.yaml
...
[INFO] GremlinServer$1 - Channel started at port 8182.$ curl -X POST -d "{\"gremlin\":\"g.V(x).out().values('name')\", \"language\":\"gremlin-groovy\", \"bindings\":{\"x\":1}}" "http://localhost:8182"{
"requestId": "abe3be05-1e86-481a-85e0-c59ad8a37c6b",
"status": {
"message": "",
"code": 200,
"attributes": {}
},
"result": {
"data": [
"lop",
"vadas",
"josh"
],
"meta": {}
}
}|
Important
|
Take careful note of the use of "bindings" in the arguments on the request. These are variables that are applied to the script on execution and is essentially a way to parameterize your scripts. This "parameterization" is critical to performance. Whenever possible, parameterize your queries. |
As mentioned earlier, Gremlin Server can also be configured with a websockets endpoint. This endpoint has an embedded subprotocol that allow a compliant driver to communicate with it. TinkerPop supplies a reference driver written in Java, but there are drivers developed by third-parties for other languages such as Python, Javascript, etc. Gremlin Server therefore represents the method by which non-JVM languages can interact with TinkerPop.
Conclusion
…and that is the end of The TinkerPop Workout - by Gremlin. You are hopefully feeling more confident in your TinkerPop skills and have a good overview of what the stack has to offer, as well as some entry points to further research within the reference documentation. Welcome to The TinkerPop!